
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Введение
Одной из наиболее остро стоящих проблем современной радиотехники является проблема эффективности использования радиочастотного спектра. Значительную его часть при этом занимают широковещательные службы, такие как радио и телевидение. Радиочастотный спектр при этом используется крайне неэффективно, поскольку для передачи телевизионного изображения до сих пор используются аналоговые методы, разработанные в прошлом веке. Потенциал аналоговых методов передачи видеоизображения очевидно исчерпан, что делает необходимым использование новых, цифровых методов. Применение при этом методов сжатия изображения, устраняющих избыточность, позволяет использовать радиочастотный спектр в разы более эффективно.
Рассмотрим представление видеоизображений в цифровом виде и основные методы устранения избыточности из этого представления.
Представление изображений в цифровом виде
Видеоизображения в общем случае могут быть представлены как непрерывные случайные функции![]() , зависящие от двух пространственных координат и времени. На ограниченном отрезке и времени, и пространства в общем случае аргументы имеют несчетное множество значений, а значит, несчетно и общее количество возможных изображений. Для хранения в цифровом виде и передачи по цифровому каналу необходимо перейти от несчетного множества изображений к счетному, а значит, и к представлению изображений в цифровом виде.
, зависящие от двух пространственных координат и времени. На ограниченном отрезке и времени, и пространства в общем случае аргументы имеют несчетное множество значений, а значит, несчетно и общее количество возможных изображений. Для хранения в цифровом виде и передачи по цифровому каналу необходимо перейти от несчетного множества изображений к счетному, а значит, и к представлению изображений в цифровом виде.
Эта задача теоретически может решаться путем обобщенного квантования. При обобщенном квантовании все пространство возможных изображений разбивается на конечное множество подпространств, которые пронумеровываются. Далее все изображения, попадающие в одно подпространство, заменяются одним представителем, которому присваивается номер подпространства, и храниться и передаваться может только номер изображения-представителя. При этом возникают ошибки представления, которые характеризуются мерой отличия реальных изображений от изображений-представителей. Обобщенное квантование позволяет решать задачи хранения и передачи по цифровому каналу наиболее эффективно с точки зрения наименьшей требуемой скорости передачи при заданном критерии точности воспроизведения. Однако технически это решение труднореализуемо, за исключением некоторых особых случаев, поэтому на практике используют менее эффективную, но более легко реализуемую процедуру преобразования изображения в цифровую форму, включающую пространственную и временную дискретизацию изображения, а также поэлементное квантование.
Задача пространственной дискретизации заключается в преобразовании непрерывной функции 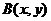 , описывающей неподвижное изображение, в дискретную
, описывающей неподвижное изображение, в дискретную ![]() , заданную на дискретном множестве точек с координатами
, заданную на дискретном множестве точек с координатами ![]() и
и ![]() , где в общем случае
, где в общем случае ![]() ,
, 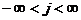 . Множество этих точек образует решетку, которую называют растром, а
. Множество этих точек образует решетку, которую называют растром, а 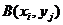 - выборочными элементами или отсчетами изображения. Дополнительным ограничением для решения этой задачи являются необходимость возможности восстановления непрерывной функции
- выборочными элементами или отсчетами изображения. Дополнительным ограничением для решения этой задачи являются необходимость возможности восстановления непрерывной функции ![]() по значениям
по значениям ![]() с допустимой величиной ошибок при минимальном количестве элементов изображения, приходящихся на единицу поверхности изображения. Это условие диктуется необходимостью получения минимально возможного объема данных, описывающего изображение с допустимой точностью.
с допустимой величиной ошибок при минимальном количестве элементов изображения, приходящихся на единицу поверхности изображения. Это условие диктуется необходимостью получения минимально возможного объема данных, описывающего изображение с допустимой точностью.
Элементы изображения располагаются в узлах регулярной решетки с равными интервалами между точками, что вытекает из конструкционных требований аппаратуры.
Наибольшее распространение для дискретизации сигналов получил подход, основанный на теореме Котельникова.
Пусть изображение – непрерывная и неограниченная в пространстве функция двух координат ![]() , для которой можно найти пространственный спектр
, для которой можно найти пространственный спектр 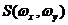 :
:
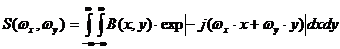 , (1)
, (1)
где ![]() и
и ![]() - пространственные круговые частоты по оси
- пространственные круговые частоты по оси ![]() и
и ![]() ,
, ![]() .
.
В силу инерционности устройств, формирующих оптические изображения, а также статистических свойств источников визуальных сообщений, можно считать, что для большого класса изображений этот спектр спадает с ростом пространственных частот и за пределами некоторой области становится равен нулю. Эту область можно ограничить прямоугольником, стороны которого равны ![]() и
и ![]() , где
, где ![]() и
и ![]() - значение пространственных частот по осям
- значение пространственных частот по осям ![]() и
и ![]() , выше которых
, выше которых ![]() . Модуль спектра (1) показан на рис. 1.
. Модуль спектра (1) показан на рис. 1.
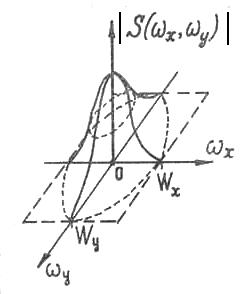
Рис. 1. Модуль спектра
Рассмотрим простой ортогональный растр с элементами, расположенными в узлах прямоугольной решетки. Дискретизированное изображение в трехмерном пространстве можно представить в виде пространственных ![]() -импульсов, расположенных в узлах ортогонального растра, амплитуда которых равна (см. рис. 2). Модулирующей функцией является изображение
-импульсов, расположенных в узлах ортогонального растра, амплитуда которых равна (см. рис. 2). Модулирующей функцией является изображение ![]() , показанное на рис. 2 пунктиром.
