
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
1. Классификация вычислительных сетей. Систематика Флина. 1
2. Уровни параллелизма. Матричная обработка информации. Вычислительная сеть ”ILLIAC-IV”. 3
3. Принципы магистральной обработки информации. Система GRAY. 7
4. Ассоциативные вычислительные системы. Система PEPE. 9
5. Транспьютеры. Транспьютеры фирмы INMOS. 11
6. Модель коллектива вычислителей. 13
7. Типовые схемы обмена информацией при реализации P-алгоритмов. 13
8. Системные операции. 14
9. ЭМ ОВС. Состав, функциональное назначение. 15
10. Основные свойства ОВС с программируемой структурой. ОВС «Минимакс». 17
11. Вычислительные среды. Функциональные и коммуникационные элементы среды. 19
12. Отказоустойчивые вычислительные системы. Эффект «Домино». Вычислительная система космического корабля «Шаттл». 20
13. Модель OSI. Понятие «открытая система». 21
14. Уровни, протоколы, интерфейсы. 22
15. Прикладной, представительный уровни. 24
16. Сеансовый, транспортный уровни. 24
17. Сетевой уровень. 25
18. Канальный, физический уровни. 25
19. Коммуникационные подсети. 26
20. Одно, многоузловая коммуникационная подсеть. 26
21. Моноканал, Поликанал. 29
22. Циклическое кольцо. 31
23. Технология Ethernet. 32
24. Технология Token Ring. 33
25. Технология FDDI. 35
26. Построение локальных сетей по стандартам физического и канального уровней. 36
27. Мосты и коммутаторы. 37
28. Концентраторы и сетевые адаптеры. 39
29. Маршрутизация. Маршрутизаторы. 42
30. Принципы построения составных сетей на основе протоколов сетевого уровня. 44
1. Классификация вычислительных сетей. Систематика Флина.
Процесс решения задачи можно представить как воздействие определенной последовательности команд программы (потока команд) на соответствующую последовательность данных (поток данных), вызываемых этой последовательностью команд. Различные способы организации параллельной обработки информации можно представить как способы организации одновременного воздействия одного или нескольких потоков команд на один или несколько потоков данных.
Под множественным потоком команд или данных понимается наличие в системе нескольких последовательностей команд, находящихся в стадии реализации, или нескольких последовательностей данных, подвергающихся обработке командами.
Классификация ВС Флина:
1.SISD-системы с одиночным потоком команд и одиночным потоком данных:
обычные однопроцессорные ЭВМ. Для повышения производительности может использоваться совмещение во времени этапов решения разных задач (одновременная работа УВВ и ЦП, введение большого числа параллельно работающих ПУ), разделение ОЗУ на несколько функционально самостоятельных модулей (уменьшение простоев из-за конфликтов при обращении к ОЗУ),конвейер команд.
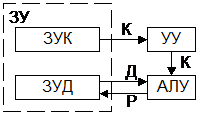
2.SIMD-одиночный поток команд, множ. поток данных:
одновременная обработка нескольких потоков данных одной и той же программы несколькими процессорами. Каждый поток данных обрабатывается своим АЛУ, работающими под общим управлением (матричный процессор).
Примеры: СRAY-1, ILLIAC IV, DAP, OMEN-64.
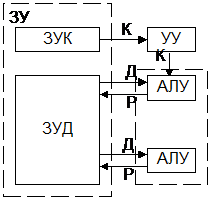
3.MISD-множ. поток команд, одиночный поток данных:
Так как в чистом виде не существует такого класса задач, в котором одна и та же последовательность данных подвергалась бы обработке по нескольким разным программам, то один поток команд разделяется УУ на несколько потоков микроопераций, каждая из которых реализуется специализированным устройством. Поток данных проходит через все или часть специализированных АЛУ. Именно системы такого класса принято называть конвейерными или системами с магистральной обработкой информации. Кроме конвейера операций может использоваться также конвейер команд и различные способы совмещения работы многих устройств. Системы этого класса развивают максимальную производительность только при решении задач определенного типа, в которых есть длинные цепочки однотипных операций над достаточно большой последовательностью данных.
