
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
1.Структура ЭВМ. Основные этапы решения задач на ЭВМ.
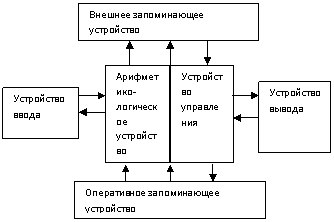 |
Устройство памяти:
1) Память компьютера должна состоять из некоторого кол-ва пронумерованных ячеек
2) В каждой ячейке могут находится или обрабатываться данные
3) Все ячейки памяти легко доступны для других устройств компьютера
4) Память линйна
1. Постановка задачи:
• сбор информации о задаче;
• формулировка условия задачи;
• определение конечных целей решения задачи;
• определение формы выдачи результатов;
• описание данных (их типов, диапазонов величин, структуры и т. п.).
2. Анализ и исследование задачи, модели:
• анализ существующих аналогов;
• анализ технических и программных средств;
• разработка математической модели;
• разработка структур данных.
3. Разработка алгоритма:
• выбор метода проектирования алгоритма;
• выбор формы записи алгоритма (блок-схемы, псевдокод и др.);
• выбор тестов и метода тестирования;
• проектирование алгоритма.
4. Программирование:
• выбор языка программирования;
• уточнение способов организации данных;
• запись алгоритма на выбранном языке
программирования.
5. Тестирование и отладка:
• синтаксическая отладка;
• отладка семантики и логической структуры;
• тестовые расчеты и анализ результатов тестирования;
• совершенствование программы.
6. Анализ результатов решения задачи и уточнение в случае необходимости математической модели с повторным выполнением этапов 2-5.
7. Сопровождение программы:
• доработка программы для решения конкретных задач;
• составление документации к решенной задаче, к математической модели, к алгоритму, к программе, к набору тестов, к использованию.
2. Понятие алгоритма. Свойства алгоритмов. Схемы алгоритмов.
Алгоритмом называют правила, предписывающие последовательность действий ведущих к достижению необходимого результата.
Свойства алгоритмов:
1)Массовость: под массовостью будем понимать возможность работы алгоритма.
2)Выполняемость: будем говорить, что алгоритм применим к допустимому исходному данному, если с его помощью отправляясь от этого исходного данного, можно получить искомый результат, т. е. алгоритмический процесс заканчивается за конечное число шагов.
3)Понятность: предполагается, что исполнитель правила будет всегда понимать, как его выполнить.
4)Определённость: исполнитель алгоритма не только не нуждается в какой-либо фантазии, но более того алгоритм, не оставляет место для проявления этих качеств даже если исполнитель ими обладает. (т. е. исполнитель, выполняя алгоритм, действует формально).
Схемы алгоритмов:
Любой алгоритм можно реализовать с помощью трёх структур:
1)Следование: линейное движение алгоритма. (линейная операция процедуры, в которой выполняется последовательность в порядке записи.)
2)Ветвление:
3)Цикл с предусловием: Условие-действие
| Пока условие – делать.
3. Блочная структура Паскаль – программ. Основные разделы.
Program <имя> (input, output)
Раздел описаний
Begin
Раздел операторов
End.
В заголовке программы даётся имя программы, которая внутри её не имеет никакого смысла.
В ( ) указываются стандартные файлы системы ввода, вывода.
После заголовка программы идёт раздел описаний переменных, функций и т. д.
1)USES: Играет важную роль при подключению к тесту программы системных и прикладных модулей из библиотек. Здесь указывается кальпелятору из какой библиотеки надо выбрать модули и включить их в текст программы. Библиотек включает в себя набор модулей каждый из которых замкнут, имеет своё имя и к программе подключается как чёрный ящик с известным интерфейсом. Каждый модуль представляет собой программу включающую описания типов и переменных, процедур и функций. Оператор юсес может быть использован только один раз, поэтому он идёт первым. Название библиотек подключённых к программе должны отделятся запятыми.
2)LABEL: Содержит перечисление через запятую имена меток переходов. Они не должны дублировать друг друга. Имя метки должно представлять собой целое число 0..9999, или комбинацию строк и чисел. Для того чтобы сослаться на оператора его надо выделить поставив перед ним через двоеточие метку.
