
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Организация данных файлов
Физическое проектирование базы данных
Физическое проектирование базы данных - процесс подготовки описания реализации базы данных на вторичных запоминающих устройствах; на этом этапе рассматриваются основные отношения, организация файлов и индексов, предназначенных для обеспечения эффективного доступа к данным, а также все связанные с этим ограничения целостности и средства защиты.
Физическое проектирование является третьим и последним этапом создания проекта базы данных, при выполнении которого проектировщик принимает решения о способах реализации разрабатываемой базы данных. Во время предыдущего этапа проектирования была определена логическая структура базы данных (которая описывает отношения и ограничения в рассматриваемой прикладной области). Хотя эта структура не зависит от конкретной целевой СУБД, она создается с учетом выбранной модели хранения данных, например реляционной, сетевой или иерархической. Однако, приступая к физическому проектированию базы данных, прежде всего необходимо выбрать конкретную целевую СУБД. Поэтому физическое проектирование неразрывно связано с конкретной СУБД. Между логическим и физическим проектированием существует постоянная обратная связь, так как решения, принимаемые на этапе физического проектирования с целью повышения производительности системы, способны повлиять на структуру логической модели данных.
Как правило, основной целью физического проектирования базы данных является описание способа физической реализации логического проекта базы данных.
В случае реляционной модели данных под этим подразумевается следующее:
· создание набора реляционных таблиц и ограничений для них на основе информации, представленной в глобальной логической модели данных;
· определение конкретных структур хранения данных и методов доступа к ним, обеспечивающих оптимальную производительность СУБД;
· разработка средств защиты создаваемой системы.
Этапы концептуального и логического проектирования больших систем следует отделять от этапов физического проектирования. На это есть несколько причин.
· Они связаны с совершенно разными аспектами системы, поскольку отвечают на вопрос, что делать, а не как делать.
· Они выполняются в разное время, поскольку понять, что надо сделать, следует прежде, чем решить, как это сделать.
· Они требуют совершенно разных навыков и опыта, поэтому требуют привлечения специалистов различного профиля.
Проектирование базы данных — это итерационный процесс, который имеет свое начало, но не имеет конца и состоит из бесконечного ряда уточнений. Его следует рассматривать прежде всего как процесс познания. Как только проектировщик приходит к пониманию работы предприятия и смысла обрабатываемых данных, а также выражает это понимание средствами выбранной модели данных, приобретенные знания могут показать, что требуется уточнение и в других частях проекта. Особо важную роль в общем процессе успешного создания системы играет концептуальное и логическое проектирование базы данных. Если на этих этапах не удастся получить полное представление о деятельности предприятия, то задача определения всех необходимых пользовательских представлений или обеспечения защиты базы данных становится чрезмерно сложной или даже неосуществимой. К тому же может оказаться затруднительным определение способов физической реализации или достижения приемлемой производительности системы. С другой стороны, способность адаптироваться к изменениям является одним из признаков удачного проекта базы данных. Поэтому вполне имеет смысл затратить время и энергию, необходимые для подготовки наилучшего возможного проекта.
Этапы методологии физического проектирования баз данных:
· Перенос глобальной логической модели данных в среду целевой СУБД.
· Проектирование основных отношений.
· Разработка способов получения производных данных.
· Реализация ограничений предметной области.
· Проектирование физического представления базы данных.
· Анализ транзакций.
· Выбор файловой структуры.
· Определение индексов.
· Определение требований к дисковой памяти.
· Проектирование пользовательских представлений.
· Разработка механизмов защиты.
· Обоснование необходимости введения контролируемой избыточности.
· Текущий контроль и настройка операционной системы.
Дополнительно
Обсуждаемая нами методология физического проектирования баз данных включает шесть основных этапов. Концептуальное и логическое проектирование охватывает три первых этапа разработки баз данных, а физическое проектировавание — этапы 4-9. Этап 4 стадии физического проектирования включает разработку основных отношений и реализацию ограничений предметной области с использованием доступных функциональных средств целевой СУБД, На этом этапе должно быть также принято решение по выбору способов получения производных данных, которые включены в модель данных.