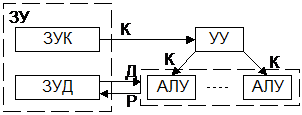
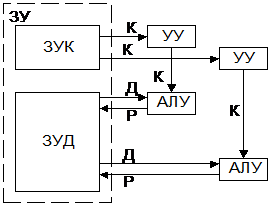
4.MIMD-множ. поток команд, множ. поток данных:
многомашинные и многопроцессорные ВС. Многомашинный вариант: для каждой последовательности команд и данных имеется собственное ЗУ; система как бы распадается на несколько независимых систем класса SISD, при этом существуют определенные связи между ЭВМ. В многопроцессорном варианте система достаточно жестко связана общей памятью команд и данных; процессоры имеют достаточную самостоятельность, но в системе организуется совместная их работа. Многомашинные системы в наилучшей степени приспособлены для решения потока независимых задач, многопроцессорные - более универсальны.
2. Уровни параллелизма. Матричная обработка информации. Вычислительная сеть ”ILLIAC-IV”.
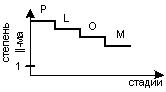
1. Выбор подходящего алгоритма (P); 2. Выражение алгоритма на языке высокого уровня (L); 3. Компилирование программы с языка высокого уровня в объектную программу, машинно-читаемую (O); 4. Выполнение программы на машине.
Степень ||-ма - число независимых операций, которые м/б выполнены одновременно. Принцип сохранения ||-ма - P≥L≥O≥M (идеальная ситуация) - степень ||-ма не должна увеличиваться по мере процесса разработки. Этот принцип является желательным. Чтобы перевести ||-ый процесс в последовательность шагов, требуется только произвольное упорядочение независимых операций. Однако, чтобы преобразовать последовательный процесс в ||-ый, требуется провести анализ. В процессе анализа необходимо проверить является ли на деле упорядочение произвольным и отсутствуют ли последовательные зависимости в этом процессе.
Таким образом, важно сохранять ||-зм алгоритма и выразить его насколько это возможно, на языке высокого уровня.
Получение параллелелизма: (при степени ||-зма = 1 - алгоритм последовательный)
1. Идеальная ситуация: P≥L≥O≥M |
|
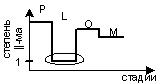
2. Потеря и регенерация алгоритма. Программа на последовательном языке, но есть векторизирующий компилятор, который смог построить ||-ый код: P≥O≥M; L=1; |
|
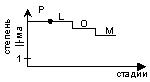
3. Специализированные конструкции в языке Компилятор ограничил степень ||-ма в зависимости от имеющихся ресурсов. P=L≥O≥M. P=L - это языки, которые позволяют писать полностью ||-ые программы. |
|
4. Наибольший класс языков P≥L=O=M - мы можем написать наш алгоритм так, как нам позволяет язык, а язык как имеющиеся ресурсы машины. Данные вид является компромиссом между 1 и 2 вариантом ПДП (хорошая производительность в сочетании с низкой стоимостью). |
|

Матричный или векторный процессор (array processor) представляют собой “матрицу” связанных элементарных идентичных процессоров, управляемых одним потоком команд. (См. рисунок). Элементарный процессор (ЭП) включает в себя АЛУ и память. Сеть связи между ЭП позволяет осуществлять обмен информацией между любыми ЭП. Поток команд поступает на матрицу ЭП от единого устройства управления, то есть матричные системы относятся к системам класса ОКМД. Матричные ВС - вариант технической реализации модели коллектива вычислителей, в которой в высокой степени воплощены новые принципы построения, такие как параллельность выполнения операций, переменность структуры и конструктивная однородность, следующая из идентичности квадрантов, УУ, ЭП и из регулярности связей между ними.

Архитектура матричного процессора была выбрана в начале 60-х годов, обоснована экономическими соображениями и необходимостью обеспечения высокой производительности при решении сложных задач . Тогда основная доля стоимости ЭВМ приходилась на схемы устройства управления, а не на схемы АЛУ или памяти. Поэтому централизация УУ и параллелизм устройств обработки и хранения информации обеспечивали компромисс между стоимостью и производительностью. Следует заметить, что с развитием интегральной технологии эти экономические соображения стали несущественными при выборе архитектуры вычислительного средства.