Begin
Go to finish;
Finish:write();
3)CONST: Позволяет повысить наглядность программы и обеспечить простоту внесения изменений и повышает надёжность. В этом разделе содержится определения постоянных, используемых в программе.
4)TYPE: Описываются новые типы данных, отличные от стандартных. Позволяет программисту определить новый тип в программе.
5)VAR: В этом разделе содержится список переменных, используемых в программе, и определяется их тип. Локальные или глобальные. Каждая переменная используемая в программе должна быть описана. Принцип умолчания в паскале не работает.
6)PROCEDURE: Записывает подпрограмма осуществляющая сложные действия, которые необходимо произвести неоднократно на разных этапах выполнения программы.
7)Основной блок программы: В разделе содержится смысловая часть программы. Грамотно напечатанная программа на паскале имеет основную часть не более страницы.
Begin
End.
4. Стандартные простые типы данных.
1)Целые типы (integer): (определяют const, переменные и функции, значения которых реализуются множеством целых чисел, допустимых к данной ЭВМ).
Диапазон зависит от их внутреннего представления, который может занимать 1,2,4 байта. При действии с целыми числами тип результата будет соответствовать типу операторов. А если операнды относятся к разным типам, то результат будет того типа, который имеет макс. мощность. Возможное переполнение результата никак не контролируется и может привести к недоразумениям. (-32768..32767)
2)Вещественный (real, single, double, extended, comp) – позволяет работать с дробями. Занимает 4 байта. Вещественный тип не может использоваться для хранения ненормализованных чисел, значений, не являющихся числом (NaN), а также бесконечно малых и бесконечно больших значений. Ненормализованное число при сохранении его в виде вещественного принимает нулевое
значение, а не числа, бесконечно малые и бесконечно большие значения при попытке использовать для их записи формат вещественного числа приводят к ошибке переполнения.
3)Логический (Boolean): имеет роль флага ДА/НЕТ
4)Символический (CHAR): предназначен для хранения букв. (под букву отводится 1 байт)
5. Перечислимый и ограниченный тип данных.
1)Перечисляемый тип — в программировании тип данных, чьё множество значений представляет собой ограниченный список идентификаторов.
Перечислимый тип определяется как набор идентификаторов, с точки зрения языка играющих ту же роль, что и обычные именованные константы, но связанные с этим типом. Классическое описание типа-перечисления в языке Паскаль выглядит следующим образом:
2)Ограниченный: Для порядковых типов можно задать поддиапазон их возможных значений для вводимого вами типа или переменной - это и будет ограниченный тип. Задается диапазон значений ограниченного типа выражением вида
<минимальное значение>..<максимальное значение>
6.Процедура ввода данных.
Для чтения данных из файла и ввода данных с клавиатуры используется read и readln.
Read считывает данные с одной строки
Readln считывает данные с новой строки.
Если значений введено больше чем в переменных то они останутся в буфере ввода.
7. Процедура вывода данных.
Для вывода данных на экран используются процедура write (writeln).
Write(‘a=’,a:3:3); где write(<текст который вы хотите вывести на экран>, <имя переменной которую вы хотите вывести на экран>:<число символов перед запятой>:<… после запятой>)
8. Основные операторы языка Паскаль. Оператор присваивания, составной оператор.
+,-,*,/,sqrt, sqr, abs, exp, mod, div, begin, end, dec, inc, pred, succ.
1)Присваивание: «s:=10;»
2)Оператор ввода/вывода: read(),write().
3)Составной: конструкция включающая в себя несколько команд, но участвующая в программе в качестве единого оператора.
4)Оператор перехода goto.
9. Условный оператор.
Условный оператор IF служит для организации процесса вычислений (изменения последовательности выполнения операторов) в зависимости от какого-либо логического условия.
If <условие> then <операция1> else <операция2>
Условие может быть представлено логической константой (FALSE – ложь, TRUE - истина), переменной логического типа (Boolean) или логическим выражением.
Если условие истинно, то выполняется оператор (простой или составной), следующий за словом THEN, в противном случае, когда условие ложно, будет выполняться оператор, следующий за словом ELSE. Альтернативная ветвь ELSE может отсутствовать, если в ней нет необходимости. В таком “усеченном” варианте, в случае, если условие оказывается ложным, ничего не происходит и выполняется оператор следующий за условным оператором IF.
10)Оператор вывода CASE.
