


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Государственное бюджетное образовательное учреждение
среднего профессионального образования
Санкт-Петербургский колледж управления и экономики
«Александровский лицей»
МДК.02.01 «Разработка, внедрение и адаптация программного обеспечения
отраслевой направленности»
ПМ.02 «Разработка, внедрение и адаптация программного обеспечения
отраслевой направленности»
Темы 2.1-2.3
Конспект лекций
для студентов специальности
230701 «Прикладная информатика (по отраслям)»
Санкт-Петербург
2013
Тема 2.1. Введение в теорию БД.
2.1.1. Информационные системы. Базы данных. Модели данных.
Информационные системы
Информационная система (ИС) служит для сбора и накопления информации, ее эффективного использования для всевозможных целей.
При проектировании ИС, с одной стороны, решается, какие сведения будут содержаться в системе, и для каких целей, а с другой – как соответствующие данные организованы в памяти ЭВМ, как они будут поддерживаться и обрабатываться.
По сферам применения можно выделить два основных специализированных класса ИС: информационно-поисковые системы и системы обработки информации.
В информационно-поисковых системах большинство обработок ориентировано на извлечение подмножества хранимых сведений, удовлетворяющих некоторому поисковому критерию. Причем пользователей интересует не столько результаты обработки, сколько сама информация. Наглядный пример такой ИС представляет справочная служба города, содержащая сведения о жителях. Пользователи такой системы могут по адресу узнать номер телефона, по фамилии и дате рождения - адрес и т. д.
В свою очередь, ряд отличительных черт содержат и системы обработки информации. Здесь обращение пользователей чаще приводит к обновлению информации. Примером такой системы может быть банковская ИС, которая содержит сведения о вкладах клиентов. Большинство обработок базы данных предполагает обновление сумм вкладов, расчет процентов, подведение итогов за некоторый период работы и т. д.
Другая классификация ИС подразделяет их на фактографические и документальные.
Фактографические системы хранят сведения об объектах реального мира (предприятиях, подразделениях, сотрудниках, договорах и т. д.). Причем сведения о каждом объекте могут поступать в систему из множества источников и из разных документов. При помещении в память ЭВМ эти сведения преобразуются и хранятся в одной записи.
В документальных ИС объект хранения - документ. Именно документы накапливаются и обрабатываются.
Документально-фактографические системы несут в себе черты каждого из описанных классов ИС.
Еще одна разновидность ИС - интеллектуальные, которые называют системами баз знаний. В отличие от традиционной ИС, которая может накапливать сведения и выдавать их в режиме вопрос-ответ, система баз знаний должна уметь интерпретировать эти сведения, строить ассоциативные выкладки, воспринимать сведения, как знания. Интеллектуальная система призвана не только накапливать знания, но и обобщать их, способствовать приобретению новых знаний.
Базы данных
Основные идеи современной информационной технологии базируются на концепции баз данных (БД). Согласно этой концепции, основой информационной технологии являются данные, которые должны быть организованы в БД целью адекватного отображения изменяющегося реального мира и удовлетворения информационных потребностей пользователей.
Таким образом, под БД следует понимать именованную совокупность данных, которая отражает состояния объектов и их отношений в рассматриваемой предметной области.
Для поддержки адекватного отображения состояния предметной области в базу данных необходимо динамически, в процессе функционирования информационной системы, обновлять (актуализировать) содержимое базы данных в соответствии с теми изменениями, которые происходят в предметной области.
Эти изменения отображаются в базе данных различными способами, в зависимости от их характера:
- путем ее реструктуризации - модификации структуры БД в терминах типов объектов и типов связей между ними, включения новых объектов данных; удаления или модификации значений существующих объектов данных, установления новых, или ликвидации существующих связей между объектами БД.
Различаются централизованные и распределенные базы данных.
Централизованная БД хранится в памяти одной вычислительной системы.
Если эта вычислительная система является компонентом сети ЭВМ, возможен распределенный доступ к такой БД - доступ к ней пользователей различных ЭВМ данной сети. Такой способ использования БД часто применяется в локальных сетях ПЭВМ.
Появление сетей ЭВМ позволило наряду с централизованными создавать и распределенные БД. Распределенная БД состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети.