Существует широкий спектр научных, технических и административно-хозяйственных задач, которые эффективно решаются на матричном процессоре. При решении задач фактически один и тот же алгоритм параллельно (одновременно) реализуется для многих массивов данных. Каждый из массивов данных размещается и обрабатывается в своем ЭП. Предварительно данные организуются в вектор.
Параллелизм в работе элементарных процессоров принципиально позволяет достичь любого уровня быстродействия матричного процессора.
К недостаткам матричных ВС следует отнести наличие единственного общего УУ, что приводит к снижению надежности системы в целом, так как в случае выхода УУ из строя система становится неработоспособной. Для устранения этого недостатка очевиден следующий шаг - введение для каждого ЭП своего устройства управления, что будет означать переход к модели коллектива машин-вычислителей.
Матричные вычислительные системы могут быть построены по двум основным схемам:
1. Каждый элементарный процессор имеет собственный массив данных, и работает над собственными данными. При необходимости обмена с данными другого процессора задействуется коммуникационное оборудование. Количество процессоров и блоков памяти обычно совпадает.

2. Каждый элементарный процессор имеет собственную память и доступ к памяти другого процессора осуществляется по разрешению “хозяина”.

. Система ИЛЛИАК-IV. Структура системы. Принцип действия.
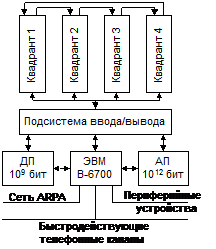
Матричная вычислительная система ILLIAC-IV создана Иллинойским университетом и фирмой Burroughs. Работы по созданию ILLIAC-IV были начаты в 1966 г., монтаж системы завершен в мае 1972г. Быстродействие системы 2*108 операций в секунду, полезное время составляет 80-85% общего времени работы системы, стоимость (3-4)*107 долларов.
Матричная вычислительная система ILLIAC-IV представляет собой модифицированный вариант системы SOLOMON и состоит из 4 квадрантов, подсистемы ввода-вывода информации, ЭВМ В-6700 (или В-6500), дисковой памяти (ДП) объемом 109 бит со средней скоростью обмена 0,5*109 бит/с и архивной памяти (АП) емкостью 1012 бит/с и скоростью обмена 4*106 бит/с. Планируемое быстродействие 109 опер/с.
Квадрант - это матричный процессор, включающий устройство управления и 64 ЭП. УУ представляет собой специализированную ЭВМ, которая используется для выполнения операций над скалярами и формирует поток команд на матрицу ЭП. ЭП матрицы регулярным образом связаны друг с другом, структура есть D2-граф вида {64,1,8}.

Матрица из 64 ЭП предназначена для выполнения операций над векторами. Все 64 ЭП работают синхронно и единообразно. Допустимо одновременное выполнение скалярных и векторных операций, то есть в ILLIAC-IV заложена возможность параллельной работы не только ЭП в матрице, но и устройства управления и матрицы в целом.
Система ILLIAC-IV оперирует 64-разрядными словами и при суммировании 512 8-разрядных чисел имеет быстродействие почти 1010 опер/с, а при сложении 64-разрядных чисел с плавающей запятой - 1,5*108 опер/с.
Каждый ЭП имеет накапливающий сумматор, регистр второго операнда, регистр передаваемой информации, регистр, используемый как временная память, регистр модификации адресного поля команды, регистр состояния данного ЭП. Память каждого ЭП составляет 2разрядных слов, использует корректирующий код Хемминга и имеет время цикла 300 нс. К каждой памяти имеет непосредственный доступ собственный ЭП. Обмен информацией между памятями различных ЭП осуществляется по сети связи при помощи специальных команд пересылок.
