

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Софт энд Сервис»

 |
Москва
2006
Содержание
Введение. 3
Предназначение Программного комплекса: 3
Преимущества поисковой системы ПК БРЭДФОРД.. 4
Сравнение с традиционными поисковыми системами. 4
Возможные схемы организации работы Поисковой системы ПК «Брэдфорд»: 5
Организация системы поиска. 6
Вариант точного и LIKE поиска. 8
Вариант НОМ поиска. 9
Особенности НОМ-поиска. 9
SQL вариант.. 10
Вариант DataCache. 10
Ранг. 10
Коэффициент релевантности. 11
Настройка справочников сокращений и аббревиатур. 13
Пример структуры вспомогательных справочников. 14
Ручной НОМ-поиск. 15
Автоматический НОМ-поиск. 18
Примеры выявленных двойников в справочнике контрагентов: 20
Примеры выявленных двойников в справочнике МТР: 21
Математическая постановка задачи и методы решения. 22
Постановка задачи. 22
Методы решения. 23
Метод вычисления минимального редакционного расстояния. 23
Методы решения с использованием N-грамм.. 24
Формальный синтаксический анализ. 26
Алгоритм формального синтаксического анализа. 27
Введение.
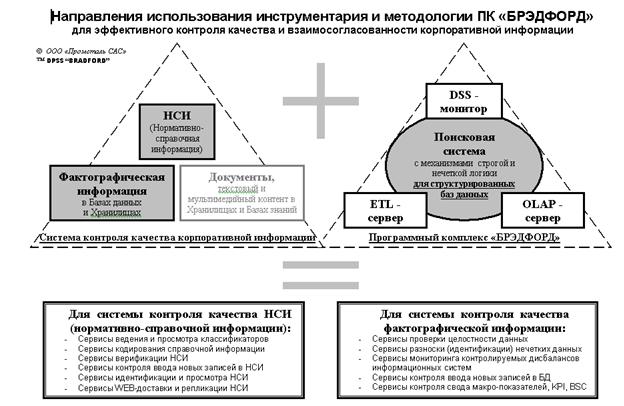
Программный комплекс «Брэдфорд» - специализированное программное обеспечение (в том числе - на основе матмоделей с нечеткой логикой поиска) для выверки массивов нормативно-справочной информации (НСИ) и построения подсистем ведения НСИ
Наиболее эффективно использование ПО для поиска и идентификации контрагентов с учетом случайных ошибок и расхождений, вызванных разными обычаями написания наименований, адресов и других реквизитов разными операторами, а также для выверки справочников и реестров контрагентов, для их объединения в эталонный сводный массив, для разработки таблиц перекодировки (переходных ключей).
Предназначение Программного комплекса:
q Для выполнения работ по объединению и выверке массивов НСИ (в том числе – перед загрузкой в ERP-системы), создания на их основе централизованных корпоративных справочников и классификаторов с таблицами переходных ключей.
q Для обеспечения обязательной перепроверки на дублирование всех вновь вводимых записей в справочники и классификаторы системы НСИ
q Для построения и поддержки распределенных систем ведения НСИ, автоматизации процессов упорядочивания, классификации, кодирования и верификации нормативно-справочной информации, обеспечения качества и взаимосогласованности информации в различных системах НСИ, а также в Хранилищах данных и контента.
Преимущества поисковой системы ПК БРЭДФОРД
1. Наличие специализированной Поисковой системы с
механизмами строгой и нечеткой логики для лингвистического поиска двойников и аналогов в структурированных базах данных с расчетом коэффициентов релевантности.
2. Наличие специализированного инструментария по контролю качества НСИ в части орфографии, стилей написания, вкрапления латинских букв, повторений и слияний.
3. Наличие специализированных словарей и баз данных по транслитерациям наименований НСИ, синонимам, сокращениям, аббревиатурам, а также вспомогательных справочников по маркам и техническим характеристикам оборудования и материалов.
4. Наличие возможности проверки НСИ по внешним источникам – Интернет, базы данных ГКС, ЕГРПО, МНС, ФКЦБ и др., Сводные Базы ГОСТов и ТУ, Перечни марок продукции и т. п., плюс - наличие инструментария, обеспечивающего пользователю возможность самому создавать, наполнять и вести Контент-хранилища, расклассифицировать их содержимое, привязывать разнородные материалы из собранного контента к узлам существующих классификаторов.
5. Наличие уникальной методологии и опыта организации АРМов обеспечения качества в справочниках контрагентов, материально-технических ресурсов, основных средств, бюджетных статей и показателей.
Сравнение с традиционными поисковыми системами.
Типовые поисковики работают по принципу предварительной индексации массива поиска и далее - с участием запроса пользователя. Плюс - ранжируют результаты по жестко настроенному принципу.
У Поискового механизма ПК «Брэдфорд» следующие преимущества:
1. оперативнось. В корпоративной НСИ изменения в справочник (новая запись, удаление, редактирование) могут вноситься разными людьми почти одновременно. И поиск должен происходить с учетом самых постедних изменений! Варианты с индексацией здесь уже отпадают - создание гигабайтных индексов занимает многие часы работы мощных серверов. (ссылку на анализ поисковиков этого типа направляю). У нас требуется только перезагрузка массива в память. При регламенте реагирования более чем на 3-минутные изменения пользователь при работе с Поисковой системой ПК «Брэдфорд» не заметит задержки времени. В более жестких условиях проблема решается за счет увеличения вычислительных можностей и распараллеливания выполнения запросов на разных серверах.
2. автоматизм. Для нашей задачи ведения НСИ в корпоративной среде необходимо, чтобы поисковая система была автоматической! Т. Е. нельзя полагаться на то, что запросы будет делать обученный эксперт, грамотно формирующий ключевые слова поиска. У нас идет потоковая разборка новых записей "как есть"! Т. е., идет обработка по полному наименованию МТР плюс полным наименованиям других полей. Работа по обучению поисковой системы самостоятельно выбирать ключевые слова вынесена на предварительный этап формирования вспомогательных справочников.
3. качество. В нашей поисковой системе не только можно управлять качеством поиска, создавая и поддерживая вспомогательные справочники, но и варьировать множеством факторов, влияющих на расчет коэффициента релевантности (в последней версии эксперт может перепроверить систему - тут же узнать почему у данного аналога именно такой коэффициент релевантности, какие факторы на него повлияли)
4. специализированность. У нас большое значение придается предподготовке обоих массивов для поиска и для этого понаделано множество дополнительных программных компонентов: выверка латиницы, сокращений и аббревиатур, синонимов, стилей и порядка написания, проверка по маске (новая опция - для проверки ИНН, паспортов и др. больших чисел).
Возможные схемы организации работы Поисковой системы ПК «Брэдфорд»:
1. Организация поиска в «НСИ-мониторе» на основе SQL-доступа к массиву поиска (по IP-доступным сетям)
2. Организация поиска в «НСИ-мониторе» на основе загрузки массива в память локального компьютера.
3. Организация поиска в «НСИ-мониторе» через ETL-сервисы с массивами, загруженными в память IP-сетевого сервера базы данных.
4. Организация поиска в «Интернет-мониторе» через WEB-сервисы по Интернет/Интранет сетям с массивами, загруженными на удаленных серверах баз данных.
