

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Ячейка (Название улицы или № комнаты) самая большая по количеству байтов.
3). Множества.
Множества – наборы однотипных, логически связанных друг с другом объектов. Характер связи между ними контролируется только программистом, а не компьютером. Максимальное количество элементов в множестве 256 минимальное 0.
Множества отличаются от массивов и записей непостоянством своих элементов. Элементы могут включаться в множество и выключаться из него. Механизм работы и множествами в Delphi схож с механизмом работы в математике.
Два множества считаются равными - если они содержат одинаковые элементы.
A {a, b, c, x}
B {c, x, y}
Пересечением – называются общие элементы двух множеств.
A ∩ B = {c, x} – пересечение.
A U B = {a, b, c, x, y} – объединение.
C = { } – пустое множество.
Если все элементы одного и того же множества входят в другое, то говорят, что A входит в B.
Формат записи множеств:
Type
<имя>= set of <базовый тип>
В качестве базового типа может использоваться любой подходящий тип кроме integer, int 64 …
Type
Mnozh = set of ‘a’…‘z’;
Var
S1, s2, s3: mnozh
Begin
S1:= [‘a’, ‘b’, ‘t’, ‘x’];
S2:= [‘a’..‘k’, ‘x’..‘z’];
Над множествами определены следующие операции:
* - пересечение; s1*s2 [‘a’, ‘b’, ‘x’]
- - разность; s1-s2 [‘t’]
= - проверка эквивалентности (возвращает true, если они эквивалентны);
<> - проверка не эквивалентности (возвращает true, если они эквивалентны);
+ - объединение множеств;
<= - проверка вхождения (возвращает true, если s1 входит в s2);
[s1<=s2]
>= - проверка вхождения (возвращает true, если s2 входит в s1);
[s1>=s2]
in – проверка принадлежности (возвращает true, если указанный элемент входит в множество);
<элемент> in <множество>
Некоторые алгоритмы для работы с массивами:
1) Заполнение массива случайными числами:
Var
a: array of integer;
i: integer;
Begin
Randomize;
Setlenght (a, 10);
For i = 1 to n-1 do
a[i]:= random (101);
End;
s := (k * si-1) mod N, где k – начальное значение (стартовое число).
2) Алгоритм поиска минимального и максимального элемента массива:
Var
a: array of integer;
i: integer;
min, max, n: integer;
nmin, nmax: integer;
Begin
N:= 10
Setlanght (a, n);
For i = 1 to n-1 do
a[i]:= random (101);
End;
Max:= a[0]; nmax:= 0;
Min:= a[0]; nmin:= 0;
For i:= 1 to n-1 do begin
if a[i] > max then begin
max:= a[i];
nmax:= i;
End;
if a[i] < min then begin
min:= a[i];
nmin:= i;
End;
End;
End;
3) Алгоритм сортировки массива:
Существует множество способов сортировки массива:
· Метод min или max элемента;
· Метод пузырька;
· Метод Шелла;
· Метод бинарного поиска;
· ...
Метод min или max элемента:
Const
n = 100
Var
a: array [1..n] of integer;
temp, max, nmax, i, j: integer;
Begin
n:= 100
Setlanght (a, n);
For i := 1 to n-1 do
a[i]:= random (101);
End;
max:= a[1], nmax:=1;
For i:= 1 to n-1 do begin
For j:= 2 to n do
if max < a[j] do begin
max:= a[j];
nmax:= j;
End;
if max > a[i] then begin
temp:= a[i];
a[i]:= max;
a[nmax]:= temp;
End;
max:= a[i+1];
nmax:= i+1;
End;
End;
End;
4) Алгоритм исключения элементов из отсортированного массива:
Var
a: array of byte;
n, n1, p, x, i: integer;
Begin
n:= 100
SetLenght (a, n);
For i = 1 to n-1 do
a[i]:= random (101);
End;
max:= a[1], nmax:=1;
For i:= 1 to n-1 do begin
For j:= 2 to n do
if max < a[j] do begin
max:= a[j];
nmax:= j;
End;
if max > a[i] then begin
temp:= a[i];
a[i]:= max;
a[nmax]:= temp;
End;
max:= a[i+1];
nmax:= i+1;
End;
End;
d:= 7; [исключенный элемент]
p:= -1;
For i:= 0 to n-1 do
if x=a[i] then p:=i;
if p=-1 then begin
ShowMessage (‘такой элемент отсутствует’);
Exit;
End;