ОС ILLIAC-IV состоит из набора асинхронных программ, выполняемых под управлением главной управляющей программы В-6700. ОС работает в дыух режимах: в первом режиме осуществляется контроль и диагностика неисправностей в квадранте и в подсистеме ввода/вывода информации. Во втором режиме осуществляется управление работой ILLIAC-IV при поступлении на В-6700 заданий от пользователей, которые могут являться программами В-6700, написанными на Алголе или Фортране, программы ILLIAC-IV, написанные на языках Glynpir или Фортран и программы на управляющем языке Illiac, определяющие задание. Таким образом средства программирования ILLIAC-IV включают язык ассемблера и три языка высокого уровня: Tranquil, Glynpir и Фортран.
Система ILLIAC-IV эффективна при решении задач большой размерности, таких как задачи матричной арифметики, решения систем линейных алгебраических уравнений, задач линейного программирования, обработки сигналов и. т.п.
3. Принципы магистральной обработки информации. Система GRAY.
Конвейерный принцип обработки информации.
Из всего многообразия способов организации параллельной обработки можно выделить три основных направления :
1) совмещение во времени различных этапов разных задач;
2) одновременное решение различных задач или частей одной задачи;
3) конвейерная обработка информации.
Конвейерная обработка может быть реализована в системе, имеющей регулярную структуру в виде цепочки последовательно соединенных процессоров или специальных вычислительных блоков, так что информация на выходе одного процессора (СВБ) является входной информацией для следующего в конвейерной цепочке:
Каждый процессор (СВБ) обрабатывает соответствующую часть задачи. Это обеспечивается подведением к каждому процессору (СВБ) своего потока команд, т. е. имеется множественный поток команд ( MISD - системы ). Если конвейер заполнен полностью, выходной процессор (СВБ) выдает результаты для последовательности входных данных через очень короткие интервалы времени, хотя действительное время прохождения задачи через конвейер может быть существенно большим.
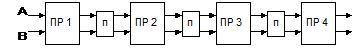
Подобные системы должны работать на непрерывном потоке данных, т. к. конвейер эффективен только при полном его заполнении. Очевидно, конвейерный метод дает тем больший выигрыш, чем сложнее выполняемые операции ( повышение эффективности на 40% для операций сложения и на 230% для операций умножения ).
Блок-схемы конвейерных систем.
Это макроконвейер ‑ на уровне программ (частей программ). Для макроконвейера характерно, что каждый процессор имеет свою память и результаты передаются по цепочке.
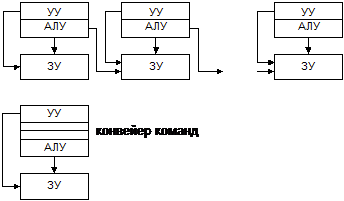
Это микроконвейер ‑ на уровне команд или слов.
Особенности конвейерных систем
1) Число ЦП ограничено, так как они завязаны на главную память.
2) Число функциональных блоков обычно не велико ( около 10 ).
3) Число этапов конвейера ограничено ( около 10 ).
4) Невозможность работы в реальном времени из-за необходимости перезагрузки конвейера и больших затрат времени на это.
.Cистема Cray-XTM.
Это универсальная многопроцессорная система для работы в многозадачном режиме. Выполняет независимые задачи из различных заданий на нескольких процессорах. Может также работать в режиме решения связанных задач одного задания: малосвязанные задачи - связь через ОП, сильносвязанные - через быстрые порты. Особенности: 1.состоит из одинаковых процессоров и является симметричной (нет разделения master-slave). 2.система может быть разбита на k групп, 0<=k<=p, p-количество процессоров (0 группа-процесс в/в). 3.Любая группа имеет один набор общих регистров. 4.Любой процессор может работать в режиме монитора и пользователя. 5. -//- выполнять скалярные и векторные операции. 6.Аппаратно решаются deadlock-и(тупики). 7.Процессор, работающий в режиме монитора, может прервать и изменить режим любого процессора, работающего в режиме пользователя. 8.Аппаратное распределение памяти. 9.В случае необходимости быстрое перераспределение функций между процессорами.