5. Настройка поиска в любом внешнем Windows-приложении через API-вызовы ETL-сервиса поисковой системы.
Организация системы поиска.
В современных крупных холдингах, использующих для работы нецентрализованные базы данных, очень часто возникает ситуация, когда одна и та же позиция в территориально различных отделениях холдинга отвечает многим записям в справочниках «на местах».
Централизация управления холдингом предусматривает необходимость создания единой системы кодирования используемых справочников и классификаторов.
В разных подразделениях холдинга и даже в разных автоматизированных системах (АС) у одного и того же подразделения, как правило, используются собственные справочники, коды и наименования которых могут не совпадать с реквизитами таких же по сути записей в справочниках других АС и подразделений. Помимо этого дублирование записи нередко встречается и внутри одного и того же локального справочника.
Все это имеет целый ряд негативных последствий как в виде прямых экономических потерь, так и в виде снижения эффективности системы управления.
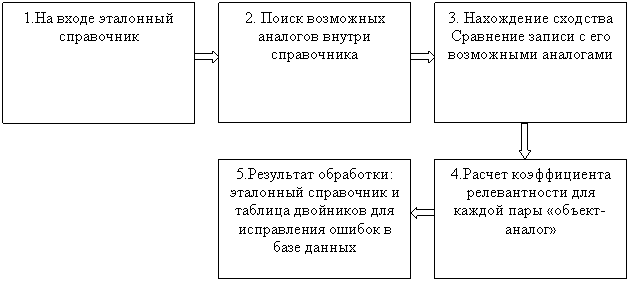
Каждая запись обладает неким набором атрибутов. Задача состоит в том, чтобы привести запись в различных справочниках к одному виду (эталонному). Для этого необходимо составить некий алгоритм, с помощью которого можно было бы осуществить нечеткое сравнение значений этих атрибутов.
Входными данными системы являются базы данных справочников. Выходные данные представляют собой коэффициенты релевантности между одним и тем же атрибутом для каждой заданной эталонной записи и множества записей-аналогов.
Укрупненная функциональная схема выглядит следующим образом:

Для обработки новой записи, ранее полученных записей и просто поиска какой-либо информации по заданным условиям в ПК БРЭДФОРД предназначена система поиска с использованием сценария. Данная система позволяет производить точный и поиск похожих значений по введенным условиям. Найденная информация может быть обработана (редактирование, экспорт, применение задач ETL приложения). Обработка информации может быть настроена произвольно для решения требуемой задачи. Суть данного поиска состоит также в том, что можно создавать настройки для поиска в других источниках данных, отличающихся от текущего.
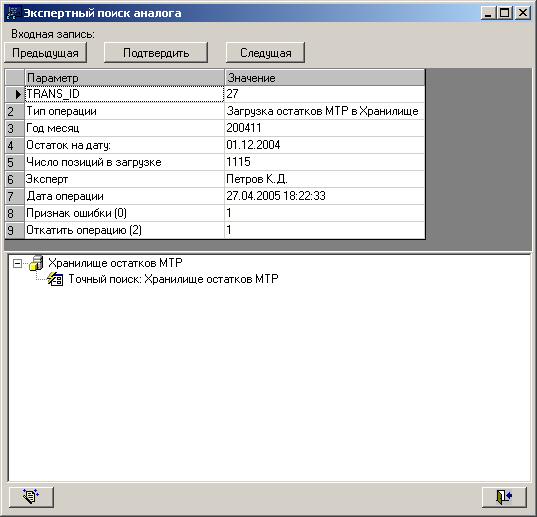
Ниже на рисунке показана стартовая форма поисковой системы. В верхней части формы расположены кнопки навигации по записям линейного справочника.
Входная (искомая) запись показана в виде развернутой таблицы. В нижней части окна расположено окно с иерархической структурой сценария поиска.


Пункт контекстного меню «Показать настройку латиницы» показывает дополнительный столбец, в котором можно указать флаг запуска проверки на вкрапления латинских букв в слова, написанные кириллицей. Если в процессе проверки будет найдена возможная ошибка, откроется форма корректировки полностью аналогичная рассмотренной ранее форме проверки на вкрапления латинских букв для таблицы линейного справочника.
Форма поиска в любом случае состоит из двух условно разделенных этапов (шагов). На первом этапе происходит формирование структуры поиска, автоподстановка искомых значений, ручное редактирование искомых значений, дополнительные вызовы вспомогательных поисковых форм, прямой вызов поиска в ресурсах Интернета с использованием сайта Яндекс. Первый этап условно обозначен как «Открытие в режиме редактирования».
На втором этапе выводится результат поиска, предоставляется возможность выбора необходимых для обработки записей и переход к механизму обработки результата (выбранных записей). Второй этап условно обозначен как «Открытие в режиме результата».
Переход от первого этапа ко второму непосредственно на самой форме поиска может быть произведен с запуском механизма поиска и без (соответственно с помощью кнопок навигации или кнопки поиска). Вариант без запуска механизма поиска может быть необходим в случае многократного поиска в пределах одной настройки для просмотра предыдущего результата при редактировании искомых значений поиска.
Вариант точного и LIKE поиска.
Вид формы для точного поиска на этапе редактирования показан на рисунке ниже. В этом режиме возможна корректировка значений подставленных автоматически из входной записи. Значения подставляются по настроенным ранее соответствиям подстановки в момент открытия формы или при переходе по сценарию в пределах одной формы. В верхней части формы показана развернутая таблица с входной записью. В нижней части формы расположена таблица условий поиска. Пользователь может вручную задать значение условия в ячейках шаблона поиска. Таблица с условиями поиска имеет 4 колонки условий, объединяемых при поиске по смыслу «ИЛИ». В пределах одной колонки условия объединяются по смыслу «И».
Форма настройки соответствия полей входной записи, и базы поиска может быть открыта непосредственно из данной формы при нажатии соответствующей кнопки. Для точного и LIKE поиска различия практически состоят лишь в самом механизме поиска. Т. е. различий в настройке поиска и показе результата нет. Поэтому данные механизмы будут рассмотрены как один.



 буфер обмена
" width="188" height="77"/>
буфер обмена
" width="188" height="77"/>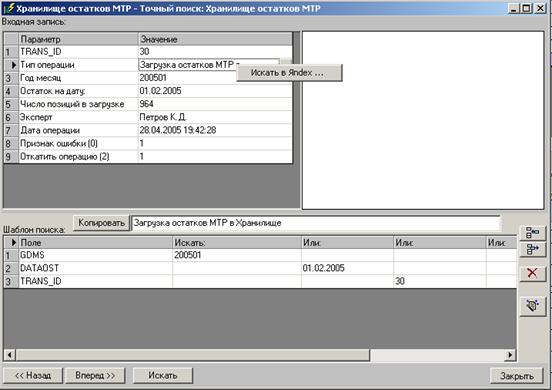
Для того чтобы вызвать контекстное меню поиска в Интернете, необходимо указать ячейку с искомой фразой в таблице входной записи и вызвать контекстное меню «Искать в Яndex…». В качестве искомого значения будет передано значение текущей ячейки или выделенная часть текста ячейки.
Ниже показан рисунок формы точного или LIKE поиска на втором этапе (в режиме результата).