For i:= p to n-1 do
a[i]:= a [i+1];
SetLenght (a, n-1);
End;
End;
5) Добавление элемента в отсортированный массив:
Var
a: array of integer;
n, p, x, i: integer;
Begin
n:= 100
SetLenght (a, n);
For i = 1 to n-1 do
a[i]:= random (101);
End;
max:= a[1], nmax:=1;
For i:= 1 to n-1 do begin
For j:= 2 to n do
if max < a[j] do begin
max:= a[j];
nmax:= j;
End;
if max > a[i] then begin
temp:= a[i];
a[i]:= max;
a[nmax]:= temp;
End;
max:= a[i+1];
nmax:= i+1;
End;
End;
x:= StrToInt (Edit1. text);
If x<= a[0] then
Begin
SetLenght (a, n+1);
For i:=n-1 down to 0 do
a[i+1]:=a[i];
a[0]:=x
End;
if x>a [n-1] then begin
SetLenght (a, n+1);
a[n]:=x;
End;
If (x>=a[0]) and (x<=a[n-1]) then begin
For i:= 0 to n-2 do
if (x>=a[i]) and (x<=a[i+1]) then
p:= i+1;
For i:= n-1 down to p do a[i+1]:= a[i]
a[p]:=x
End;
End;
6) Пример алгоритма работы с множествами:
Программа выделяет из 1 сотни натуральных чисел (все простые числа). Алгоритм заимствован из приема “Решето Эратосфена”.
Const
N=100;
Type
SetOfNamber = set of 1..n;
Var
n1, next, i: word;
BeginSet, PrimSet: SetOfNamber;
Begin
BeginSet:= [1..n];
PrimSet:=[1];
Next:= 2;
While begin set <> [ ] do begin
n1:=next;
While n1<=n do begin
BeginSet:=BeginSet – [n1];
N1:= n1+next;
End;
PrimSet:=PrimSet+[next];
Repeat
Ine(next);
Unit(next in BeginSet) or (next>n);
End;
7) Заполнение случайным образом двумерного массива (матрицы):
Var
a: array [1..n; 1..m] of byte
For i:=1 to n do
For j:= 1 to m do
a[i, j]:= random (11);
Совместимость и преобразование типов.
Два типа являются совместными если:
· Оба одинаковы;
· Один тип является типом-диапазоном другого;
· Оба вещественны;
· Оба целые;
· Оба являются типами-диапазонами одного и того же базового типа;
· Оба являются множествами, составленными из элементов одного и того же базового типа.
Пусть t1 – тип переменной, а t2 – тип выражения. Операция t1:=t2 возможна, если выполняются перечисленные 6 правил и t1,t2 – не являются файлами, массивами файлов и записями, содержащими поля файлов. А так же диапазон t2 лежит внутри диапазона t1. Или существует функция преобразования типов.
t1:=t2, [где t1: integer; а t2: real ]
[integer:= round(real)]
4). Файлы.
Под файлами понимается либо именованная область внешней памяти ПВЭМ, либо логическое устройство, которое является потенциальным источником или приемником информации (адаптер интерфейса – USB…).
Любой файл имеет три характерных особенности:
1. он обладает именем (это дает возможность работать одновременно с несколькими файлами в программе);
2. он содержит компоненты одного и того же типа (типом может быть любой тип OPascal кроме файла);
3. длина файла в OPascal не регламентируется (ограничение накладывает только емкость внешнего устройства).
По способу организации файлы делятся на:
1. файлы прямого доступа;
2. файлы последовательного доступа.
При работе с файлами существует понятие указатели (это виртуальный элемент, который указывает на текущую позицию в файле (то место, с которого будет считана информация при последующем обращение к файлу)). При открытие файла, указатель устанавливается в начало файла.
У файлов прямого доступа можно установить указатель на любую запись и прочитать ее.
У файлов последовательного доступа каждая следующая запись может быть прочитана только после прочтения предыдущей записи, т. е. что бы получить запись с номером (N) надо прочитать (N-1) записей.
В OPascal существует три типа файлов:
1. текстовые;
2. типизированные;
3. не типизированные.
Типизированные файлы являются файлами прямого доступа, а не типизированные и текстовые – файлы последовательного доступа.
Доступ к файлам.
