

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
МИНИСТЕРСТВО НАУКИ И ОБРАЗОВАНИЯ РФ
НОВОСИБИРСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
Кафедра Вычислительной Техники
Курсовая работа по дисциплине «Программирование»
Выполнил: Милюков Олег Факультет: АВТ Группа: АБ-521 | Проверил: преподаватель |
Новосибирск 2007
Cодержание
Задание 4
Введение 5
Теоретический материал. 6
Структурное описание разработки. 8
Этап 1. Создание html-текста. 9
Этап 2. Чтение файла, с последующей «обработкой» слов. 9
Этап 3. Создание словаря. 11
Функциональное описание программы.. 12
Описание работы программы на контрольном примере 16
Заключение 17
Список литературы.. 18
Приложение 19
Задание
Лексический контроль текста. При чтении очередного слова с него «снимаются» окончания, а затем суффиксы. Полученная основа ищется в упорядоченном словаре и при ее отсутствии добавляется в словарь. Сам словарь хранится в виде отдельного файла *.htm, при этом основы являются ссылками на абзацы, где встречаются слова, из которых они получены.
Введение
Лексический контроль текста требует наряду со знаниями в области информатики еще и представление о словообразовании в русском языке.
В программе должны быть использованы различные структуры данных. Сама тема — форматирование текстового файла — предполагает работу с файловым вводом-выводом, а именно: чтение, создание и изменение текстового файла.
Из всего вышесказанного можно сделать вывод, что для реализации задания придется использовать все знания, полученные нами до настоящего момента.
Структурное описание разработки
Программа, осуществляющая лексический контроль текста, может быть представлена схематически следующим образом.
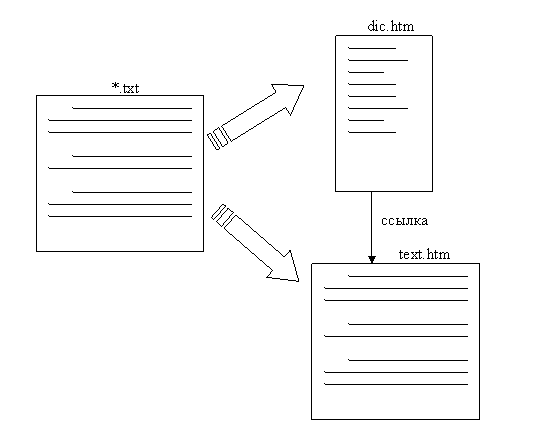

Как видно из рисунка, задача состоит в том, чтобы получить из исходного txt-файла два html-документа, связанных между собой ссылками. Один html-файл (словарь) дожжен содержать список основ слов, которые бы являлись ссылками на абзацы исходного текста, содержащегося во втором html-файле.
Условно процесс выполнения программы можно разбить на 3 этапа:
· создание html-документа с исходным текстом;
· чтение txt-файла и «обработка» слов;
· создание словаря.
Рассмотрим каждый из вышеуказанных этапов подробнее.
Этап 1. Создание html-текста
Переписывать текст обрабатываемого файла в html нужно в первую очередь для того, чтобы поставить метки перед каждым абзацем, а также для последующей связи с файлом-словарем.
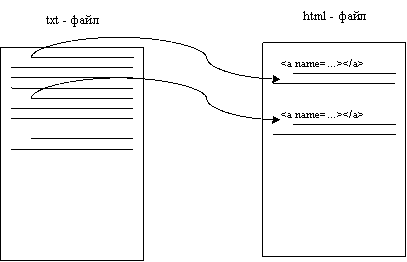
Текст, переносимый из одного файла в другой, никоим образом не изменяется. Только лишь каждый новый абзац предваряется тегом, содержащим метку, соответствующую номеру этого абзаца.
Этап 2. Чтение файла, с последующей «обработкой» слов.
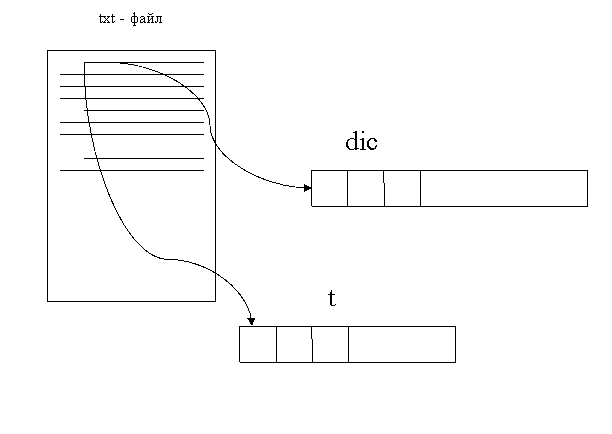 |
Как можно видеть из рисунка, на данном этапе происходит считывание слова из файла его в Collection<String> dic, а в Collection<Integer>помещается номер абзаца, где встретилось данное слово.