Части распределенной БД, размещенные на отдельных ЭВМ сети,
управляются собственными (локальными) СУБД, и могут использоваться одновременно как самостоятельные локальные БД. Локальные СУБД не обязательно должны быть одинаковыми в разных узлах сети.
При разработке ИС обычно стремятся, чтобы ее БД была интегрированной. Это означает, прежде всего, что критерии оценки возможных вариантов построения БД носят «социальный» характер и направлены на интегральную эффективность системы, а не на удовлетворение интересов отдельных ее пользователей. При этом могут учитываться приоритеты и частота решения отдельных задач, их требования к вычислительным ресурсам, используемые в них части БД и т. п.
Пользователи информационной системы
Пользователей ИС условно можно разделить на 2 группы: внутренние и конечные. Внутренние пользователи разрабатывают ИС и поддерживают ее нормальное функционирование. Конечные - это те, ради нужд которых и создается ИС.
Группу внутренних пользователей составляют: администратор БД, администраторы функциональных подсистем, системные и прикладные программисты. Функции администратора БД на стадиях разработки и эксплуатации ИС различны и поэтому выполняются разными лицами.
На стадии проектирования администратор БД выступает как идеолог и конструктор системы, руководит работами по созданию программного окружения БД.
На стадии эксплуатации администратор БД отвечает за функционирование ИС и его основными задачами являются: защита данных от разрушения, обеспечение достоверности данных, анализ эффективности использования ресурсов ИС.
Администраторы функциональных подсистем определяют алгоритмы обработки данных, необходимые для разработки прикладных программ на стадии проектирования ИС.
Системные программисты выполняют генерацию СУБД, следят за ее нормальным функционированием в среде операционной системы, разрабатывают программные компоненты, расширяющие программное обеспечение СУБД.
Задача прикладных программистов состоит в разработке прикладных программ.
Конечных пользователей, в свою очередь, можно разделить на косвенных, которые не общаются с ЭВМ непосредственно и формулируют свои запросы службе администратора БД и прямых, которые общаются с ИС в интерактивном режиме и умеют интерпретировать ответы ИС.
Модели ИС
Система БД поддерживает в памяти ЭВМ модель предметной области.
Однако, результат моделирования зависит не только от предметной области, но и от используемой СУБД, поскольку каждая система представляет свой инструментарий для отображения предметной области (ПО). Этот инструментарий принято называть моделью данных. В то же время, результат отображения ПО в терминах модели данных называется моделью баз данных. Модель данных определяется тремя компонентами:
- допустимой организацией данных;
- ограничениями целостности;
- множеством операций, допустимых над объектами модели данных.
Допустимая организация данных определяется разнообразием и количеством типов объектов модели данных, ограничениями на структуру данных.
Ограничения целостности поддерживаются средствами, предусмотренными в модели данных для выражения ограничений на значения данных, которые характеризуют достоверные состояния БД.
Ряд ограничений целостности поддерживается моделью данных по умолчанию и распространяется на все типовые ситуации, возникновение которых возможно при внесении изменений в БД.
Другие ограничения целостности могут задаваться явно и также распространяются на множество однотипных операций.
Множество операций определяет виды обработок, которым могут
подвергаться объекты модели данных. Сюда в первую очередь входят операции выборки данных и операции, изменяющие состояние БД.
Модели данных, поддерживаемые промышленными СУБД и описанные в научной литературе, традиционно разбивают на несколько разновидностей: сетевые, иерархические и реляционные модели данных.
Жизненный цикл информационной системы
ПРОЕКТИРОВАНИЕ. Проектирование выполняется посредством изучения ПО и требований, предъявляемых к созданию ИС. Его основные результаты:
а) структура данных и стратегия их хранения в памяти ЭВМ;
б) технология обслуживания ИС и взаимодействия с ней конечных
пользователей;
в) выбор технических средств, а также выбор стандартных и разработка оригинальных программных средств обслуживания ИС.
РЕАЛИЗАЦИЯ. Сущность реализации заключается в материализации проекта, в перенесении его в память ЭВМ. На этой стадии разрабатывается и отлаживается программное обеспечение информационной системы, создается отладочная БД, разрабатываются многочисленные приложения. При этом администратор БД предварительно создает "фильтры" - внешние схемы, обеспечивающие взаимодействие приложений с СУБД. На стадии реализации тестируется и корректируется технология обслуживания ИС.