Любые файлы и логические устройства становятся доступны в модуле после процедуры открытия.
Эта процедура заключается:
1. в связывании ранее объявленной файловой переменной с именем файла;
2. в открытии файла для чтения и (или) записи.
Файловая переменная (дескриптор файла).
Объявление файловой переменной.
Var
F: TextFile; {текстовый файл}
F1: file of integer; {типизированный файл}
F2: file of string [20]; {типизированный файл}
F3: file; {не типизированный файл}
AssignFile – процедура связывания файловой переменной с именем файла:
AssignFile (<файловая переменная>, <имя файла или логическое устройство>);
Пример:
AssignFile (f, ‘c:\alpha. txt’);
AssignFile (f1, ‘PRN’);
Именем файла может являться любое выражение строкового типа, которое строится по правилам определения имени в операционной системе Windows.
Логические устройства в OPascal.
К ним относятся стандартные аппаратные средства (клавиатура, экран, принтер, коммуникационные каналы). Аппаратные средства определяются специальными именами и называются логическими устройствами:
CON – консоль (клавиатура / экран; допустима передача в двух направлениях);
PRN – принтер (допустима передача в одном направлении);
COM 1 = (AUX) – последовательный интерфейс;
COM 2 – последовательный интерфейс;
LPT 1 – параллельный интерфейс;
LPT 2 – параллельный интерфейс.
Инициализация файла.
Под инициализацией понимается указание направления передачи данных, для этого существуют специальные процедуры:
1. reset (<файловая переменная>); - открытие файла для чтения;
2. rewrite (<файловая переменная>); - открытие файла для записи (при открытии rewrite файл стирается и создается заново).
3. append (<файловая переменная>); - открытие файла для записи (при открытии append происходит добавление в файл; работает только для текстовых файлов).
Процедуры инициализации должны следовать после того, как с именем файла связана файловая переменная.
Закрытие файла.
Закрытие осуществляется с помощью процедуры CloseFile (<файловая переменная>).
Эта процедура закрывает файл, но закрывает связь файловой переменной с именем файла. При создании нового или расширении старого файла процедура CloseFile обеспечивает сохранение всех новых записей в файле и регистрирует файл в каталоге.
При нормальном завершении работы приложения всех действий, выполняемые этой процедурой, производятся автоматически для всех открытых файлов.
Процедуры и функции для работы с файлами:
Eof(<файловая переменная>); - возвращает true если достигнут конец файла;
Eoln(<файловая переменная >); - возвращает true если достигнут конец строки;
SeekEof(<файловая переменная >); - возвращает true если до конца файла остались только символы разделители (‘ ’, tab);
SeekEoln(<файловая переменная >);- возвращает true если до конца строки остались только символы разделители (‘ ’, tab);
AssignPRN(<файловая переменная >); - процедура присваивает дескриптор текстового файла принтеру;
Erase(<файловая переменная >); - процедура стирает файл (перед стиранием необходимо закрыть файл);
Flush(<файловая переменная >); - процедура очищает внутренний буфер файла (при этом все изменения сохраняются на диске);
ReName(<файловая переменная >,<новое имя>); - процедура переименовывает файл…
Процедуры чтения записей:
Read(<файловая переменная >,<список вывода>); - читает информацию из файла;
ReadLn(<файловая переменная >,<список вывода>); - читает информацию из файла;
Write(<файловая переменная >,<список ввода>); - записывает информацию в файл;
WriteLn(<файловая переменная >,<список ввода>); - записывает информацию в файл.
Ø Текстовые файлы.
Текстовые файлы связываются с файловыми переменными, принадлежащими стандартному типу TextFile, используются для хранения текстовой информации. В файлах такого типа так же могут храниться целые вещественные числа. Запись текстового файла имеет переменную длину, поэтому файлы такого типа относятся файлам последовательного доступа. При создании текстового файла, в конце каждой строки автоматически ставится специальный символ, который называется EoLn, который состоит из 2-х байтов.
В конце файла ставится специальный символ Eof.
Текстовые файлы открываются с помощью трех процедур:
Reset – для чтения;
RewRite – для записи;
Append – для добавления.
Чтение осуществляется с помощью процедуры Read и ReadLn, запись – Write и WriteLn.
