

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Глава 2. Искусственные нейронные сети
1. Искусственный нейрон: идея и реализация
2. Однонаправленные многослойные сети и алгоритм обратного
распространения ошибки
3. Градиентные методы обучения. Метод наискорейшего спуска
4. Радиальные нейронные сети
5. Сети Хопфилда
6. Сети Хэмминга
7. Сети Кохонена
8. Авторезонансные сети
1. Искусственный нейрон: идея и реализация
Биологические основы функционирования нейрона (нервной клетки) изложены нами в предыдущей главе. В математической модели нейрона, входные сигналы должны умножаться на численные коэффициенты (веса).
Математическая модель нейронаь представляет собой некоторый абстрактный элемент, имеющий несколько входов и один выход. Структурная модель представлена на рис. 1. На вход ![]() -го нейрона подается
-го нейрона подается ![]() входных сигналов
входных сигналов ![]() . Далее они суммируются с некоторыми весами
. Далее они суммируются с некоторыми весами ![]() , и к результату добавляется постоянная смещения
, и к результату добавляется постоянная смещения ![]() :
:

Рис. 1. Структурная модель искусственного нейрона
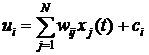 (1)
(1)
Для получения значения ![]() на выходе нейрона вычисляется функция f(u) – функция активации. Она имеет сигмообразный вид:
на выходе нейрона вычисляется функция f(u) – функция активации. Она имеет сигмообразный вид:
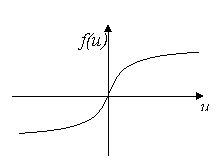
Рис.2. Характерный ыид функции отклика
В модели персептрона (МакКаллона-Питса)
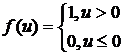 (2)
(2)
Для нейронов сигмоидального типа функцию отклика чаще всего выбирают в виде униполярной функции
![]() (3)
(3)
Её график представлен на рис. 3
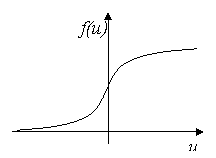

Рис.3. График униполярной функции
Часто используют также биполярную функцию
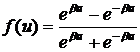 . (4)
. (4)
Её график представлен на рис. 4.
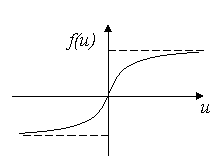

Рис. 4. График биполярной функции
Чаще всего на практике принимают ![]() . Важным свойством сигмоидальной функции является ее дифференцируемость и простое выражение для ее производной. Для униполярной функции
. Важным свойством сигмоидальной функции является ее дифференцируемость и простое выражение для ее производной. Для униполярной функции
![]() . (5)
. (5)
Для биполярной функции
![]() . (6)
. (6)
Все особенности нейронных сетей заключаются в их структуре. Соединяя между собой нейроны можно получить сеть, способную отображать сложную структуру данных.
Фактически для решения большинства задач оказывается достаточно трехслойных нейросетей. Первый слой нейронов в сети называется входным, последний – выходным. На вход подаются некоторые известные сигналы, а на выходе ожидается получение некоторого ожидаемого выходного сигнала. При этом система модифицирует свои параметры по мере предъявления ей новых примеров с тем, чтобы наиболее точно воспроизводить выходной сигнал. Такое обучение системы называется обучением с учителем. Возможно и обучение без учителя, когда нейросети просто предъявляются разные примеры данных. Мы остановимся вначале и главным образом на обучении с учителем.
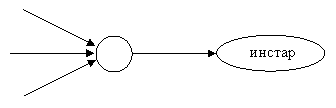

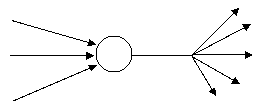
 Аутстар
Аутстар
Рис.7. Варианты нейронов
Представимость непрерывных отображений на основе трехслойной нейросети является следствием теоремы Колмогорова-Арнольда о представимости функции многих переменных в виде суперпозиции и сумм функций одного переменного.