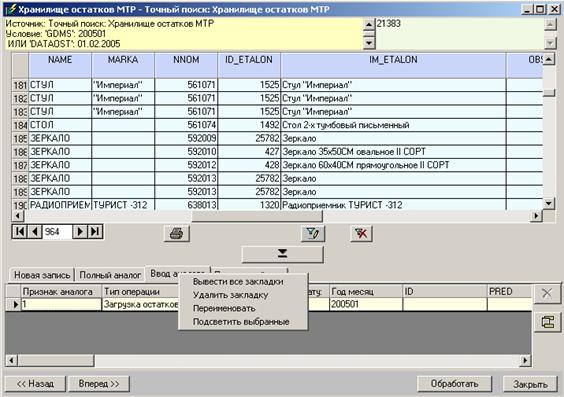
Программой предусмотрено наличие четырех накопительных таблиц, в которые могут быть помещены выбранные для обработки записи. Каждая из таблиц имеет свою особенность. В первой таблице (по умолчанию закладка называется «Новая запись») всё время находится одна входная запись. Если эта запись была получена из формы ввода, то в дальнейшем в процессе обработки её можно будет добавить в какой-либо источник данных. В эту таблицу нет возможности добавлять другие записи. После обработки новая запись из данной таблицы удаляется, кнопка «Обработать» для данной закладки блокируется, предотвращая повторный ввод новой записи. Вторая таблица, у которой закладка по умолчанию называется «Полный аналог», позволяет многократно запускать обработку, но только для одной выбранной записи. Третья таблица, у которой закладка по умолчанию называется «Ввод аналога», содержит строку входящей записи. В эту таблицу могут быть перенесены любые другие записи. Запись в данную таблицу происходит с учетом соответствия полей, настроенных ранее. После обработки таблица обработки очищается, кнопка обработки блокируется. В четвёртую таблицу, у которой закладка по умолчанию называется «Прочие двойники», могут быть добавлены любые записи. После выполнения обработки таблица очищается. Обработка может запускаться многократно. Макет каждой таблицы может быть сохранен при вызове контекстного меню «Сохранить макет таблицы» на заголовках столбцов.
Вариант НОМ поиска.
НОМ-поиск организован в двух вариантах: ручной (для одной записи) и автоматический (для массива записей).
Особенности НОМ-поиска.
Выполнение НОМ-поиска возможно в двух вариантах организации массивов, по которым происходит поиск:
SQL вариант
В качестве массива используется строка SQL-запроса.
Порядок выполнения:
- предподготовка искомой фразы (нормализация с учетом точек, запятых, кавычек и т. п.
- подготовка массива поисковых фраз, исключение ненужных слов.
Вариант DataCache
Данный тип поиска выполняется аналогично правилам SQL поиска, за исключением отсутствия поиска по массиву усеченных слов, более гибкому механизму варьирования (расчет коэффициента релевантности ведется сразу по найденой фразе и фильтруется в соответствии с коэффициентом отсечки), что в свою очередь позволяет более качественно выполнить поиск. К достоинству следует также отнести отсутствие нагрузки на СУБД (сервер, сети), т. к. расчет происходит в памяти локальной машины, а также в росте производительности поиска (при оптимальной настройке) за счет выполнения только одного прохода по записям поисковой базы для одной искомой фразы. Недостаток - кэш данных статический, т. е. для синхронизации с СУБД требует перезагрузки.
Ранг
После выполнения поиска каждой найденной фразе присваивается ранг и коэффициент релевантности.
Первый ранг поиска - точное совпадение искомой фразы или совпадение всех поисковых фраз (т. е. совпадение по нормализованной фразе), второй - совпадение по аббревиатурам (если система распознает аббревиатурное написание слов), третий ранг и далее (в зависимости от количества нормализованных фраз поиска) - работает механизм ранжирования по количеству совпавших слов в проверяемой записи. Например третий ранг означает, что в нормализованном предложении из 5 слов совпало 4 слова, четвертый ранг - 3 слова. В механизме ранжирования ранг рассчитывается только до уровня двух слов.
Следующий ранг рассчитывается по совпадению каждого одного отдельного слова из нормализованной фразы.
Далее массив нормализованных слов подвергается дополнительной обработке, в результате чего появляется массив усеченных слов (в зависимости от длины исходных слов).
По массиву усеченных слов рассчитываются следующие ранги теми же механизмами ранжирования по словам и поиска по каждому отдельному слову.
В процессе формирования результата все найденные записи проверяются на их присутствие в таблице результата для устранения возможности двоения.
Для получения каждого типа рангов выполняется свой SQL запрос.
В зависимости от версий использования ранги могут быть приведены к виду 0, 1 или 9 (т. е.абсолютное совпадение, нормализованное точное и похожее). Это необходимо для более успешной реализации вывода результатов с учетом коэффициента релевантности. Также при указании дополнительных полей для расчета коэффициента релевантности выполняется точный поиск для указанных в них значениях в соответствующих полях поисковой базы. В некоторых случаях могут быть использованы справочники для получения вариаций искомой фразы (справочник сокращений и транслитерации). Если появляется вариация искомой фразы механизм поиска запускается повторно для данной вариации.
Коэффициент релевантности.
Соответствия полей используются для настройки расчета коэффициента релевантности. В нижней части формы поиска показаны поля поисковой базы настроенные в форме соответствий. Для тех полей, у которых был установлен признак копирования, при открытии формы будут скопированы значения искомой записи. При первом вызове формы поиска или при добавлении новых полей для расчета коэффициента релевантности («К2») необходимо произвести настройку механизма релевантности (вызывается соответствующей кнопкой). После выбора настройки релевантности ее название будет указано в поле «Настройка» в нижней таблице. В поле «Метод» можно выбрать из списка нужный метод расчета «К2» для получения наилучшего результата. Для ограничения вывода найденных данных в соответствии с коэффициентом релевантности служит поле с признаком «Отсечка».
В соседних полях можно выбрать тип отсечки (из комбобокса) и указать физическое числовое значение. При процентном соотношении отсечки, будет предварительно вычислен максимальный коэффициент «К2» и затем от этого значения рассчитан минимальный «К2» подлежащий отсечке. При использовании абсолютного значения следует помнить, что значение максимально похожего по «К2» - величина не постоянная. Порядок записей с настройками для расчета коэффициента «К2» влияет на порядок показа полей результата поиска. В том же порядке осуществляется сортировка по «К2». Менять позиции настроек можно «перетаскивая» записи вверх-вниз с помощью курсора мыши.
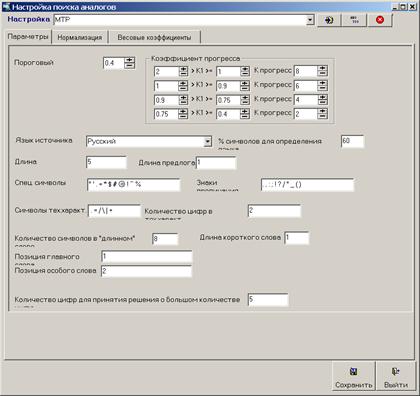
Настройка расчета коэффициента релевантности.
Форма настройки имеет три закладки:
1. Параметры.