Пример:
WriteLn(f,‘ABC’;12;‘x’;0,5); [ABC12x5E-1]
При переводе переменных типа String количество считываемых процедурой и помещенных в строки символов равно максимальной длине строки, если раньше не встретится признак EoLn; этот признак в строку не помещается. Если количество символов во входном потоке данных больше максимальной длинны строки, то лишние символы отбрасываются. При вводе числовых переменных процедура Read работает следующим образом: все ведущие знаки разделители и признаки конца строк пропускаются до появления первого значащего символа (и наоборот: любой из перечисленных символов, а так же признак конца файла считается концом подстроки). Выделенная таким образом подстрока рассматривается как строковое выражение числовой переменной; затем она конвертируется во внутреннее представление числа и результат присваивается переменной.
Ansistr = 256 символов.
WriteStr = 4 Гб.
‘ ’ ‘ ’ ‘ ’ 209 ‘ ’ EoLn 2 ‘ ’ 3 ‘ ’ a5 ‘ ’2,5 Eof |
Var
F: TextFile;
S: string;
S2: string [2];
a, b, c: integer;
x: real;
Begin
AssignFile (f,‘c:\FEI\alpha. txt’);
Reset(f);
ReadLn(f, s) [s=‘_abc ’]
Read(f, a); [a=209]
Read(f, b,c); [b=2 c=3]
Read(f, x); [ошибка a5 перевести нельзя]
End;
Работа с текстовыми файлами.
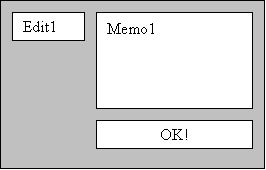
___1)._Пример Вывод текстового файла на экран:
Procedure TForm1.Button1.Click (…);
Var
F: TextFile;
S: string;
Begin
AssignFile(f,‘c:\alpha. txt’);
|
|
While not Eof(f) do begin
ReadLn(f, s);
Memo1.Lines. Add(s);
End;
End;
Если в конвертируемой строке был нарушен требуемый формат – возникнет ошибка ввода / вывода.
Процедура Write и WriteLn обеспечивает вывод информации в текстовый файл. Список вывода аналогичен процедуре Read, за исключением числовых значений, для которых существует специальный формат: элемент [:m [: n]];
m - минимальная ширина поля, в которое будет помещен элемент;
n – максимальное количество знаков после ( , ).
Процедура WriteLn аналогична процедуре Write, но в конце добавляется признак конца строки.
___2)._Пример Слияние двух текстовых файлов в третий:
 Procedure TForm1.Button1.Click (…);
Procedure TForm1.Button1.Click (…);
Var
f1, f2, f3: TextFile;
s: string;
Begin
AssignFile (f1,‘c:\Fei\alpha1.txt’);
AssignFile (f2,‘c:\Fei\alpha2.txt’);
AssignFile (f3,‘c:\Fei\alpha3.txt’);
Reset(f1);
Reset(f2);
Reset(f3);
While not Eof(f1) do begin
ReadLn(f1,s);
WriteLn(f3,s);
End;
While not Eof(f2) do begin
ReadLn(f2,s);
WriteLn(f3,s);
End;
CloseFile(f1);
CloseFile(f2);
CloseFile(f3);
ShowMessage(‘OK!’);
End;
Обработка ошибок при работе с файлами.
При обращение к файлам (т. е. к диску) могут возникать ошибки, приводящие к ненормальному завершению работы приложения. Эти ошибки необходимо предусмотреть и соответствующим образом обработать. В основном ошибки возникают при открытии файла, реже при чтении и записи из них. Что бы обрабатывать ошибки ввода / вывода (ошибки при работе с файлами) необходимо использовать соответствующую директиву компилятора (специальным образом оформленные указания компилятору внутри кода программы). Директиву заключают в { }, внутри ставится обозначение соответствующей директивы, + или -:
{<обозначение>,<+ или ->}:
отключить контроль ошибок ввода / вывода: {I-};
включить контроль ошибок ввода / вывода: {I+}.
Если делается попытка чтения несуществующего файла или логического устройства, то возникает ошибка времени выполнения (from time error). Тип ошибки можно определить с помощью использования встроенной функции – IOResult: word; (эта функция возвращает результат последней операции ввода / вывода; если операция прошла успешно, функция возвращает (0), иначе возвращает код ошибки ввода / вывода).
Для использования этой функции необходимо отключить контроль ошибок ввода / вывода.