2. Многослойные нейронные сети и алгоритм обратного
распространения ошибки
Важнейшим для реализации нейронных сетей является определение алгоритма обучения сети. Хотя основные идеи нейронных сетей были развиты еше Розенблютом в конце сороковых годов, именно отсутствие эффективных методов обучения нейронных сетей тормозило их развитие и применение.
В настоящее время одним из самых эффективных и обоснованных методов облучения нейронных сетей является алгоритм обратного распространения ошибки, который применим только к однонаправленным многослойным сетям. В многослойных нейронных сетях имеется множество скрытых нейронов, входы и выходы которых не являются входами и выходами нейронной сети., а соединяют нейроны внутри сети - это скрытые нейроны.
Занумеруем выходы нейронной сети индексом 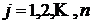 , а обучающие примеры индексом
, а обучающие примеры индексом ![]() . Тогда в качестве целевой функции можно выбрать функцию ошибки как сумму квадратов расстояний между реальными выходными состояниями
. Тогда в качестве целевой функции можно выбрать функцию ошибки как сумму квадратов расстояний между реальными выходными состояниями ![]() нейронной сети на примерах и правильными значениями
нейронной сети на примерах и правильными значениями ![]() , соответствующими примерам. Пусть
, соответствующими примерам. Пусть 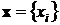 – столбец входных значений, где i=1,2,..,n. Тогда
– столбец входных значений, где i=1,2,..,n. Тогда 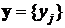 – выходные значения, где j=1,2,…,m. В общем случае n≠m. Рассмотрим разность
– выходные значения, где j=1,2,…,m. В общем случае n≠m. Рассмотрим разность 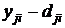 , где
, где ![]() – точное значение. Эта разность должна быть минимальна. Введем расстояния согласно евклидовой метрике, определив норму
– точное значение. Эта разность должна быть минимальна. Введем расстояния согласно евклидовой метрике, определив норму
![]() . (1)
. (1)
Пусть целевая функция имеет вид
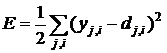 . (2)
. (2)
Задача обучения нейронной сети состоит в том, чтобы найти такие коэффициенты ![]() , чтобы достигался минимум Е (Е
, чтобы достигался минимум Е (Е![]() 0). Обозначим q – номер слоя нейронной сети, Q – выходной слой.
0). Обозначим q – номер слоя нейронной сети, Q – выходной слой.
Для простоты индексации рассмотрим случай, когда на вход подается только один пример, тогда
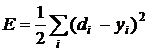 . (3)
. (3)


Рис.8. Схема связей между нейронами слоя ![]() и слоя в сети
и слоя в сети ![]() прямого распространения
прямого распространения
Найдем производную:
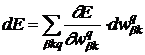 . (4)
. (4)
Необходимы такие ![]() чтобы
чтобы ![]() <0:
<0:
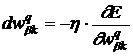 , (5)
, (5)
где ![]() >0. Тогда
>0. Тогда
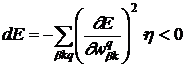 . (6)
. (6)
Выходное значение каждого слоя определяется функцией активации.
Для выходного слоя:
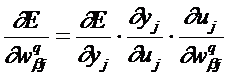 , (7)
, (7)
где ![]() =
=![]() , а
, а 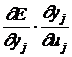 =
= ![]()
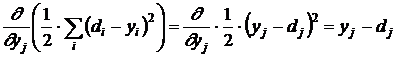 . (8)
. (8)
Производная ![]() дает
дает ![]() , где q – номер слоя,
, где q – номер слоя, ![]() - входной слой.
- входной слой.
Перейдем к переменным следующего слоя:
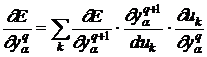 . (9)
. (9)
Умножим обе части на ![]() :
:
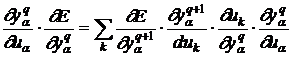 (10)
(10)
и далее обозначим
![]() =
=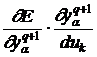 , (11)
, (11)
а
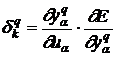 . (12)
. (12)
Тогда получим
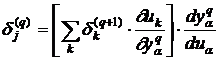 . (13)
. (13)
Для униполярной функции активации
![]() (14)
(14)
параметры вычисляются в соответствии с формулами
![]()
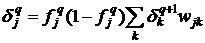 , (15)
, (15)
где ![]() - правильное значение на выходе слоя. При этом
- правильное значение на выходе слоя. При этом
![]() . (16)
. (16)
Приведем алгоритм вычисления весов нейронов в соответствии с методом обратного распространения ошибки:
Шаг 1. Подать на входы сети один из примеров и вычислить все значения в сети от входа к выходу.