УМС - устройство межпроцессорной связи (через быстрые регистры). БП - буферная память. ГОП - 4¸16 Мслов. ГОП разбита на 32 банка, которые могут работать независимо (адреса чередуются). Цикл ОП-38нс, цикл процессора-9.5нс. Процессор в/в имеет буфер 8 Мслов. Буферная память до 32 Мслов. Время доступа к БП 0.5 мкс. Скорость обмена БП - ГОП до 10 Гслов в секунду.
V - векторные регистры 8 штук. Каждый векторный регистр состоит из 64-х 64bit регистров.
Т - Т-RG:64x64. S - пул S-RG:8x64 А - пул адресных регистров: 64х24
B - пул B-регистров: 8х24.
ком. рег. - командные регистры: 512х16.(для подкачки команд).
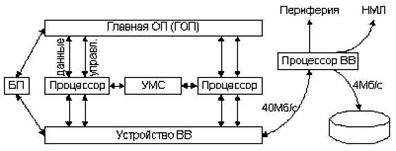
УА - управляющий автомат. БВО - блок векторной обработки; 3 подблока: ±, сдвиг, логические операции. Все устройства работают по конвейерной схеме (6 ступеней) микроконвейер. R1 - длина вектора - 7 бит, R2 - маска вектора - 64 бита, R3 - счетчик относительного времени - 32 бита. Системные часы 64 бита. Наличие буферной памяти резко сокращает время ввода-вывода. Эффективность системы при выполнении векторных операций достигается за счет уменьшения такта, за счет наличия 3-х параллельных портов для связи с памятью, а также за счет реализации аппаратно-программного механизма обработки цепочек векторов. Т. о. эффективность данной системы достигается за счет быстрого обмена между блоками скалярных и векторных операций, ускорения обращения к памяти и быстрым регистрам, а также за счет быстрого запуска скалярных и векторных операций через буферные регистры.
Сравнение с CRAY-1 (в разах). 1 и 2 процессорные системы.
Показатель производительности | 1 Пр | 2 Пр |
Смесь операций | 1 | 2 |
Преобладание скалярных операций | 1.5 | 3 |
Преобладание векторных операций | 2 | 4 |
Пиковая производительность | 4 | 8 |
Особенности работы в многозадачном режиме в состоянии с векторизацией.
1.Векторизация позволяет повысить производительность по сравнению со скалярной в 10-20 раз в зависимости от типа программы и длины вектора. 2.Число процессоров <=10 (т. к. они завязаны на общую память). 3.Число функциональных блоков примерно 10. 4.Число участков конвейера примерно 10. Это промежуточный вариант между одно - и многопроцессорной системой. Недостаток: Невозможность работы в реальном масштабе времени.
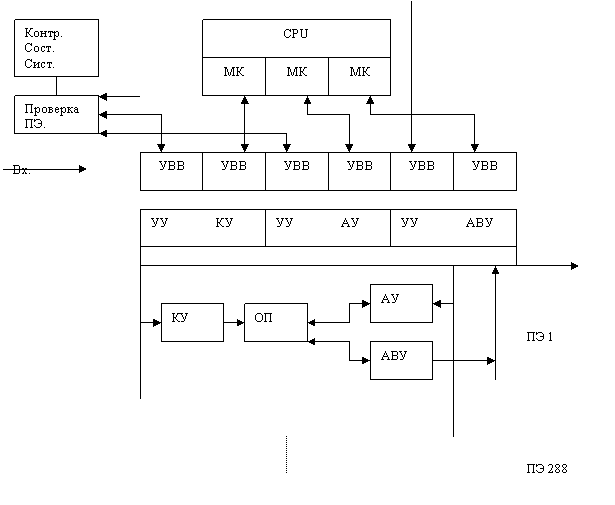
4. Ассоциативные вычислительные системы. Система PEPE.
Ассоциативный способ обработки данных позволяет преодолеть многие ограничения, присущие адресному доступу к памяти, за счет задания некоторого критерия отбора и проведение требуемых преобразований, только над теми данными, которые удовлетворяют этому критерию. Критерием отбора может быть совпадение с любым элементом данных, достаточным для выделения искомых данных из всех данных. Поиск данных может происходить по фрагменту, имеющему большую или меньшую корреляцию с заданным элементом данных.