Закладка с информацией о параметрах замены и учета символов, позиции и длины слов при нормализации фраз. В этой же закладке настраиваются значения коэффициента прогресса для усиления коэффициента релевантности.
2. Нормализация.
Перед расчетом коэффициента релевантности для двух фраз желательна их нормализация с учетом содержания и качества справочников. Для того, чтобы при нормализации фраз выполнялся какой-либо пункт, достаточно напротив него поставить галочку.
При поиске кодов контрагентов можно настроить маску разделения пробелами, согласно которой все цифровые значения будут разделяться пробелами. Например, если маска равна 223 (структура ИНН), то все встречаемые числа будут преобразованы к виду ## ## ### ####.
При поиске наименований материалов желательно настроить замену размеров и теххарактеристик, в которых цифровые значения и размерности могут писаться слитно. Например, все «мм», встречающиеся после групп цифр заменять на « мм». Возможно три варианта замен: стоки, идущие за цифрами (мм, см, м и т. д.), перед (ф, d, Ду и т. д.) и между.
Внимание: замены происходят циклически и нельзя, чтобы они друг другу противоречили.
Также можно настроить справочники замен, особых слов и весовых коэффициентов.
3. Весовые коэффициенты.
Справочник коэффициентов влияния параметров слов при расчете коэффициента релевантности.
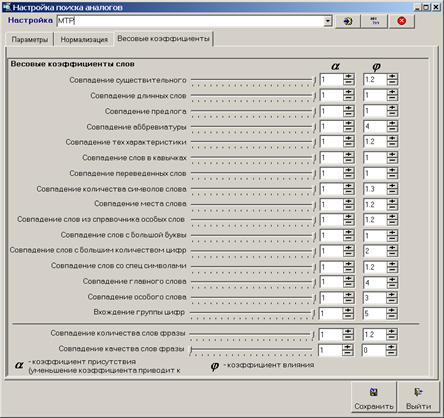
Примечание: при настройке таблицы расчета коэффициента релевантности важно помнить, что к разным типам справочников нужен разный подход. Например, при поиске контрагентов совершенно не важны настройки, связанные с теххарактеристиками, которые играют немаловажную роль в справочнике материалов.
Настройка справочников сокращений и аббревиатур.
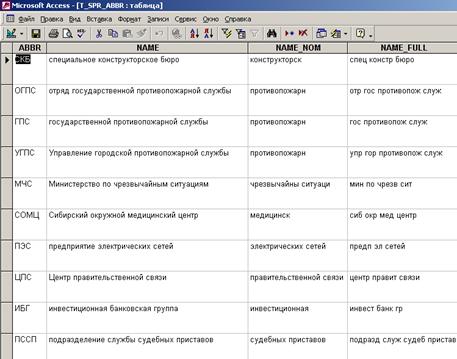
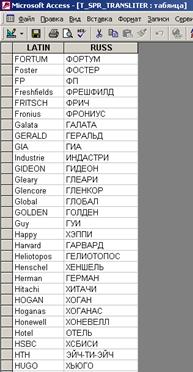
Для получения вариаций сокращений и аббревиатур необходимо настроить справочник вариантов сокращений. Справочная таблица сокращений должна содержать поле с искомым названием, поле с расшифрованным названием и полем поиска аббревиатур. В процессе варьирования искомого предложения каждое слово предложения будет сравниваться с искомым и при совпадении строиться новое предложение с дополнением расшифровки. Также буде произведен поиск значений из поля поиска аббревиатур (если оно не пустое) и при совпадении добавлена аббревиатура. Аналогично работает механизм расшифровки транслитераций.
Следует учесть, что каждая дополнительная вариация поиска запускает НОМ механизм заново и требует соответственно дополнительное время. Результат поиска дополнительной вариации объединяется с ранее найденными записями (ограничения количества записей в данном случае действуют на каждый из вариантов поиска, а не на весь объем найденных записей).
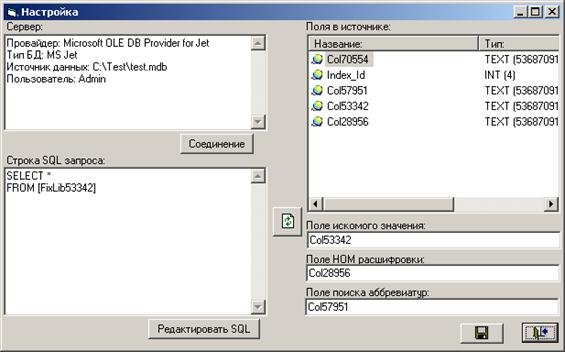
Пример структуры вспомогательных справочников
Справочник аббревиатур:
Справочник транслитераций и весовых коэффициентов:
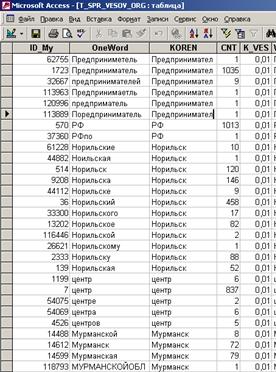
Ручной НОМ-поиск.
Идеология условий для ручного НОМ поиска примерно аналогична рассмотренному варианту LIKE поиска. Исключение составляет то, что поиск ведется по одному основному полю. Из комбинации слов входной фразы, вариации ее длины строятся специфичные запросы к базе поиска. Полученная таким образом информация в дальнейшем отсеивается с использованием настройки коэффициента релевантности.
Пример рисунка формы для шага НОМ поиска смотрите ниже.





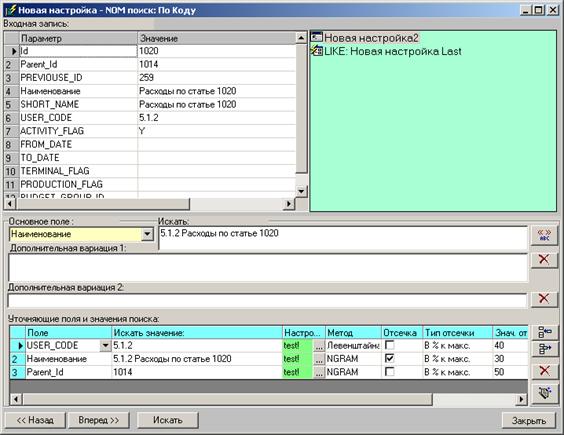
Если подключены справочники транслитерации и расшифровки аббревиатур при открытии формы происходит автоматическое варьирование фразы поиска. Дополнительные варианты с расшифровкой появляются в окнах дополнительных вариаций поиска. Для дополнительного запуска механизма вариаций (при ручном задании основной фразы поиска) предусмотрена соответствующая кнопка. Кнопка «Искать» запускает механизм НОМ поиска.
Вид формы поиска с НОМ результатом аналогичен шагу LIKE результата. Основное отличие состоит в появлении дополнительных полей в таблице результата, с префиксом «К2» скомбинированным с названием поля для которого он был рассчитан. Заголовки столбцов с «К2» дополнительно выделяются цветом.
