


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РФ
НОВОСИБИРСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
КАФЕДРА ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ

Лабораторная работа №1
по дисциплине: «Параллельное программирование»
«Параллельное программирование для систем с общей памятью
с использованием технологии OpenMP»
Факультет: АВТФ
Группа: АВТ-918
Студенты: Кукарин :
Новосибирск, 2013
Цель работы
Изучить технологию OpenMP и основы разработки параллельных программ для многоядерных процессоров, написать и отладить на языке С параллельную программу для решения поставленной задачи на системе с общей памятью.
Задание
Найти наименьшее число n, большее заданного N, имеющее точно такое же количество различных делителей, какое имеет число n+1.
Описание алгоритма решения задачи
В данном программном продукте представлен метод релаксации переменных для решения систем линейных алгебраических уравнений.
Что же касается распараллеливания, то тут есть «подводные камни». Например, просто так распараллелить цикл не представляется возможным, т. к. внутри цикла используются массивы, память под которые выделена вне блока. Таким образом, параллельные потоки могут пройти по очереди по одному и тому же ряду массива, что приведет к неверному результату на выходе программы.
Для решения этой проблемы было решено направить каждый поток по своей строке. Например, если мы указали 3 потока, то каждый поток будет проходить по таким строкам:
0-й: строки 0, 3, 6 и т. д.
1-й: строки 1,4,7 и т. д.
2-й: строки 2, 5, 8 и т. д.
Так можно избежать прохода двух различных потоков по одному пути.
Результаты решения задачи
Поскольку данный метод, как и остальные итерационные методы, имеет ограничения на решаемые уравнения, генерация СЛАУ больших размерностей для наиболее наглядного представления является проблематичной. Была сгенерирована матрица А размерностью 8 на 8. В связи с этим счет времени выполнения программы идет не на секунды, а на тысячные доли секунды.
Укажем постоянное количество потоков. Пусть их будет 2.
Оценим скорость работы однопоточной программы.
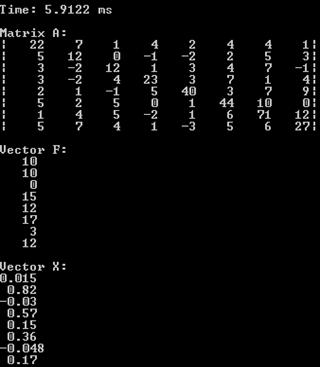
Рис. 1 Результаты работы последовательной программы
Целесообразно ожидать увеличение скорости работы программы в два раза при разбиении на два потока.
Однако, в связи с тем, что распараллеливаемый цикл является частью другого цикла, содержащего несколько сторонних методов, итоговое время выполнения алгоритма все же зависит не только от распараллеленного цикла. Поскольку наш цикл является наиболее емким (это будет заметно на матрицах сверхбольшой размерности), то его распараллеливание окажет значительное влияние на итоговое время. Можно в этом убедиться воочию:
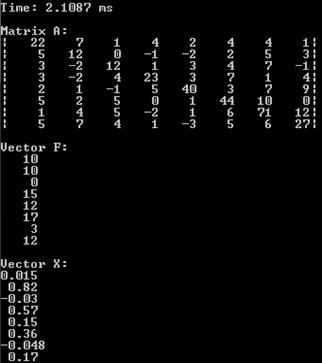
Рис. 2 Результаты работы многопоточной программы
Скорость выполнения как последовательной, так и распараллеленной программ варьируется и не остается постоянной с каждым новым запуском в связи с достаточно объемным алгоритмом, вызываемыми функциями внутри алгоритма и большим количеством обращений к памяти (в качестве массивов используются указатели).
В среднем скорость работы программы последовательной варьируется от 6 до 12 мс. При этом время программы с распараллеленным циклом варьируется от 3 до 7.
Ниже приведена таблица для оценки работы двух программ.
Однопоточная | Многопоточная | ||
Время (мс) | Вектор решений | Время (мс) | Вектор решений |
5.9122 | 0.015 | 2.1087 | 0.015 |
0.82 | 0.82 | ||
-0.03 | -0.03 | ||
0.57 | 0.57 | ||
0.15 | 0.15 | ||
0.36 | 0.36 | ||
-0.048 | -0.048 | ||
0.17 | 0.17 |
Результаты идентичны при очевидном ускорении. Это еще раз доказывает эффективность распараллеливания.
Так как сложно посчитать вручную решение данной СЛУ, оценим правильность работы программы на примере системы двух уравнений:
![]()
Очевидно, что ее решение (1, 2).