Оператор варианта необходим в тех случаях, когда в зависимости от значения какой-либо переменной нужно выполнить те или иные операторы (простые или составные). Если вариантов всего два, то можно обойтись и оператором IF. Но если их, например, десять? В этом случае оптимален оператор варианта CASE.
Синтаксис оператора CASE:
CASE Управляющая Переменная Или Выражение OF
НаборЗначений1 : Оператор1;
НаборЗначений2 : Оператор2;
НаборЗначений3 : Оператор3;
. . .
Набор Значений N : Оператор N
ELSE Альтернативный Оператор
END;
Между служебными словами CASE и OF должна стоять переменная или выражение (оно вычисляется при исполнении оператора CASE) целочисленного или любого порядкового типа. Набор значений – это конкретные значения управляющей переменной или выражения, при которых необходимо выполнить соответствующий оператор, игнорируя остальные варианты. Если в наборе несколько значений, то они разделяются между собой запятой.. Можно указывать диапазоны значений, например, 0..9 – все значения от нуля до девяти. Наборы значений и диапазоны можно комбинировать. Между набором значений и соответствующим ему оператором обязательно ставится символ “:”. Значения в каждом наборе должны быть уникальными, т. е. они могут появиться только в одном варианте. Пересечение наборов значений для разных вариантов является ошибкой, и она будет замечена компилятором.
Оператор (Оператор1, Оператор2, …) в конкретном варианте может быть как простым, так и составным.
11. Логические выражения в языке Паскаль.
Логическое выражение — конструкция языка программирования, результатом вычисления которой является «истина» или «ложь».
1)Или (дизъюнкция) – or ((a>2) or (b<3))
2)И (конъюнкция) – and ((a>2) and (b<3))
3)Не (отрицание) - not ((not a>2) or (not b<3))
12. Цикл с параметром.
Циклическим называется алгоритм, который содержит участок, выполняющийся многократно, каждый раз с новыми значениями переменных, изменяющихся по одним и тем же законам.
For i:=a to b do <оператор>
For i:=a downto b do <оператор>
13. Цикл с предусловием.
While <условие> do <оператор>
14. Цикл с постусловием.
Repeat <оператор> until <условие>
15, 21. Вложенные циклы.
Цикл называется вложенным, если он размещается внутри другого цикла. На первом проходе, внешний цикл вызывает внутренний, который исполняется до своего завершения, после чего управление передается в тело внешнего цикла. На втором проходе внешний цикл опять вызывает внутренний. И так до тех пор, пока не завершится внешний цикл. Само собой, как внешний, так и внутренний циклы могут быть прерваны командой break.
Запрещена ситуация, когда циклы частично пересекаются, т. е. конец внутреннего цикла выходит за границу внешнего цикла.
16, 17. Структурный тип данных. Массивы и их описание. Одномерные и двумерные массивы.
Объединение нескольких элементов данных в структуру под одним именем создаёт сложную структуру данных – структуризация. Паскаль содержит много структурированных данных которые могут представлять структурированные значения: массивы, записи, множества, файлы.
Выбор той или иной структуры данных определяет алгоритм обработки этих данных.
Самый простой это регулярный тип и регулярная структура называемая массивом.
Массив – это совокупность фиксированного числа элементов одинакового типа. Массивы необходимы тогда, когда приходится иметь дело с наборами однородных и однотипных данных.
Такой набор имеет общее для всех элементов имя и называется массивом. Массивы бывают одномерными и многомерными. Многомерными называются массивы элементы которых тоже массивы. Массив определяется типом элементов и их количеством. Количество элементов определяются размерностью массива и диапазоном изменяемости каждой размерности. В массиве под одним именем объединяется множество однотипных элементов, каждый из которых имеет определённый номер. (индекс) обращение к элементам происходит только по цифрам. Количество индексов необходимых для определения положения каждого жлемента массива совпадает с его размерностью.
Индекс – номер элемента массива, как правил – число или выражение типа интежер.
Элементом массива может быть любой тип данных за исключением типа файла. Массив может состоять из структуры данных.