Но процессу запоминания самого слова и его позиции предшествуют манипуляции над морфемами вышеозначенного слова. И в итоге, основа слова будет помещена в Collection<String> out_col.
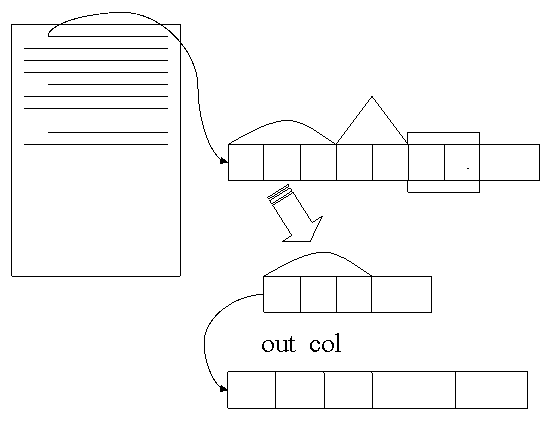 |
Русский язык очень сложен. В нем существует множество правил и еще больше исключений из этих правил. В словообразовании тоже есть свои «нюансы». Есть множество таких сочетаний букв, которые в одном случае могут относиться к одной морфеме, в другом случае к иной. Также стоит отметить, что в настоящее время стало употребляться очень много зарубежных слов и неологизмов.
Следует сразу отметить, что данная программа обрабатывает так называемые типовые, самые распространенные суффиксы и окончания, которые описаны в справочниках по словообразованию и правописанию.
Этап 3. Создание словаря
На предыдущих этапах были выполнены все необходимые действия, манипуляции с файлами и словами. Осталось только создание самого словаря. Чтобы словарь был упорядоченным, предварительно производится сортировка класса-коллекции out_col.
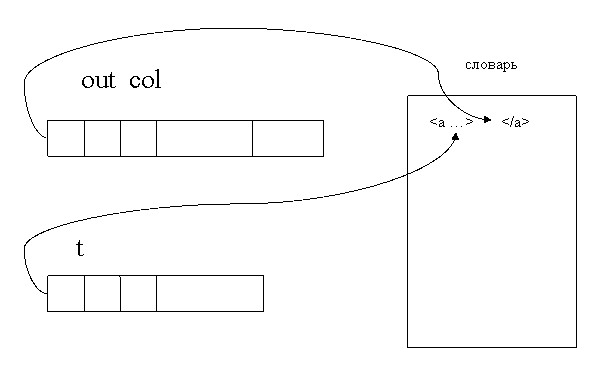

Словарь должен представлять собой набор основ-ссылок на абзацы исходного текста. Для воплощения этого в жизнь, каждая очередная основа записывается внутрь тега, в котором уже стоит номер абзаца, на который нужно сослаться.
Функциональное описание программы
Класс MyDict
Метод создания html-файла с исходным текстом.
Функция Create_html_text() необходима для записи текста, содержащегося в исходном файле, в html-документ и установки меток перед каждым абзацем.
void Create_html_text(String f) throws IOException
{
Входным параметром функция получает имя файла, который ей нужно обработать.
В только что созданный файл записывается первый тег-метка с номером абзаца
(fprintf(fp,"<p><a name=0></a>")).
Исходный файл читается построчно, после каждой записанной строки в новом файле перед абзацем ставится метка и счетчик абзацев “i” увеличивается на единицу Результат выполнения функции — html-документ, содержащий текст исходного файла с необходимыми метками на каждом абзаце.
Метод чтения и обработки слов исходного текста.
void Read(String f) throws IOException
{
Входным параметром функция получает имя файла, над которым она должна произвести все описанные ниже действия.
Пока не достигнут конец файла, из него считывается по строке s и к ней добавляется символ конца строки, при этом на каждом шаге цикла s – это текущая считанная строка из файла. Все считанные строки объединяются в одну строку ss. Одновременно с этим контролируется появление символа перехода на новую строку.
while (s!=null)
{
s=in. readLine();
if(s!=null) ss+=s + "\n";
}
Затем наша строка делится на слова посредством создания объекта класса StringTokenizer T=new StringTokenizer(ss," "), который делит строку в цикле на части между разделителями
« ».
while(T. hasMoreTokens())
{
css. add(T. nextToken() + " ");
}
Каждое считанное слово заносится в объект класса-коллекции Collection<String> css.
Затем по циклу над каждым словом (элементом объекта класса-коллекции) производятся необходимые манипуляции.