Шаг 2. Рассчитать δQ.
Шаг 3. Рассчитать δq и ![]() wq.
wq.
Шаг 4. 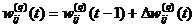 , где t – номер шага.
, где t – номер шага.
Шаг 5. Если ошибка сети существенна (мы сравниваем контрольный результат и то, что получили), то переходим к шагу 1. Иначе обучение прекращается.
Для лучшей сходимости предпочтительно примеры подавать вразбивку.
Формулы, задающие порядок вычислений в соответствии с описанным алгоритмом имеют вид:
![]() ,
,
![]() ,
,
где j – номер нейрона.
![]() ,
,
![]() .
.
Для двухслойной сети с тремя нейронами, показанной на рис.9:
![]() ,
,
![]() ,
,
![]() .
.


Рис.9. Двухслойная нейронная сеть прямого распространения
Искусственные нейронные сети прямого распространения весьма популярны в практических приложениях, поскольку имеют простую и наглядную структуру, способны решать довольно сложные задачи и имеют простые и эффективные алгоритмы обучения, в первую очередь алгоритм обратного распространения ошибки.
3. Градиентные методы обучения. Метод наискорейшего спуска
Задача: наикратчайшим способом спуститься в долину. ![]() - вектор весов. Рассмотрим двумерный случай, т. е. пусть существуют веса w1, w2 , тогда E=1/2(y-d)2
- вектор весов. Рассмотрим двумерный случай, т. е. пусть существуют веса w1, w2 , тогда E=1/2(y-d)2
Надо идти по линии максимальной крутизны. (для одной переменной - по касательной)
Надо построить перпендикуляр к линии уровня, а это градиент.
В окрестности некоторой точки разложим целевую функцию в ряд Тейлора:
![]()
![]()
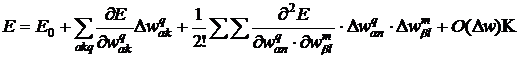 . (23)
. (23)
![]()
 i j
i j
Введем обозначения
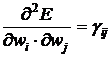 , (24)
, (24)
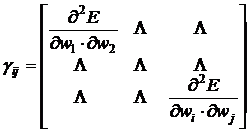 . (25)
. (25)
Все частные производные =0, а det может быть любым:
1) det![]() =0 – это точка перегиба (седло, перевал).
=0 – это точка перегиба (седло, перевал).
2) det![]() >0 – точка минимума,
>0 – точка минимума,
3) det![]() <0 – точка максимума.
<0 – точка максимума.
Возьмем разложение функции в достаточно малой окрестности, а остальные слагаемые ряда отбросим.
В градиентном методе мы отбрасываем все, кроме первой поправкик значению функции:
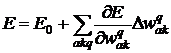 . (26)
. (26)
Дадим приращение весам
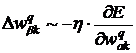 . (27)
. (27)
Здесь 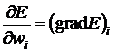 , то есть
, то есть ![]() является компонентой градиента.
является компонентой градиента.
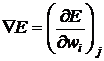 . (28)
. (28)
Отличие: раньше вычисляли аналитически при помощи выражения для производной, а теперь – численно: даем приращение ![]() и находим:
и находим: 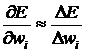 . Это один из самых распространенных методов, он основан на определении величины производной.
. Это один из самых распространенных методов, он основан на определении величины производной.
Трудности:
1. Если использовать большой шаг при спуске, то будет происходить колебание вокруг точки минимума.
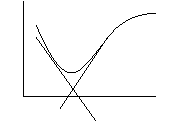

2. В точке перегиба ![]() =0, поэтому обучение прекратиться, не достигнув минимума.
=0, поэтому обучение прекратиться, не достигнув минимума.
Чтобы этого избежать используют метод моментов.