ЭКСПЛУАТАЦИЯ. Эта стадия жизни ИС начинается с наполнения системы реальной информацией. Эксплуатация охватывает весь комплекс действий по поддержанию нормального функционирования ИС: ведение словаря-справочника, обеспечение защиты, организация коллективного использования данных, анализ и управление эффективностью системы.
Кроме того, стадия эксплуатации включает разработку новых приложений, а также совершенствование и последующее развитие ИС.
2.1.2. СУБД и их функции. Типы данных. Домены. Отношения. Кортежи отношения.
Системой управления базами данных называют программную систему, предназначенную для создания на ЭВМ общей БД для множества приложений, поддержания ее в актуальном состоянии и обеспечения эффективного доступа пользователей к содержащимся в ней данным в рамках предоставленных им полномочий.
СУБД предназначена, таким образом, для централизованного управления базой данных как социальным ресурсом в интересах всей совокупности ее пользователей.
Доступ к базе данных отдельных пользователей при этом возможен только через посредство СУБД.
По степени их универсальности различают два класса СУБД:
- системы общего назначения,
- специализированные системы.
СУБД общего назначения не ориентированы на какую-либо предметную
область или на информационные потребности конкретной группы пользователей. Каждая система такого рода реализуется как программный продукт, способный функционировать на некоторой модели ЭВМ в определенной операционной обстановке, и поставляется многим пользователям как коммерческое изделие.
Использование СУБД общего назначения в качестве инструментального
средства для создания автоматизированных информационных систем, основанных на технологии баз данных, позволяет существенно сокращать сроки разработки, экономить трудовые ресурсы. Развитые функциональные возможности таких СУБД, присущая им, как правило, функциональная избыточность позволяют иметь значительный «запас мощности», необходимый для эволюционного развития построенных на их основе информационных систем в рамках их жизненного цикла.
Вместе с тем, средства настройки дают возможность достигнуть приемлемого уровня производительности информационной системы в процессе ее эксплуатации.
Однако, в некоторых случаях доступные СУБД общего назначения не позволяют добиться требуемых характеристик производительности и/или удовлетворить заданные ограничения по объему памяти, предоставляемой для хранения БД. Тогда приходится разрабатывать специализированную СУБД для данного конкретного применения.
Создание специализированной СУБД весьма трудоемкое дело даже в сравнительно простых случаях, и для того, чтобы избрать этот путь, нужно иметь действительно веские основания и твердую убежденность в невозможности или нецелесообразности использования какой-либо СУБД общего назначения.
СУБД общего назначения - это сложные программные комплексы, предназначенные для выполнения всей совокупности функций, связанных с созданием и эксплуатацией БД ИС. Они позволяют определить структуру создаваемой БД, инициализировать ее и произвести начальную загрузку данных.
Системные механизмы выполняют функции управления ресурсами среды хранения, обеспечения логической и физической независимости данных, предоставления доступа пользователям к БД, защиты логической целостности БД, обеспечения ее физической целостности - защиты от разрушения.
Еще одна важная группа функций - управление полномочиями пользователей на доступ к БД, настройка на конкретные условия применения, организация параллельного доступа пользователей к БД в социальной пользовательской среде, поддержка деятельности системного персонала, ответственного за эксплуатацию БД.
Более конкретно, к числу функций СУБД принято относить следующие:
Непосредственное управление данными во внешней памяти.
Эта функция включает обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным в некоторых случаях (обычно для этого используются индексы). В некоторых реализациях СУБД активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. Но подчеркнем, что в развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД файловую систему, и если использует, то как организованы файлы. В частности, СУБД поддерживает собственную систему именования объектов БД.
Управление буферами оперативной памяти
СУБД обычно работают с БД значительного размера, который существенно больше доступного объема оперативной памяти. В этом случае при обращении к любому элементу данных система будет работать со скоростью устройства внешней памяти.
Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной памяти. При этом, даже если операционная система производит общесистемную буферизацию (как в случае ОС UNIX), этого недостаточно для целей СУБД, которая располагает гораздо большей информацией о полезности буферизации той или иной части БД. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственным порядком замены буферов.