, показанное на рис. 2 пунктиром.
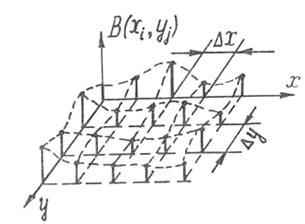
Рис. 2. Изображение ![]() в трехмерном пространстве в виде
в трехмерном пространстве в виде ![]() -импульсов
-импульсов
Аналитически продискретизированное изображение ![]() можно записать в следующем виде:
можно записать в следующем виде:
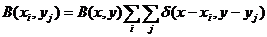 , (2)
, (2)
где ![]() - двухмерная
- двухмерная ![]() -функция.
-функция.
Спектр произведения двух функций есть свертка спектров исходных функций. Спектр исходного изображения ![]() задается формулой (1), а спектр пространственных
задается формулой (1), а спектр пространственных ![]() -функций, показанный на рис. 3, представляет собой периодическую структуру из двухмерных
-функций, показанный на рис. 3, представляет собой периодическую структуру из двухмерных ![]() -функций в области пространственных частот, имеющую период по оси
-функций в области пространственных частот, имеющую период по оси ![]() , равный
, равный ![]() , а по оси
, а по оси ![]() -
- ![]() , где
, где 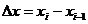 ;
; 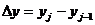 . Аналитически его можно записать в следующем виде:
. Аналитически его можно записать в следующем виде:
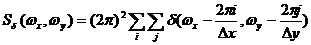 (3)
(3)
Используя фильтрующее свойство ![]() -функций, после свертки спектров (1) и (3) получается спектр дискретизированного изображения
-функций, после свертки спектров (1) и (3) получается спектр дискретизированного изображения ![]() , который отличается от (3) тем, что на месте каждой из
, который отличается от (3) тем, что на месте каждой из ![]() -функций в области пространственных частот появился спектр исходного непрерывного изображения
-функций в области пространственных частот появился спектр исходного непрерывного изображения ![]() (на рис. 3 изображен пунктиром).
(на рис. 3 изображен пунктиром).
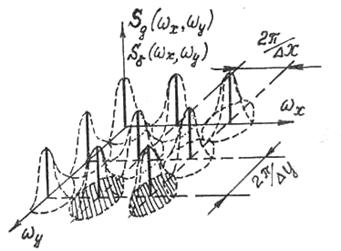
Рис. 3. Спектр дискретизированного изображения
Если спектральные компоненты не перекрываются, то есть при условии
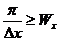 ,
, 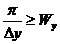 , (4)
, (4)
то из дискретизированного изображения можно точно восстановить исходное непрерывное изображение путем удаления высокочастотных компонент спектра.
С учетом сказанного можно сформулировать обобщенную теорему Котельникова. Любое непрерывное изображение, имеющее конечный пространственный спектр, полностью определяется своими элементами, расположенными в узлах прямоугольной решетки, интервалы между узлами которой удовлетворяют условию
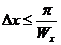 ,
, 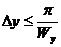 . (5)
. (5)
Реальные изображения никогда не удовлетворяют условиям теоремы Котельникова, поскольку они имеют ограниченные в пространстве размеры, а значит, бесконечный спектр. Кроме того, для идеального восстановления ![]() нужно иметь бесконечное число отсчетов, что реально невозможно. Поэтому в процессе дискретизации и восстановления изображения всегда появляются ошибки.
нужно иметь бесконечное число отсчетов, что реально невозможно. Поэтому в процессе дискретизации и восстановления изображения всегда появляются ошибки.
При дискретизации реальных изображений и при использовании практически реализуемых восстанавливающих фильтров возникают ошибки следующих видов: стробоскопические, ошибки ограничения спектра, муаровые, частотные и ошибки типа «ложных узоров».
За дискретизацией аналогового изображения следует квантование его по уровню. Весьма часто используется импульсно-кодовая модуляция (ИКМ), называемая также кодово-импульсной (КИМ). Примером формата хранения изображений, использующего КИМ, является bmp. При использовании ИКМ каждый отсчет изображения представляется кодовым словом, состоящим из m символов (для двоичных кодов, естественно, символов два – нуль и единица). В этом случае общее число возможных m-символьных кодовых комбинаций, равное числу уровней квантования ТВ-сигнала, будет
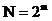 (6)
(6)
Очевидно, что качество воспроизводимых изображений зависит от выбранного количества уровней квантования, причем чем выше уровней квантования, тем выше качество. С другой стороны, увеличение числа символов m увеличивает объем данных, необходимых для представления изображения фиксированного размера, увеличивает требования к доступной скорости передачи по цифровому каналу R. Поэтому возникает задача такого выбора числа уровней квантования, при котором заданное качество воспроизводимых изображений достигается при минимальных требованиях к R.
В измерительных системах качество изображения оценивается величиной ошибок квантования. В этом случае число m выбирается исходя из допустимой максимальной ошибки квантования, или из допустимого среднеквадратического значения ошибки квантования. Указанные ошибки зависят от закона распределения мгновенных значений сигнала яркости, а также от типа преобразователя аналог-цифра (АЦП). Плотность вероятности сигнала яркости хорошо аппроксимируется равномерным законом распределения, и ошибки квантования минимальны, если используется АЦП с равномерным шагом квантования.