Необходимо придать моменту некоторую инерцию, поэтому вводим коэффициент:
![]()
к ![]() , α должно быть порядка 4%.
, α должно быть порядка 4%.
Это позволяет проскочить «плато».
3. Проблема локального минимума.
Нужны новые начальные данные. Существует алгоритм случайного блуждания.
4. Радиальные нейронные сети
Возможность построения радиальных нейронных сетей достаточно очевидна из свойств δ-функции Дирака:
![]() . (1)
. (1)
Тем самым значение функции в данной точке выражается через сумму данных о функции во всех точках.
Это точное равенство в ослабленном виде может выть записана как приближенное
![]() , (2)
, (2)
где теперь 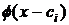 уже не δ - функции, а гауссовские функции.
уже не δ - функции, а гауссовские функции.
Тем самым простейшая нейронная сеть радиального типа функционирует по принципу многомерной интерполяции, состоящей в отображении p различных входных векторов ![]() (i=1,2,…,p) из входного N-мерного пространства во множество из p рациональных чисел di (i=1,2,…,p). Для реализации этого процесса необходимо использовать p скрытых нейронов радиального типа и задать такую функцию отображения
(i=1,2,…,p) из входного N-мерного пространства во множество из p рациональных чисел di (i=1,2,…,p). Для реализации этого процесса необходимо использовать p скрытых нейронов радиального типа и задать такую функцию отображения ![]() , для которой выполняется условие интерполяции
, для которой выполняется условие интерполяции
![]() . (3)
. (3)
Рассмотрим радиальную сеть с одним выходом и p обучающими параметрами (![]() ,di). Примем, что координаты каждого из p центров узлов сети определяются одним из векторов xi, то есть
,di). Примем, что координаты каждого из p центров узлов сети определяются одним из векторов xi, то есть ![]() . В этом случае взаимосвязь между входными и выходными сигналами сети может быть определена системой уравнений, линейных относительно весов
. В этом случае взаимосвязь между входными и выходными сигналами сети может быть определена системой уравнений, линейных относительно весов ![]() . В матричной форме она имеет вид:
. В матричной форме она имеет вид:
 , (4)
, (4)
где 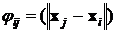 определяет радиальную функцию с центром в точке
определяет радиальную функцию с центром в точке ![]() с вынужденным вектором
с вынужденным вектором ![]() . Если обозначить матрицу
. Если обозначить матрицу ![]() как
как ![]() и ввести обозначения векторов
и ввести обозначения векторов ![]() и
и![]() , система уравнений (3) может быть представлена в редуцированной матричной форме
, система уравнений (3) может быть представлена в редуцированной матричной форме
![]()
![]() =
=![]() . (5)
. (5)
Доказано, что для ряда радиальных функций в случае ![]() квадратная интерполяционная матрица
квадратная интерполяционная матрица ![]() может быть обращена и уравнение имеет решение в виде:
может быть обращена и уравнение имеет решение в виде:
![]() =
=![]() , (6)
, (6)
что позволяет получить вектор весов выходного нейрона сети. Недостатком такого решения является адаптация при большом количестве обучающих выборок к различным шумам и нерегулярностям, сопровождающим обучающие выборки.
Как следствие, интерполирующая эти данные гиперповерхность не будет гладкой, а обобщающие возможности окажутся очень слабыми.
Главной проблемой обучения радиальных сетей остается подбор параметров нелинейных радиальных функций, особенно центров ![]() . Одним из простейших, хотя и не самым эффективным способом, является случайный выбор. В этом решении центры
. Одним из простейших, хотя и не самым эффективным способом, является случайный выбор. В этом решении центры ![]() базисных функций выбираются случайным образом на основе равномерного распределения. Такой подход допустим применительно к классическим радиальным сетям при условии, что равномерное распределение обучающих данных хорошо соответствует специфике задачи.
базисных функций выбираются случайным образом на основе равномерного распределения. Такой подход допустим применительно к классическим радиальным сетям при условии, что равномерное распределение обучающих данных хорошо соответствует специфике задачи.
