

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ
РОССИЙСКОЙ ФЕДЕРАЦИИ
Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования
«Юго-Западный государственный университет»
Кафедра высшей математики
ИНСТРУКЦИЯ
ПО ИСПОЛЬЗОВАНИЮ ПАКЕТА
STATISTICA 6.0
(УЧЕБНОЕ ПОСОБИЕ)
КУРСК 2013
УДК 004.4ББК 32.973.26-018.11Д75 | Печатается по решению Ученого Совета Юго-Западного университетаот ______________________ |
Резензенты:
к. э.н. доц.
к. т.н. доц.
ИНСТРУКЦИЯ ПО ИСПОЛЬЗОВАНИЮ ПАКЕТА STATISTICA 6.0:
учебное пособие. – Курск: Юго-Западный государственный университет, 20с.
В учебном пособии проведено краткое описание технологии работы с модулями программы, необходимое для первичного знакомства с возможностями пакета Statistica 6.0.
Рассмотрены некоторые процедуры управления данными, графические возможности программы, «разведочный» анализ данных, первичные понятия одномерных и многомерных статистических методов, формирование отчетов.
Автор – - кандидат технический наук, доцент кафедры высшей математики ЮЗГУ.
Учебное пособие предназначено для студентов бакалавриата экономических специальностей, изучающих дисциплину «Теория вероятностей и математическая статистика», «Анализ данных», «Эконометрика».
© , 2013© ЮЗГУ, 2013 |
СОДЕРЖАНИЕ
1. | Случайные величины………………………………………... | 4 | ||
1.1. | Законы распределения ………………………………… | 4 | ||
1.2. | Числовые характеристики…………………………… | 6 | ||
2. | Подготовка пакета к работе………………………………… | 12 | ||
3. | Расчет основных характеристик…………………………… | 15 | ||
4. | Построение гистограмм……………………………………… | 22 | ||
5. | Диаграммы «Коробка-усы»………………………………… | 24 | ||
6. | Проверка гипотезы о законе распределения…………… | 28 | ||
7. | Корреляционный анализ…………………………………… | 32 | ||
8. | Регрессионный анализ……………………………………… | 42 | ||
8.1. | Уравнение регрессии для одной переменной……… | 42 | ||
8.1.1. | Линейная регрессия (без проверки гипотезы на адекватность)………………………………… | 42 | ||
8.1.2. | Нелинейная регрессия (без проверки гипотезы на адекватность)………………………………… | 47 | ||
8.1.3. | Линейная регрессия (с проверкой гипотезы на адекватность)……………………………………. | 48 | ||
8.2. | Множественный регрессионный анализ (уравнение регрессии от нескольких переменных)…...................... | 52 | ||
8.2.1. | Линейная регрессия………………………… | 52 | ||
8.2.2. | Нелинейная регрессия………………………. | 57 | ||
9. | Редактирование рисунков…………………………………... | 67 | ||
ЛИТЕРАТУРА……………………………………………… | 87 | |||
1.
2. СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
1.1. ЗАКОНЫ РАСПРЕДЕЛЕНИЯ
Пусть Х случайная величина. Функцию
![]()
называют функцией распределения или интегральной функцией распределения.
Основные свойства ![]() .
.
Свойство 1.
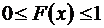 .
.
Свойство 2.
.
Свойство 3.
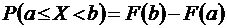 .
.
Свойство 4.
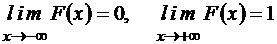 .
.
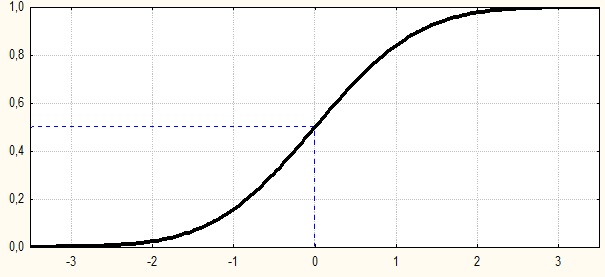
Рис.1.1. Пример графика интегральной функции распределения
Функцию
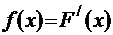
называют плотностью распределения вероятностей или дифференциальной функцией распределения.