Такой подход неоптимален для систем, в которых получателем информации является человек, и поэтому при выборе числа m учитывают особенности субъективного восприятия квантованных изображений. Ошибки квантования незаметны наблюдателю, если их величина меньше яркостного порога ![]() , под которым понимается минимальная разность между яркостью цветового пятна и яркостью фона
, под которым понимается минимальная разность между яркостью цветового пятна и яркостью фона ![]() , различимая глазом. Экспериментально установлена закономерность, называемая законом Вебера-Фехнера, утверждающая, что в большом диапазоне яркостей остается постоянным пороговый контраст
, различимая глазом. Экспериментально установлена закономерность, называемая законом Вебера-Фехнера, утверждающая, что в большом диапазоне яркостей остается постоянным пороговый контраст ![]() . Тогда для незаметности ошибок квантования шаг квантования нужно выбирать соответствующим
. Тогда для незаметности ошибок квантования шаг квантования нужно выбирать соответствующим ![]() . В этом случае
. В этом случае
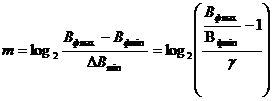 (7)
(7)
При больших размерах тестового пятна пороговый контраст равен примерно 0,02. При близком к реальности отношении ![]() получим m=15. В этом случае ошибки квантования будут незаметны даже при минимальной яркости фона, при больших значениях яркости яркостный порог во много раз больше. Используя неравномерную шкалу квантования яркости, например, логарифмическую, можно добиться снижения m до 8.
получим m=15. В этом случае ошибки квантования будут незаметны даже при минимальной яркости фона, при больших значениях яркости яркостный порог во много раз больше. Используя неравномерную шкалу квантования яркости, например, логарифмическую, можно добиться снижения m до 8.
Использованное значение порогового контракта, однако, достигается только в условиях длительной адаптации глаза к выбранной освещенности фона и при длительном рассматривании изображения. Эти условия почти никогда не соблюдаются для видеоизображений; прямой эксперимент показывает, что высокое качество восстановленного изображения обеспечивается уже при m=7 для логарифмической шкалы квантования или m=8 для равномерной шкалы.
Величина ![]() также увеличивается приблизительно на два порядка при уменьшении тестового пятна до размеров, соответствующих пропускной способности человеческого зрения. Существует взаимозависимость между разрешающей способностью восприятия деталей
также увеличивается приблизительно на два порядка при уменьшении тестового пятна до размеров, соответствующих пропускной способности человеческого зрения. Существует взаимозависимость между разрешающей способностью восприятия деталей ![]() , градационной разрешающей способностью
, градационной разрешающей способностью ![]() и чувствительностью зрения к восприятию движения
и чувствительностью зрения к восприятию движения ![]() . Приблизительно ее можно записать в виде
. Приблизительно ее можно записать в виде ![]() , так что взаимосвязь этих параметров можно представить в виде гиперболической поверхности (см. рис. 4). При этом предполагается, что пропускная способность зрения ограничена и конечна. Поэтому при передаче быстрого движения допустима пониженная разрешающая способность при передаче мелких деталей и уменьшенное число воспроизводимых градаций, передача контрастных деталей изображения ограничивает требования к скорости движения и числу градаций и, наконец, передача изображений большой площади с большим числом различимых градаций ограничивает требования к скорости движения и передаче мелких деталей. Число уровней квантования при передаче мелких деталей, а также резких перепадов яркости, можно уменьшать до 2-3.
, так что взаимосвязь этих параметров можно представить в виде гиперболической поверхности (см. рис. 4). При этом предполагается, что пропускная способность зрения ограничена и конечна. Поэтому при передаче быстрого движения допустима пониженная разрешающая способность при передаче мелких деталей и уменьшенное число воспроизводимых градаций, передача контрастных деталей изображения ограничивает требования к скорости движения и числу градаций и, наконец, передача изображений большой площади с большим числом различимых градаций ограничивает требования к скорости движения и передаче мелких деталей. Число уровней квантования при передаче мелких деталей, а также резких перепадов яркости, можно уменьшать до 2-3.
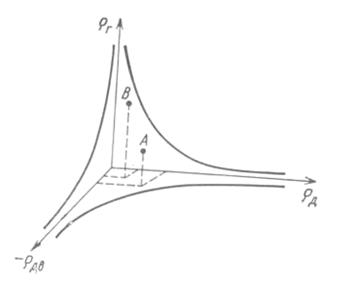
Рис. 4. Идеализированная пространственная модель пропускной способности зрения.
Ошибки квантования яркости видеоизображения являются сильно коррелированными, и воспринимаются зрителем как ложные контуры. Для снижения их заметности используется введение в сигнал частотных предыскажений, а также псевдошумовое квантование.
Квантование цветности соответствует разбиению цветового треугольника на элементарные участки так, чтобы внутри каждого различия в цветности не были видны для глаза. Экспериментально установлено, что число таких участков составляет от одной до нескольких тысяч. Аналогично, экспериментально установлены приемлемые нормы на квантование цветоразностных сигналов – по шесть разрядов на каждый при нелинейной шкале квантования, учитывающей величину зрительных порогов.
Чувствительность зрения к цвету мелких деталей существенно меньше, чем к цвету крупных. Поэтому ширина полосы сигналов цветности при кодировании видеоизображения зачастую выбирается много меньшей ширины полосы яркостного сигнала.