Этап 5 включает выбор файловой организации и индексов для основных отношений. Как правило, СУБД для персональных компьютеров имеют фиксированную структуру внешней памяти, а другие СУБД предоставляют несколько альтернативных вариантов файловой организации для хранения данных. С точки зрения пользователя организация внутренней структуры хранения отношений должна быть совершенно прозрачной — пользователь должен иметь возможность получать доступ к любому отношению и к отдельным его строкам без учета способа хранения данных. Это означает, что СУБД должна обеспечивать полную независимость физического хранения данных от их логической организации. Только в этом случае внесение изменений в физическую организацию базы данных не окажет никакого влияния на работу пользователей (см. Раздел 2.1.5). Соответствие между логической моделью данных и физической моделью данных определяется внутренней схемой базы данных (см. рис. 2.1). Разработчик должен предоставить подробные физические проекты базы данных с учетом применяемой СУБД и операционной системы. В проекте реализации базы данных в СУБД разработчик должен определить структуры файлов, которые будут использоваться для представления каждого отношения. В проекте реализации базы данных в операционной системе разработчик должен указать расположение отдельных файлов и обеспечить необходимую их защиту. Прежде чем приступить к изучению этапа 5 рассматриваемой методологии, рекомендуем читателю ознакомиться со сведениями о файловой организации и структурах внешней памяти, приведенными в приложении В.
На этапе 6 необходимо принять решение о том, как должно быть реализовано каждое пользовательское представление. А на этапе 7 осуществляется проектирование средств защиты, необходимых для предотвращения несанкционированного доступа к данным, включая управление доступом к основным отношениям.
На этапе 8 анализируется также необходимость снижения уровня требований нормализации данных в логической модели, что может способствовать повышению общей производительности системы. Однако эти действия следует предпринимать только в случае реальной необходимости, поскольку введение в базу данных избыточности неизбежно вызовет появление проблем с поддержанием целостности данных. На этапе 9 описан способ организации текущего контроля операционной системы, позволяющий своевременно обнаруживать и устранять все проблемы производительности, которые могут быть решены на уровне проекта, а также учитывать новые или изменившиеся требования.
В приложении Е приводится обобщенное формальное описание методологии разработки баз данных, предназначенное для тех читателей, которые уже хорошо знакомы с теорией и нуждаются лишь в общем обзоре основных этапов проектирования.
Проектирование физического представления базы данных
Определение оптимальной файловой структуры для хранения базовых отношений и индексов, необходимых для достижения приемлемой производительности. Иными словами, определение способа хранения отношений и кортежей во вторичной памяти.
Анализ транзакций
Определение функциональных характеристик транзакций, которые будут выполняться в проектируемой базе данных, и выделение наиболее важных из них.
Выбор файловой структуры
Определение наиболее эффективной файловой структуры для каждого базового отношения.
Выбор индексов
Определение того, будет ли добавление индексов способствовать повышению производительности системы.
Определение требований к дисковому пространству
Оценка объема дискового пространства, необходимого для размещения базы данных.
Индексирование в базах данных
Индекс - структура данных, которая помогает СУБД быстрее обнаружить отдельные записи в файле и сократить время выполнения запросов пользователей.
Индекс в базе данных аналогичен предметному указателю в книге. Это — вспомогательная структура, связанная с файлом и предназначенная для поиска информации по тому же принципу, что и в книге с предметным указателем. Индекс позволяет избежать проведения последовательного или пошагового просмотра файла в поисках нужных данных. При использовании индексов в базе данных искомым объектом может быть одна или несколько записей файла. Как и предметный указатель книги, индекс базы данных упорядочен, и каждый элемент индекса содержит название искомого объекта, а также один или несколько указателей (идентификаторов записей) на место его расположения.
Хотя индексы, строго говоря, не являются обязательным компонентом СУБД, они могут существенным образом повысить ее производительность. Как и в случае с предметным указателем книги, читатель может найти определение интересующего его понятия, просмотрев всю книгу, но это потребует слишком много времени. А предметный указатель, ключевые слова в котором расположены в алфавитном порядке, позволяют сразу же перейти на нужную страницу.
