Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Стандартные действия, процедуры и функции для работы со строками и символами.
Действие, процедура, функция | Действие | Пример |
s:=m+s; | Объединение двух строк в одну. | s := '123' + '456'; s:=slovo_1+slovo_2; |
k:=Ord ('c') | Функция Ord возвращает код символа. | k := Ord('1'); {результат - k:=49} |
c:=Chr (k) | Функция Chr возвращает символ по его коду k. | c := Chr(49); {результат - c:=3} |
n := Length(s); | Записать длину строки s в целую переменную n. | n := Length(s); |
s1 := Copy(s, k, m); | Записать в символьную строку s1 подстроку строки s, которая начинается с символа с номером k и состоит из m символов. | s1 := Copy(s, 1, 10); |
n := Pos('s1', s); | Записать в целую переменную n номер символа, с которого в строке s начинается подстрока s1 (если ее нет, в переменную n записывается 0) (так же можно искать отдельные символы). | n := Pos('задача', s); |
n := StrToInt(s); | Преобразовать строку s в целое число и записать результат в переменную n. | n := StrToInt(s); |
Delete(s, k, m); | Удалить из строки s m символов, начиная с k-ого. | Delete(s, 3, 8); |
Insert(s1, s, k); | Вставить в строку s фрагмент s1, начиная с k-ого символа (между k-ым и (k+1)-ым). | Insert('Задача’, s, 3); |
Val(s, n, r); | Преобразовать строку s в целое число и записать результат в переменную n; если при этом произошла ошибка, в переменной r будет номер ошибочного символа, если все нормально – ноль. | Val(s, n, r); |
Обращение | Тип аргумента | Тип результата | Примечание |
Frac(x) | Real | Real | Дробная часть числа |
Int(x) | Real, integer | Real | Целая часть числа |
Round(x) | Real | Integer | Округление до ближайшего целого |
Trunc(x) | Real | Integer | Отбрасывание дробной части числа |
Алгоритм ввода, описание | Фрагмент программы |
Входная строка - символьная строка (cтроковый тип) Пример: Ihoiggu376xjk hjg+5. | |
Алгоритм ввода: считать всю строку целиком в некоторую переменную строкового типа и далее обрабатывать ее посимвольно. Данный способ позволяет обращаться к отдельному символу строки как к элементу массива – по его индексу (номеру), при этом номера символов в строке начинаются с единицы. | var str: string; i: integer; begin readln (str); i:=1; while str[i]<>’.’ do begin {обработка входной строки} i:=i+1; end; … |
Алгоритм ввода: читать исходные данные посимвольно и сразу их посимвольно обрабатывать. В данном случае оператор ввода символа встречается два раза: перед циклом и внутри цикла. Это сделано для того, чтобы избежать обработки завершающего символа (точки) внутри цикла, целиком «посвятив» его непосредственно преобразованию строки. | var c: char; begin read (c); while c<>’.’ do begin {обработка символа} read (c); end; … |
Входные строки состоят из значений различных типов или из подстрок с разбиением на слова по пробельным символам. Пример: Иванов 5 | |
Алгоритм ввода: если входные строки состоят из значений различных типов, то входную строку придется разбирать «вручную», используя тот факт, что элементы входных данных разделены, например, пробелами. | var name: string; c: char; a: integer; begin name :=’ ’; while c<>’ ’ do begin {чтение фамилии} read (c); name:= name+c; end; {чтение числа} read (a); … |
Алгоритм ввода: читаем строку и определяем, на каком месте стоит первый пробел в строке. Копируем часть строки до первого пробела в переменную name, затем удаляем из строки s, начиная с первого символа, все символы до первого пробела. Преобразуем в число оставшуюся часть строки. | var s, name: string; c: char; a: integer; begin readln(s); { определяем, на каком месте стоит первый пробел в строке} p := Pos(' ', s); name:=copy(s,1, p); { удаляем из строки s, начиная с первого символа, p символов} delete(s, 1, p); { в строке s осталось одно число, но оно объявлено как строка} { преобразуем строку s, в числовое представление a} val(s, a, r); … |
Входные данные имеют формат <Время чч. мм> Пример: 3.21 | |
Алгоритм ввода: считывается первый символ-цифра и находится число соответствующее данной цифре. Читаем второй символ. Если второй символ – цифра, то вычисляем час. Минуты задаются двумя знаками. Вычисляем минуты. Аргументом функции Ord является некоторый символ, а результатом –ASCII код этого символа. В коде ASCIIсимволы десятичных цифр расположены подряд от ‘0’ до’9’, поэтому значением выражения ord(c)-ord(‘0’) будет числовое значение цифры c. Операция in определяет, принадлежит ли элемент множеству. | var c: char; h: 0..23; m:0..59; begin {чтение первого символа} read (c); {h – число, равное значению первой цифры часов} h:=ord(c)-ord(‘0’); {чтение второго символа} read (c); if c in [‘0’..’9’] then begin h:=10*h+ord ( c ) - ord(‘0’); read (c); end; read (c); {m-число, равное значению первой цифры минут} m:=ord(c)-ord(‘0’); read (c); {вычисляем минуты} m:=10*m+ord ( c ) - ord(‘0’); … |
Входные данные имеют формат <Школьный класс> Пример: 10 a 1 б | |
Алгоритм ввода: в номере класса – одна или две цифры, поэтому проверяем 2-й считанный символ на принадлежность множеству цифр [‘0’..’9’]. Если он цифра, то предыдущий символ был числом десятков, анализируемый символ является цифрой, в которой хранится число единиц в номере класса. Следующий символ – литер класса.