Кодирование видеоизображений с предсказанием
Элементы видеоизображения сильно коррелированы как в горизонтальном и вертикальном направлениях, так и во времени. Наличие этой корреляционной связи обуславливает большую статистическую избыточность КИМ-кодированного представления изображения. Первым способом кодирования, который позволяет сократить эту избыточность, стало кодирование с предсказанием. В этом случае по одному или нескольким предшествующим отсчетам предсказывается величина последующего. Затем предсказанное значение сравнивается с истинным, и хранится или передается разность между предсказанным и истинным значением. Этот метод кодирования получил название дифференциальной импульсно-кодовой модуляции (ДИКМ). Частным случаем ДИКМ является дельта-модуляция, при которой разностный сигнал квантуется всего на два уровня.
Все системы с ДИКМ разделяются на три основные группы в зависимости от того, как выбираются элементы, по которым ведется предсказание. В одномерных системах предсказание ведется по одному измерению – например, межэлементное, межстрочное или межкадровое предсказание. В двухмерных системах используется предсказание по двум координатам, а в трехмерных – сразу по трем: по горизонтали, вертикали и времени.
Алгоритм предсказания случайного процесса, обеспечивающий минимальные ошибки, может быть найден методами математического синтеза. Наибольшее распространение получил метод линейного предсказания, в соответствии с которым предсказываемое значение ![]() формируется в виде взвешенной суммы нескольких предыдущих отсчетов
формируется в виде взвешенной суммы нескольких предыдущих отсчетов 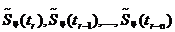 . Для одномерной системы с ДИКМ алгоритм работы линейного предсказателя (экстраполятора) определяется следующим выражением:
. Для одномерной системы с ДИКМ алгоритм работы линейного предсказателя (экстраполятора) определяется следующим выражением:
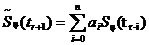 (8)
(8)
где ![]() - весовые коэффициенты, n – величина, называемая порядком предсказания.
- весовые коэффициенты, n – величина, называемая порядком предсказания.
При этом предсказание аналогично при использовании в качестве предыдущих отсчетов предыдущих элементов строки, элементов предыдущих строк или предыдущих кадров. Изменяются лишь весовые коэффициенты и время задержки.
Наиболее простым является кодирование с предсказателем нулевого порядка (n=0), для которого ![]() . Очевидно, предсказанное значение в этом случае совпадет со значением предыдущего отсчета, и хранится или передается разность между текущим отсчетом и предыдущим. Простота подобного предсказателя привела к его широкому использованию.
. Очевидно, предсказанное значение в этом случае совпадет со значением предыдущего отсчета, и хранится или передается разность между текущим отсчетом и предыдущим. Простота подобного предсказателя привела к его широкому использованию.
Двухмерный и трехмерный предсказатели более сложны. В аналоговой технике для их работы необходимы линии задержки, равные длительности строки и кадра, соответственно; в цифровом случае они сложнее алгоритмически.
Уменьшение избыточности в ДИКМ-кодировании основано на том, что, как правило, диапазон значений разностного сигнала значительно меньше диапазона значений исходного сигнала, что позволяет при сохранении неизменным шага квантования сократить число уровней квантования. Кроме того, плотность распределения мгновенных значений разностного сигнала является существенно неравномерной (распределение имеет форму, близкую к гауссовой кривой), что позволяет использовать АЦП с нелинейной шкалой квантования, то есть в области вероятных значений разностного сигнала выбирать шаг квантования малым, а в области маловероятных значений, соответствующих резким перепадам яркости, увеличивать его. При сохранении субъективного качества восстановленного изображения в таком случае требуется меньше уровней квантования, чем при использовании АЦП с равномерным шагом квантования.
Кроме шума квантования в системе с ДИКМ присутствуют специфические искажения: шум перегрузки по крутизне и гранулярный шум (шум зернистой структуры). Природа возникновения этих искажений проиллюстрирована на рис. 5.
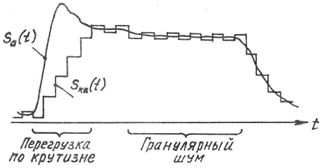
Рис. 5. Специфические искажения ДИКМ: шум перегрузки по крутизне и гранулярный шум
Шум перегрузки по крутизне возникает при кодировании резких изменений сигнала яркости. При этом величина разностного сигнала оказывается больше динамического диапазона и ограничивается. Шум перегрузки по крутизне проявляется на изображении как нелинейные искажения.
Гранулярный шум возникает при кодировании сигнала с медленно изменяющимся уровнем. При этом кодированное представление имеет вид колебания, размах которого равен минимальному шагу квантования. Гранулярный шум приводит к возрастанию уровня шумов на изображении и появлению муара на больших поверхностях постоянного уровня яркости.
Особенностью систем ДИКМ, как и других систем дифференциального кодирования, является накопление ошибки. Ошибки в одномерной системе с межэлементным предсказанием проявляются на декодированном изображении в виде горизонтальных полос. Для борьбы с этим уменьшают коэффициент ![]() предсказателей кодера и декодера или же время от времени передают вместо разностного сигнала непосредственное значение отсчета. Переход к двухмерному предсказателю также ведет к резкому улучшению субъективного качества изображения благодаря улучшению передачи вертикально ориентированных перепадов яркости.
предсказателей кодера и декодера или же время от времени передают вместо разностного сигнала непосредственное значение отсчета. Переход к двухмерному предсказателю также ведет к резкому улучшению субъективного качества изображения благодаря улучшению передачи вертикально ориентированных перепадов яркости.
Экспериментально установлено, что использование для устранения избыточности одномерного линейного предсказания по элементам строки позволяет сократить с 8 до 4 число разрядов кодовых слов при неизменном субъективном качестве изображения. При использовании же одномерного предсказания по элементам изображения предыдущих кадров оказывается возможным кодировать видеоизображение даже так, что на каждый элемент изображения приходится в среднем один двоичный разряд, что обусловлено сильной корреляцией элементов изображения соседних кадров.
