

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Базы данных
(Пособие)
1.Информационные модели
Под информационной моделью понимается модель в терминах информационных данных. Основными понятиями являются понятия информационных элементов и отношений между ними. К основным информационным моделям относятся:
1. Модели в терминах свойство – связь.
2. Реляционная модель.
3. Многомерная модель данных.
4. Объектная и объектно – реляционная модель данных.
Наиболее простой, с которой и началась история БД, является модель свойство – связь.
1.1.Модель свойство-связь
Основными понятиями данной модели являются понятия информационного элемента и отношений между этими элементами.
Информационным элементом называется единая неделимая единица информации, которая характеризуется именем, типом, размером и экземпляром. Под именем понимается идентификатор, позволяющий однозначно определить данный элемент. Под типом информационного элемента будем понимать вещественный тип (E), целый (I), текстовый (T), дату (D) и Булев (B). Размером информационного элемента называется сколько места он занимает в памяти в байтах. Экземпляром информационного элемента называется одно из возможных значений, которые он может принимать. Например, информационный элемент «Ф. И.О. студента» можно задать следующим образом:
· Имя элемента - FIOS.
· Тип элемента – T.
· Размер элемента – 30 байт.
· Экземпляр элемента –
Основными отношениями, используемыми в данной модели данных, являются:
· Одно-однозначное отношение (1:1). Отношение между элементами A и B называется одно-однозначным, если одному экземпляру A соответствует один экземпляр B, и наоборот. Это отношение обозначается A(1:1)B и изображается в виде:
 |
Примером такого отношения может служить ИНН и номер пенсионного страхования.
· Одно – многозначное отношение (1:n). Отношение между элементами A, B называется одно – многозначным, если одному экземпляру A соответствует несколько экземпляров B, но одному экземпляру B соответствует один экземпляр. Такое отношение обозначается A(1:n)B и изображается:
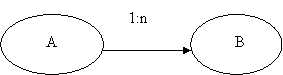 |
Примером такого отношения может служить № группы и № зачетки.
· Много – многозначное отношение (m:n). Элементы A, B находятся в много – многозначном отношении, если одному экземпляру A соответствует много экземпляров B и наоборот.
Если это особо не оговорено, то на графе связь не изображается. В противном случае изображается следующим образом:
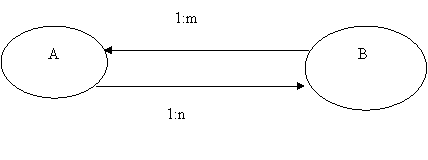 |
Примером такого отношения может служить № зачетки студента и ИНН преподавателя.
Таким образом, модель свойство-связь можно представить в виде графа. Для построения этого графа используется графический метод проектирования.
1.1.1. Графический метод проектирования
Графический метод проектирования состоит из следующих этапов:
1. Выделение информационных элементов и связей между ними.
2. Агрегирование элементов.
3. Удаление транзитивных зависимостей.
4. Введение фиктивных элементов.
Выделение информационных элементов можно проводить с помощью двух подходов: функционального и объектного. В первом случае анализируются задачи, которые предполагается решать с использованием данного приложения базы данных. Например, если в ходе эксплуатации приложения предполагается необходимость ответа на запрос:
 |
Здесь «В какой группе» является целевой частью запроса, в которой можно рассматривать № группы, как информационный элемент, а «обучается студент» - квалифицирующая часть, где – экземпляр информационного элемента Ф. И. О. студента. Недостатком данного подхода является то, что при изменении запросов, в БД может не оказаться требуемая информация. При объектном подходе анализируется объект, для которого строится база, и в нее вносятся все возможные элементы, выявляемые в ходе анализа. Недостатком данного подхода является то, что база может оказаться избыточной, и в нее могут быть включены элементы, к которым не будет проводиться обращение. Поэтому на практике используют комбинацию подходов. Пусть в ходе выделения информационных элементов был выделены следующие элементы:
№ | Имя | Тип | Размер | Экземпляр |
1 | Факультет | Текстовый | 12 | ФИТ |
2 | № группы | Текстовый | 12 | АП51 |
3 | № зачетки | Текстовый | 12 | АП03\5 |
4 | № пропуска | Текстовый | 12 | АП03\5 |
5 | Ф. И.О. студента | Текстовый | 25 | |
6 | Кафедра | Текстовый | 10 | ИТАС |
7 | Ф. И.О. преподавателя | Текстовый | 25 |
Для установления связей анализируется каждая пара информационных элементов. Получаем:
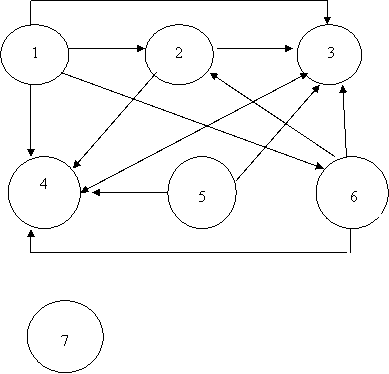 |
Здесь предполагается, что среди студентов и преподавателей могут быть однофамильцы.