Управление транзакциями
Транзакцией называют последовательность операций пользователя над БД, рассматриваемых СУБД как единое целое, которая сохраняет ее логическую целостность.
Транзакция либо успешно выполняется, и СУБД фиксирует изменения БД, произведенные этой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается на состоянии БД.
Понятие транзакции необходимо для поддержания логической целостности БД.
ПРИМЕР. Предположим, необходимо реализовать информационную систему, поддерживающую учет сотрудников некоторой организации.
Система должна выполнять следующие действия:
- выдавать списки сотрудников по отделам,
- поддерживать возможность перевода сотрудника из одного отдела в другой,
- поддерживать возможность приема на работу новых сотрудников и увольнения работающих.
Для каждого отдела должна поддерживаться возможность получения имени руководителя этого отдела, общей численности отдела, общей суммы выплаченной в последний раз зарплаты и т. д.
Для каждого сотрудника должна поддерживаться возможность выдачи номера удостоверения по полному имени сотрудника, выдачи полного имени по номеру удостоверения, получения информации о текущем соответствии занимаемой должности сотрудника и о размере его зарплаты.
Информационную систему будем строить в виде двух информационно-связанных файлов: Отделы и Сотрудники. Поскольку минимальной информационной единицей в нашем случае является сотрудник, естественно потребовать, чтобы в БД содержалась одна запись для каждого сотрудника. Такая запись должна содержать поля:
- полное имя сотрудника (СОТР_ИМЯ),
- номер его удостоверения (СОТР_НОМ),
- информацию о его соответствии занимаемой должности (для простоты, «да» или «нет») (СОТР_СТАТ),
- размер зарплаты (СОТР_ЗАРП),
- номер отдела (СОТР_ОТД_НОМ).
Та же запись должна содержать имя руководителя отдела (СОТР_ОТД_РУК).
Кроме того, должна обеспечиваться возможность выбора всех записей с общим значением СОТР_ОТД_НОМ.
Чтобы получить численность отдела или общий размер зарплаты, каждый раз при выполнении такой функции информационная система должна будет выбрать все записи о сотрудниках отдела и посчитать соответствующие общие значения.
Прежде всего, система должна знать, что она работает с двумя информационно связанными файлами (это шаг в сторону схемы базы данных), должна знать структуру и смысл каждого поля (например, что СОТР_ОТД_НОМ в файле СОТРУДНИКИ и ОТД_НОМ в файле ОТДЕЛЫ означают одно и то же), а также понимать, что в ряде случаев изменение информации в одном файле должно автоматически вызывать модификацию во втором файле, чтобы их общее содержимое было согласованным. Например, если на работу принимается новый сотрудник, то необходимо добавить запись в файл СОТРУДНИКИ, а также соответствующим образом изменить поля ОТД_ЗАРП и ОТД_КОЛ в записи файла ОТДЕЛЫ, описывающей отдел этого сотрудника.
Единственным способом не нарушить целостность БД при выполнении операции приема на работу нового сотрудника является объединение элементарных операций над файлами СОТРУДНИКИ и ОТДЕЛЫ в одну транзакцию.
Таким образом, поддержание механизма транзакций является обязательным условием даже однопользовательских СУБД. Но понятие транзакции гораздо более важно в многопользовательских СУБД.
То свойство, что каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к БД.
При соответствующем управлении параллельно выполняющимися транзакциями со стороны СУБД каждый из пользователей может в принципе ощущать себя единственным пользователем СУБД (на самом деле, это несколько идеализированное представление, поскольку в некоторых случаях пользователи многопользовательских СУБД могут ощутить присутствие своих коллег).
С управлением транзакциями в многопользовательской СУБД связаны важные понятия сериализации транзакций и сериального плана выполнения смеси транзакций.
Под сериализаций параллельно выполняющихся транзакций понимается такой порядок планирования их работы, при котором суммарный эффект смеси транзакций эквивалентен эффекту их некоторого последовательного выполнения.
Сериальный план выполнения смеси транзакций - это такой план, который приводит к сериализации транзакций. Понятно, что если удается добиться действительно сериального выполнения смеси транзакций, то для каждого пользователя, по инициативе которого образована транзакция, присутствие других транзакций будет незаметно (если не считать некоторого замедления работы по сравнению с однопользовательским режимом).