Кодирование видеоизображений с помощью преобразований
Высоко эффективным способом уменьшения избыточности представления изображений является способ поблочной обработки цифровых сигналов изображения, базирующийся на ортогональных преобразованиях групп отсчетов и последующем вторичном квантовании полученных компонент.
Примером широко распространенного формата хранения изображений, использующего метод преобразований, является формат jpg, в котором применяется метод дискретного косинусного кодирования.
Метод кодирования изображений с помощью преобразований является по существу практическим приближением к реализации метода обобщенного квантования. При кодировании с помощью преобразований изображение представляется многомерным вектором в некотором пространстве, координатами которого являются базисные изображения. Очевидно, что любой многомерный вектор однозначно определяется своими проекциями на координатные оси, то есть может быть представлен в виде суммы взвешенных с весовыми коэффициентами базисных векторов (изображений). Весовые коэффициенты вычисляются в результате преобразования и хранятся, что эквивалентно хранению номера изображения-представителя при обобщенном квантовании.
В настоящее время наиболее разработанными являются линейные ортогональные преобразования, при которых, как правило, выполняются следующие операции:
- изображение разделяется на фрагменты прямоугольной или квадратной формы;
- производится линейное преобразование групп отсчетов каждого фрагмента;
- кодируются коэффициенты, вычисленные в результате преобразования сигнала.
Для обработки фрагментов изображений в основном используются ортогональные преобразования следующих типов: преобразования Фурье, Хаара, Адамара, наклонное преобразование, преобразование Карунена-Лоэва и синусно-косинусное преобразование.
Возможность сокращения избыточности при кодировании изображения с помощью преобразований обусловлена тем, что большое число вычисленных коэффициентов разложения при правильно выбранной системе базисных изображений имеет малую величину и может не храниться. На восстановленном изображения это будет практически незаметно.
При выполнении преобразования исходный фрагмент изображения представляется в виде матрицы ![]()
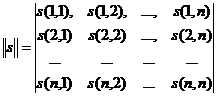 (9)
(9)
Каждый элемент матрицы (9) ![]() есть просто отсчет яркости соответствующего элемента изображения. В результате преобразования вычисляется матрицы коэффициентов преобразования
есть просто отсчет яркости соответствующего элемента изображения. В результате преобразования вычисляется матрицы коэффициентов преобразования 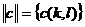 :
:
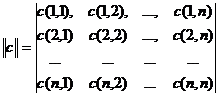 (10)
(10)
где ![]() ,
,
![]() - элементы матрицы преобразования
- элементы матрицы преобразования ![]() , имеющей смысл базисного изображения. Базисные изображения для преобразования Адамара показаны на рис. 6.
, имеющей смысл базисного изображения. Базисные изображения для преобразования Адамара показаны на рис. 6.

Рис. 6. Базисные изображения для преобразования Адамара
Каждый из элементов матрицы (10) определяется всеми элементами исходного изображения. Декодированию изображения соответствует обратное преобразование, в результате которого восстанавливаются элементы исходного изображения
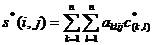 (11)
(11)
Звездочкой в (11) отмечено то, что восстановленные коэффициенты ![]() могут отличаться от исходных из-за квантования коэффициентов матрицы, а при передаче изображения – из-за помех в канале передачи.
могут отличаться от исходных из-за квантования коэффициентов матрицы, а при передаче изображения – из-за помех в канале передачи.
Линейное преобразование само по себе не устраняет избыточности, однако в результате преобразования энергия элементов ![]() существенно перераспределяется между элементами матрицы
существенно перераспределяется между элементами матрицы ![]() , что создает предпосылки для сокращения объема хранимой информации. Число уровней квантования для коэффициентов преобразования
, что создает предпосылки для сокращения объема хранимой информации. Число уровней квантования для коэффициентов преобразования ![]() , имеющих малую величину, можно резко уменьшить или вовсе отбросить их.
, имеющих малую величину, можно резко уменьшить или вовсе отбросить их.
Методы квантования коэффициентов преобразования разделяются на адаптивные и неадаптивные. К неадаптивным методам относится метод зонального отбора. В соответствии с этим методом передают только те коэффициенты преобразования, которые принадлежат определенной зоне. Зона определяется для множества передаваемых изображений, причем в зону входят те коэффициенты, которые оказывают существенное влияние на субъективное качество изображения. На рис. 7 показаны зоны матрицы ![]() , которые обычно сохраняются при использовании преобразования Адамара. Эти зоны соответствуют "низкочастотным" коэффициентам преобразования и коэффициентам вертикальных и горизонтальных пространственных частот. Необходимость сохранения последних обусловлена анизотропией спектров изображений и пространственно-частотных характеристик зрительной системы.
, которые обычно сохраняются при использовании преобразования Адамара. Эти зоны соответствуют "низкочастотным" коэффициентам преобразования и коэффициентам вертикальных и горизонтальных пространственных частот. Необходимость сохранения последних обусловлена анизотропией спектров изображений и пространственно-частотных характеристик зрительной системы.
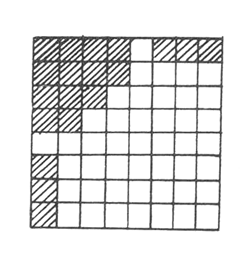
Рис. 7. Зоны матрицы коэффициентов преобразования , которые обычно сохраняются при использовании преобразования Адамара
Применимость метода зонального отбора ограничена тем, что выбор границ зоны может быть оптимальным только для некоторого класса изображений. В связи с этим более широкое распространение получал адаптивный метод порогового отбора, в соответствии с которым коэффициент преобразования ![]() не сохраняется, если его величина меньше некоторого порога.