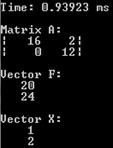
Рис. 3. Результаты работы программы на примере небольшой СЛУ
В результате программа выдала верное решение.
В итоге мы получили правильно работающую программу с увеличенной после распараллеливания скоростью вычисления.
Вывод
В результате выполнения лабораторной работы, мы познакомились с технологией OpenMP.
Написали программу, выполняющую поставленную задачу с помощью изученной технологии.
Оценивая данные, полученные при запуске программы, можно прийти к выводу, что грамотное использование технологии действительно позволяет увеличить скорость выполнения вычислений.
Листинг программы
Main.cpp – содержит основной код
#include <iostream>
#include <fstream>
#include <vector>
#include <math. h>
#include <time. h>
#include <omp. h>
using namespace std;
//функция поиска делителей числа и вывода их на экран
int divout(unsigned long long number)
{
unsigned long long n = 1;
int m = 0;
cout << "Number: " << number << '\n';
cout << "Dividers: ";
while (n!=number)
{
if (number%n==0)
{
cout << n << " ";
m++;
}
n++;
}
cout << "\nAmount of dividers: " << m << '\n';
return m;
}
int main()
{
//инициализация переменных
unsigned long long number;
unsigned long long nextnumber1;
unsigned long long nextnumber2;
unsigned long long n;
int p1 = 0;
int p2 = 0;
//запрашиваем число n
cout << "Enter your number:\n";
cin >> number;
//берём числа n+1 и n+2
nextnumber1 = number+1;
nextnumber2 = number+2;
//засекаем время
double wall_timer1 = omp_get_wtime();
//до тех пор, пока число делителей не равно
while ((p1!=p2) || (p1==0))
{
p1 = 0;
p2 = 0;
n = 1;
//ищем количество делителей
while(n!=nextnumber1)
{
//у первого числа
if (nextnumber1%n==0)
{
p1++;
}
//у второго числа
if (nextnumber2%n==0)
{
p2++;
}
n++;
}
//увеличиваем оба числа
nextnumber1++;
nextnumber2++;
}
//смотрим сколько прошло времени
double time1 = omp_get_wtime() - wall_timer1;
//выводим числа на экран
divout(nextnumber1-1);
divout(nextnumber2-1);
//выводим затраченное время
cout << "Consecutive execution time: " << time1 << '\n';
//закончили работу в последовательном режиме
//-----
//параллельный режим
nextnumber1 = number+1;
nextnumber2 = number+2;
unsigned long long nextnumber3 = number+2;
unsigned long long nextnumber4 = number+3;
//запрещаем создание новых потоков
omp_set_dynamic(0);
//выставляем кол-во потоков равное 2
omp_set_num_threads(2);
//засекаем время
double wall_timer2 = omp_get_wtime();
//входим в блок кода, подлежащий распараллеливанию
#pragma omp parallel private(p1,p2,n)
{
//инициализация переменных
p1 = 0;
p2 = 0;
n = 1;
//получаем номер потока
int r = omp_get_thread_num();
//если поток нулевой, то отрабатывают первые два числа
if(r==0)
{
while ((p1!=p2) || (p1==0))
{
p1 = 0;
p2 = 0;
n = 1;
while(n!=nextnumber1)
{
if (nextnumber1%n==0)
{
p1++;
}
if (nextnumber2%n==0)
{
p2++;
}
n++;
}
nextnumber1 = nextnumber1+2;
nextnumber2 = nextnumber2+2;
}
}
//если поток первый, то отрабатывают последние два числа
else
{
while ((p1!=p2) || (p1==0))
{
p1 = 0;
p2 = 0;
n = 1;
while(n!=nextnumber3)
{
if (nextnumber3%n==0)
{
p1++;
}
if (nextnumber4%n==0)
{
p2++;
}
n++;
}
nextnumber3 = nextnumber3+2;
nextnumber4 = nextnumber4+2;
}
}
}
//смотрим сколько прошло времени
double time2 = omp_get_wtime() - wall_timer2;
//выбираем наилучший результат из двух полученных и выводим на экран
if(nextnumber1<nextnumber3)
{
divout(nextnumber1-2);
divout(nextnumber2-2);
}
else
{
divout(nextnumber3-2);
divout(nextnumber4-2);
}
//выводим затраченное время
cout << "Parallel execution time: " << time2 << '\n';
//закончили работу в параллельном режиме
int g;
cin >> g;
}