Одномерные массивы, по сути, представляют собой список однотипных переменных. Чтобы создать массив, вначале необходимо создать переменную массива требуемого типа. Общая форма объявления одномерного массива выглядит следующим образом: ТИП имя_переменной[] ;
Двумерный массив - это одномерный массив, элементами которого являются одномерные массивы. Другими словами, это набор однотипных данных, имеющий общее имя, доступ к элементам которого осуществляется по двум индексам. Наглядно двумерный массив удобно представлять в виде таблицы, в которой n строк и m столбцов, а под ячейкой таблицы, стоящей в i-й строке и j-м столбце понимают некоторый элемент массива a[i][j].
При написании программы необходимо следить за тем, чтобы значение индексов не привышало границ, указанных при объявлении массива, т. к. выход за границы массива приведёт к сбою в работе программы.
18. Подпрограммы. Процедуры и функции. Сходство и отличия.
1)Процедура – это подпрограмма, являющаяся независимой и поименованной части программы, предназначенной для выполнения определённых действий. Процедурой является оператор с которым связано некоторое имя. После однократного описания процедуру можно называть по имени из последующих частей программы.
Использование имени процедуры в программе называется оператором процедуры или вызовом процедуры. После использования процедуры программа продолжается с оператора следующего за оператором вызова процедуры.
Описание процедуры:
Описание процедуры размещается в основной программе после раздела описания CONST и TYPE.
Для выполнения процедуры необходимо обратиться к ней по имени выполняемой части программы и указать в ( ). При вызове процедуры устанавливается взаимнооднозначное соответствие между формальными и фактическими.
Затем правление передаётся процедуре. После окончания работы процедуры, управление передаётся основной программе на оператор, следующей за вызовом процедуры.
2)Функция: Если процедура может возвращать 0, 1 и более параметров, то функция возвращает ровно одно значение. В этом случае функцию можно рассматривать как частный случай процедуры.
Основные функции уже встроены в Pascal и называются стандартными.
Однако при написании программы возникают ситуации когда удобно определить свою собственную функцию, чтобы обращаться к ней также просто как и к стандартной функции. Впоследствии программисту не обязательно понимать как выполняется функция, ему достаточно уметь правильно задать аргументы функции, и знать какое значение она выдаёт при выходе.
Функция может возвращать значения типа:
-integer
-real
-boolean
-char
-string
-pontek
Функция – это логически законченный фрагмент программы, имеющий собственное имя, предназначенный для определения функциональной зависимости и вырабатывающий некоторую информацию, которая называется значением или результатом функции.
Всё ранее сказанное для процедур верно и для функции, но есть 2 существенных отличия:
-В теле функции должно быть не менее одного оператора, присваивающего значению имени функции.
- В заголовке функции, которая начинается служебным словом FUNCTION, обязательно указывается имя типа, возвращаемого значению.
22.Локальные и глобальные переменные.
Локальные переменные - это переменные которые видны только тому куску программы (функции, процедуры) в котором они записаны.
Глобальные переменные – это переменные которые задаются в теле самой программы, и к ним можно обращаться отовсюду, к этим переменные видны всей программе. (все объекты описанные после слова программ до объявления процедуры или функций наз-ся глобальными, и они доступны внутри самой процедуры, функции и доступны само программе.)
Использование глобальных перемен внешне упрощает работу, все нужные переменные видны отовсюду. Но с другой стороны использование глобальных перемен - плохо.
-Переменные работают только с исходными данными, если приходиться решать задачу с другими исходными данными, то придётся писать ещё одну процедуру.
-в процедуре основной программы возможно изменение глобальных перемен, и если процедур много, то весьма затруднительно найти, то место где это произошло.
Это приводит к снижению надёжности программы и повышению стоимости.
25. Способы передачи параметров. Правило согласования формальных и фактических параметров.
Сравнение.
Существует несколько способов передачи параметров в подпрограмму.
Передача параметров по имени. В формальный параметр может быть помещено произвольное выражение. При этом вычисление этого выражения произойдёт внутри подпрограммы в тот момент, когда потребуется его значение. Если это значение фигурирует несколько раз, то и вычисляться оно будет тоже несколько раз. Параметры, передаваемые по имени, дают возможность писать довольно универсальные подпрограммы. Такой способ передачи параметров используется, к примеру в языках Алгол или Алгол 68.
Передача параметров через стек. Это фактически разновидность передачи параметра по значению «с ручным приводом», в данном случае отсутствует понятие формальных и фактических параметров. Все параметры лежат на стеке, причём их типы, количество и порядок не контролируются компилятором. Данный подход реализован в языке Форт.