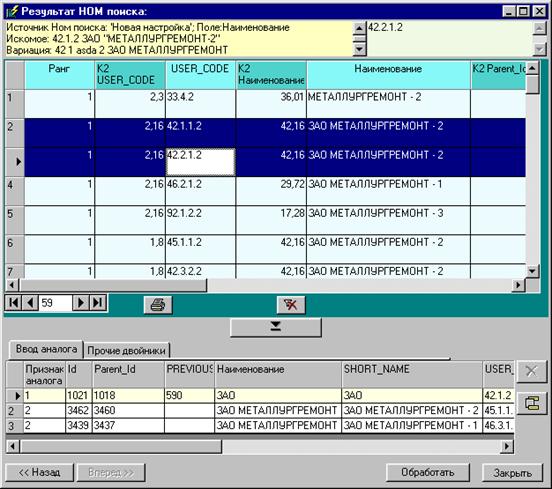
На рисунке ниже показана форма настройки НОМ параметров и справочников вариаций.
Для настройки механизма НОМ поиска и справочников вариаций нужно нажать клавишу «Ctrl» на клавиатуре, при этом появится кнопка открытия формы настройки.
В верхней части формы имеются окна ограничивающие количество найденных записей для НОМ поиска.
Ограничивать значения следует осторожно. Ограничение по ранжированию предложения – ограничивает количество поиска записей при поиске комбинации слов (не менее двух любых найденных слов из предложения и не более количества слов в предложении за вычетом единицы). Из основного искомого предложения строится новое поисковое предложение, в котором слова укорачиваются для получения более широко охватывающего поиска. Для этого метода также существует два типа ограничения. Правильной представляется идеология снятия ограничений на количество найденных записей, но это в свою очередь требует больших временных затрат при поиске.
Комбобокс «Поле идентификатора» позволяет выбрать поле идентификатора записи (если ранее не настраивалось в основной настройке диалога). Справочник исключаемых слов необходим для нормирования искомого предложения при поиске и исключения слов, не имеющих смысла при поиске и дающих только лишние паразитные записи результата (например «НПО», «ОАО» и т. п.). Справочник должен представлять собой любую таблицу, в одном поле, которого находятся исключаемые слова (по одному на запись таблицы). Настройка справочника исключаемых слов довольна простая и будет рассмотрена ниже.
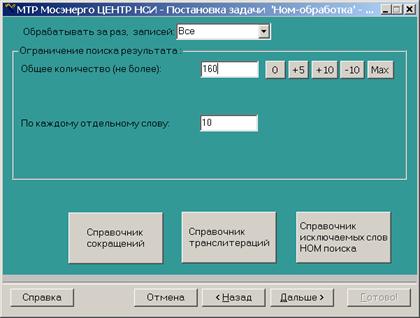
Автоматический НОМ-поиск.
Кроме вызова НОМ-поиска для одной записи можно запустить задачу автоматического НОМ-поиска для многих записей. Настройка и вызов автоматического поиска происходит в ETL-сервере. В форме задачи указываются источник и поисковый справочник (это может быть SQL-запрос или массив Data Cache), индексные и поисковые поля, mdb-файл, в котором будет сохраняться результат.
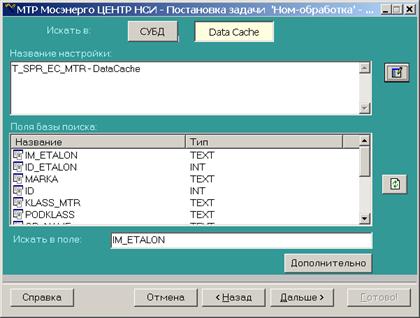
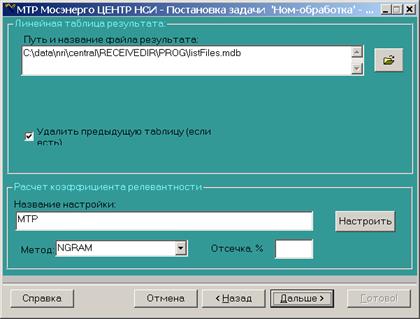
Количество найденных аналогов для фразы в целом и по отдельным словам ограничено значениями, прописанными в поле «Общее количество (не более)» и «По каждому отдельному полю». Так же, как и при ручном поиске, можно настроить справочники сокращений, транслитераций и исключений.
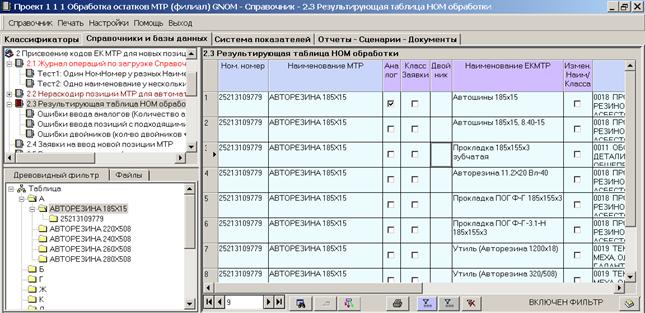
Результат автоматического подбора аналогов записывается в результирующую таблицу НОМ-обработки, в которой слева (столбец Наименование МТР) находится новое значение МТР, а справа (столбец Наименование ЕКМТР) — найденные в результате НОМ-обработки возможные аналоги. Коэффициент релевантности К2 показывает степень соответствия найденной позиции справочника МТР нераскодированному значению, чем он больше, тем более схожи наименования.
Основная задача пользователя — в массиве возможных аналогов выявить максимальное количество прямых аналогов, отмечая их флагом в поле «Аналог». Для каждой позиции может быть отмечен только один прямой аналог.