Если считанное слово содержит цифры (if(Digit(s))) или латинских буквы (if(Latin(s))), то никаких действий не происходит и чтение продолжается дальше.
В противном случае от слова отбрасываются знаки препинания (если таковые имеются)(Zpt(s)). Далее, со слова «снимаются» окончания и суффиксы, заглавные буквы заменяются строчными. Полученная основа заносится в ещё один объект класса-коллекции Collection<String> dic. Параллельно с этим в ещё один объект класса-коллекции заносится номер абзаца, в котором встретилось слово, основа которого была снята только что:
t. add(cnt);
Также для каждого слова в коллекции осуществляется проверка того, не встречалось ли уже это слово ранее.
}
Метод создания словаря.
void Write()
{
Создается html-файл и в него, из уже упорядоченного объекта класса-коллекции out_col записываются слова, предварительно обрамляемые тегами ссылки:
out_col. add(("<a href=text. htm#" + tt. charAt(i) + ">" + word + "</a><br>"));
где tt – преобразованный в строку с удалением разделителей объект класса-коллекции t
}
Методы удаления окончаний и суффиксов.
В массивах fin[] и suf[] содержаться только наборы букв, составляющих окончания и суффиксы, а также знак «пробел» на конце, чтобы их можно было искать как подстроку в слове, к которому в конец предвариетлньо записывается пробел. Del_end() и Del_suffix() «отрубают» от слова окончание и суффикс соответственно.
Конструктор класса
MyDict()
{
f ="";
Строка f – строка, куда будет записываться название входного файла у каждого объеката класса MyDict
}
Класс MyFrame
В начале мы создаём объект класса MyDict, а также объявляем текстовые поля на фрейме:
MyDict X=new MyDict();
TextField tf_file1, tf_file2;
TextArea ta;
Затем следует конструктор данного класса:
MyFrame(String s)
{
Входным параметром является строка, которая будет заголовком окна после вызова конструктора super(s).
Затем мы создаём необходимые кнопки и текстовые поля на фрейме, задаём их координаты и размеры, а также указываем что они могут создавать объект класса ActionListener.
Затем следует создание меню с выпадающими элементами. Каждому элементу меню присваивается своё действие, а также горячая клавиша (HotKey). Все возможные действия от объектов рассматриваются в методе public void actionPerformed (ActionEvent ae).
Затем вызывается метод main(String[] args), в котором создаётся объект класс MyFrame, т. е. основное окно. Затем следует ещё один класс - public class About implements ActionListener, в котором создаётся объект класса FrameAbout.
}
Класс FrameAbout
Класс, служащий для создания окна «О программе» , в котором указана информация о курсовой работе, выполненный вариант.

Описание работы программы на контрольном примере
Рассмотрим время работы программы на файлах определенного объема.
Возьмем небольшой текстовый файл «весом» 3 kb, содержащий 6 строк. Время, которое затрачивает программа на обработку этого файла — меньше секунды (![]() 0,219). Полученный словарь содержит 701 слово и занимает 17,5 kb.
0,219). Полученный словарь содержит 701 слово и занимает 17,5 kb.
Теперь посмотрим на результаты, полученные при обработке большого файла.
Входной txt-файл имеет размер 650 kb и содержит 11603 строки.
На обработку файла такого размера уходит ![]() 40с. Получившийся словарь содержит 12500 основ слов. Размер файла-словаря — 460 kb.
40с. Получившийся словарь содержит 12500 основ слов. Размер файла-словаря — 460 kb.
Следует отметить, что большие объемы получающихся словарей связаны не только с размерами исходных текстов, но еще и с тем, что каждое слово, содержащееся в словаре, является гиперссылкой на абзац исходного текста.
Так же стоит обратить внимание на то, что часть времени выполнения программы тратится переписывание исходного текста в html-документ.
Заключение
В данной работе нам потребовались знания не только по программированию, но и по русскому языку.
В процессе создания файла-словаря нам пришлось использовать язык разметки гипертекста HTML.
Достоинство данной разработки состоит в том, что можно довольно быстро получить список основ слов, употребляемых в каком-либо тексте, в виде отдельного файла, содержащего ссылки на исходный текст.
Недостатком можно считать (и об этом уже говорилось ранее) невозможность рассмотреть все виды окончаний и суффиксов. Но все же, в этой программе рассмотрены случаи, которые чаще всего можно встретить.
Список литературы
1. Розенталь по правописанию и литературной правке. — М.: Рольф, 1996.
2. Программирование на языке JAVA в электронном враианте
3. , . Программирование на Java.
Приложение
Класс MyDict
import java. io.*;
import java. util.*;
import java. util. Collection;
import java. util. regex. PatternSyntaxException;
///////////////////////////////////////////////////////////