| var c, letter: char; N:1..12; begin read(c); {N – число, равное значению первой цифры} N:=ord (c )-ord(‘0’); read(c); if c in [‘0’..’9’] then begin {вычисляем номер класса} N:=N*10+ ord (c )-ord(‘0’); read(c); end; letter:=c; |
Входные данные имеют формат <Дата дд. мм. гг> Пример: 21.04 | |
Алгоритм ввода: считывается первый символ-цифра и находится число соответствующее данной цифре. Читаем второй символ. Если второй символ – цифра, то вычисляем день. Месяц и год задаются двумя знаками. | var c: char; d:1..31; m:1..12; g:0..99; begin read(c); d:=ord(c)-ord(0); read(c); if c in ['0'..'9'] then begin d:=10*d+ord(c)-ord(0); read(c); end; read(c); m:=ord(c)-ord(0); read(c); if c in ['0'..'9'] then begin m:=10*m+ord(c)-ord(0); read(c); end; read(c); g:=ord(c)-ord(0); read(c); if c in ['0'..'9'] then begin g:=10*g+ord(c)-ord(0); read(c); end; ... |
I. Нахождение минимального (максимального) значения в данном массиве и количества элементов, равных ему, за однократный просмотр массива.
{Нахождение максимума в массиве и подсчет кол-ва максимальных значений
за один проход массива}
Const
N=10; // Размерность массива
Var
Arr: array [1..N] of integer;
i: integer; // Счётчик для цикла
max: integer; // Максимальное значение массива
KolMax: integer; // Счётчик максимальных эл.
Begin
// Заполнение массива случайными числами
Write('Исходный массив: ');
For i:=1 to N do
begin
arr[i]:= random(10);
Write(arr[i], ' ');
end;
Writeln();
max:=arr[1];
KolMax:=1;
For i:=2 to N do
Begin
if Arr[i]=max then
inc(KolMax);
if arr[i]>max then
begin
max:=arr[i];
KolMax:=1;
end;
end;
Writeln('Максимальное значение массива: ', max);
Writeln('Количество в массиве: ', KolMax);
End.
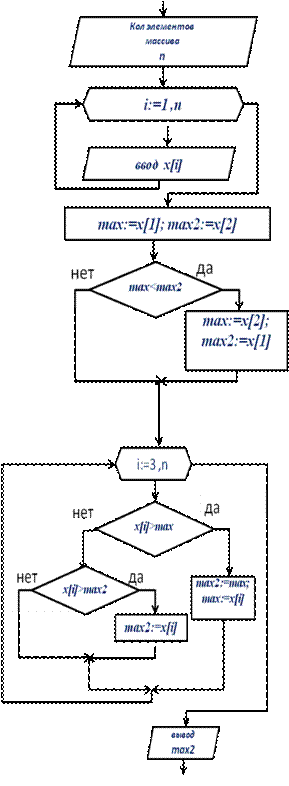
II. Нахождение второго по величине (второго максимального или второго минимального) значения в данном массиве за однократный просмотр массива.
• Вводим две переменные: первый и второй максимумы и задаем им начальные значения
• Перебираем все элементы массива и сравниваем их с максимумом:
– Если текущий элемент больше текущего максимума – значение максимума перекладываем в переменную второго максимума, а в максимум кладем значение текущего.
– Иначе – сравниваем текущий элемент со вторым максимумом. Если текущий больше – кладем его на место второго максимума.