Структура индекса связана с определенным ключом поиска и содержит записи, состоящие из ключевого значения и адреса логической записи в файле, содержащей это ключевое значение. Файл, содержащий логические записи, называется файлом данных, а файл, содержащий индексные записи, — индексным файлом. Значения в индексном файле упорядочены по полю индексирования, которое обычно строится на базе одного атрибута.
Типы индексов
Для ускорения доступа к данным применяется несколько типов индексов.
Основные из них перечислены ниже.
Первичный индекс.
Файл данных последовательно упорядочивается по полю ключа упорядочения, а на основе поля ключа упорядочения создается поле индексации, которое гарантированно имеет уникальное значение в каждой записи.
Индекс кластеризации.
Файл данных последовательно упорядочивается по неключевому полю, и на основе этого неключевого поля формируется поле индексации, поэтому в файле может быть несколько записей, соответствующих значению этого поля индексации. Неключевое поле называется атрибутом кластеризации.
Вторичный индекс.
Индекс, который определен на поле файла данных, отличном от поля, по которому выполняется упорядочение.
Файл может иметь не больше одного первичного индекса или одного индекса кластеризации, но дополнительно к ним может иметь несколько вторичных индексов. Индекс может быть разреженным (sparse) или плотным (dense). Разреженный индекс содержит индексные записи только для некоторых значений ключа поиска в данном файле, а плотный индекс имеет индексные записи для всех значений ключа поиска в данном файле. Ключ поиска для индекса может состоять из нескольких полей.
Индексно-последовательные файлы
Отсортированный файл данных с первичным индексом называется индексированным последовательным файлом, или индексно-последовательным файлом. Эта структура является компромиссом между файлами с полностью последовательной и полностью произвольной организацией. В таком файле записи могут обрабатываться как последовательно, так и выборочно, с произвольным доступом, осуществляемым на основу поиска по заданному значению ключа с использованием индекса. Индексированный последовательный файл имеет более универсальную структуру, которая обычно включает следующие компоненты:
· первичная область хранения;
· отдельный индекс или несколько индексов;
· область переполнения.
Обычно большая часть первичного индекса может храниться в оперативной памяти, что позволяет обрабатывать его намного быстрее. Для ускорения поиска могут применяться специальные методы доступа, например метод бинарного поиска. Основным недостатком использования первичного индекса (как и при работе с любым другим отсортированным файлом) является необходимость соблюдения последовательности сортировки при вставке и удалении записей. Эти проблемы усложняются тем, что требуется поддерживать порядок сортировки как в файле данных, так и в индексном файле. В подобном случае может использоваться метод, заключающийся в применении области переполнения и цепочки связанных указателей, аналогично методу, используемому для разрешения конфликтов в хешированных файлах.
Вторичные индексы
Вторичный индекс также является упорядоченным файлом, аналогичным первичному индексу. Однако связанный с первичным индексом файл данных всегда отсортирован по ключу этого индекса, тогда как файл данных, связанный со вторичным индексом, не обязательно должен быть отсортирован по ключу индексации. Кроме того, ключ вторичного индекса может содержать повторяющиеся значения, что не допускается для значений ключа первичного индекса. Для работы с такими повторяющимися значениями ключа вторичного индекса обычно используются перечисленные ниже методы.
Создание плотного вторичного индекса, который соответствует всем записям файла данных, но при этом в нем допускается наличие дубликатов.
Создание вторичного индекса со значениями для всех уникальных значений ключа. При этом указатели блоков являются многозначными, поскольку каждое его значение соответствует одному из дубликатов ключа в файле данных.
Создание вторичного индекса со значениями для всех уникальных значений ключа. Но при этом указатели блоков указывают не на файл данных, а на сегмент, который содержит указатели на соответствующие записи файла данных.