 Procedure TForm1.Button1.Click (…);
Procedure TForm1.Button1.Click (…);
Var
F: TextFile;
S: string;
Begin
AssignFile (f, Edit1.Text);
{I-}
Reset(f);
If IOResult<>0 then begin
ShowMessage (‘неверное имя файла’);
Exit;
End;
{I+}
While not Eof(f) do begin
ReadLn(f, s);
Memo1.Lines. Add(s);
End;
End;
В Delphi существуют объекты для работы с файлами. В частности объекты TOpenDialog и TSaveDialog. Эти объекты позволяют открывать и использовать стандартные диалоговые окна открытия и сохранения файла.
Вызов диалогового окна осуществляется с помощью метода ExeCute: Boolean; (который возвращает true если окно открывалось успешно и false в противном случает).
___3)._Пример Открытие файла:
|
|

…
if OpenDialog1.Execute then begin
AssignFile (f, OpenDialog. FileName);
…
Reset(f);
End;
___4)._Пример Процедура подсчитывает количество строк и символов в текстовом файле:
Procedure TForm1.Button1.Click(…);
Var
f: TextFile;
s: string;
i, k: int64;
Begin
AssignFile(f,'alpha. txt');
Reset(f);
k:=0;
i:=0;
While not Eof(f) do begin
ReadLn(f, s);
inc(i);
k:= k + length(s);
End;
memo1.Lines. Add (‘alpha. txt содержит’ + IntToStr(k) + ‘символов’ + ‘и’+IntToStr(i) + ‘строк’);
End;
Использование объекта TStringList (набор строк и является потомком объекта TStrings, каждая строка имеет свой индекс, к ней можно обратиться с помощью свойства *.strings[i] – i – необходимая строка).
Пример:
Var
T: TStringList;
...
Procedure TForm1.Button1.Click(...);
T:=TStringList. Create(...);
T. LoadFromFile (‘c:\alpha. txt’);
Memo1.Lines. Add(t. StringList[0]);
Memo1.Lines. Add(t. StringList[1]);
...
// по окончании работы объект t надо уничтожить
t. Free;
End;
Методы объекта StringList:
*.Count – возвращает количество строк в этом объекте;
*.SaveToFile – позволяет скинуть объект в файл.
Ø Типизированные файлы.
Длинна, любого компонента типизированного файла, постоянна, что дает возможность организовать прямой доступ к каждому из них. Каждая запись файла может быть доступна путем указания ее порядкового номера. После открытия файла, указатель стоит в его начале и указывает на первый компонент с номером (0). После каждого чтения или записи указатель смещается на одну позицию, т. е. на одну запись. Перемещение в списках ввода / вывода процедур read / write должны иметь тот же тип, что и компоненты файла (работает правило приведения типов). Если переменных в списках ввода / вывода несколько, то указатель будет смещаться после каждой операции обмена данными между переменными и фалом.
Работа с типизированными файлами.
___1)._Пример Объявление типизированного файла:
Var
F: file of integer;
T: file of string [20];
A: integer;
B: byte;
C: int64;
X: string [20];
...
Procedure TForn1.Button1.Click (...);
Begin
AssignFile(f,‘c:\int. dat’);
AssignFile(f,‘c:\string. txt’);
ReWrite(f);
ReWrite(t);
Write(f, a,b);
Write(t, x,‘abcdef’);
Reset(f);
Reset(t);
Read(f, c);
Read(t, x);
Write(t,‘stuvw’);
End;
Процедура Reset применима к типизированным файлам, открывает как для записи, так и для чтения одновременно. ReWrite работает аналогично текстовым.
Процедуры для работы с файловыми переменными:
Seek(<файловая переменная>,<номер записи>); - процедура смещает указатель файла к требуемой записи.
<файловая переменная> - дескриптор файла.
<номер записи> - выражение типа int64 содержащее номер записи.
FileSize(<файловая переменная>):int64; - функция возвращает количество записей в файле.
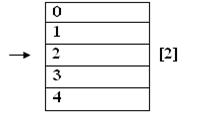
SizeOf(<экземпляр структуры>); – позволяет определить размер объекта:
Var
Z: word; [2]
...
FileSize(z);
...