не сохраняется, если его величина меньше некоторого порога.
С точки зрения степени сокращения избыточности передаваемого сигнала наиболее эффективными являются преобразования Карунена - Лоэва, наклонное и синусно-косинусное преобразования. Несколько уступают им преобразования Фурье и Хаара. Преобразование Адамара проигрывает всем остальным, однако на применимость преобразования зачастую более существенно влияет не его эффективность, а вычислительные трудности, связанные с выполнением преобразования. Для преобразования Карунена - Лоэва не существует быстрого алгоритма вычисления коэффициентов преобразования, и при преобразовании фрагмента из ![]() отсчетов необходимо выполнить
отсчетов необходимо выполнить ![]() операций. В случае быстрого преобразования Фурье требуется выполнять
операций. В случае быстрого преобразования Фурье требуется выполнять 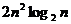 перемножений и такое же число сложений, а для преобразования Адамара - только сложений. Поэтому реализация преобразования Адамара является наиболее простой.
перемножений и такое же число сложений, а для преобразования Адамара - только сложений. Поэтому реализация преобразования Адамара является наиболее простой.
Сложность преобразования зависит также от размеров фрагмента. Субъективные экспертизы качества изображений показали, что при размерах фрагментов, больших 4x4, субъективное качество изображения улучшается медленно. Это объясняется тем, что базисные изображения рассмотренных преобразований недостаточно согласованы со статистическими свойствами изображений.
Результаты экспериментов по кодированию изображений с помощью преобразований показали, что сокращение цифрового потока до двух разрядов на элемент изображения достигается при кодировании с преобразованием Адамара фрагментов изображения размером 16х16 элементов. При уменьшении фрагмента до 8х8 цифровой поток уменьшается только лишь до 2,5 разрядов на элемент при той же оценке качества восстановленного изображения.
Для сравнения различных типов преобразования на рис. 8 приведены зависимости среднеквадратической ошибки восстановления исходного изображения для различных преобразований от размера группы отсчетов, полученные в предположении, что изображение описывается двумерным марковским процессом с коэффициентами корреляции между соседними элементами по горизонтали Rэ=0,95 и по вертикали Rс=0,95.
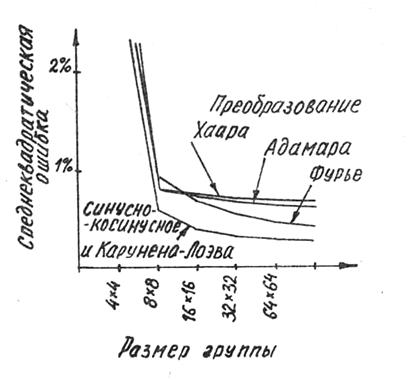
Рис. 8. Зависимость среднеквадратической ошибки от размера группы отсчетов для различных видов преобразований
Как видно из рис. 8, с точки зрения обеспечения малых среднеквадратических ошибок размер группы отсчетов целесообразно брать не меньшим, чем 8x8. Для указанной модели изображения лучшим преобразованием является синусно-косинусное, которое по среднеквадратической ошибке совпадает с преобразованием Карунена-Лоэва. Однако в отличие от последнего синусно-косинусное преобразование имеет алгоритм быстрого преобразования и поэтому более просто реализуется.
В системах с кодированием изображения с помощью линейных преобразований проявляются характерные искажения, связанные с заметностью разбиения его на фрагменты. Цифровые ошибки, обусловленные искажением цифрового сигнала в канале связи, в таких системах горазда меньше заметны на восстановленном изображена, чем при использовании ДИКМ, поскольку при обратном преобразовании искажения переданного коэффициента распределяются по всему фрагменту изображения.
Стандарт цифрового сжатия MPEG-2
В отличие от ранее рассмотренных методов кодирования изображений, стандарт цифрового сжатия MPEG-2 использует и пространственное, и временное сжатие. Это дает хорошие результаты для видеоизображений, поскольку последовательные кадры как правило сильно коррелированы.
Пространственное сжатие
 На рис. 9 показаны три основных этапа пространственного сжатия.
На рис. 9 показаны три основных этапа пространственного сжатия.
Рис. 9. Этапы пространственного сжатия
 Вначале изображение разбивается на макроблоки 16х16 отсчетов, каждый из которых содержит по 4 блока отсчетов яркости Y размером 8x8 пикселов и блоков сигналов цветности СB и CR размером также 8 х 8 пикселов. Количество блоков сигналов цветности определяется форматом дискретизации (рис. 10).
Вначале изображение разбивается на макроблоки 16х16 отсчетов, каждый из которых содержит по 4 блока отсчетов яркости Y размером 8x8 пикселов и блоков сигналов цветности СB и CR размером также 8 х 8 пикселов. Количество блоков сигналов цветности определяется форматом дискретизации (рис. 10).
Рис. 10. Форматы дискретизации MPEG-2
На вход дискретного косинусного преобразователя DCT поступают 8x8 массивы пикселов изображения с различными значениями интенсивности по яркости и цвету. На выходе преобразователя - уже другой массив чисел размером 8x8. Пространственное преобразование преобразует блок изображения размером 8x8 элементов в блок коэффициентов того же размера, который может быть закодирован с использованием значительно меньшего количества бит, чем оригинальный блок, который мы имели на первом этапе.