Вторичные индексы повышают производительность обработки запросов, в которых для поиска используются атрибуты, отличные от атрибута первичного ключа. Однако такое повышение производительности запросов требует дополнительной обработки, связанной с сопровождением индексов при обновлении информации в базе данных. Эта задача решается на этапе физического проектирования базы данных.
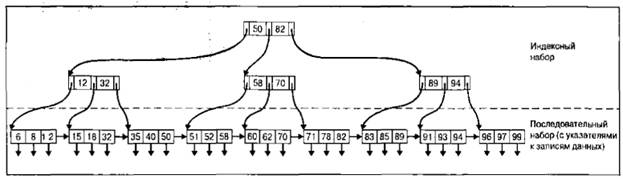
Многоуровневые индексы
При возрастании размера индексного файла и расширении его содержимого на большое количество страниц время поиска нужного индекса также значительно возрастает. Обратившись к многоуровневому индексу, можно попробовать решить эту проблему путем сокращения диапазона поиска. Данная операция выполняется над индексом аналогично тому, как это делается в случае файлов другого типа, т. е. посредством расщепления индекса на несколько субиндексов меньшего размера и создания индекса для этих субиндексов. На каждой странице файла данных могут храниться две записи. Кроме того, в качестве иллюстрации здесь показано, что на каждой странице индекса также хранятся две индексные записи, но на практике на каждой такой странице может храниться намного больше индексных записей. Каждая индексная запись содержит значение ключа доступа и адрес страницы. Хранимое значение ключа доступа является наибольшим на адресуемой странице.
Усовершенствованные сбалансированные древовидные индексы
Сбалансированное дерево
Во многих СУБД для хранения данных или индексов используется структура данных, называемая деревом. Дерево состоит из иерархии узлов (node), в которой каждый узел, за исключением корня (root), имеет родительский (parent) узел, а также один, несколько или ни одного дочернего (child) узла. Корень не имеет родительского узла. Узел, который не имеет дочерних узлов, называется листом (leaf).
Глубиной дерева называется максимальное количество уровней между корнем и листом. Глубина дерева может быть различной для разных путей доступа к листам. Если же она одинакова для всех листов, то дерево называется сбалансированным, или В-деревом (В-Тгее). Степенью (degree) (или порядком (order)) дерева называется максимально допустимое количество дочерних узлов для каждого родительского узла. Большие степени обычно используются для создания более широких и менее глубоких деревьев. Поскольку время доступа в древовидной структуре зависит от глубины, а не от ширины, обычно принято использовать более "разветвленные" и менее глубокие деревья. Бинарным деревом (binary tree) называется дерево порядка 2, в котором каждый узел имеет не больше двух дочерних узлов.
Усовершенствованные сбалансированные древовидные индексы определяются по следующим правилам.
Если корень не является лист-узлом, то он должен иметь, по крайней мере, два дочерних узла.
В дереве порядка n каждый узел (за исключением корня и листов) должен иметь от n/2 до n указателей и дочерних узлов. Если число n/2 не является целым, то оно округляется до ближайшего большего целого.
В дереве порядка n количество значений ключа в листе должно находиться в пределах от (n-1)/2 до (n-1). Если число (n-1)/2 не является целым, то оно округляется до ближайшего большего целого.
Количество значений ключа в нелистовом узле на единицу меньше количества указателей.
Дерево всегда должно быть сбалансированным, т. е. все пути от корня к каждому листу должны иметь одинаковую глубину.
Листы дерева связаны в порядке возрастания значений ключа.
Методы доступа к файлам и хеширование
Организация файла - физическое распределение данных файла по записям и страницам на вторичном устройстве хранения.
Существуют следующие основные типы организации файлов.
Неупорядоченная организация файла предусматривает произвольное неупорядоченное размещение записей на диске.
Упорядоченная (последовательная) организация предполагает размещение записей в соответствии со значением указанного поля.
В хешированием файле записи хранятся в соответствии со значением некоторой хеш-функции.
Для каждого типа организации файлов используется соответствующий набор методов доступа.
Метод доступа - действия, выполняемые при сохранении или извлечении записей из файла.
