

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
По результатам Лабораторной работы №1 мы получили следующие данные:
Переменная | ADF Test | Result | ||
спецификация | ADF статистика | Критические значения | ||
in levels | C,2 | -6.682693 | -2.9399 | I(0) |
basic | C,2 | -6.682693 | -2.9399 | I(0) |
chain | N,0 | -6.163828 | -1.9495 | I(0) |
sootv per pr g | N,0 | -5.887691 | -1.9504 | I(0) |
narost itogom | T,1 | -6.680474 | -3.5426 | I(0) |
По результатам ADF теста все пять рядов( in levels, basic, chain, sootv per pr g, narost itogom) имеют спецификацию xt~I(0), т. е. стационарные ряды. Следовательно, для рядов TS строим модели ARMA.
1. Строим модель ARMA для ряда in levels, поскольку он имеет спецификацию xt~I(0),С, т. е. стационарный и имеет линейный тренд.
Строим коррелограм для исходного ряда in levels:
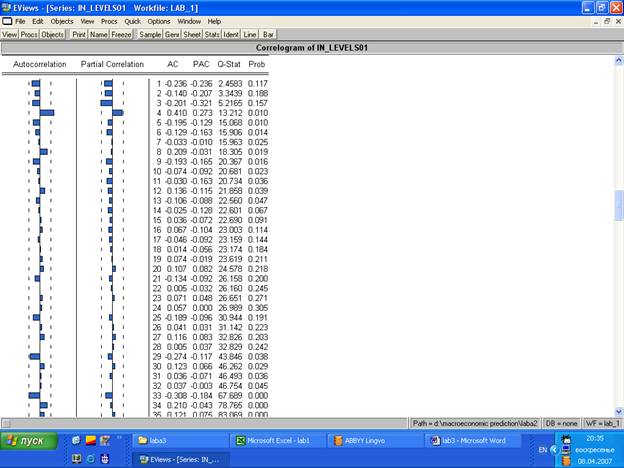
По поведению графиков Autocorrelation и Partial Correlation определяем порядок составляющих MA(q) и AR(p). По поведению Partial Correlation определяем, что порядок AR=3. По поведению МА делаем вывод о наличии сезонной составляющей.
Если существует сезонность, в модель нужно включить функцию X(-4). В нашем случае включаем функцию in levels(-4).
Исходя из полученных данных строим модель в объекте Equation, которая в общем виде имеет вид:
In levels01(-4) C AR(1) AR(2) AR(3)
Получаем результат:
Dependent Variable: IN_LEVELS01(-4) | ||||
Method: Least Squares | ||||
Date: 04/08/07 Time: 20:58 | ||||
Sample(adjusted): 1997:4 2006:4 | ||||
Included observations: 37 after adjusting endpoints | ||||
Convergence achieved after 3 iterations | ||||
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
C | 83.64004 | 19.77352 | 4.229902 | 0.0002 |
AR(1) | -0.354890 | 0.138994 | -2.553283 | 0.0155 |
AR(2) | -0.272458 | 0.141882 | -1.920315 | 0.0635 |
AR(3) | -0.328740 | 0.140172 | -2.345257 | 0.0252 |
R-squared | 0.247659 | Mean dependent var | 97.77297 | |
Adjusted R-squared | 0.179265 | S. D. dependent var | 257.9182 | |
S. E. of regression | 233.6596 | Akaike info criterion | 13.84741 | |
Sum squared resid | 1801695. | Schwarz criterion | 14.02157 | |
Log likelihood | -252.1772 | F-statistic | 3.621033 | |
Durbin-Watson stat | 1.834715 | Prob(F-statistic) | 0.023037 | |
Inverted AR Roots | .16+.68i | i | -.67 |
Построенная модель характеризуется очень низким качеством т. к. R-squared=0.247659. Далее улучшаем модель исключая незначимые переменные и добавляя новые переменные.
Вообще говоря, существует несколько методов построения моделей:
A. Метод экспертных оценок
B. Также можно вводить переменные и исключать, если эти действия приводят к увеличению надежности модели.
Начнем преобразование построенной модели. В построенной модели необходимо проанализировать ряд остатков Resid, построив correlogram для ряда остатков. У него не должно быть AR составляющей. Если существует AR, то в исходную модель нужно добавать MA составляющую.