При выборе гауссовской формы радиальной функции
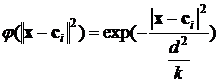 , (7)
, (7)
для i=1,2,…,k, где d обозначает максимальное расстояние между центрами ![]() . Ширина функции
. Ширина функции ![]() пропорциональна максимальному разбросу центров и уменьшается с ростом их количества.
пропорциональна максимальному разбросу центров и уменьшается с ростом их количества.
Неплохие результаты можно получить при использовании алгоритма самоорганизации. Данные группируются внутри кластера и представляются центральной точкой, определяющей среднее значение всех элементов этого кластера. Центр кластера в дальнейшем принимается за центр соответствующей радиальной функции. По этой причине количество радиальных функций равно количеству кластеров и может корректироваться алгоритмам самоорганизации.
Если обучающие данные представляют непрерывную функцию, начальные значения центров в первую очередь размещают в точках, соответствующих всем максимальным и минимальным значениям функции. Данные об этих центрах и их ближайшем окружении впоследствии убирают из обучающего множества, а оставшиеся центры равномерно распределяются в множестве, образованными оставшимися элементами.
В ходе обучения после предъявления k-ого вектора ![]() , принадлежащего обучающему множеству, выбирается центр, ближайший к
, принадлежащего обучающему множеству, выбирается центр, ближайший к ![]() , относительно применяемой метрики. Этот центр подвергается уточнению в соответствии с алгоритмом
, относительно применяемой метрики. Этот центр подвергается уточнению в соответствии с алгоритмом
![]() , (8)
, (8)
то есть центр радиальной функции смещается в направлении вектора обучающего примера, η - коэффициент обучения, имеющий малое значение (обычно η<<1), при чем он уменьшается во времени. Существуют и иные алгоритмы определения центров. Однако ни один алгоритм не гарантирует абсолютную сходимость к глобальному решению. Трудность заключается также в подборе коэффициента обучения η.
Чаще всего выбирается алгоритм
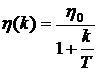 , (9)
, (9)
где T- постоянная времени, индивидуальная для каждой задачи.
5. Генетические алгоритмы
Идея генетических алгоритмов была предложена Холландом в 70-х годах XX в, а их интенсивное развитие и практическая реализация для численных оптимизационных расчетов были инициированы Гольдбергом. Эти алгоритмы имитируют процессы наследования свойств живыми организмами и генерируют последовательность новых векторов ![]() , содержащие оптимизированные переменные:
, содержащие оптимизированные переменные: 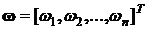 . При этом выполняются операции трех видов: селекция, скрещивание и мутация.
. При этом выполняются операции трех видов: селекция, скрещивание и мутация.
Отдельные компоненты вектора ![]() могут кодироваться в двоичной системе либо натуральными числами. После соответствующего масштабирования отдельные биты в двоичном представлении представляют конкретные значения параметров, подлежащих оптимизации. Каждому вектору
могут кодироваться в двоичной системе либо натуральными числами. После соответствующего масштабирования отдельные биты в двоичном представлении представляют конкретные значения параметров, подлежащих оптимизации. Каждому вектору ![]() сопоставляется определенное значение целевой функции. Генетические операции (селекция, скрещивание, мутация) выполняются для подбора таких значений переменных
сопоставляется определенное значение целевой функции. Генетические операции (селекция, скрещивание, мутация) выполняются для подбора таких значений переменных ![]() , вектора
, вектора ![]() , при которых максимизируется величина так называемой функции приспособленности (fitness function). Функция приспособленности
, при которых максимизируется величина так называемой функции приспособленности (fitness function). Функция приспособленности ![]() определяется через целевую функцию
определяется через целевую функцию ![]() путем ее инвертирования:
путем ее инвертирования: ![]() .
.