Поскольку некоторые методы доступа могут применяться только к файлам с определенным типом организации (например, нельзя применять индексный метод доступа к файлу, не имеющему индекса), термины Ърганизация файла и метод доступа часто рассматриваются как эквивалентные. Дальше в этом приложении описаны основные типы структуры файлов и соответствующие им методы доступа. В главе 16 представлена методология физического проектирования базы данных для реляционных систем вместе с рекомендациями по выбору наиболее подходящей структуры файлов и индексов.
Неупорядоченные файлы
Неупорядоченный файл (который иногда называют кучей) имеет простейшую структуру. Записи размещаются в файле в том порядке, в котором они в него вставляются. Каждая новая запись помещается на последнюю страницу файла, а если на последней странице для нее не хватает места, то в файл добавляется новая страница. Это позволяет очень эффективно выполнять операции вставки. Но поскольку файл подобного типа не обладает никаким упорядочением по отношению к значениям полей, для доступа к его записям требуется выполнять линейный поиск. При линейном поиске все страницы файла последовательно считываются до тех пор, пока не будет найдена нужная запись. Поэтому операции извлечения данных из неупорядоченных файлов, имеющих несколько страниц, выполняются относительно медленно, за исключением тех случаев, когда извлекаемые записи составляют значительную часть всех записей файла.
Для удаления записи сначала требуется извлечь нужную страницу, потом удалить нужную запись, а после этого снова сохранить страницу на диске. Поскольку пространство удаленных записей повторно не используется, производительность работы по мере удаления записей уменьшается. Это означает, что неупорядоченные файлы требуют периодической реорганизации, которая должна выполняться администратором базы данных (АБД) с целью освобождения неиспользуемого пространства, образовавшегося на месте удаленных записей.
Неупорядоченные файлы лучше всех остальных типов файлов подходят для выполнения массовой загрузки данных в таблицы, поскольку записи всегда вставляются в конец файла, что исключает какие-либо дополнительные действия по вычислению адреса страницы, в которую следует поместить ту или иную запись.
Упорядоченные файлы
Записи в файле можно отсортировать по значениям одного или нескольких полей и таким образом образовать набор данных, упорядоченный по некоторому ключу. Поле (или набор полей), по которому сортируется файл, называется полем упорядочения. Если поле упорядочения является также ключом доступа к файлу и поэтому гарантируется наличие в каждой записи уникального значения этого поля, оно называется ключом упорядочения для данного файла.
В общем случае бинарный поиск эффективнее линейного, однако этот метод чаще применяется для поиска данных в первичной (оперативной), а не во вторичной памяти (внешней).
Операции вставки и удаления записей в отсортированном файле усложняются в связи с необходимостью поддерживать установленный порядок записей. Для вставки новой записи нужно определить ее расположение в указанном порядке, а затем найти свободное место для вставки. Если на нужной странице достаточно места для размещения новой записи, то потребуется переупорядочить записи только на этой странице, после чего вывести ее на диск. Если же свободного места недостаточно, то потребуется переместить одну или несколько записей на следующую страницу. На следующей странице также может не оказаться достаточно свободного места, и из нее потребуется переместить некоторые записи на следующую страницу и т. д.
Таким образом, вставка записи в начало большого файла может оказаться очень длительной процедурой. Для решения этой проблемы часто используется временный неотсортированный файл, который называется файлом переполнения (overflow file) или файлом транзакции (transaction file). При этом все операции вставки выполняются в файле переполнения, содержимое которого периодически объединяется с основным отсортированным файлом. Следовательно, операции вставки выполняются более эффективно, но выполнение операций извлечения данных немного замедляется. Если запись не найдена во время бинарного поиска в отсортированном файле, то приходится выполнять линейный поиск в файле переполнения. И наоборот, при удалении записи необходимо реорганизовать файл, чтобы удалить пустующие места.
Упорядоченные файлы редко используются для хранения информации баз данных, за исключением тех случаев, когда для файла организуется первичный индекс.