Язык программирования может предоставлять возможность передавать параметры в подпрограммы либо только по значению (так сделано в языке Си), либо по значению и по ссылке (это реализовано в Паскале, Аде, C++), либо по имени и значению (это реализовано в языках Алгол и Алгол 68). В последних двух случаях для различения способов передачи параметра используются отдельные синтаксическая конструкции (в Паскале это ключевое слово var при описании параметра). В действительности, если язык содержит понятие ссылки (указателя), то можно обойтись и без передачи параметра по ссылке (её всегда можно смоделировать, описав параметр типа «ссылка»), но эта возможность удобна, так как позволяет работать с формальным параметром-ссылкой без разыменования, а также повышает надёжность и безопасность программы.
На параметры, передаваемые по ссылке, накладываются естественные ограничения: фактический параметр, подставляемый на место такого параметра при вызове, обязан быть переменной (то есть иметь адрес), а в языках со строгой типизацией — ещё и иметь в точности такой же тип данных.
Передача по значению.
Передача параметров по значению. Формальному параметру присваивается значение фактического параметра. В этом случае формальный параметр будет содержать копию значения, имеющегося в фактическом, и никакое воздействие, производимое внутри подпрограммы на формальные параметры, не отражается на параметрах фактических. Так, если в качестве фактического параметра будет использована переменная, и внутри подпрограммы значение соответствующего формального параметра будет изменено, то фактический параметр останется без изменений.
int func1(int x) { x=x+1; return x; }
Передача по ссылке.
Передача параметров по ссылке. В формальный параметр может быть помещён сам фактический параметр (обычно это реализуется путём помещения в формальный параметр ссылки на фактический). При этом любое изменение формального параметра в подпрограмме отразится на фактическом параметре — оба параметра во время вызова подпрограммы суть одно и то же. Параметры, передаваемые по ссылке, дают возможность не только передавать параметры внутрь подпрограммы, но и возвращать вычисленные значения в точку вызова. Для этого параметру внутри подпрограммы просто присваивается нужное значение, и после возврата из подпрограммы переменная, использованная в качестве фактического параметра, получает это значение.
void func2(int &x) { x=x+1; }
27,28,29.Сортировка в языке Паскаль.
Под сортировкой понимают процесс перестановки объектов данного множества в определённом порядке. Цель: облегчить последовательный поиск элементов в сортированном множестве.
1) Сортировка массивов.
2) Сортировка файлов.
Эти две категории называют внутренней и внешней. Массивы располагаются во внутренней оперативной памяти ЭВМ, которые характеризуются быстродействием, но малым объёмом, а файлы хранятся в более медленных, но более вместительной памяти на дисках.
Пусть даны элементы А1,А2,Аn. Сортировка означает перестановку этих элемнетов в таком порядке Ак1, Ак2, .. , Акн, что при заданной функции упорядочивания Ф(Ак1),Ф(Ак2),..,Ф(Акн).
Обычно функция упорядочивания не вычисляется по какому то специальному файлу, а содержится в каждом элементе в виде явной компоненты поля. Ее значение называется ключом элемента, а само поле ключевым, следовательно для представления элемента А хорошо подходит структура данных типа Запись.
Type
Item=record
Key:integer;
Data:t_date;
Поле дата –все существенные данные об элементе, поле кей – ключ который служит для идентификации элементов.
Для алгоритмов сортировки есть единственная существующая компонента, и нет необходимости определять остальные данные. Кей может иметь любой тип, на котором задано отношение порядка чар, реал, интежер, стринг, байт, ворд.
Основное требование к методу сортировки – экономное использование памяти, это значит, что переупорядочивание элементов надо производить в исходном массиве. Метод сортировки можно разбить на 3 основных класса, в зависимости о лежащего в их основе приёма.
1) сортировка вставок
2) сортировка выбором
3) сортировка обменом (пузырёк)
27. Сортировка Обменом (пузырёк).
Основан на том, что более «лёгкие» элементы массива постепенно «всплывают» , то есть переносятся к началу массива. Происходит сравнение и обмен соседних элементов попарно, пока не будут отсортированы все элементы.
Алгоритм пузырьковой сортировки по возрастанию состоит из последовательных просмотров снизу вверх (от конца к началу) массива. Если нижний элемент из 2-х соседних меньше верхнего, то выполняется обмен значениями таких элементов.