Первый коэффициент преобразования, имеющий индекс (0,0), особенный. Он представляет среднее значение всех 64 входящих пикселов матрицы 8x8. При движении коэффициента слева направо по горизонтали или вниз по вертикали преобразования говорят о росте пространственной частоты. DCT преобразование эффективно из-за того, кто оно имеет тенденцию концентрировать энергию преобразования в коэффициентах преобразования, расположенных в верхнем левом углу матрицы, где наименьшая пространственная частота.
Квантование
Второй этап пространственного сжатия - квантование коэффициентов преобразования, которое уменьшает число бит для представления DCT коэффициентов. Квантование выполняется путем деления коэффициентов преобразования на целое число с последующим округлением до ближайшего целого числа.
Целый делитель каждого DCT коэффициента состоит из двух частей, первая часть уникальна для каждого коэффициента в DCT матрице 8x8. Набор этих уникальных чисел также является матрицей и называется матрицей квантования. Вторая часть делителя (quantizer_scale) - это целое число, которое фиксировано для каждого следующего макроблока. В частности, существуют две матрицы квантования с фиксированными коэффициентами для I-кадров и не I-кадров. Эти две матрицы показаны в таблицах 1 и 2.
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
0 | 8 | 16 | 19 | 22 | 26 | 27 | 29 | 34 |
1 | 16 | 16 | 22 | 24 | 27 | 29 | 34 | 37 |
2 | 19 | 22 | 26 | 27 | 29 | 34 | 34 | 38 |
3 | 22 | 22 | 26 | 27 | 29 | 34 | 37 | 40 |
4 | 22 | 26 | 27 | 29 | 32 | 35 | 40 | 48 |
5 | 26 | 27 | 29 | 32 | 35 | 40 | 48 | 58 |
6 | 26 | 27 | 29 | 34 | 38 | 46 | 56 | 69 |
7 | 27 | 29 | 35 | 38 | 46 | 56 | 69 | 83 |
Таблица 1. Матрица квантования для I-кадров
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
0 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
1 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
2 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
3 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
4 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
5 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
6 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
7 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
Таблица 2. Матрица квантования для не I-кадров
Коды переменной длины
Следующим этапом в пространственном сжатии является размещение квантованных DCT коэффициентов в одномерный вектор, который затем будет являться частью таблиц кодов переменной длины. Процесс этого размещения называется зигзагообразным сканированием.
После этого производится статистическое кодирование без потерь по методу Хаффмана. Алгоритм метода заключается в следующем. Сначала анализируется вся последовательность символов. Часто повторяющимся сериям бит присваивается короткие элементы (маркеры). В частности, последние нули в конце строки могут быть заменены одним символом конца блока. Поскольку блоки имеют одинаковую длину, всегда определено количество опущенных нулей.
Временное сжатие
В отличие от пространственного сжатия, которое обеспечивается техникой преобразования изображений, временное сжатие достигается компенсацией движения (см. рис. 11).

Рис. 11. Удаление избыточности по трем осям
Для достижения максимального сжатия избыточность в изображений должна быть удалена в трех направлениях: двух пространственных и временном. С этой целью для удаления избыточности по времени изображение передается в виде последовательности I-, Р - и В-кадров (см. рис. 12).
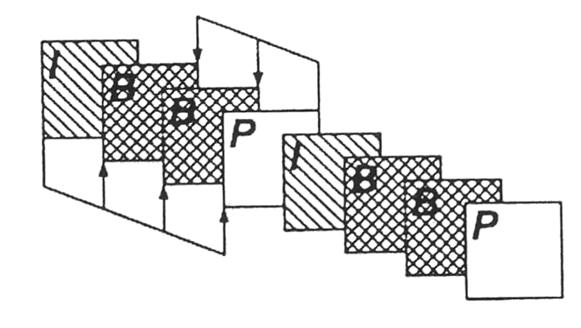
Рис. 12. Типовая группа изображений в MPEG-2.
На рисунке выше представлена типовая группа изображений GOP (Group of Pictures) - это набор изображений, который включает в себя:
- кадры, не требующие информации от других кадров, приходящих раньше или позже (так называемые Intra или I-кадры);
- кадры с однонаправленным предсказанием по предыдущим кадрам (Р-кадры);
- кадры с двунаправленным предсказанием по предыдущим и следующим кадрам (В-кадры).
Группа изображений - серия изображений, содержащих один I-кадр (см. рис. 12), где стрелками показаны направления предсказания в пределах одной группы изображений.
С информационной точки зрения каждое изображение представляет собой три прямоугольных матрицы отсчетов изображений: яркостную Y и две матрицы цветности С. Соотношение между количеством отсчетов яркости и цветности определяется форматом дискретизации (рис. 10):
- 4:2:0 — размеры матриц СB и СR в два раза меньше, чем Y и в горизонтальном, и в вертикальном направлении;
- 4:2:2 — все три матрицы имеют одинаковые размеры по вертикали, но в горизонтальном направлении матрицы цветности имеют в два раза меньшее количество элементов;
- 4:4:4 — все матрицы одинаковы.
Р - и В-кадры используются для достижения временного сжатия. Опыты показывают, что Р-кадрам требуется только 40%, а В-кадрам 10% от количества бит, требуемых для I-кадров.
Преобразование, изображенное на рис. 8, обычно называют гибридым кодированием, в основном из-за того, что пространственное сжатие достигается техникой преобразования, а временное сжатие — компенсацией движения.
Так как В-кадры должны быть получены из I - и Р-кадров, декодер должен сначала получить те и другие кадры, прежде чем будет декодирован В-кадр. Поэтому порядок передачи не может быть IBBP IBBP. Порядок передачи кадров должен быть следующий: IPBB IPBB.