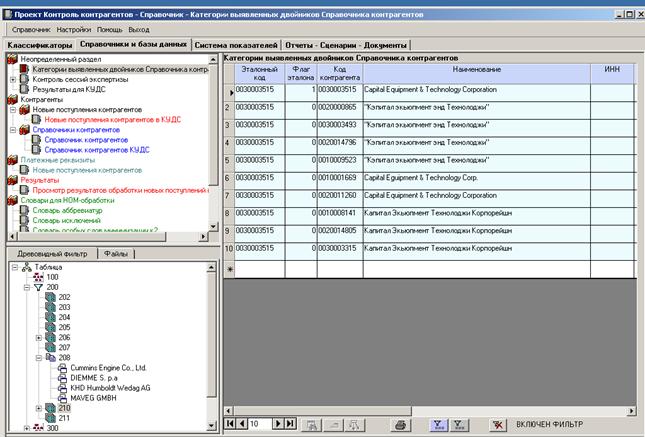
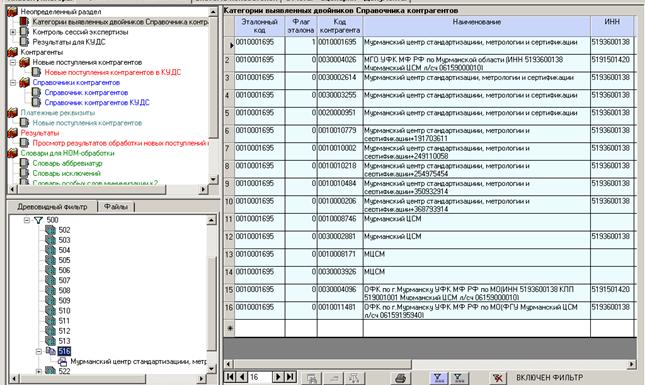
Примеры выявленных двойников в справочнике контрагентов:
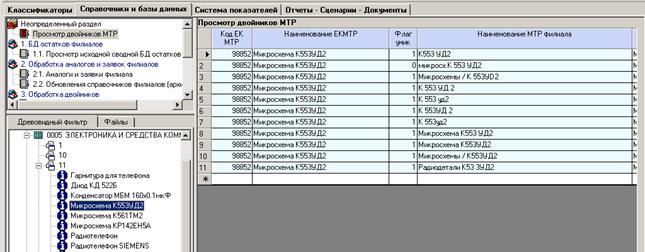
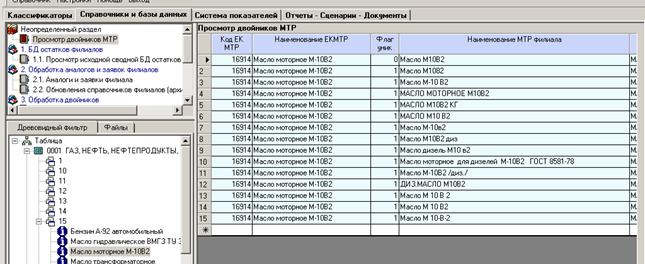
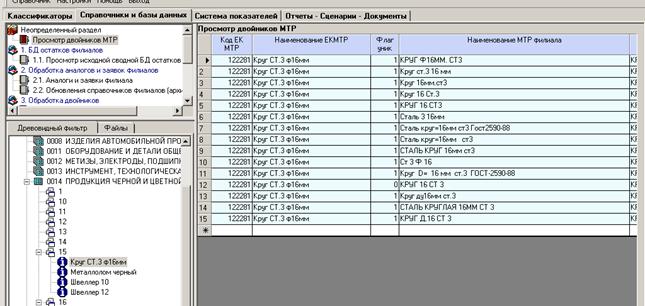
Примеры выявленных двойников в справочнике МТР:
Математическая постановка задачи и методы решения.
Постановка задачи.
Определим коэффициент сходства двух строк как число от 0 до 1. Пусть имеется функция f(S1, S2) от двух строк, которая осуществляет отображение меры сходства двух строк на отрезок [0; 1], где 1 соответствует полному смысловому совпадению строк.
Пусть существует множество пар строк, которые считаются одинаковыми в смысловом плане даже при их формальном несовпадении. В этом случае задача состоит в том, чтобы определить функцию коэффициента сходства таким образом, чтобы на этих парах строк функция принимала бы максимальные значения. Ослабив условие строгого максимума, можно сказать, что функция сходства не должна принимать значения меньше порогового коэффициента на таких парах строк.
Итак, если множество пар строк обозначить как S0, а функцию от двух строк – f(S1, S2), то формальная постановка задачи записывается так:
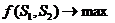 для всех пар строк <S1, S2> Î S0 при условии
для всех пар строк <S1, S2> Î S0 при условии 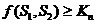 , где Kп – пороговый коэффициент сходства.
, где Kп – пороговый коэффициент сходства.
При ослабленном условии необходимо всего лишь найти такую функцию f, значение которой на данном множестве будет больше заданного порогового коэффициента Kп.
Основная работа по нахождению функции f в данной задаче находится тремя методами: методом вычисления редакционного расстояния (расстояния Левенштайна) и двумя методами, использующими N-граммы. В качестве дополнительных условий сравнения строк используется частичный формальный синтаксический анализ строк.
Задача нахождения редакционного расстояния (иначе, оптимального выравнивания) представляет собой задачу динамического программирования. Редакционное расстояние представляет собой последовательность операций вставки, удаления и замены символа /!!!!!/. Редакционное расстояние будет минимальным, если будет минимальна функция
d(S1,S2) = k1I + k2R + k3D + k4M, где
I – количество операций вставки символа,
R – количество операций замены символа другим символом,
D – количество операций удаления символа,
M – количество «пустых» операций, когда на шаге не делается ничего.
Коэффициенты ki в зависимости от конкретного применения выбираются различными. В данной задаче k1=k2=k3=1, а k4=0. Программная реализация системы позволяет выбирать k2 в зависимости от того, какой именно символ каким заменяется (алфавитно-взвешенное редакционное расстояние).
Соответственно, искомая функция сходства строк выглядит так:
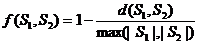 , где
, где
d(S1,S2) – редакционное расстояние между строками S1 и S2,
|S1|, |S2| – длины строк S1 и S2.
При использовании методов, основанных на N-граммах, математически задача сводится к разбиению обеих сравниваемых строк на множество N-грамм, нахождение среди них повторяющихся элементов и вычисление пересечения и объединения множеств N-грамм первой и второй строки.
Алфавитом для строк в данном случае являются буквы русского алфавита, цифры и специальные символы (например, кавычки). Допустим, есть слово A = a1a2a3a4a2a3 и слово B = b1b2a4a2a3, а длина N-граммы равна двум. Задача заключается в том, чтобы найти все кортежи вида <a1, a2>, <a2, a3>,…, <b1, b2>,…. Также предполагается дополнение слов начальным и конечным пробелом, т. е. в данном примере необходимо учесть кортежи вида <_, a1>, <a3, _>,….
После разбиения строк на множество кортежей необходимо вычислить коэффициент Пфайфера, который определен как
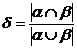 , где a и b – множества N-грамм слов А и В.
, где a и b – множества N-грамм слов А и В.
Методы решения.
Итак, сравнение строк в данной задаче производится методом вычисления минимального редакционного расстояния и методами, основанными на N-граммах.
Метод вычисления минимального редакционного расстояния
С помощью динамического программирования находится редакционное расстояние между двумя строками.
Для двух строк, S1 и S2, значение d(i, j) определяется как редакционное расстояние между S1[l..i] и S2[1..j].
Значит, d(i, j) определяет минимальное число редакционных операций, необходимых для преобразования первых i символов S1 в первые j символов S2. При использовании этой нотации если |S1|= n и |S2| = т, то редакционное расстояние между S1 и S2 равно в точности значению d(n, т).
Чтобы найти d(n, т), надо решить более общую задачу вычисления значений d(i, j) для всех комбинаций i и j, когда i меняется от 0 до n, a j от 0 до т. Это стандартный подход динамического программирования, применяемый в большом числе вычислительных задач.
Рекуррентное соотношение задаёт рекурсивное отношение между значением d(i, j) для положительных i и j и значениями d с индексными парами, меньшими i, j. Когда меньших индексов нет, значение d(i, j) должно получаться явно из условий, которые будем называть базовыми условиями для d(i, j).
Для задачи о редакционном расстоянии базовые условия таковы:
d(i, 0) = i
d(0, j) = j
Базовое условие d(i, 0) = i очевидно корректно (т. е. оно даёт число, требуемое определением d(i, 0)), так как единственный способ преобразования первых i символов S1 в нуль символов S2 заключается в удалении всех этих i символов. Аналогично, условие d(0, j) = j корректно, потому что для преобразования нуля символов S1 в j символов S2 требуется вставить j символов.