Существует несколько базовых алгоритмов сериализации транзакций. В централизованных СУБД наиболее распространены алгоритмы, основанные на синхронизационных захватах объектов БД. При использовании любого алгоритма сериализации возможны ситуации конфликтов между двумя или более транзакциями по доступу к объектам БД. В этом случае для поддержания сериализации необходимо выполнить откат (ликвидировать все изменения, произведенные в БД) одной или более транзакций. Это один из случаев, когда пользователь многопользовательской СУБД может реально (и достаточно неприятно) ощутить присутствие в системе транзакций других пользователей.
Журнализация
Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается возможность СУБД восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя.
Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти.
Примерами программных сбоев могут быть: аварийное завершение работы СУБД (по причине ошибки в программе или в результате некоторого аппаратного сбоя) или аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при возникновении последней требуется ликвидировать последствия только одной транзакции.
Независимо от вида сбоя в любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. Другими словами, в БД требуется хранить часть данных, которая используется для восстановления. И она должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД.
Журнал - это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД.
В разных СУБД изменения БД журнализуются на разных уровнях: иногда запись в журнале соответствует некоторой логической операции изменения БД (например, операции удаления строки из таблицы реляционной БД), иногда - минимальной внутренней операции модификации страницы внешней памяти; в некоторых системах одновременно используются оба подхода.
Во всех случаях придерживаются стратегии «упреждающей» записи в журнал (так называемого протокола Write Ahead Log - WAL). Эта стратегия заключается в том, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Известно, что если в СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя.
Самая простая ситуация восстановления - индивидуальный откат транзакции. Строго говоря, для этого не требуется общесистемный журнал изменений БД. Достаточно для каждой транзакции поддерживать локальный журнал операций модификации БД, выполненных в этой транзакции, и производить откат транзакции путем выполнения обратных операций, следуя от конца локального журнала. Но большинство СУБД локальные журналы не поддерживают, а индивидуальный откат транзакции выполняют по общесистемному журналу, для чего все записи от одной транзакции связывают обратным списком (от конца к началу).
При мягком сбое во внешней памяти основной части БД могут находиться объекты, модифицированные транзакциями, не закончившимися к моменту сбоя, и могут отсутствовать объекты, модифицированные транзакциями, которые к моменту сбоя успешно завершились (по причине использования буферов оперативной памяти, содержимое которых при мягком сбое пропадает). При соблюдении протокола WAL во внешней памяти журнала должны гарантированно находиться записи, относящиеся к операциям модификации обоих видов объектов.
Целью процесса восстановления после мягкого сбоя является состояние внешней памяти основной части БД, которое возникло бы при фиксации во внешней памяти изменений всех завершившихся транзакций и которое не содержало бы никаких следов незаконченных транзакций. Чтобы этого добиться, сначала производят откат незавершенных транзакций (undo), а потом повторно воспроизводят (redo) те операции завершенных транзакций, результаты которых не отображены во внешней памяти. Этот процесс содержит много тонкостей, связанных с общей организацией управления буферами и журналом.
Для восстановления БД после жесткого сбоя используют журнал и архивную копию БД. Архивная копия - это полная копия БД к моменту начала заполнения журнала.
Для нормального восстановления БД после жесткого сбоя необходимо, чтобы журнал не пропал. К сохранности журнала во внешней памяти в СУБД предъявляются повышенные требования. В этом случае восстановление БД состоит в том, что, исходя из архивной копии по журналу воспроизводится работа всех транзакций, которые закончились к моменту сбоя. Теоретически можно даже воспроизвести работу незавершенных транзакций и продолжить их работу после завершения восстановления. Однако на практике это не делается, поскольку процесс восстановления после жесткого сбоя является длительным.
Для создания БД разработчик описывает ее логическую структуру, организацию в среде хранения, а также способы ведения БД пользователями.
При этом используются предоставляемые СУБД языковые средства определения данных, и система настраивается на работу с конкретной БД.
Такие описания БД называются соответственно схемой (или логической
схемой) БД, схемой хранения (или внутренней схемой) и внешними схемами.
Обрабатывая схемы БД, СУБД создает пустую БД, которую можно далее наполнить данными о ПО и начать эксплуатировать для удовлетворения информационных потребностей пользователей.