Исследованы и в разной степени используются несколько подходов, различающихся полнотой реализации модели ассоциативной обработки. Если реализуется только ассоциативная выборка данных с последующим поочередным использованием найденных данных, то говорят об ассоциативной памяти или памяти, адресуемой по содержимому. При достаточно полной реализации всех свойств ассоциативной обработки, используется термин «ассоциативный процессор».
Также как и матричные они относятся к классу SIMD, т. е. характеризуются наличием большого числа ОУ, способных одновременно вести обработку неск потоков данных, но отлич способом формирования этих потоков.
Основная особенность – использование ассоциативной памяти.
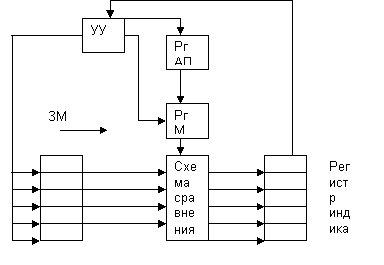

Выборка из АЗУ закл в следующем: из УУ в Рг АП передается код признака искомой инф-ии. если код используется полностью, то он без изменений передается на сх. Сравнения, если исп-ся только частьЮ то ненужные разряды маскируются. Перед выборкой все разряды Рг инд. Адр. Уст в 1.
Время обращения к памяти не зависит от её емкости, а зависит от количества разрядов.
Система PEPE содержит 3 основных компоненты:
- ведущий CPU
- ансамбль ПЭ, сост из 288 независимых ПЭ, каждый из кот сост из КУ, АУ, АВУ, и ОП
Благодаря этому PEPE может обраб параллельно до 864 комманд. УУ могут связываться м/у собой посредством логич устройства во внутр связи. Каждое УУ имеет по 2 УВВ, кот обеспечивает полнодуплексную связь с CPU

5. Транспьютеры. Транспьютеры фирмы INMOS.
Транспьютеры.
Транспьютер – это однокристальная микро ЭВМ, имеющая встроенные асинхронные каналы в\в
Области применения:
- платы ускорители
-использование во встроенных системах (в контроллере лазерного принтера)
- параллельные компьютеры общего назначения
Транспьютеры имеют 4 линии связи, благодаря чему можно организовать различные топологии
![]()
конвейерная
В больших двумерных структурах сталкиваются с трудностями:
- передача данных в массив
- нерегулярность передачи информации
Транспьютер - программируемая СБИС, может быть использован как в качестве МП, так и в качестве ячейки для больших ВС. Т800 ориентирован на выполнение программ на языке ОККАМ. Обмен информацией осуществляется через каналы (между ЦП). Для работы с внешней памятью предусмотрен интерфейс памяти с пропускной способностью 26.6 Мб/сек, позволяющий обращаться к памяти до 4 Гбайт.
Архитектура Т800:
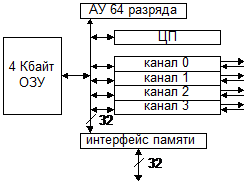
АУ-арифметическое устройство для расчетов с плавающей точкой
Каналы транспьютера имеют автономные контроллеры в/в, что обеспечивает параллельную работу многих устройств, возможно параллельное обращение к памяти.
Любое обращение к внешней памяти происх за 1 цикл. Слово выравнивается на 4 байта.
Т800: внутр память: начало - # конец #80000FFF
внеш память: 80001 7FFFFFFF
Система команд Т800:
Код оп. Поле данных
Всего 112 команд, 16 основных
0 - Jump 1 - Load Local Pointer
2 - Prefix 3 - Load non-Local
4 - Load constant 5 - Load non-Local Pointer
6 - negative prefix 7 - load local
8 - add constant 9 - Call
A - Conditional jump B - adjust workspace
C - equals constant D - store local
E - store non-local F - operate
Применение транспьютеров: 1. Высокопроизводительные комплексы, 2. Коммутатор цифровых потоков данных. 3. Встроенный микропроцессор в контроллерах, САУ. 4. Ускоритель в ПК. 5. В различных адаптерах, преобразователях, акселераторах.