FilePos(<файловая переменная>):int64; - функция возвращает порядковый номер записи, которая будет обработана следующей операцией ввода / вывода:
___2)._Пример Создание базы данных содержащих информацию о погоде (база данных состоит из одной таблицы):
Месяц | День | 0С | Скорость ветра | Направление ветра |
byte | byte | real | real | String[3] |
Type
Pogoda=recode;
m:bute;
d:bute;
t:real;
sv:real;
nv:string[3];
End;
Var
f:file of pogoda;
a, b:pogoda;
i:int64;
Procedure TForm1.Button1.Click(...);
{заполнение файла}
AssignFile(f,‘c:\pogoda. dat’);
ReWrite(f);


Procedure TForm1.Button2.Click(...);
{просмотр файла}
Reset(f);
While not Eof(f) do begin
Read(f, b);
i=i+1;
With StringGrid1 do begin
Cells[1,i]:=IntToStr(b. m);
Cells[2,i]:=IntToStr(b. d);
Cells[3,i]:=FloatToStr(b. t);
Cells[4,i]:= FloatToStr(b. sv);
Cells[5,i]:=b. nv;
End;
End;
End;
Ø Не типизированные файлы (бинарные).
Объявляются как переменные типа файл:
Var
f:file;
…
Отличаются тем, что для них не указан тип компонента. Файл воспринимается как набор байтов. Отсутствие типов данных дает ряд преимуществ:
ü Эти файлы совместимы с любыми другими;
ü Высокая скорость обмена данными между диском и памятью.
Инициализация не типизированного файла осуществляется процедурами Reset и ReWrite:
Reset(<файловая переменная>[,<длинна записи>]);
Длинна записи не типизированного файла измеряется в байтах и по умолчанию равна 128 байт.
Тип данных Word(<длинна записи>) – 0..65535 максимальная длинна записи 64 Кбайт. Delphi не накладывает ограничений на длину записи не типизированного файла, за исключением ограничения на целый тип Word.
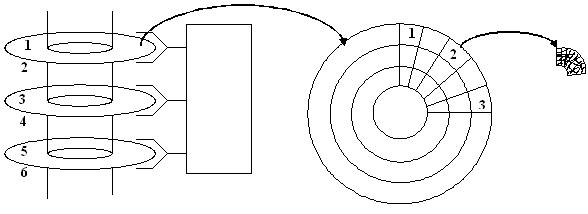
Жесткий диск состоит из нескольких дисков, которые в свою очередь состоят из секторов, состоящих из доменов. Размер физического сектора на жестком диске 512 байт. Для обеспечения максимальной скорости обмена данными длину записи не типизированного файла следует задавать кратной размеру физического сектора на диске (512 байт). Кроме того на логическом уровне каждому файлу выделяется как минимум 1 кластер. Каждый кластер занимает 2 или более смежных секторов. Как правило, на большинстве дисков 1 кластер читается или записывается за один оборот диска, по-этому, максимальную скорость обмена данными можно получить, если указать длину записи не типизированного файла равной размеру кластера в байтах.
Процедуры и функции для работы с не типизированными файлами.
Для этих файлов могут применяться все процедуры и функции, предназначенные для типизированных, за исключением Read и Write, которые заменяются высокоскоростными процедурами BlokRead и BlokWrite:
BlokRead(<файловая переменная 1>,<2>,<3>[,<4>]);
BlokWrite(<файловая переменная 1>,<2>,<3>[,<4>]);
1 – файловая переменная;
2 – буфер (т. е. имя переменной, которая будет участвовать в обмене данными с диском);
3 – количество записей, которые должны быть прочитаны или записаны за одно обращение к диску;
4 – возвращает при выходе из процедуры количество фактически обработанных записей.
Buff: array [1..1024] of byte;
BlokRead: (f, buff,2,x); [x=1]
За одно обращение к процедуре BlokRead / BlokWrite может быть передано n*(длинна записи) байт. Передача идет начиная с первого файла к переменной Buff. Программист должен заботиться о том, что бы длинна внутреннего представления переменной Buff была достаточной для размещения всех n*(длинна записи) байт. Если длинна буфера будет недостаточной или место на диске закончится то выведется: ‘ОШИБКА!’
Ø Потоки.
Stream – поток данных.
Thread – отдельно выполняющаяся программа (отдельный процесс); программный поток.