Основные свойства ![]() .
.
Свойство 1.
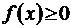 .
.
Свойство 2.
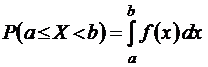 .
.
Свойство 3.
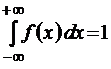 .
.
Свойство 4.
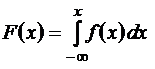 .
.
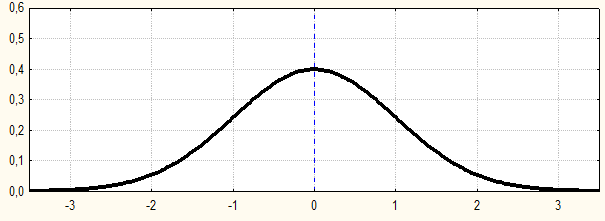
Рис.1.2. Пример графика дифференциальной функции распределения
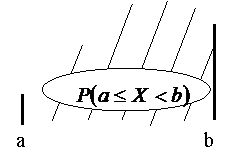
Рис.1.3. Иллюстрация свойства 2
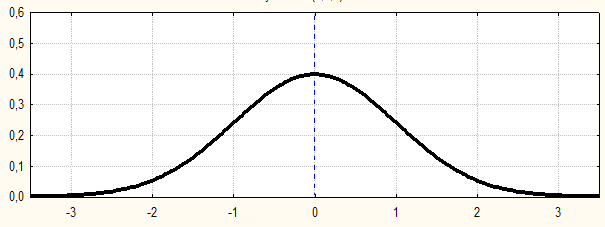
Рис.1.4. Иллюстрация свойства 4. Связь между дифференциальной и интегральной функцией распределения
1.2. ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ
Математическое ожидание
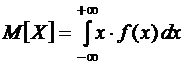 .
.
Дисперсия
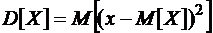
Или
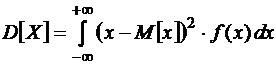 .
.
Среднеквадратическое отклонение
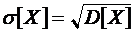 .
.
Мода
Мода случайной величины ![]() - это наиболее вероятное её значение.
- это наиболее вероятное её значение.

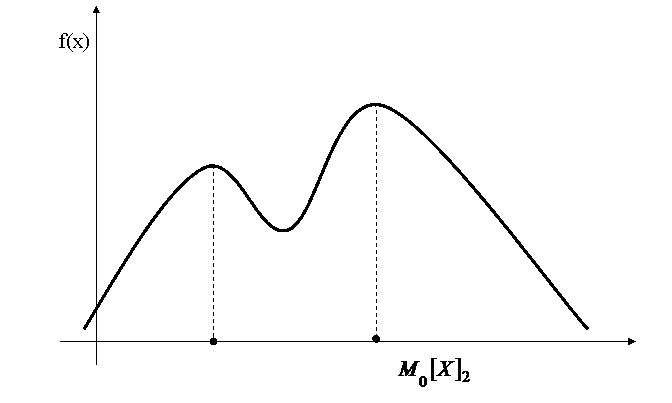

Рис.1.5. Двухмодальное распределение
Медиана
Медианой случайной величины Х ![]() называется такое ее значение, которое удовлетворяет условию
называется такое ее значение, которое удовлетворяет условию
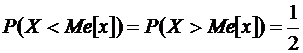 .
.
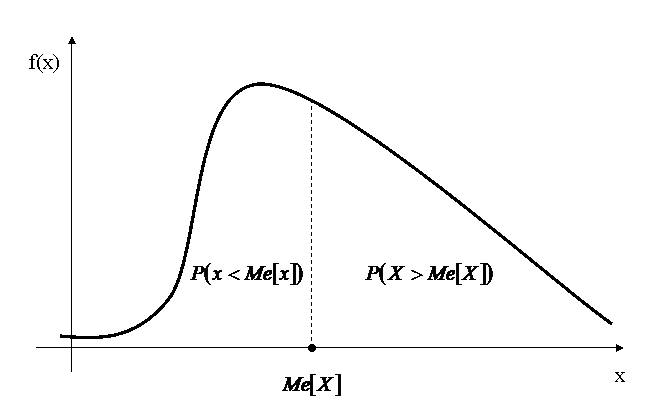

Рис.1.6. Площади до прямой ![]() и после ее равны между
и после ее равны между
собою и равны ![]()
Прямая 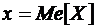 делит фигуру на две равновеликие.
