


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Сайт ВИО (vio. *****) – электронный журнал «Вопросы Интернет-образования»
Выдержки из статьи http://vio. *****/vio_28/cd_site/Articles/art_2_3.htm
,
Составление частотного словаря слов средствами Microsoft Office
Написать эту статью побудили три материала, опубликованные в журнале.
1. Замечательная статья Ирины Алексеевны Морозовой «Коллективное лингвистическое исследование» о составлении частотного словаря букв русского алфавита [1]. На основе этой статьи можно организовать увлекательный урок, внеклассное мероприятие, она может стать основой исследовательской работы. Так что, если у статьи могут быть фанаты, то мы относимся к их числу.
2. Константин Алексеевич Попов «Использование частотных словарей при изучении иностранных языков» [2]. В этой статье рассматривается использование генераторов частотных словарей в учебном процессе.
3. «Все на борьбу с рутиной!» Павла Юрьевича Белкина и дальнейшее обсуждение этой статьи, в которой рассматривается проблема поиска и замены символов в MS Word [3]-[5].
Как у нас, так и у учеников, возник вопрос: «А можно ли средствами стандартных программ, без обращений к специальным, составить частотный словарь слов одного или нескольких произведений?»
В результате совместных изысканий появился способ, прямо скажем, не лишенный недостатков, который, однако, работает. Он может служить хорошей иллюстрацией глубокой интеграции офисных программ пакета Microsoft Office и хорошим практикумом для уроков компьютерных технологий.
Как можно использовать частотный словарь? Увлекательный рассказ о статистическом лексическом анализе можно найти по адресу http://euro. svoboda. org/programs/sc/2001/sc.062601.asp. Там же есть и предостережение от излишнего увлечения такими методами.
Итак, наша идея состоит в следующем: удалить из текста все знаки кроме букв русского языка, получив, таким образом, список слов, а затем отсортировать его и, сгруппировав одинаковые слова, подсчитать количество слов в каждой группе.
Далее, собственно, сам способ:
Сначала откроем анализируемый текст в Microsoft Word.
Шаг 1. Уберем из текста точки, запятые, цифры, латинские буквы и… В принципе, избавимся от всего, кроме букв русского алфавита. Это можно сделать с помощью пункта меню Правка\Заменить. При поиске необходимо использовать отрицание [!] и подстановочные знаки [А-я]. Запрос на все символы, кроме букв русского алфавита, будет выглядеть так [!А-я]. Заменять будем на пробел, хотя это и необязательно. Можно использовать на любой другой символ, например, @ или специальный символ ^p («символ абзаца»). Нажимаем кнопку Заменить все.
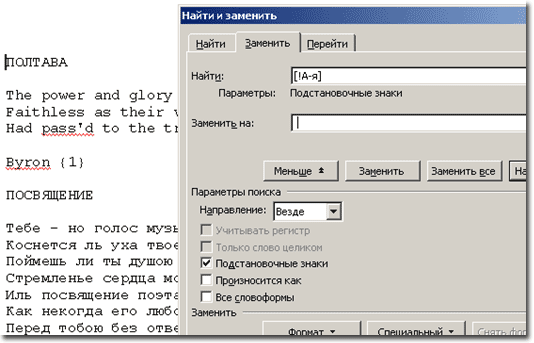
Шаг 2. Убираем из текста лишние пробелы, заменяя двойные на одиночные до тех пор, пока двойные еще встречаются [5].
Шаг 3. Преобразуем весь текст к верхнему регистру Формат\Регистр\ВСЕ ПРОПИСНЫЕ, предварительно выделив весь текст Правка\Выделить все.
Шаг 4. Преобразуем текст в таблицу Таблица\Преобразовать\текст в таблицу. В качестве разделителя используем пробел. Данная таблица характерна тем, что у нее один столбец и в каждой ячейке стоит отдельное слово.
Шаг 5. Выделяем полученную таблицу и копируем в буфер обмена.
Далее можно воспользоваться одной из двух других знаменитых офисных программ: Microsoft Excel или Microsoft Access.
Для Microsoft Excel:
Шаг 6. Создаем новую книгу Excel.
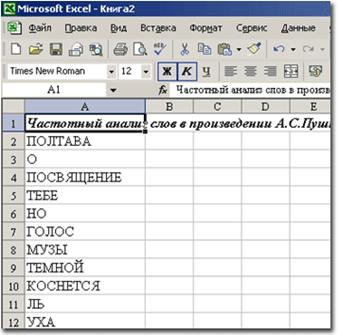
Шаг 7. В ячейке A1 пишем заголовок: «Частотный анализ слов в произведении «Полтава».