Это вносит ограничения для кодера, так как он должен хранить кадры, которые должны стать В-кадрами. Это ведет к росту задержки — времени от момента начала кодирования кадра до момента его воспроизведения.
Изображения (I-, Р - или В-кадры) делятся на слайсы (slices), макроблоки (macroblocks) и блоки (blocks), каждый из которых имеет свой заголовок. Следует отметить, что в литературе слайсы иногда принято переводить как срезы.
Р - и В-кадры используются для достижения временного сжатия. Опыты показывают, что Р-кадрам требуется только 40%, а В-кадрам 10% от количества бит, требуемых для I-кадров.
Структуру, показанную на рис. 11, обычно называют гибридым кодированием, в основном из-за того, что пространственное сжатие достигается техникой преобразования, а временное сжатие — компенсацией движения.
Так как В-кадры должны быть получены из I - и Р-кадров, декодер должен сначала получить те и другие кадры, прежде чем будет декодирован В-кадр. Поэтому порядок передачи не может быть IBBP IBBP. Порядок передачи кадров должен быть следующий: IPBBIPBB.
Это вносит ограничения для кодера, так как он должен хранить кадры, которые должны стать В-кадрами. Это ведет к росту задержки — времени от момента начала кодирования кадра до момента его воспроизведения.
Изображения (I-, Р - или В-кадры) делятся на слайсы (slices), макроблоки (macroblocks) и блоки (blocks), каждый из которых имеет свой заголовок. Название слайсы также переводят как срезы.
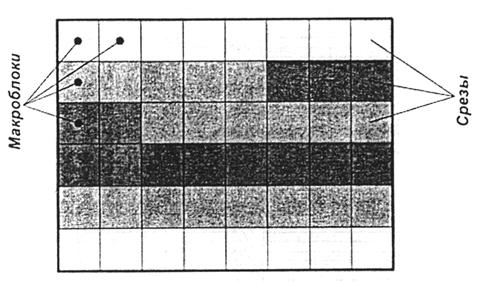
Рис. 13. Деление изображения на слайсы и макроблоки в MPEG-2.
Слайсом называется группа последовательных макроблоков в видеокадре (рис. 13), объединяемых общей шкалой квантования. Слайс представляет собой минимальную единицу видеопоследовательности в борьбе с ошибками. Если декодер обнаруживает ошибку, он игнорирует данный слайс и сдвигается к началу следующего. Чем больше срезов в видеокадре, тем эффективнее борьба с ошибками (но ниже степень сжатия). Деление изображений на срезы (слайсы) являете одной из новаций в алгоритмах сжатия MPEG.
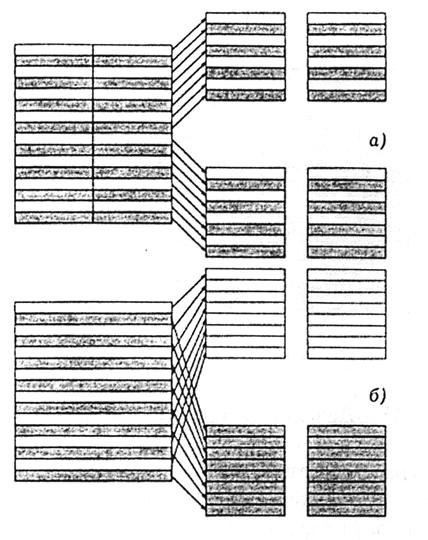
Рис. 14. Варианты внутренней организации макроблока в MPEG-2
В стандарте MPEG-2 возможны два варианта внутренней организации макроблока (см. рис. 14):
- кадровое кодирование, при котором каждый блок яркости образуется из чередующихся строк двух полей (рис. 14а);
- полевое кодирование, при котором каждый блок яркости образуется из строк только одного из двух полей (рис. 14б)
Макроблок яркости — это область, имеющая размер 16x16 пикселей. Цветовая часть макроблока зависит от выборки отсчетов яркости. (Структура макроблока с форматом 4:2:0 показана на рис. 11). Из этого рисунка видно, что макроблок формата 4:2:0 состоит из шести блоков. Яркостная составляющая представляет из себя квадрат из четырех блоков размером 8х8, а каждая из цветовых составляющих состоит из одного блока 8x8 пикселов. Векторы для компенсации движения определяются по яркостной составляющей макроблока.
Блоки имеют размер 8x8 пикселей и являются наименьшим синтаксическим элементом MPEG-2. Блоки являются основными элементами для DCT кодирования.
Набор операций такого кодирования:
- дискретное косинусное преобразование;
- взвешенное квантование, определяемое элементами матрицы квантования;
- энтропийное кодирование серии коэффициентов косинусного преобразования, полученной в результате диагонального сканирования матрицы коэффициентов.
Видеоизображениям, закодированным с использованием формата MPEG, свойственны искажения, типичные для кодирования с использованием преобразований, например, блокинг-эффект и мозаичный эффект (разбиение всего изображения на квадратные блоки с заметными границами по цвету и яркости), размывание изображения и окантовки на границах (вызываемые отбрасыванием высокочастотной части спектра ДКП). Кроме того, межкадровое кодирование также вызывает появление искажений, такие как ложные границы, эффект «комаров» и эффект «привидений», вызываемые несовпадением положения макроблоков в опорных кадрах и кадрах с предсказанием, разностью ошибок квантования между кадрами и другими эффектами.
Для рассмотрения в настоящей работе выбраны все перечисленные основные методы кодирования видеоизображений. Использование нескольких методов кодирования для представления одного видеоизображения позволяет не только оценить степень сжатия, получаемую при использовании каждого из них, но и наглядно сравнить возникающие при кодировании и декодировании искажения.