Рекуррентное соотношение для d(i, j), когда i и j строго положительны, выглядит так:
d(i, j) = min{d(i–1, j)+1, d(i, j–1)+1, d(i–1, j–1)+t(i, j)},
где значение t(i, j) no определению равно 1, если S1(i)![]() S2(j), и 0, если S1(i) = S2(j).
S2(j), и 0, если S1(i) = S2(j).
Соответственно, значение d(n,m), вычисленное из рекуррентного соотношения для d(i–1, j)+1, d(i, j–1)+1, d(i–1, j–1)+t(i, j), дает минимальное редакционное расстояние для строк S1 и S2. Таким образом, функция сходства двух строк S1 и S2 находится как
![]() . (0)
. (0)
Этот же метод может быть применен для решения задачи о наибольшей общей подстроке. Ее можно найти, если известны все оптимальные редакционные предписания. Соответственно, наибольшей общей подстрокой будет та подстрока, для которой максимально значение M-операций (пустых операций), идущих друг за другом. Это значение и соответствующую ему подстроку можно найти любым переборным методом, просмотрев все полученные в результате решения задачи оптимальные предписания.
Методы решения с использованием N-грамм
N-граммы представляют собой конструкции из N символов, идущих в строке подряд. Как было сказано выше, все строки дополняются начальным и конечным пробелами. Используя различные значения N, можно улучшить либо ухудшить результат сравнения в зависимости от характера сравниваемых строк. Для данной работы N принимается равным двум и все последующие алгоритмические вычисления делаются с учетом неизменности N в течение всего времени работы программы.
Рассмотрим две строки:
S1 = a1 a2 a3 a4 a5
S2 = b1 b2 a3 a4 a5
Каждое из слов дополняется начальным и конечным пробелами. Значение N принимается равным двум и слова разбиваются на диграммы следующим образом:
a = { _a1, a1a2, a2a3, a3a4, a4a5, a5_ }– множество диграмм первого слова.
b = {_b1, b1b2, b2a3, a3a4, a4a5, a5_ } – множество диграмм второго слова.
Тогда
a Ç b = { a3a4, a4a5, a5_ } – пересечение множеств диграмм первого и второго слова.
a È b = { a1, a1a2, a2a3, a3a4, a4a5, a5_, _b1, b1b2, b2a3 } – объединение множеств диграмм первого и второго слова.
| a Ç b | – мощность множества a Ç b.
| a È b | – мощность множества a È b.
Очевидно, что | a Ç b | = 3 , | a È b | = 9.
Тогда коэффициент Пфайфера, определяющий меру сходства строк вычисляется по формуле (0):
В данном случае 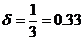 .
.
Таким образом, один из методов, основанный на N-граммах, подразумевает построение множеств N-грамм сравниваемых строк и вычисление отношения мощности пересечения множеств N-грамм первой и второй строки к мощности их объединения.
В качестве более сложного метода взят метод поиска совпадений с использованием так называемого «строкового графа», который представляет собой следующую конструкцию:
Допустим, сравниваются две строки «прокат» и «проект». Разбив эти слова, дополненные начальным и концевым пробелами, на диграммы, можно построить следующую зависимость:
_п ® пр ® ро ® ок ® ка ®ат ®т_
_п ® пр ® ро ® ое ® ек ® кт ® т_
Из примера видно, какие именно диграммы присутствуют в обеих строках: «_п», «пр», «ро», «т_». Стрелки на схеме показывают порядок следования N-грамм в слове. Можно сказать, что та диграмма, из которой выходит стрелка, является порождающей, а в ту, в которую входит – порождаемой диграммой. Если все диграммы записать в заголовках строк и столбцов некой таблицы, можно построить матрицу смежности ориентированного графа, вершинами которого являются диграммы.
В данном примере граф порождения диграмм выглядит так:
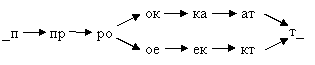

Рисунок 0. Граф, построенный на диаграммах
Матрица смежности для этого графа выглядит так:
Таблица 0. Матрица смежности для графа, построенного на диграммах
_п | пр | ро | ок | ка | ат | т_ | ое | ек | кт | |
_п | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
пр | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
ро | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
ок | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
ка | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
ат | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
т_ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
ое | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
ек | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
кт | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
Суть метода сводится к решению задачи о нахождении всех «развилок» в построенном графе и вычислению длин всех цепочек, которые находятся «вне» разветвлений. Иначе говоря,
а) из одной вершины в другую должен вести один и единственный путь,
б) исходя из вершины, с которой начинается цепочка, можно дойти в ту и только в ту вершину, где начинается развилка, либо в терминальную вершину (вариант, когда совпадают суффиксы строк).
Алгоритмически задача сводится к нахождению пересечения путей из всех вершин, в которые не входит ни одно ребро, до тех вершин, из которых ни одно ребро не выходит. Задачу можно решить, перенумеровав вершины графа и запоминая на каждом шаге из вершины к вершине их номера. Пути записываются в виде множества кортежей, первый элемент которых – вершина, из которой начинается шаг, а второй – вершина, где шаг кончается. Пройдя по всем возможным путям такого рода и взяв пересечение множеств кортежей для каждого пути, находятся общие участки пути в графе.
Мера сходства в данном случае определяется как сумма длин путей всех неразветвленных цепочек к максимальной длине пути между вершинами в графе.
Метод был разработан в основном для нахождения орфографических ошибок в словах, нахождения однокоренных слов в строках и нахождения максимальной общей подстроки двух строк.
Можно проиллюстрировать применение всех вышеизложенных методов сравнения строк на примере сравнения слов «прокат» и «проект».
Построим таблицу для вычисления редакционного расстояния между словами «прокат» и «проект». Значения в нулевой строчке и нулевом столбце определяются из базовых условий (0).
d(i, j) | п | р | о | к | а | т | ||
0 | 1 | 2 | 3 | 4 | 5 | 6 | ||
0 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
п | 1 | 1 | 0 | 1 | 2 | 3 | 4 | 5 |
р | 2 | 2 | 1 | 0 | 1 | 2 | 3 | 4 |
о | 3 | 3 | 2 | 1 | 0 | 1 | 2 | 3 |
е | 4 | 4 | 3 | 2 | 1 | 1 | 2 | 3 |
к | 5 | 5 | 4 | 3 | 2 | 1 | 2 | 3 |
т | 6 | 6 | 5 | 4 | 3 | 2 | 2 | 2 |
Значения таблицы получаются из рекуррентных соотношений (0), значение в каждой ячейке таблицы представляет собой редакционное расстояние между префиксами первой и второй строки длины i и j соответственно. Таким образом, значение в правом нижнем углу таблицы дает искомое минимальное редакционное расстояние.
Мера сходства между строками рассчитывается по формуле (0) и для данного примера будет равна 2/3:
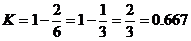
Рассмотрим пример нахождения меры сходства по первому методу N-грамм.
Рассмотрим множество a = { _п, пр, ро, ое, ек, кт, т_ }– множество диграмм первого слова и множество b = {_п, пр, ро, ок, ка, ат, т_ } – множество диграмм второго слова.
Тогда пересечением множеств диграмм первого и второго слова a Ç b будет множество {_п, пр, ро, т_ }.
Соответственно, объединением a È b будет множество
{_п, пр, ро, ое, ек, кт, ок, ка, ат, т_ }.