var x: array [1..100] of real;
i, n: integer;
max, max2: real;
begin
read(n);
for i:=1 to n do
read(x[i]);
max:=x[1];
max2:=x[2];
if max < max2 then begin
max:= x[2];
max2 := x[1];
end;
for i := 3 to n do
if x[i] > max then
begin max2 := max; max := x[i] end
else if x[i] > max2 then
max2 := x[i];
writeln(max2);
end.
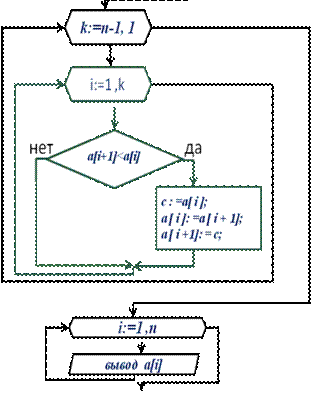
III. Сортировка элементов массива в порядке возрастания.
– Метод решения:
– Последовательно сравниваем все пары соседних элементов массива и, если значения элементов в паре стоят в неправильном порядке (правый меньше левого), то меняем их местами. В результате одного такого прохода по массиву самый большой элемент окажется на последней позиции.
– Всю процедуру повторяем столько раз, сколько элементов нужно поставить на нужное место. То есть n-1
var i, n, k: integer;
x: array [1..100] of real;
d: real;
begin
read (n);
for i:=1 to n do read (x[i]);
for k:=n-1 downto 1 do
for i:=1 to k do
if x[i+1]<x[i] then begin
d:=x[i];
x[i]:=x[i+1];
x[i+1]:=d;
end;
for i:=1 to n do
writeln(x[i]);
end.
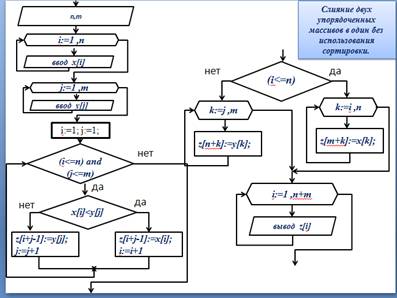
IV. Слияние двух упорядоченных массивов в один без использования сортировки.
– Введем две переменных - счетчика: i и j , каждый из которых изначально установим на начало первого и второго массивов соответственно.
– Сравниваем между собой элементы массивов, на которые «указывают» счетчики: x[i]<y[j] . Меньший из них записываем в результирующий массив и передвигаем на следующий элемент счетчик того массива, откуда был взят элемент.
– Так продолжаем до тех пор, пока один из массивов не закончится. После этого оставшуюся часть допишем в конец результирующего массива.
const n=3; m=2;
var x: array [1..n] of real;
y: array [1..m] of real;
z: array [1..n+m] of real;
i, j,k: integer;
begin
for i:=1 to n do read (x[i]);
for j:=1 to m do read (y[j]);
i:=1; j:=1;
while (i<=n) and (j<=m) do
if x[i]<y[j] then begin
z[i+j-1]:=x[i];
i:=i+1;
end
else begin
z[i+j-1]:=y[j];
j:=j+1;
end;
if i<=n then
for k:=i to n do z[m+k]:=x[k]
else
for k:=j to m do z[n+k]:=y[k];
for i:=1 to n+m do
writeln(z[i]);
end.
V. Подсчёт появления символа в строке
var c:char;
ch: array ['a'..'z'] of integer;
i:integer;
begin
repeat
read (c);
if c in['a'..'z'] then ch[c]:= ch[c]+1;
until c='#';
for c:='a' to 'z' do writeln (c, ch[c]);
end.
VI. Поиск подстроки внутри данной строки, и замена подстроки.
Во введенной строке заменить все вхождения подстроки 'ABC' на подстроки 'KLMNO'".
Program Str6;
Var
S : String;
A : Byte;
Begin
Writeln('Введите строку');
Readln(S);
While Pos('ABC',S)<>0 Do
Begin
A:= Pos('ABC',S);
Delete(S, A,3);
Insert('KLMNO',S, A)
End;
Writeln(S)
End.