TSream – объект потока данных. Является базовым для потоков данных разного типа. В нем реализованы все необходимые свойства и методы, используемые для чтения и записи данных на различные типы носителей (память, диск, сеть …). Благодаря ему, доступ к различным типам носителей становится унифицированным (единым, одинаковым …). У объектов TSream существует несколько потомков одного уровня позволяющих работать с различными носителями информации.
Потомки TSream:
TFileStream – применяется для получения доступа к файлам.
TMemoryStream – применяется для получения доступа к памяти.
TStringStream – применяется для получения доступа к строкам, хранящимся в динамической памяти.
TWinSocketStream – применяется для получения доступа к данным из сети.
TOleStream – применяется для получения доступа к COM-интерфейсу (component object model).
Для всех этих объектов действуют основные методы и свойства родительского объекта TSream.
Основные свойства объекта TSream:
Position – указывает на текущую позицию курсора в потоке (начиная с нее будет происходить чтение файла).
Size – размер данных в потоке.
Методы объекта TSream:
CopyFrom – метод предназначен для копирования из другого потока:
1. указатель на поток, из которого надо копировать;
2. размер данных (байт) подлежащих копированию.
Read – позволяет прочитать данные из потока, начиная с текущей позиции курсора:
1. буфер, в который будет происходить чтение;
2. количество читаемых байтов.
Write – позволяет записывать данные в буфер (по параметрам аналогичен read);
Seek – позволяет переместиться в новую позицию в потоке:
1. число, указывающее на сколько байт нужно передвинуться;
2. от куда надо двигаться (не обязательные параметр). Может принимать 3-и значения:
· soFromBegining – от начала;
· soFromCurrent – с текущей позиции (по умолчанию);
· soFromEnd – с конца.
SetSize – устанавливает размер потока (один параметр – число указывающее новый размер потока (байт)).
Пример Работа с объектом TFileStream – чтение информации:
…
Var
f: TFileStream;
out: array [1..1024] of byte;
Begin
if OpenDialog1.Exwcute then
begin
f:=TFileStream. Create (OpenDialog1.FoleName, fmOpenRead);
f. Read(buf,1024);
f. Free;
end;
end;
fmOpenRead – режим работы с файлом.
Режимы работы с файлом для объектов TFileStream:
fmCreate – создает новый файл (если файл уже существует, то он открывает его в режиме записи);
fmOpenRead – открывает файл только для чтения;
fmOpenWrite – открывает файл только для записи (вся предыдущая информация стирается);
fmOpenReadWrite – добавляет информация в файл не удаляя предыдущую;
fmShareExclusive – при работе с файлами в таком режиме не одно приложение, кроме вашего не сможет его открыть;
fmDenyWrite – при работе с файлами в таком режиме другие приложения не могут писать в файл, но могут его читать;
fmDenyRead – при работе с файлами в таком режиме другие приложения могут только писать, но не открывать приложения.
III. Строки.
Строки используются для обработки текста:
Var
Имя: string;
Этот тип похож на одномерный массив символов, но в отличие от него количество элементов в строке может меняться в ходе выполнения программы.
Максимальное количество символов в строке 255.
Пример:
s: string; [0-255]
s1: string [10]; [0-10]
В OPascal строка выглядит как цепочка символов, к каждому символу можно обратиться как к элементу одномерного массива указав его индекс:
s: “это_строка”;
s1:=s6; [т]
Строка хранится в памяти компьютера следующим образом – самый первый элемент строки имеет индекс 0 и содержит значение текущей длинны строки:
10 ( это_строка ) - для человека
A (ASCII код символов) - для компьютера
Над длинной строки можно производить необходимые действия оперируя с нулевым байтом строки.
Над строками допустимы следующие операции:
1). Сравнение (результат – истина, если строки идентичны).
2). Сложение.
S1:= “ab”;
S2:= “12”
S3:=s1+s2; [“ab12”]
При записи строки допустимо использовать ASCII коды символов:
S:= “abs”;
S:= #65#66#67;
S:= “a”#66 “c”
Если, при сцепление строк, длинна строки более 255 символов, то лишние символы отсекаются.
Правила сравнения строк:
<,> - допустимо использование при работе со строками. Строки сравниваются поэлементно в соответствие с их ASCII кодами. Если коды соответствующих символов строк отличаются от операций < или > выдают истина или ложь.
s1:= “abcde”; [65]
s2:= “abcae”; [65]
s1>S2
s1:= “abc”; [65 66 67]

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