На следующем шаге агрегируются (объединяются) информационные элементы, находящиеся в одно-однозначном соответствии. Такими элементами являются № зачетки и № пропуска. Получаем новый граф:
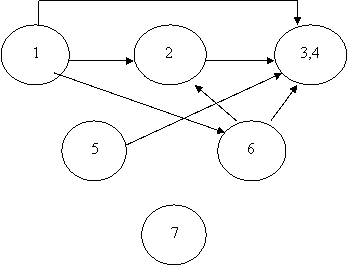 |
На следующем шаге удаляются транзитивные связи. Транзитивные связи имеют на графе следующий вид:
 |
Здесь можно удалить перечеркнутую связь. Фактически задача сводится к оставлению в графе путей наибольшей длины, связывающих вершины. В нашем случае получим:
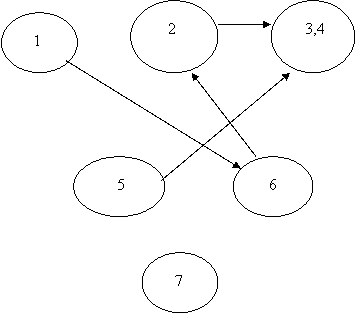 |
Недостаток этого графа заключается в том, что он не является связанным. Для того чтобы устранить этот недостаток вводится фиктивный информационный элемент, который находился бы в одно-многозначном соответствии с какими-либо элементами несвязанных подграфов. Для нашего примера таким элементом является ИНН преподавателя. Получаем:
 |
Такой граф принято изображать следующим образом. На верхнем уровне изображаются корневые вершины, а на нижнем – вершины листья.
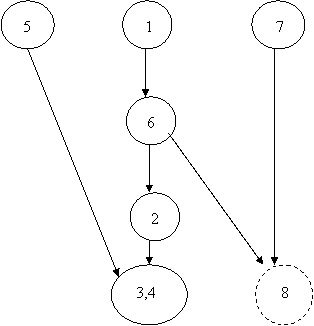 |
В зависимости от получаемого графа различают три структуры данных: строка, дерево, сеть.
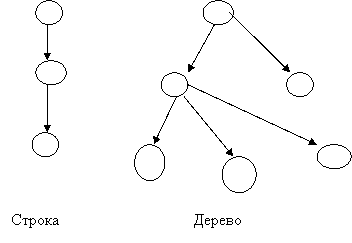 |
Граф, полученный в примере, соответствует сети.
Строка – это такая структура данных, в которой в вершину входит не более одной дуги, и выходит из нее также не более одной дуги (плоские БД).
В структуре данных дерево в вершину входит не более одной дуги, а исходит из нее сколь угодно много (иерархические БД – IMS).
В сети в вершину может входить сколь угодно много дуг и из вершины также выходит сколь угодно много дуг (сетевые БД – IDMS).
2.Реляционная модель данных
2.1.Основные понятия
Реляционная модель данных базируется на более сложном понятии отношения, чем модель свойство-связь.