Принципиально важное свойство СУБД заключается в том, что она позволяет различать и поддерживать два независимых взгляда на БД - взгляд
пользователя, воплощаемый в «логическом» представлении данных, и «взгляд» системы – «физическое» представление, характеризующее организацию хранимых данных.
Поддержка языков БД
Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два языка - язык определения схемы БД (SDL - Schema Definition Language) и язык манипулирования данными (DML - Data Manipulation Language). SDL служил главным образом для определения логической структуры БД, т. е. той структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными, т. е. операторов, позволяющих заносить данные в БД, удалять, модифицировать или выбирать существующие данные.
В современных СУБД поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных.
Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language). Язык SQL сочетает средства SDL и DML, т. е. позволяет определять схему БД и манипулировать данными.
Язык SQL содержит специальные средства определения ограничений целостности БД. Специальные операторы языка SQL позволяют определять так называемые представления БД, фактически являющиеся хранимыми в БД запросами.
Наконец, авторизация доступа к объектам БД производится также на основе специального набора операторов SQL.
Подводя итог описанию функций СУБД, отметим следующее. Обеспечение логической независимости данных - одна из важнейших функций СУБД, предоставляющая определенную степень свободы вариации «логического» представления БД без необходимости соответствующей модификации «физического» представления. Благодаря этому, достигается возможность адаптации взгляда пользователя на БД к его реальным потребностям, конструирования различных «логических» взглядов на одну и ту же «физическую» БД.
При этом пользовательское видение БД может по своей структуре существенно отличаться от структуры хранимых данных и синтезироваться не только непосредственно из фактически хранимых объектов БД и их связей, но и с помощью различного рода агрегирования таких объектов и связей объектов, осуществляемого динамически в процессе обработки пользовательских запросов.
Под физической независимостью данных понимается способность СУБД предоставлять некоторую свободу модификации способов организации БД в среде хранения, не вызывая необходимости внесения соответствующих изменений в логическое представление. Благодаря этому можно вносить изменения в организацию хранимых данных, производить настройку системы с целью повышения ее эффективности, не затрагивая прикладных программ, использующих БД. Физическая независимость данных реализуется в СУБД за счет тех же самых механизмов трансформации архитектуры системы, которые обеспечивают логическую независимость данных.
Поддержка логической целостности (непротиворечивости) БД - важная функция СУБД. В развитых системах ограничения целостности БД объявляются в схеме БД, и их проверка осуществляется при каждом обновлении объектов данных или связей между ними, являющихся аргументами таких ограничений.
Проблема обеспечения физической целостности БД возникает в связи с возможными ее разрушениями в результате сбоев и отказов оборудования вычислительной системы. Современные СУБД располагают средствами восстановления разрушенной БД, основанные чаще всего, на использовании ее контрольных копий.
В многопользовательских СУБД предусматриваются механизмы разграничения полномочий доступа пользователей к БД.
Механизмы управления доступом обычно основываются на принципах паролей, сопоставлении так называемых замков управления доступом, ассоциированных с запрещенными объектами, и ключей, специфицируемых пользователем, либо на явной спецификации полномочий доступа.
Настройка СУБД на конкретные условия применения может включать модификацию параметров организации среды хранения данных, выбор новых, более эффективных для данного случая методов доступа из числа предоставляемых системой.
Кроме того, предусматривается возможность логической реструктуризации БД - модификации концептуальной схемы с последующим приведением БД в соответствие с вновь сформированной схемой, а также ряд других функций для поддержки деятельности системного персонала, ответственного за эксплуатацию БД. Такой персонал называют администраторами БД.
Для управления настройкой системы используются ее языковые средства - языки определения данных, связанные с различными архитектурными уровнями системы, а в некоторых системах - возможности задания параметров системной среды. Характер и возможности языковых средств СУБД определяются главным образом моделью данных, поддерживаемой этой системой.
Организация параллельного доступа пользователей к БД является довольно сложной задачей. Здесь нужно исключать проблемы, связанные с одновременным обновлением данных разными пользователями, что может привести к нарушению логической целостности БД. Для их предотвращения в СУБД предусматривается техника транзакций и блокировка ресурсов данных.