Транспьютеры фирмы INMOS.
Семейство транспьютеров фирмы Inmos состоит из набора систем. Компонентов, каждый из которых объед обраб-ку Эл-т, систему связей и память в одном кристалле. Изготовлены по технологии СБИС
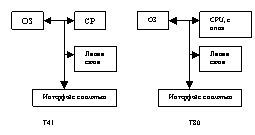

Наличие быстрой памяти позволило обойтись малым числом регистров в CPU – 6 RG для увеличения длины операнда используются префиксные функции, при выполнении каждой из которых данные сдвигаются на 4 разряда влево. CPU им. Эффективную поддержку параллелизма. Есть микропрограммный планировщик, который позволяет выполнять любое количество процессов в режиме разделения времени.
6. Модель коллектива вычислителей.
Модель коллектива вычислителей лежит в основе одного из подходов к построению вычислительных систем.
Малозависящие друг от друга части алгоритма одновременно обрабатываются на выч. средствах
В основе этой модели – три принципа:
- параллельность выполнения большого числа операций – рост производительности
- переменность структуры ( программно настр. На конкретный алгоритм)
- конструктивная однородность – простота, дешевизна.
7. Типовые схемы обмена информацией при реализации P-алгоритмов.
Построение || алгоритмов;
- локальное распараллеливание (ЯПЛ) (кружки)
- глобальное распараллеливание (линии (на линиях дорисовать кружки))

Все взаимодействия м/д ветвями || алгоритма сводятся к след. Видам обмена
- трансляционный – одна передает всем
- конвейерно параллельный – первая – второй, вторая – третьей и т. д.
- дифференцированный – i ая мшина -- j ой
- трансляционно – циклический обмен – трансляция в цикле
- коллекторный обмен – все машины передают информацию одной машине.
8. Системные операции.
Для совместной работы всех машин нужно организовать передачу данных между машинами. При этом можно выделить, например, следующие виды межмашинных взаимодействий: 1.Трансляционный обмен - одна ЭВМ передает всем; 2.Конвейерно-параллельный - передача информации от одной машины к другой за 2 такта: четные передают нечетным и наоборот; 3.Дифференцированный - между 2-мя ЭМ; 4.Трансляционно-циклический - каждая ЭМ по очереди берет на себя функции инициатора обмена; 5.Коллекторный - для сбора данных из всех ЭМ в одну.
Для управления структурой ОВС, процессом вычислений и обменами используются системные операции. Один из возможных полных наборов системных операций составляют операции настройки, обмена (передачи и приема), обобщенного условного и безусловного переходов.
Операции настройки предназначаются для программирования структуры связей между машинами (для настройки канала связи между требуемыми ЭМ) и для задания степени их участия при функционировании системы. Следовательно операции настройки должны позволять из данной машины изменять содержимое регистра настройки любой машины (передача служебной информации из памяти произвольной ЭМ в регистры настройки любых машин системы). Информация, содержащаяся в регистре настройки ЭМ, используется для управления коммутацией и реализации системных операций.
Операции обмена позволяют осуществить передачу в канал и прием из него любого количества слов. Разделение операций на передающую и приемную позволяет избежать трудностей, связанных с полной адресацией памяти в предположении неограниченного наращивания вычислительных машин в системе. По команде передачи информация передается в канал связи, образованный с помощью команд настройки коммутаторов. В машинах, которые подключены с помощью коммутаторов к каналу связи и содержат команды приема, осуществляется прием информации, поступающей из канала связи.
Операции обобщенного условного перехода (ОУП) используются для управления процессом вычислений при совместной работе машин в системе. Операции ОУП похожа на обычную операцию условного перехода для ЭВМ. Для выполнения операции ОУП необходимо, чтобы было выработано условие всеми машинами, участвующими в его выработке. После того как будет выработано обобщенное условие, во всех машинах, реализующих ОУП, происходит в зависимости от значения обощенного условия переход либо к очередной операции, либо к операции, указанной в адресной части. Эта же операция может быть использована для синхронизации машин перед обменом.