Шаг 8. Вставляем таблицу из буфера обмена, начиная с ячейки A2.
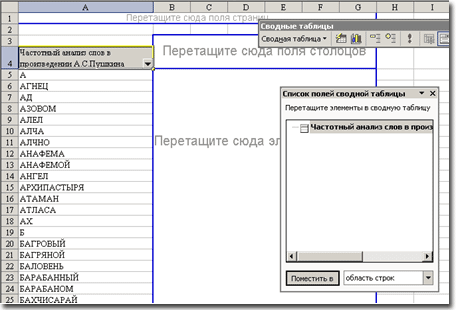
Шаг 9. На отдельном листе создаем сводную таблицу Данные\Сводная таблица. Это ли не повод рассказать ученикам о сводной таблице!
Шаг 10. Нажмите клавишу Поместить в. Мы увидим отчет из слов встречающихся в произведении. Для того чтобы вывести количество вхождений данного слова в текст, достаточно перетащить элемент в сводную таблицу. По умолчанию будет как раз вычисляться количество повторений этого слова, что собственно нам и нужно. Таким образом, мы получили частотный словарь. Далее его можно изменять по своему усмотрению. Изменяя свойства поля можно отсортировать сводную таблицу по убыванию, подсчитать долю слов в произведении, добавить столбец с длиной слов и т. п.
Для Microsoft Access:
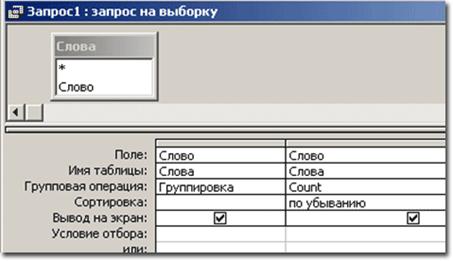
Шаг 6. Создаем новую базу данных. В режиме конструктора создаем таблицу «Слова» с полем [Слово].
Шаг 7. Переходим в режим таблицы и Вставляем таблицу из буфера обмена.
Шаг 8. Создаем запрос на выборку, используя групповые операции и функцию Count, подсчитывающую сумму по группе. При необходимости сортируем по нужному полю.
Замечание: можно решить эту задачу только с помощью Word и макросов на языке Visual Basic for Application (VBA), но это не совсем соответствует поставленной задаче. С другой стороны, при таком подходе можно автоматизировать описанные выше действия. Можно также попробовать составить частотный словарь с учетом словоформ, правда, только для английского языка.
Последовательность действий будет примерно такой:
Шаг 1. Удаляем из текста все знаки, кроме букв русского языка.
Шаг 2. Удаляем из текста лишние пробелы.
Шаг 3. Устанавливаем один шрифт для всего текста. Выделяем и переводим в верхний регистр.
Шаг 4. Заменяем пробелы на символ конца абзаца.
Шаг 5. Сортируем по возрастанию.
Шаг 6. Составляем частотный словарь и вычисляем длину слов.
Шаг 7. Преобразуем в таблицу с тремя столбцами.
Шаг 8. Выводим во второй столбец количество вхождений данного слова, а в третий - его длину.
Шаг 9. Добавляем заголовок.
Большинство описанных выше операций можно просто записать в макросы с помощью режима «Запись макроса» (Сервис\Макрос\Начать запись).
……………………………………………………………………………..
Пример этих макросов находится в документе Частотный анализ слов_А_С_ Пушкин_ ПОЛТАВА. doc. Для выполнения макросов необходимо установить в пункте меню Сервис\Макрос\Безопасность уровень безопасности: «Низкий» или «Средний».
После изменения уровня безопасности -  перезапустите MS Word.
перезапустите MS Word.
Запустите форму my_form, нажав кнопку Составление словаря на панели Частотный анализ.
Если вы хотите, чтобы макросы были доступны для других документов, просто скопируйте их и панель с кнопкой с помощью «Организатора» в шаблон Normal. dot (Сервис\Шаблоны и надстройки…).
Ссылки на публикации
1.Морозова лингвистическое исследование (http://vio. *****/vio_04/cd_site/articles/art_2_10.htm)
2.Попов частотных словарей при изучении иностранных языков (http://vio. *****/vio_26/cd_site/articles/art_1_7.htm)
3.Белкин на борьбу с рутиной! (http://vio. *****/vio_18/cd_site/articles/art_1_15.htm)
4.Белкин «Борьбы с рутиной» (http://vio. *****/vio_19/cd_site/articles/art_2_3.htm)
5.Усенков «борьбы с рутиной»: PostScriptum (http://vio. *****/vio_20/cd_site/articles/art_2_3.htm)