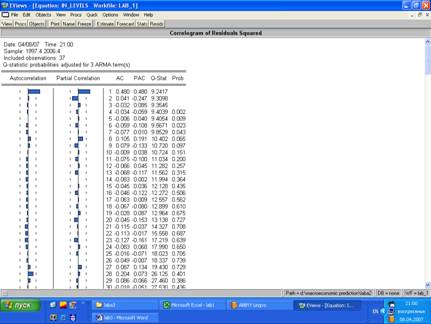
В нашем случае у ряда остатков существует AR cоставляющая, следовательно, в исходный ряд добавляем MA составляющую.
Модель в общем виде будет иметь вид:
In levels01(-4) C AR(1) AR(2) AR(3) МА(1)
Получаем результат:
Dependent Variable: IN_LEVELS01(-4) | ||||
Method: Least Squares | ||||
Date: 04/08/07 Time: 21:06 | ||||
Sample(adjusted): 1997:4 2006:4 | ||||
Included observations: 37 after adjusting endpoints | ||||
Convergence achieved after 10 iterations | ||||
Backcast: 1997:3 | ||||
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
C | 79.97326 | 21.67671 | 3.689364 | 0.0008 |
AR(1) | -0.566511 | 0.252683 | -2.241985 | 0.0320 |
AR(2) | -0.344304 | 0.165727 | -2.077538 | 0.0459 |
AR(3) | -0.420447 | 0.139115 | -3.022308 | 0.0049 |
MA(1) | 0.305013 | 0.312748 | 0.975267 | 0.3367 |
R-squared | 0.266275 | Mean dependent var | 97.77297 | |
Adjusted R-squared | 0.174559 | S. D. dependent var | 257.9182 | |
S. E. of regression | 234.3284 | Akaike info criterion | 13.87641 | |
Sum squared resid | 1757114. | Schwarz criterion | 14.09410 | |
Log likelihood | -251.7136 | F-statistic | 2.903268 | |
Durbin-Watson stat | 1.941873 | Prob(F-statistic) | 0.037115 | |
Inverted AR Roots | .12+.72i | i | -.80 | |
Inverted MA Roots | -.31 |
Если проверить после проведенных преобразований ряд остатков на наличие AR составляющей, то она будет присутствовать и в этом случае. Для того чтобы избавиться от AR составляющей увеличим порядок p до 4.
Далее путем преобразования модели, анализируя ряд остатков и принимая во внимание качество построенной модели, получаем следующую модель:
In levels01(-4) C AR(1) AR(4) AR(5) МА(1), ряд остатков которой не будет содержать AR составляющей, что говорит о том, что построенная модель правильная.
Получаем результаты:
Dependent Variable: IN_LEVELS01(-4) | ||||
Method: Least Squares | ||||
Date: 04/08/07 Time: 21:21 | ||||
Sample(adjusted): 1998:2 2006:4 | ||||
Included observations: 35 after adjusting endpoints | ||||
Convergence achieved after 53 iterations | ||||
Backcast: OFF (Roots of MA process too large for backcast) | ||||
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
C | 76.66913 | 22.82546 | 3.358931 | 0.0021 |
AR(1) | 0.746106 | 0.162248 | 4.598566 | 0.0001 |
AR(4) | 0.451360 | 0.132590 | 3.404167 | 0.0019 |
AR(5) | -0.638896 | 0.174425 | -3.662860 | 0.0010 |
MA(1) | -1.371322 | 0.310856 | -4.411434 | 0.0001 |
R-squared | 0.659367 | Mean dependent var | 86.94571 | |
Adjusted R-squared | 0.613949 | S. D. dependent var | 261.0928 | |
S. E. of regression | 162.2248 | Akaike info criterion | 13.14741 | |
Sum squared resid | 789506.5 | Schwarz criterion | 13.36960 | |
Log likelihood | -225.0796 | F-statistic | 14.51781 | |
Durbin-Watson stat | 2.475580 | Prob(F-statistic) | 0.000001 | |
Inverted AR Roots | .88+.33i | i | -.07+.89i | -i |
-.89 | ||||
Inverted MA Roots | 1.37 | |||
Estimated MA process is noninvertible |
Все переменные значимые в построенной моделе т. е. Prob<0,05, и R-squared достаточно высокий.
Мы получили модель вида:
Xt=a1xt-1+a4xt-4+a5xt-5+b1et-1+mt
Строим прогноз на 2 года вперед.