На время исполнения транзакции, модифицирующей значения данных, необходимо блокировать эти ресурсы с тем, чтобы не допустить к ним доступа для других транзакций. В различных СУБД используются разные методы блокирования.
В одних системах предусматривается автоматическое блокирование ресурсов на время их обновления, в других - оно должно явно запрашиваться в пользовательских транзакциях. Используются и комбинированные стратегии блокирования.
2.1.3. Фундаментальные свойства отношений.
Рассмотрим некоторые важные свойства отношений, которые следуют из приведенных выше определений.
Отсутствие кортежей-дубликатов. Тот факт, что отношения не содержат кортежей-дубликатов, следует из определения отношения как множества кортежей. В классической теории множеств по определению каждое множество состоит из различных элементов.
Из этого свойства вытекает наличие у каждого отношения так называемого первичного ключа - набора атрибутов, значения которых однозначно определяют кортеж отношения. Понятие первичного ключа является исключительно важным в связи с понятием целостности баз данных.
Поскольку отношение – это множество, а множества по определению не содержат совпадающих элементов, то никакие два кортежа отношения не могут быть дубликатами друг друга в любой произвольно-заданный момент времени. Пусть R – отношение с атрибутами A1, A2, ..., An.
Говорят, что множество атрибутов K=(Ai, Aj, ..., Ak) отношения R является возможным ключом R тогда и только тогда, когда удовлетворяются два независимых от времени условия:
· Уникальность: в произвольный заданный момент времени никакие два различных кортежа R не имеют одного и того же значения для Ai, Aj, ..., Ak.
· Минимальность: ни один из атрибутов Ai, Aj, ..., Ak не может быть исключен из K без нарушения уникальности.
Каждое отношение обладает хотя бы одним возможным ключом, поскольку, по меньшей мере, комбинация всех его атрибутов удовлетворяет условию уникальности. Один из возможных ключей (выбранный произвольным образом) принимается за его первичный ключ.
Отсутствие упорядоченности кортежей. Свойство отсутствия упорядоченности кортежей отношения также является следствием определения отношения-экземпляра как множества кортежей. Отсутствие требования к поддержанию порядка на множестве кортежей отношения дает дополнительную гибкость СУБД при хранении баз данных во внешней памяти и при выполнении запросов к базе данных. Это не противоречит тому, что при формулировании запроса к БД, например, на языке SQL можно потребовать сортировки результирующей таблицы в соответствии со значениями некоторых столбцов.
Отсутствие упорядоченности атрибутов. Атрибуты отношений не упорядочены, поскольку по определению схема отношения есть множество пар {атрибут, домен}. Для ссылки на значение атрибута в кортеже отношения всегда используется имя атрибута. Это свойство теоретически позволяет, например, модифицировать схемы существующих отношений не только путем добавления новых атрибутов, но и путем удаления существующих атрибутов.
Атомарность значений атрибутов. Значения всех атрибутов являются атомарными. Это следует из определения домена как потенциального множества значений простого типа данных, т. е. среди значений домена не могут содержаться множества значений (отношения).
Принято говорить, что в реляционных базах данных допускаются только нормализованные отношения. Потенциальным примером ненормализованного отношения является следующее:
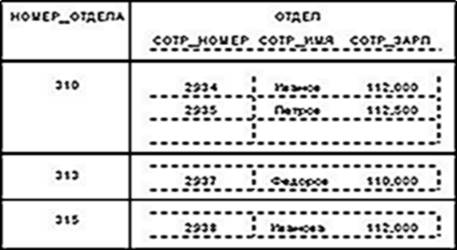
Здесь задано бинарное отношение, значениями атрибута ОТДЕЛЫ которого являются отношения.
Исходное отношение СОТРУДНИКИ является нормализованным вариантом отношения ОТДЕЛЫ:
СОТР_НОМЕР | СОТР_ИМЯ | СОТР_ЗАРП | СОТР_ОТД_НОМЕР |
2934 | Иванов | 112,000 | 310 |
2935 | Петров | 144,000 | 310 |
2937 | Федоров | 110,000 | 310 |
2938 | Иванова | 112,000 | 315 |
Нормализованные отношения составляют основу классического реляционного подхода к организации баз данных. Они обладают некоторыми ограничениями (не любую информацию удобно представлять в виде плоских таблиц), но существенно упрощают манипулирование данными.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