1. Сначала сравниваются 2 последних элемента массива (последний и предпоследний). Если последний элемент меньше чем предпоследний, то происходит обмен значениями этих элементов.
2. Дальше сравнивается 2-й и 3-й с конца элементы массива и если элемент расположенный ниже меньше, то он меняется местами со своим верхним соседом.
3. И т. д. до начала массива. В результате чего на 1-м месте окажется элемент массива с наименьшим значением.
4. Далее процесс по парного сравнения продолжается от конца массива уже до 2-го элемнта массива, т. к. 1-й элемент уже упорядочен. В результате на 2-м месте окажется элемент, значение которого меньше значения 1-го элемента.
5. И т. д. пока все элементы не будут упорядочены.
Главное достоинство – простота.
Наиболее серьёзным недостатком является быстрое замедление, когда кол-во элементов становиться большим.
Во многих случаях показано, что последние несколько проходов не влияют на порядок, т. к. они уже отсортированы(цикл работает впустую.
Способ улучшения алгоритма, это выяснить производился ли на данном проходе обмен, если нет, то алгоритм может закончить свою работу.
Program bubble_sort;
Const n=10;
Type vector=array[1..10] of real;
Var
Vec:vector;
Temp:real;
I, j:integer;
Begin
{vvod vec}
For i:=2 to n do
Begin
For j:=n downto I do
Begin
If vec[j]<vec[i]
Then
Begin
Temp:=vec[j-1];
Vec[j-1]:=vec[j];
Vec[j]:=temp;
End;
End;
End;
{pechat}
End.
Асимметрия метода.
Один лёгкий пузырь в тяжёлом конце отсортированного массива выплывает на место за 1 проход, а тяжёлый элемент в лёгком конце будет опускать на правильное место только на 1 шаг на каждом проходе, потом первый массив будет упорядочен за 1 шаг, а второй потребует больше проходов.
Отсюда вывод: менять направление следующих на других проходах, т. е. двигаясь снизу вверх, поднимаем лёгкий элемент, а двигаясь сверху вниз, опускаем тяжёлый элемент, получаем шейкер сортировку.
Сортировка обменом и её небольшие улучшения хуже, чем сортировка выбором и вставок. Их выгодно использовать, когда известно, что элементы упорядочены (но это очень редко).
28. Сортировка методом вставок(включения).
Элементы просматриваются по одному и каждый новый элемент вставляется в подходящее место среди ранее упорядоченных. Аналогичным образом игроки упорядочивают свои карты после раздачи.
Принцип метода.
Массив разделяется на 2 части – отсортированную и не отсортированную.
Элементы из не отсортированной части поочерёдно выбираются и вставляются в отсортированную часть. Так чтобы не нарушать в ней упорядоченности.
В начале работы алгоритм в качестве не отсортированной части принимает только один 1-й элемент, а в качестве не отсортированного все остальные, таким образом алгоритм будет состоять из (н-1) проходов, где н - размер массива, и каждый из которых будет включать 4 действия.
1) Взятие очередного и-го элемента и сохранение его копии в дополнительной переменной.
2) Поиск позиции «ж» в отсортированной части массива в которой присуттвие взятого элемента не нарушит упорядоченности элементов.
3) Сдвиг элементов массива от «и-1» до «ж» вправо, чтобы освободить найденную «ж-ю» позицию вставки.
4) Вставка взятого элемента в «ж-ю» позицию из дополнительной переменной.
Program sort_ins;
Const n=10;
Type vector=array[1..10] of real;
Var
Vec:vector;
Temp:real;
I, j, k:integer;
Begin
{vvod vec}
For i:=2 to n do
Begin
Temp:=vec[i];
J:=1;
While (temp>vec[j]) and (j<=i-1) do
J:=j+1;
For k:=i-1 downto j do
Vec[k+1]:=vec[k];
Vec[j]:=temp;
End;
{pechat vec}
End.
29. Сортировка методом выбора.
Суть метода сортировки по возрастанию такова:
1) Массив имеет 2 части: упорядоченную и неупорядоченную.
2) В отдельной переменной заполняется минимум, равный первому элементу и его индекс, 1-й элемент массива составляет упорядоченную часть, неупорядоченная часть массива начинается со второго элемента.