1. На начальной стадии вычисления генетического алгоритма инициируется определенная популяция хромосом (векторов ![]() ). Она формируется случайным образом, хотя применяются и самонаводящиеся способы (если их можно определить заранее). Размер популяции, как правило, пропорционален количеству оптимизируемых параметров. Слишком малая популяция хромосом приводит к замыканию в локальных неглубоких минимумах. Слишком большое их количество чрезмерно удлиняет вычислительную процедуру, а также может не привести к точке глобального минимума. При случайном выборе векторов
). Она формируется случайным образом, хотя применяются и самонаводящиеся способы (если их можно определить заранее). Размер популяции, как правило, пропорционален количеству оптимизируемых параметров. Слишком малая популяция хромосом приводит к замыканию в локальных неглубоких минимумах. Слишком большое их количество чрезмерно удлиняет вычислительную процедуру, а также может не привести к точке глобального минимума. При случайном выборе векторов ![]() , составляющих исходную популяцию хромосом, они статистически независимы и представляют собой погружение в пространство параметров. Хромосомы отбираются (подвергаются селекции) для формирования очередного поколения по значениям функции соответствия.
, составляющих исходную популяцию хромосом, они статистически независимы и представляют собой погружение в пространство параметров. Хромосомы отбираются (подвергаются селекции) для формирования очередного поколения по значениям функции соответствия.
Селекция хромосом для спаривания (необходимого для создания нового поколения) может основываться на различных принципах. Одним из наиболее распространенных считается принцип элитарности, в соответствии с которым наиболее приспособленные хромосомы сохраняются, а наихудшие отбрасываются и заменяются вновь созданным потомством, полученным в результате скрещивания пар родителей. На этапе скрещивания подбираются такие пары хромосом, потомство которых может быть включено в популяцию путем селекции.
Существует огромное количество методов спаривания, начиная от полностью случайного (как правило, среди наиболее приспособленных хромосом), через взвешенно-случайное спаривание, и вплоть до так называемой турнирной системы. В последнем случае случайным образом отбирается несколько хромосом, среди которых определяются наиболее приспособленные (с наименьшим значением целевой функции). Из победителей последовательно проведенных турниров формируется пара для скрещивания.
При взвешенно-случайной системе в процессе отбора вероятность выбора хромосомы делается пропорциональной величине ее относительной функции приспособленности.
2. Процесс скрещивания основан на рассечении пары хромосом на две части с последующим обменом этих частей в хромосомах родителей (кроссинговер). Место рассечения также выбирается случайным образом. Количество новых потомков равно количеству отбракованных в результате селекции. После их добавления к оставшимся хромосомам размер популяции остается неизменным.
3. Последняя генетическая операция – это мутация, состоящая в замене значений отдельных битов (при двоичном кодировании) на противоположные. Мутация обеспечивает защиту как от слишком раннего завершения алгоритма (в случае выравнивания значений хромосом и целевой функции), так и от представления в какой-либо позиции всех хромосом одного и того же значения. Однако необходимо иметь в виду, что случайные мутации приводят к повреждению уже частично приспособленных векторов. Обычно мутации подвергается не более 1-5% бит всей популяции хромосом. Как и при выполнении большинства генетических операций, элемент, подвергаемый мутации, отбирается случайным образом.
Доказано, что генетический алгоритм почти монотонно улучшает приспособленность (в среднем). Алгоритм останавливается по завершении максимального числа итераций или в результате достижения требуемой точности. Хорошие результаты обучения приносит объединение алгоритмов глобальной оптимизации с детерминированными методами – сначала генетический алгоритм, а затем градиент.
6. Сети Хопфилда
Американский исследователь Хопфилд в 80-х гдах 20-го века предложил специальный тип нейросетей. Названные в его честь сети Хопфилда являются рекуррентными или сетями с обратными связями и были предназначены для распознавания образов. Обобщенная структура этой сети представляется, как правило, в виде системы с обратной связью выхода со входом. Сеть Хопфилда является однослойной.