делит фигуру на две равновеликие.
Квантиль
Квантилем уровня q называется такое значение ![]() случайной величины Х, при котором
случайной величины Х, при котором
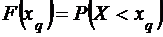 .
.
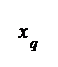
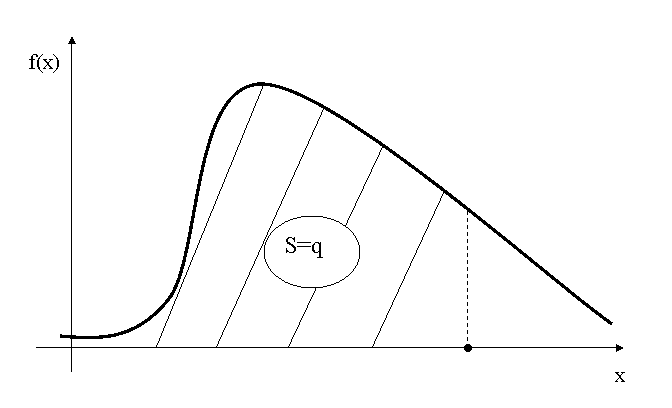
Рис.1.7. Площадь до прямой ![]() равна
равна ![]()
Замечание. ![]() . Квантили
. Квантили ![]() и
и ![]() называют соответственно верхним и нижним квартилем.
называют соответственно верхним и нижним квартилем.
Разность
![]() -
- ![]()
называют размахом квартиля.
Начальные и центральные моменты
Начальным моментом ![]() - го порядка случайной величины Х называется
- го порядка случайной величины Х называется
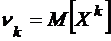 .
.
Центральным моментом ![]() - го порядка случайной величины Х называется
- го порядка случайной величины Х называется
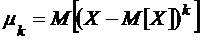 .
.
Коэффициент асимметрии
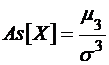 .
.
Асимметрия характеризует скошенность графика функции плотности распределения относительно некоторого симметричного графика, имеющего асимметрию равную нулю.
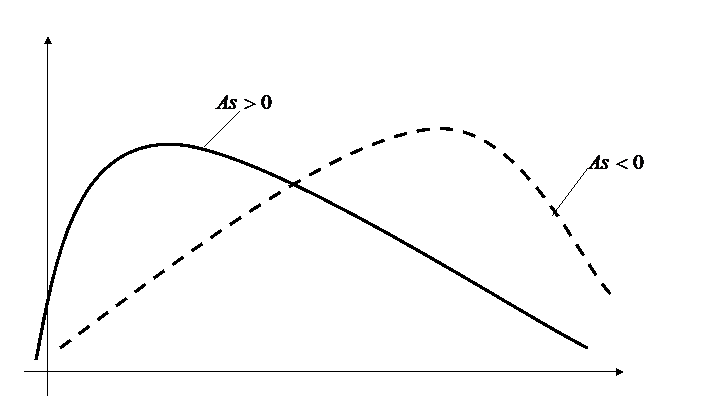
 Рис.1.8. Асимметрия: положительная и отрицательная
Рис.1.8. Асимметрия: положительная и отрицательная
Эксцесс
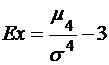 .
.
Эксцесс служит для характеристики крутости (островершинности или плосковершинности) графика функции плотности распределения.
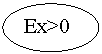
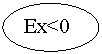
![]()
![]()
![]()
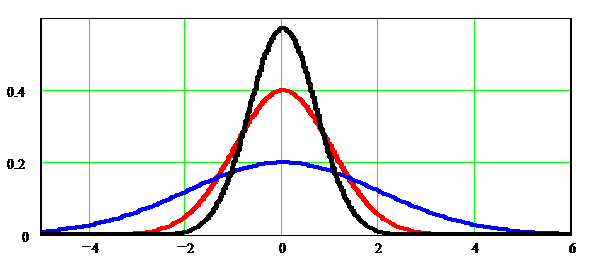
Рис.1.9. Кривые распределения с различным эксцессом
(положительным и отрицательным)
Основы использования пакета «Statistica 6.0»
в прикладном статистическом анализе
2. Подготовка пакета к работе
На рабочем столе найти пусковой файл  .