Хеширование
Статическое хеширование
В хешированием файле записи не обязательно должны вводиться в файл последовательно. Вместо этого для вычисления адреса страницы, на которой должна находиться запись, используется хеш-функция (hash function), параметрами которой являются значения одного или нескольких полей этой записи. Подобное поле называется полем хеширования (hash field), а если поле является также ключевым полем файла, то оно называется хеш-ключом (hash key). Записи в хешированием файле распределены произвольным образом по всему доступному для файла пространству. По этой причине хешированные файлы иногда называют файлами с произвольным или прямым доступом (random file или direct file).
Хеш-функция выбирается таким образом, чтобы записи внутри файла были распределены наиболее равномерно. Один из методов создания хеш-функции называется сверткой (folding) и основан на выполнении некоторых арифметических действий над различными частями поля хеширования. При этом символьные строки преобразуются в целые числа с использованием некоторой кодировки (на основе расположения букв в алфавите или кодов символов ASCII). Например, можно преобразовать в целое число первые два символа поля табельного номера сотрудника (атрибут staffNo), а затем сложить полученное значение с остальными цифрами этого номера. Вычисленная сумма используется в качестве адреса дисковой страницы, на которой будет храниться данная запись. Более популярный альтернативный метод основан на хешировании с применением остатка от деления. В этом методе используется функция MOD, которой передается значение поля. Функция делит полученное значение на некоторое заранее заданное целое число, после чего остаток от деления используется в качестве адреса на диске.
Недостатком большинства хеш-функций является то, что они не гарантируют получение уникального адреса, поскольку количество возможных значений поля хеширования может быть гораздо больше количества адресов, доступных для записи. Каждый вычисленный хеш-функцией адрес соответствует некоторой странице, или сегменту (bucket), с несколькими ячейками (слотами), предназначенными для нескольких записей. В пределах одного сегмента записи размещаются в слотах в порядке поступления. Тот случай, когда один и тот же адрес генерируется для двух или более записей, называется конфликтом (collision), a подобные записи — синонимами. В этой ситуации новую запись необходимо вставить в другую позицию, поскольку место с вычисленным для нее хеш-адресом уже занято. Разрешение конфликтов усложняет сопровождение хешированных файлов и снижает общую производительность их работы.
Для разрешения конфликтов можно использовать следующие методы:
· открытая адресация;
· несвязанная область переполнения;
· связанная область переполнения;
· многократное хеширование.
Открытая адресация
При возникновении конфликта система выполняет линейный поиск первого доступного слота для вставки в него новой записи. После неудачного поиска пустого слота в последнем сегменте поиск продолжается с первого сегмента. При выборке записи используется тот же метод, который применялся при сохранении записи, за исключением того, что запись в данном случае рассматривается как не существующая, если до обнаружения искомой записи будет обнаружен пустой слот.
На первый взгляд может показаться, что этот подход не дает большого выигрыша в производительности. Однако при более внимательном анализе обнаруживается, что при использовании открытой адресации конфликты, устраненные с помощью первого свободного слота, могут вызвать дополнительные конфликты с записями, которые будут иметь хеш-значение, равное адресу этого прежде свободного слота. Таким образом, количество конфликтов будет возрастать, а производительность — падать. С другой стороны, если количество конфликтов удастся свести к минимуму, то линейный поиск в малой области переполнения будет выполняться достаточно быстро.
Связанная область переполнения
Как и в предыдущем методе, в этом методе для разрешения конфликтов с записями, которые не могут быть размещены в слоте с их адресом хеширования, используется область переполнения. Однако в данном методе каждому сегменту выделяется дополнительное поле, которое иногда называется указателем синонима. Оно определяет наличие конфликта и указывает страницу в области переполнения, использованную для его разрешения. Если указатель равен нулю, то никаких конфликтов нет.
Для более быстрого доступа к записи переполнения можно использовать указатель синонима, который указывает на адрес слота внутри области переполнения, а не на адрес сегмента. Записи внутри области переполнения также имеют указатели синонима, которые содержат в области переполнения адрес следующего синонима для такого же адреса, поэтому все синонимы одного адреса могут быть извлечены с помощью цепочки указателей.