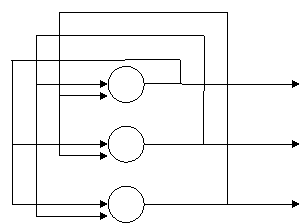

Рис.1
Характерная особенность такой системы состоит в том, что входные сигналы нейронов являются одновременно входными сигналами сети: xi(k)=yi(k-1), при этом возбуждающий вектор особо не выделяется. В классической системе Хопфилда отсутствует связь нейрона с собственным выходом, что соответствует wij=0 , а матрица весов является симметричной: wij=wji
![]() . (1)
. (1)
Симметричность матрицы весов гарантирует сходимость процесса обучения. Процесс обучения сети формирует зоны притяжения некоторых точек равновесия, соответствующих обучающим данным. При использовании ассоциативной памяти мы имеем дело с обучающим вектором ![]() , либо с множеством этих векторов, которые в результате проводимого обучения определяют расположение конкретных точек притяжения (аттракторов)
, либо с множеством этих векторов, которые в результате проводимого обучения определяют расположение конкретных точек притяжения (аттракторов)
Будем предполагать, что каждый нейрон имеет функцию активации сигнум со значениями ![]() :
:
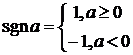 . (2)
. (2)
Это означает, что выходной сигнал i-го нейрона определяется функцией
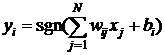 , (3)
, (3)
где N обозначает количество нейронов, N=n. Для упрощения дальнейших рассуждений предположим, что постоянная составляющая bi, определяющая порог срабатывания отдельных нейронов, равна 0. Тогда циклическое прохождение сигнала в сети Хопфилда можно представить соотношением
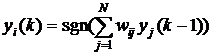 (4)
(4)
с начальным условием ![]() .
.
В процессе функционирования сети Хопфилда можно выделить два режима: обучения и классификации. В режиме обучения на основе известных обучающих выборок ![]() подбираются весовые коэффициенты wij.
подбираются весовые коэффициенты wij.
В режиме классификации при зафиксированных значениях весов и вводе конкретного начального состояния нейронов ![]() возникает переходный процесс, протекающий в соответствии с выражением (2) и заканчивающийся в одном из локальных минимумов, для которого
возникает переходный процесс, протекающий в соответствии с выражением (2) и заканчивающийся в одном из локальных минимумов, для которого ![]()
Обучение не носит рекуррентного характера. Достаточно ввести значения (правило Хебба)
![]() , (5)
, (5)
Поскольку
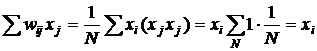 , (6)
, (6)
Так как вследствие биполярности значений элементов вектора ![]() всегда
всегда 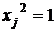 .
.
При вводе большого количества обучающих выборок x(k) для k=1,2,…,p веса wij подбираются согласно обобщенному правилу Хебба в соответствии с которым
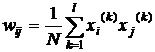 . (7)
. (7)
Благодаря такому режиму обучения веса принимают значения, определяемые усреднением множества обучаемых выборок. В случае множества обучаемых выборок актуальным становится вопрос о стабильности ассоциативной памяти.
Сети Хопфилда также относятся к классу сетей, которые могут быть описаны в терминах «энергии» сети. В такой интерпретации запомненные образы соответствуют локальным минимумам энергетической поверхности.
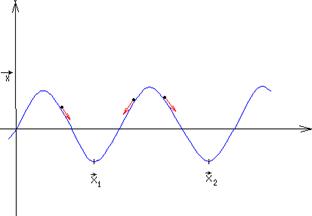
Рис.2
Если шарик с трением начнет движение вблизи соответствующего минимума, то он остановиться в локальном минимуме, соответствующем ближайшему образу в обучающей выборке. Для сети Хопфилда «энергия» взаимодействия пары узлов
![]() . (8)
. (8)
Энергия сети может быть найдена как сумма по всем парам узлов:
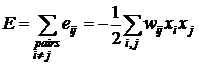 . (9)
. (9)
Коэффициент ½ учитывает, что каждая пара присутствует в сумме дважды как wijxixj и как wijxjxi, а также, что wij=wji, wii=0 . Рассмотрим теперь изменение энергии при изменении значения входа k-го узла. Выделим в полной энергии E соответствующее слагаемое:
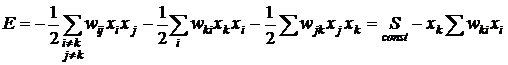 . (10)
. (10)
Иными словами
![]() , (11)
, (11)
где 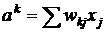 - аргумент функции активации.
- аргумент функции активации.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