Операции обощеннного безусловного перехода (ОБП) используются для вмешательства в вычислительный процесс из одной машины в любую другую машину системы. При выполнении опреации ОБП информация и з памяти данной машины передается в другие машины через канал связи, где воспринимается как команда, подлежащая исполнению.
Приведенный набор системных операций является полным, сего помощью можно организовать самые разнообразные схемы организации параллельного вычислительного процесса. Этот набор системных операций может быть реализован многими способами: аппаратным (путем схемных решений), микропрограммным, программным (спомощью специальных процедур, составленных из команд машины) и т. д.
9. ЭМ ОВС. Состав, функциональное назначение.
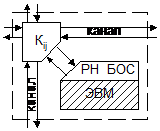

Под однородной вычислительной системой будем понимается совокупность ЭВМ, функциональное взаимодействие между которыми осуществляется через регулярную програмно настраиваемую сеть связи. Каждая вычислительна ямашина предназначена для выполнения функций не только по переработке и хранению информации, но и по управлению системными процессами, т. е. по организации функционирования совокупности машин как единого целого. Состав каждой ЭВМ можно варьировать в широких пределах. Минимальная конфигурация ЭВМ есть процессор и память; максимальная включает в себя также каналы, ВЗУ, терминалы, УВВ и др. ЭВМ, образующие систему, могут иметь различный состав, но каждая из них обязательно компонуется из однотипных процессорв и блоков оперативной памяти. Сеть связи между машинами образуется из каналов и коммутаторов (К), распределенных по машинам ОВС. Коммутатор реализует такой набор соединительных функций, который по крайней мере позволяет орга6низовать связь данной машины с ближайшими соседними. Вид соединительной функции определяется содержимым регистра настройки (РН). Таким образом, путем изменения содержимого РН можно задать любую коммутацию (из полного их набора) между входными и выходными полюсами коммутатора. Коммутатор и ЭВМ, дополненная блоком реализации системных операций (БОС), составляют элементарную машину (ЭМ). Системные операции позволяют организовать взаимодействие машин в процессе функционирования ОВС. Коммутатор, БОС и регистр настройки модуля могут быть конструктивно оформлены в виде специального модуля, называемого системным устройством. Топологическое размещение вычислительных машин в ОВС может быть одномерным, двумерным и, вооюще, n-мерным. Наиболее часто к n-мерным относятся ОВС, в которых каждая машина имеет 2n соседних ЭВМ. (на рисунке одиночная ЭМ и 2-мерная ОВС).
ОВС бывают: одно-, дву-, n-мерные. В зависимости от расстояния между ЭМ - сосредоточеннные и распределенные. В сосредоточенных время распространения сигналов между двумя наиболее удаленными ЭМ не больше среднего времени выполнения операции ЭМ. В сосредоточенных ЭМ запаздывание сигналов связи практически не влияет на производительность системы. Распределенные ОВС имеют машины удаленные на значительные расстояния. В зависимости от способа выборки настраиваемыхз ЭМ - с произвольной и упорядоченной схемами выборки. При произвольной настройке в любой момент может быть настроена любая ЭМ. При упорядоченной настройке ЭМ настраиваются в строго заданной последовательности. Также бывают с частично изменяемой структурой и с полностью изменяемой структурой. По методу управления структурой вычислений - с иерархической и с однородной структурами управления. При иерархической структуре управления программа работы находится в определенной группе машин (или в одной ЭМ), которая посылает команды управления во все остальные ЭМ системы. При этом устанавливаются иерархическая подчиненность иправила приоритета команд управления, поступающих от различных ЭМ. При однородной структуре управления все ЭМ системы равнозначны, программа решения задачи распределена между всеми ЭМ и ход вычислений в зависимости от полученных результатов изменяется с помощью операций обобщенного условного перехода. В зависимости от способа обмена информацией между ЭМ внутри ОВС и между ОВС и внешними объектами будем различать ОВС с параллельной, последовательной и параллельно-последовательной передачей слов. Также можно выделять системы с совмещенными и несовмещенными обменами. В первых в отличие от вторых возможен обмен информацией по каналам одновременно со счетом в машинах.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