Алгоритмы решения задач
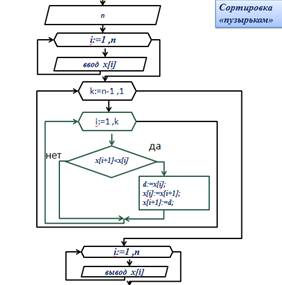
Сортировка пузырьком | |
Описание переменных: n – количество элементов a[i] – элемент массива c – буферная переменная n:integer; c, a[i]: real; Алгоритм решения задачи: Алгоритм состоит в повторяющихся проходах по сортируемому массиву. За каждый проход элементы последовательно сравниваются попарно и, если порядок в паре неверный, выполняется обмен элементов. Проходы по массиву повторяются до тех пор, пока на очередном проходе не окажется, что обмены больше не нужны, что означает — массив отсортирован. При проходе алгоритма, элемент, стоящий не на своём месте, «всплывает» до нужной позиции как пузырёк в воде, отсюда и название алгоритма. Количество проходов по массиву равно n-1, где n– это количество элементов массива. 1. Количество сравнений в каждом проходе равно n-k, где k – это номер прохода по массиву (первый, второй, третий и т. д.). 2. При обмене элементов массива обычно используется "буферная" (третья) переменная, куда временно помещается значение одного из элементов. |
|
Поиск значения, ближайшего по величине к максимуму (нахождение второго максимального элемента массива). | |
Описание переменных: n – количество элементов x[i] – элемент массива max, max2 – первый и второй максимумы n:integer; max, max2, x[i]: real; Алгоритм решения задачи:
Вводим две переменные: первый и второй максимумы и задаем им начальные значения. Перебираем все элементы массива и сравниваем их с максимумом: - Если значение рассматриваемого элемента больше значения текущего максимума, то значение максимума присваиваем второму максимуму, а максимуму присваиваем значение рассматриваемого элемента. - Иначе – сравниваем текущий элемент со вторым максимумом. Если элемент больше, то второму максимуму присваиваем значение рассматриваемого элемента.
|
|
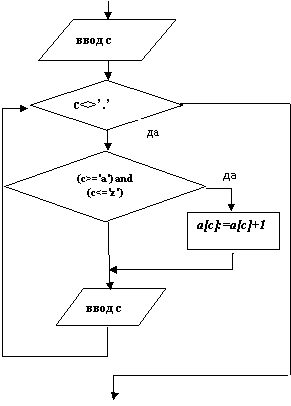
Подсчет частоты появления символа (буквы) в строке. | ||
Описание переменных: a[c]- частота появления символа c; c- символ в строке a[c]: integer; c: char; Алгоритм решения задачи: - вводим символ; - если символ является буквой, то увеличиваем счет этой буквы на 1; - повторяем действия 1-2, пока не будет введена «.».
|
| |
Поиск подстроки внутри данной строки, замена найденной подстроки на другую строку | ||
Описание переменных: s, – исходная строка, s_old - заменяемая подстрока, s_new вставляемая подстрока; i – номер символа строки, с которого начинается подстрока; l_old – длина заменяемой подстроки. Алгоритм решения задачи: 1. Ввести строку, подстроку, которую требуется заменить, и подстроку, которую требуется вставить на место прежней. 2. Найти место вхождения подстроки в строку с помощью функции pos(). 3. Удалить старую подстроку с помощью процедуры delete(). 4. Вставить новую подстроку, используя процедуру insert(). |
| |
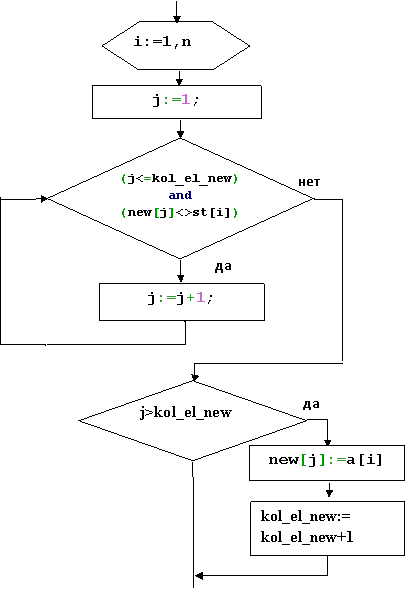
Составление «нового» списка без повторений из «старого», в котором есть одинаковые элементы. | ||
Описание переменных: n-количество элементов в «старом» списке; i-параметр в «старом» списке; kol_el_new- количество элементов в «новом» списке; j-параметр в «новом» списке; new[j] – элемент в «новом» списке; st[i]– элемент в «старом» списке; Алгоритм решения задачи: Берем элемент «старого» массива. Начинаем просмотр «нового» массива с первого элемента. Пока не дошли до конца «нового» массива или пока не нашли в «новом» массиве элемент, равный, элементу «старого» массива, переходим к новой строке в «новом» массиве. Если j>kol_el_new, то количество элементов в новом массиве увеличиваем на 1 и вносим элемент «старого» массива в «новый» массив. |
| |