1996:1 | 180.6 |
1996:2 | 0.2 |
1996:3 | -803.7 |
1996:4 | 310.9 |
1997:1 | 263.6 |
1997:2 | 80.9 |
1997:3 | -162.7 |
1997:4 | 491.3 |
1998:1 | 384.3 |
1998:2 | 90.5 |
1998:3 | 79.8 |
1998:4 | 119.5 |
1999:1 | 71.3 |
1999:2 | 71.6 |
1999:3 | 68.5 |
1999:4 | 168.2 |
2000:1 | -18.3 |
2000:2 | -63.5 |
2000:3 | 40.2 |
2000:4 | 56.5 |
2001:1 | -35.1 |
2001:2 | 35 |
2001:3 | 117.7 |
2001:4 | 225.9 |
2002:1 | -41.7 |
2002:2 | 43.9 |
2002:3 | 39 |
2002:4 | 526.8 |
2003:1 | 8.5 |
2003:2 | -67.4 |
2003:3 | 120.4 |
2003:4 | 307.2 |
2004:1 | -232.3 |
2004:2 | 270.5 |
2004:3 | 20.9 |
2004:4 | 811.7 |
2005:1 | -812.6 |
2005:2 | -158.9 |
2005:3 | 6.7 |
2005:4 | 378.8 |
2006:1 | -575. |
2006:2 | -124. |
2006:3 | -222. |
2006:4 | 220. |
2007:1 | -579. |
2007:2 | -87. |
2007:3 | -52. |
2007:4 | 236. |
2008:1 | -192. |
Графически это будет выглядеть следующим образом:
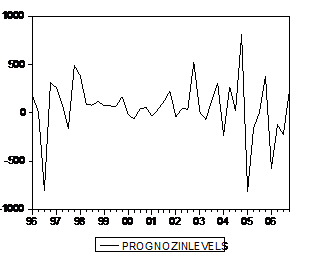
Прогноз показателя сравниваем с прогнозами, построенными в Лабораторной работе №2.
Показатели лабораторной 3 | |
2006:2 | -124. |
2006:3 | -222. |
2006:4 | 220. |
2007:1 | -579. |
2007:2 | -87. |
2007:3 | -52. |
2007:4 | 236. |
2008:1 | -192. |
Показатели лабораторной 2 | |
2006:2 | -48. |
2006:3 | -53. |
2006:4 | -58. |
2007:1 | -63. |
2007:2 | -68. |
2007:3 | -73. |
2007:4 | -78. |
2008:1 | -83. |
Аналогичным образом строим модели для оставшихся рядов basic, chain, sootv per pr g, narost itogom.
2.
Dependent Variable: BASIC(-4) | |||||
Method: Least Squares | |||||
Date: 04/08/07 Time: 21:48 | |||||
Sample(adjusted): 1998:2 2006:4 | |||||
Included observations: 35 after adjusting endpoints | |||||
Convergence achieved after 53 iterations | |||||
Backcast: OFF (Roots of MA process too large for backcast) | |||||
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
|
C | 0.424525 | 0.126387 | 3.358931 | 0.0021 |
|
AR(1) | 0.746106 | 0.162248 | 4.598567 | 0.0001 |
|
AR(4) | 0.451360 | 0.132590 | 3.404167 | 0.0019 |
|
AR(5) | -0.638896 | 0.174425 | -3.662860 | 0.0010 |
|
MA(1) | -1.371322 | 0.310856 | -4.411434 | 0.0001 |
|
R-squared | 0.659367 | Mean dependent var | 0.481427 |