3) В неупорядоченной части массива ищется минимальный элемент и его индекс.
4) Обмен значений найденного минимального элемента с последним элементом в упорядоченной части.
5) Граница упорядоченной части сдвигается вправо на 1 элемент и добавочный элемент в упорядоченной части подлежит сортировке и т. д. до тех пор пока упорядоченная часть массива не будет составлять (н-1) элемент массива.
Program srot_choose;
Const n=10;
Type vector=array[1..10] of real;
Var
Vec:vector;
Min:real;
I, j,imin:integer;
Begin
{vvod vec}
For i:=1 to n-1 do
Begin
Min:=vec[i];
Imin:=I;
For j:=i+1 to n do
Begin
If vec[j]<min
Then
Begin
Min:=vec[j];
Imin:=j;
End;
End;
If min<vec[i]
Then
Begin
Vec[imin]:=vec[i];
vec[i]:=min;
end;
end;
{pechat}
End.
30. Индексная сортировка
Сортировка по индексному полю предполагает сортировку по исходным данным с использованием вспомогательного массива.
Элементом массива является запись содержащая ключевое поле (информация которого подлежит сортировке) и номер соответствующей строки массива (индекс), откуда взята эта информация.
Изначально индексный массив получается упорядочиванием по номерам строк, а по ключевому полю неизвестно, затем сортируется вспомогательный массив по ключевому полю и переставляется в записи целиком вместе с номерами строк. В результате индексный массив становится упорядоченным по ключевому полю, а по номерам строк как получится, исходный массив записей при этом останется без изменения. Для просмотра данных исходного массива в отсортированном порядке используется упорядоченный индексный массив. Индексный массив определяет порядок исходного массива. Идёт цикл по индексному массиву, берётся значение очередного индекса и печатается элемент основного массива с индексом, взятым из этого индексного массива. Таким образом осуществляется вывод исходного массива в порядке заданном номерами строк в отсортированном индексном массиве. Собственно сортировка индексного массива осуществляется любым способом.
Индексная сортировка находит высокое применение в базах данных, содеражащие таблицы с большим числом столбцов и строк. Сортировать по разным столбцам не эффективно, т. к. после каждой сортировки надо хранить копию массива упорядоченного по одному полю. Получается число копий таблиц равно числу сортировок по разным столбцам (ключевым полям). После изменения таблицы все сортировки приходится проводить заново.
Недостатки очевидны: большие затраты памяти и времени на сортировки.
Индексные массивы занимаю мало места во время работы хранятся в оперативной памяти и после изменения основного массива легко переупорядочиваются.
31. Символьные переменные и строки. Обработка строк. Операции со строками.
Строка – последовательность значений типа CHAR длинной от 0 до 255 символов.
При использовании в выражениях строки выделяются апострофами(' ')
Для определения данных строчного типа используется идентификатор STRING за которым следует в квадратных скобках максимальное кол-во символов в строке, если это значение не указано, то по умолчанию максимальная длинна строки равна 255 символов.
Примеры объявления и использования строковых постоянных и переменных:
Const
MyS=’first’
Var
S1:string[12];
S2:string;
Для хранения строки даётся дополнительный байт, он находится в начале строки, т. е. является её нулевым байтом и предназначен ля хранения её длины.
В байте с индексом 0 хранится символ, ASKI код которого равен длине строки. Текущую длину строки можно получить с помощью функции length(s).
В программах к каждому символу строки можно обратиться отдельно.
Например: s1[i]:=’a’;
К строкам можно применять оператор конкатенации (соединения), а также сравнения.
Сравнение строк выполняется посимвольно слева направо до первого несовпадающего символа. Большей считается та строка, которой больше код первого не совподающего символа в соответствии с таблицей АСКИ.
Такой способ взаимного расположения строк называется «Лексико-графической упорядоченностью».
32. Специальные процедуры и функции для работы со строками.
При работе со строками используются операторы функций:
1) CONCAT(S1,S2) соединяет строки с1 и с2
2) COPY(S, I,N); копирует из строки с, с позиции и, н-элементов.
3) DELETE(S, I,N) удаляет из строки с, с позиции и, н-элементов.
4) INSERT(S1,S2,I) вставлет строку с1, в строку с2 с позиции и.
5) POS(S1,S2) ищет позицию подстроки с1 в строке с2, если не нашёл то ставит 0.