Введем следующие понятия:
Отношение – это плоская таблица, состоящая из столбцов и строк.
Атрибут – это поименованный столбец отношения.
Домен – это набор допустимых значений для одного или нескольких атрибутов.
Кортеж – это строка отношения.
Степень отношения определяется количеством атрибутов, которое оно содержит.
Кардинальность – это количество кортежей, которое содержит отношение.
Реляционная база данных (РБД) – набор нормализованных отношений.
2.1.2.Математическое определение
Пусть имеется n множеств ![]() Декартово произведение для этих множеств можно определить следующим образом:
Декартово произведение для этих множеств можно определить следующим образом:
Подмножество этого множества и будет называться отношением.
Схема отношения – это имя отношения, за которым заключенное в скобки следует множество пар имен доменов и атрибутов.
Отношение обладает следующими свойствами:
· Отношение имеет имя, которое отличается от имен других отношений.
· Каждая ячейка отношения содержит атомарное (неделимое) значение.
· Каждый атрибут имеет уникальное присущее только ему имя.
· Значения атрибутов берутся из одного и того же домена.
· Порядок кортежей не важен.
· Каждый кортеж уникален, то есть дублирование значений кортежей не допускается.
· Порядок атрибутов важен и определяется следованием доменов в операции декартового произведения (Не верьте утверждению некоторых учебников, что он не важен. Это справедливо для табличных БД, одной таблице соответствует количество отношений равное числу сочетаний комбинаций столбцов отношений).
Эти утверждения являются результатом свойств определения понятий множеств и кортежей.
Вероятный или потенциальный ключ – атрибут или множество атрибутов, которое единственным образом определяет кортеж данного отношения.
Первичный или основной ключ – это потенциальный ключ, который выбран для уникальной идентификации кортежей отношения.
2.1.3.Реляционная целостность
Определитель NULL указывает, что значение атрибута в настоящий момент неизвестно или неприемлемо для данного кортежа.
В отношении ни один атрибут первичного ключа не может содержать значение NULL.
2.2.Нормализация
Нормализация – метод создания набора отношений с заданными свойствами на основе требований к данным, установленном в некотором приложении. Необходимость нормализации вызвана избыточностью данных и аномалиями обновления.
2.2.1.Избыточность данных и аномалии обновления
Одна из целей проектирования РБД заключается в группировании атрибутов в отношениях так, чтобы минимизировать избыточность данных и таким образом повысить эффективность БД.
Рассмотрим отношения:
Исходное: Работник_отдела(ИНН, ФИО, АдресС, Должность, Ставка, № отдела, АдресО, Телефон)
Преобразованные:
Служащий(ИНН, ФИО, АдресС, Должность, Ставка, № отдела)
Отдел(№ отдела, АдресО, Телефон)
Здесь подчеркнуты ключи отношений.
В отношении Работник_отдела содержатся избыточные данные, если рассмотреть экземпляры отношений, так как сведения об отделах повторяются.
Работник_отдела
ИНН | ФИО | АдресС | Должн | Ставка | № отд | АдресО | Тел |
5621 | Антон | Москва | Н. с. | 1000 | В3 | М, 1 | 353 |
5634 | Боря | Москва | инж | 700 | В3 | М, 1 | 353 |
5214 | Витя | Тула | Ст. инж | 800 | В3 | М, 1 | 353 |
4567 | Гриша | Реутов | С. н.с | 1500 | В5 | К, 3 | 211 |
2134 | Дима | Москва | инж | 700 | В7 | М, 2 | 145 |
6667 | Женя | Вязьма | инж | 700 | В7 | М, 2 | 145 |
Служащий
ИНН | ФИО | АдресС | Ставка | № отд |
5621 | Антон | Н. с | 1000 | В3 |
5634 | Боря | Инж | 700 | В3 |
5214 | Витя | Ст..инж | 800 | В3 |
4567 | Гриша | С. н.с | 1500 | В5 |
2134 | Дима | Инж | 700 | В7 |
6667 | Женя | инж | 700 | В7 |
Отдел

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