| |
Adjusted R-squared | 0.613949 | S. D. dependent var | 1.445696 |
| |
S. E. of regression | 0.898255 | Akaike info criterion | 2.754837 |
| |
Sum squared resid | 24.20584 | Schwarz criterion | 2.977030 |
| |
Log likelihood | -43.20965 | F-statistic | 14.51781 |
| |
Durbin-Watson stat | 2.475580 | Prob(F-statistic) | 0.000001 |
| |
Inverted AR Roots | .88+.33i | i | -.07+.89i | -i |
|
-.89 |
| ||||
Inverted MA Roots | 1.37 |
| |||
Estimated MA process is noninvertible |
|
Строим прогноз на 2 года вперед:
1996:1 | 1 |
1996:2 | 0. |
1996:3 | -4. |
1996:4 | 1. |
1997:1 | 1. |
1997:2 | 0. |
1997:3 | -0. |
1997:4 | 2. |
1998:1 | 2. |
1998:2 | 0. |
1998:3 | 0. |
1998:4 | 0. |
1999:1 | 0. |
1999:2 | 0. |
1999:3 | 0. |
1999:4 | 0. |
2000:1 | -0. |
2000:2 | -0. |
2000:3 | 0. |
2000:4 | 0. |
2001:1 | -0. |
2001:2 | 0. |
2001:3 | 0. |
2001:4 | 1. |
2002:1 | -0. |
2002:2 | 0. |
2002:3 | 0. |
2002:4 | 2. |
2003:1 | 0. |
2003:2 | -0. |
2003:3 | 0. |
2003:4 | 1. |
2004:1 | -1. |
2004:2 | 1. |
2004:3 | 0. |
2004:4 | 4. |
2005:1 | -4. |
2005:2 | -0. |
2005:3 | 0. |
2005:4 | 2. |
2006:1 | -0. |
2006:2 | 0. |
2006:3 | -0. |
2006:4 | 1. |
2007:1 | -3. |
2007:2 | 0. |
2007:3 | 0. |
2007:4 | 1. |
2008:1 | -1. |
3. По поведению графиков Autocorrelation и Partial Correlation нельзя определить порядок составляющих MA(q) и AR(p). Это явление называется «белый шум». «Белый шум» –– случайный процесс, допускает представление в виде MA бесконечностей, но это теоретически, на практике такого не делают.
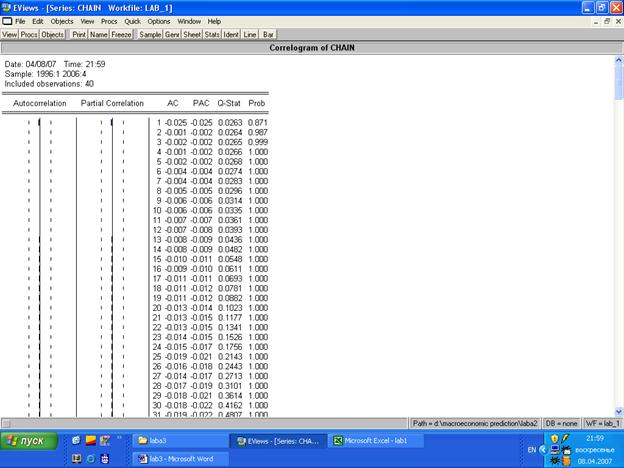
Следовательно, построить модель невозможно.
4. По поведению графиков Autocorrelation и Partial Correlation нельзя определить порядок составляющих MA(q) и AR(p), т. е. присутствует «белый шум».
Следовательно, построить модель невозможно.
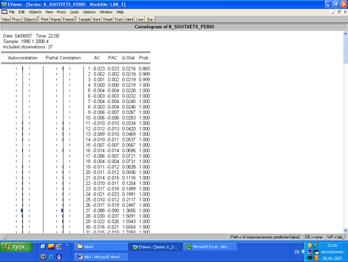
5. По поведению графиков Autocorrelation и Partial Correlation нельзя определить порядок составляющих MA(q) и AR(p), т. е. присутствует «белый шум».
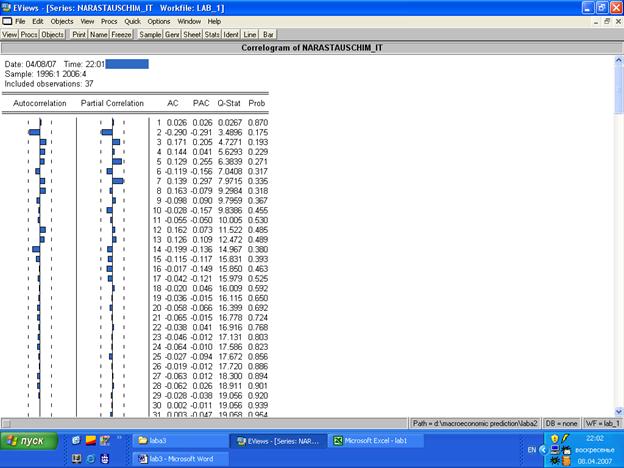
Следовательно, построить модель невозможно.