6) VAL(S, X,Code); перевод из строкового типа с в числовой х и коде-позиция ошибки если 0 то ошибки нет.
33. Прокраммирование с использованием множеств. Тип данных – множества.
Это набор однотипных логически связанных друг с другом объектов. Множества рассматриваются как набор констант одного типа. Может принадлежать либо не принадлежать множеству.
Элементы конкретного множества должны принадлежать одному типу, который называется базовым типом. Количество элементов входящих множество может меняться в диапазоне от 0 до 255. Именно не постоянством кол-ва элементов множество отличается от массивов и записей. В отличие от массива к элементу множества нельзя обращаться по индексу. Множество не содержащее элементов называется пустым и обозначается []. Тип множество задаётся либо перечислением значений, либо отрезком типа, либо именем скалярного типа.
Операции над множествами.
1) Пересечение – элементы общие для обоих множеств.
2) Объединение – элементы первого множества дополненные элементами второго множества.
3) Разность – элементы первого множества не содержащие элементов второго множества.
4) Проверка эквивалентности – все элементы в обоих множествах одинаковые, причём порядок безразличен.
5) Проверка не эквивалентности – элементы различны в обоих множествах.
6) Вхождение
7) Проверка принадлежности ['a'] in ['a','b','c'] – true
Если все элементы одного множества входят в другое множество то говорят о вхождении одного множества в другое.
Пустое множество включается в любое множество.
34.Программирование с использованием записей. Тип данных – запись.
Записи являются составной структурой данных.
Record - структурированный тип данных, состоящий из фиксированного числа компонентов одного или нескольких типов, называемых полями. Такой тип удобен для комбинации полей различных типов. Возможно сформирование структуры данных из элементов различных типов данных.
Между массивами и записями имеются различия. Если все компоненты массива должны быть одного типа, то записи могут содержать компоненты различных типов. Для массива доступ осуществляется по индексу или по выражению.
Нет однородности по типу данных полей.
Фиксированные Записи состоят из одного или нескольких фиксированных полей для каждого из которых при объявлении задаётся или поле или его тип. Обращение к полям выполняется с помощью идентификаторов, в которых указывается вся цепочка имен от идентификатора переменной до идентификатора требуемого поля.
Записи могут передаваться в качестве параметра процедуры или функции, но значением функции она быть не может при заполнении информации структур, через оператор read, следует помнить, что из текстовых файлов можно вводить данные только стандартных типов, а не типов задаваемых пользователем, поэтому оператор read должен содержать идентификаторы внутренних полей, которые имеют стандартный тип.
Ввод записи из файла. При наборе текстового файла следует соблюдать правила.
1) Символьные (строковые) поля не должны отделятся пробелами, т. е. должны быть впритык друг к другу. Число знаковых мест в каждом поле должно строго соответствовать длинне поля заданного при его писании, недостающие места следует заполнить пробелами справа до конца фактической длины поля. В этом случае все разноимённые поля будут располагаться в отдельных колонках. Получается таблица.
2) После поля перед числом нужно ставить пробел, и после числа тоже.
3) Числа отделяют друга от друга пробелами.
35.Оператор присоединения WITH при работе с записями.
Если используются длинные идентификаторы полей или записей, или возникает необходимость обращаться к одной и той же записи несколько раз на небольшом отрезке текста программы, то для упрощения работы и предания программе большей наглядности используется оператор присоединения WITH.
Целесообразно использовать WITH для вложенных записей.
Один раз указав переменную типа Запись в операторе WITH можно работать с именами полей, как с обычными переменными, т. е. без указания имени переменной определенной записью.
WITH имя пер. Записи do
Оператор
Поскольку на тип значения полей не накладывается ограничения то отдельными полями записи могут быть сложные типы данных например записи.
39.Файловый тип данных. Работа с текстовыми файлами в паскале.
Любой файл имеет 3 характеристических особенности.
1)Имеет имя
2)Содержит компоненты одного типа.
3)Типом может быть любой тип, кроме файла.
Const fname=’<адрес>’;
Var
<имя>:file;
<имя>:text;
Assing(<файли из которого считывается информация>;fname);
Reset(); читать файл
Rewrite(); писать файл
Close(); - закрыть файл
Erase(); - удалить файл
Append(<файл в который закладывается информация>) читать и писать.
Close();