Мощности множеств будут соответственно равны: | a Ç b | = 4 и | a È b | = 10.
Тогда по формуле (0) коэффициент релевантности между словами «прокат» и «проект» 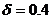 .
.
Рассмотрим использование второго метода N-грамм на данном примере. В соответствии с рисунком (0), можно записать все нужные пути в строковом графе:
_п ® пр ® ро ® ок ® ка ®ат ®т_
_п ® пр ® ро ® ое ® ек ® кт ® т_
Длина каждого из путей равна 7.
Общими для всех путей являются вершины «_п», «пр», «ро» и «т_». Количество таких вершин для данного примера равно 4.
Мера сходства находится как отношение количества вершин, общих для всех путей, к количеству вершин в самом длинном пути в графе, для данного примера d = 4/7 » 0,.
Формальный синтаксический анализ
Все описанные выше методы являются в той или иной степени формальными методами, которые не учитывают особенности русского языка в построении наименований предприятий, для работы с которыми и была создана данная система.
Разумеется, все формальные методы будут давать хорошие результаты для тех строк, которые мало отличаются друг от друга, например, при наличии орфографических ошибок в словах.
При разработке прототипа системы были опытным путем получены пороговые коэффициенты для меры сходства. Для метода нахождения минимального редакционного расстояния все строки из тестовой совокупности, значение меры сходства которых было больше 0.8, оказались одинаковыми (в смысле, который был предусмотрен заказчиком). Для методов, основанных на N-граммах, пороговый коэффициент равен 0.7.
Изначально было предусмотрено только сравнение строк как таковых, но для более точного анализа строк было принято решение в тех случаях, когда мера сходства оказывается хоть и достаточно высокой, но все же недостаточной (ниже пороговых значений), чтобы по ней можно было однозначно назвать строки одинаковыми в данном смысле, использовать дальнейший формальный синтаксический анализ построения фраз с использованием сравнения не строк, а слов, входящих в строки.
Известно, что каждому слову, входящему, к примеру, в наименование торговой фирмы, соответствует некоторое количество формальных атрибутов, например:
- является ли слово частью названия фирмы;
- является ли слово указанием на территориальное расположение контрагента и так далее.
Путем логического анализа существующих справочников фирм-контрагентов были найдено более десятка подобных атрибутов для каждого слова, входящего в наименование контрагента.
Ярким примером подобного атрибута являются слова, заключенные в кавычки. В соответствии с синтаксисом русского языка, в кавычки заключаются непосредственно названия фирм. В разных справочниках при сохранении записанного в кавычках названия часто оставшиеся за кавычками слова просто опускают. Тогда для получения адекватных результатов надо учитывать то, что совпадение (четкое или нечеткое) слов, заключенных в кавычки, намного больше влияет на то, что строки одинаковы в данном смысле, нежели совпадение тех слов из строк, которые находятся за кавычками.
Для того, чтобы учесть все найденные при сравнении слов атрибуты, был разработан алгоритм, который позволяет учесть их и разбить множество строк, сравниваемых с эталонной строкой, на несколько групп, объединенных по степени сходства с учетом наличия тех или иных атрибутов для слов в сравниваемых строках.
Алгоритм формального синтаксического анализа
Пусть имеются две строки S1 и S2, состоящие из N и M слов соответственно. Базы данных в программе построены таким образом, что в качестве S1 берется строка из той таблицы, значения которой мы принимаем за эталон или исходную точку, а в качестве S2 – последовательно берутся те строки, которые являются возможными аналогами эталонной строки.
Далее производится разбивка каждой пары строк (эталон, кандидат) по словам. Дальнейшие сравнения будут производиться для всех пар слов, входящих в первую и вторую строки. Каждому слову из первой строки сопоставляется каждое слово из второй строки.
Все пары слов сравниваются между собой по любому из методов нечеткого сравнения, описанных выше. Для каждой пары строк рассматриваются пары слов, в которых достигнута мера сходства, большая порогового значения для того метода, который использовался для их сравнения.
Для каждой пары слов проводится учет факторов (атрибутов):
1. Совпадение имен существительных. В текущей реализации программы существует справочник имен существительных, и тот случай, когда совпадают существительные, имеет большее значение в плане сходства, нежели совпадение других частей речи.
2. Совпадение длинных слов. Как правило, длинные слова обозначают либо одно из частей собственно названия контрагента, либо (менее распространено) – его сущность («мясокомбинат»).
3. Совпадение аббревиатур. Исключая общеупотребительные аббревиатуры, используемые для обозначения юридической формы устройства предприятия (ЗАО, т. д.), совпадение аббревиатур часто указывает на совпадение сущностей, а иногда и названий фирм.
4. Совпадение слов в кавычках. Как и было описано выше, слова в кавычках позволяют с весьма большой вероятностью определить название фирмы-контрагента.
5. Совпадение переведенных слов. В программе предусмотрена возможность транслитерации из латиницы в кириллицу. Практически всегда записанное латиницей слово является частью названия фирмы.
6. Совпадение количества символов слова. Иногда позволяет (в частности, при вычислении редакционного расстояния) сделать вывод о похожести строк.
7. Совпадение места слова. Порядок слов в строках важен для данной системы: перестановка слов в наименовании фирмы встречается очень редко.
8. Совпадение слов из справочника исключений. Можно определить небольшой словарь исключений (в основном используется для ручной обработки результатов работы программы), который будет содержать, возможно, те слова, которые не подходят под действие ни одного из этих факторов.
9. Совпадение слов с большой буквы. Достаточно очевидный фактор – названия фирм являются именами собственными.
10. Совпадение слов с большим количеством цифр. Для государственных учреждений часто используются различные коды и цифры в наименовании, они, как правило, уникальны и наличие данного фактора сильно свидетельствует в сторону похожести строк.
11. Совпадение главного слова. Наличие данного фактора объясняется тем, что программа может сравнивать не только строковые наименования фирм, но и любые другие их строковые атрибуты, например, как ИНН фирмы. Опять же, в силу уникальности, совпадение ИНН говорит о совпадении контрагентов. К сожалению, не во всех записях справочников имеется данное (или похожее) поле.
Далее рассчитывается коэффициент совпадения строк k2 по формуле
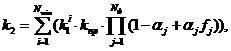 где
где
Nmin – минимальное количество слов в каждой фразе из пары (иначе говоря, максимальное количество слов в фразах, которые могут совпасть);
(Nmin – количество пар слов, совпадающих с максимальным значением коэффициента, превышающем пороговое значение.)
Nф – количество факторов, учитываемых для данной пары слов;
k1 – значение посчитанного коэффициента сходства для i-й пары слов;
kпр – коэффициент прогресса, который рассчитывается следующим образом: если k1=1, то kпр=8; если 0.9<=k1<1, то kпр=5; если kпор<=k1<0.9, то kпр=3;
αj – коэффициент присутствия j-го фактора;
fj – коэффициент влияния j-го фактора.
Расчет влияния количества слов:
![]()
αкол – коэффициент присутствия количества слов фразы;
fкол – коэффициент влияния количества слов фразы.
Расчет влияния качества слов:
![]()
αкач – коэффициент присутствия качества слов фразы;
fкач – коэффициент влияния качества слов фразы.