Многократное хеширование
Альтернативный способ разрешения конфликтов заключается в применении второй хеш-функции, если первая функция приводит к возникновению конфликта. Цель второй хеш-функции заключается в получении нового адреса хеширования, который позволил бы избежать конфликта. Вторая хеш-функция обычно используется для размещения записей в области переполнения.
При работе с хешированными файлами запись может быть достаточно эффективно найдена с помощью первой хеш-функции, а в случае возникновения конфликта для определения ее адреса следует применить один из перечисленных выше способов. Прежде чем обновить хешированную запись, ее следует найти. Если обновляется значение поля, которое не является хеш-ключом, то такое обновление может быть выполнено достаточно просто, причем обновленная запись сохраняется в том же слоге. Но если обновляется значение хеш-ключа, то до размещения обновленной записи потребуется вычислить хеш-функцию. Если при этом будет получено новое хеш-значение, то исходная запись должна быть удалена из текущего слота и сохранена по вновь вычисленному адресу.
Динамическое хеширование
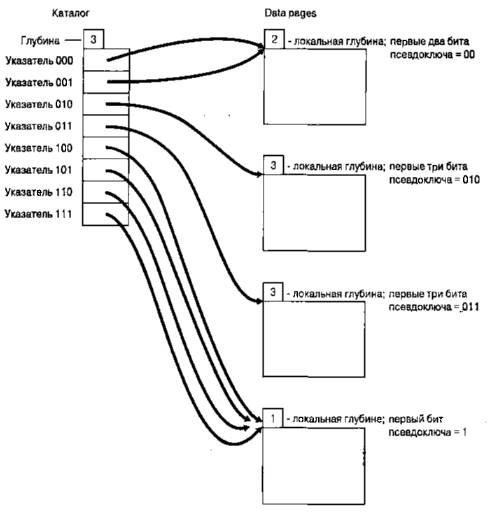
Динамическое хеширование
Перечисленные выше методы хеширования являются статическими, в том смысле, что пространство хеш-адресов задается непосредственно при создании файла. Считается, что пространство файла уже насыщено, когда оно уже почти полностью заполнено и администратор базы данных вынужден реорганизовать его хеш-структуру. Для этого может потребоваться создать новый файл большего размера, выбрать новую хеш-функцию и переписать старый файл во вновь отведенное место. В альтернативном подходе, получившем название динамического хеширования, допускается динамическое изменение размера файла с целью его постоянной модификации в соответствии с уменьшением или увеличением размеров базы данных.
Основной принцип динамического хеширования заключается в обработке числа, выработанного хеш-функцией в виде последовательности битов, и распределении записей по сегментам на основе так называемой прогрессирующей оцифровки (progressive digitization) этой последовательности. Динамическая хеш-функция вырабатывает значения в широком диапазоне, а именно b-битовые двоичные целые числа, где b обычно равно 32.
Ограничения, свойственные методу хеширования
Использование метода хеширования для извлечения записей основано на полностью известном значении хеш-поля. Поэтому, как правило, хеширование не подходит для операций извлечения данных по заданному образцу или диапазону значений. Более того, хеширование не подходит для поиска и извлечения данных по любому другому полю, отличному от поля хеширования.
Дополнительная литература
· http://ru. wikipedia. org/wiki/%D0%98%D0%BD%D0%B4%D0%B5%D0%BA%D1%81_(%D0%B1%D0%B0%D0%B7%D1%8B_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85)
· http://ru. wikipedia. org/wiki/%D0%A5%D0%B5%D1%88-%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F
Вопросы:
1. Понятие проектирования БД. Физическое проектирование БД.
2. Перечислите этапы физического проектирования БД.
3. Понятие индекса.
4. Типы индексов.
5. Многоуровневые индексы. Сбалансированные древовидные индексы.
6. Метод доступа к файлам. Организация файла. Упорядоченные и неупорядоченные индексы.
7. Понятие хеширования. Методы. Ограничения.