.
После двойного нажатия на данную этикетку, загрузится математическая оболочка «Statistica 6.0». На экране появится окно, фрагмент которого представлен на рис.1


Рис.1. Общий вид верхней части экрана после запуска «Snatistica 6.0»
Верхние строки представляют собой панель инструментов.
Щелкнув по кнопке, указанной стрелкой, появится диалоговое окно рис.2. Здесь «Число переменных» обозначает количество столбцов (количество исследуемых СВ), а «Число регистров»- число строк (объем выборки). По умолчанию число столбцов и число строк равно 10. Указав необходимое число столбцов и число строк, щелкните по кнопке «ОК». В результате появится таблица, которую необходимо заполнить своими экспериментальными данными (см. рис.3).
Можно для удобства, сформировать свою шапку таблицы. Для этого в самой верхней строке таблицы введите ее название (например, Исходные данные по математике для второго курса спец. ЭК, МД, ТЭ, СЛ). Определите название каждой СВ. Для этого активизируйте, необходимый столбец таблицы (щелкнув по нему). В результате появится диалоговое окно, представленное на рис.4.
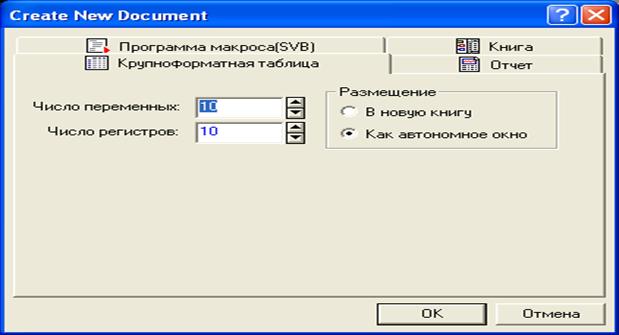
Рис.2. Диалоговое окно для формирования необходимого размера обрабатываемой таблицы
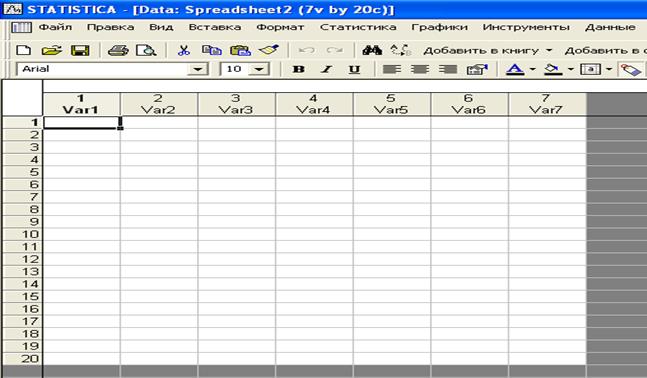
Рис.3. Таблица для заполнения экспериментальными данными
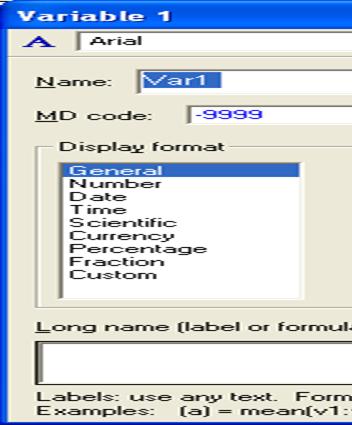
Рис.4. Диалоговое окно для формирования шапки таблицы
В окне Name: введите название столбца. В нашем случае СВ1- Входной уровень, СВ2 – Мод.17, СВ3- Мод.17, СВ4 – Мод.19, СВ5 – Мод.20, СВ6 – Рейтинг семестровый, СВ7 – экзаменационная оценка за третий семестр. Окончательно таблица, готовая для обработки, примет вид, представленный на рис.5.
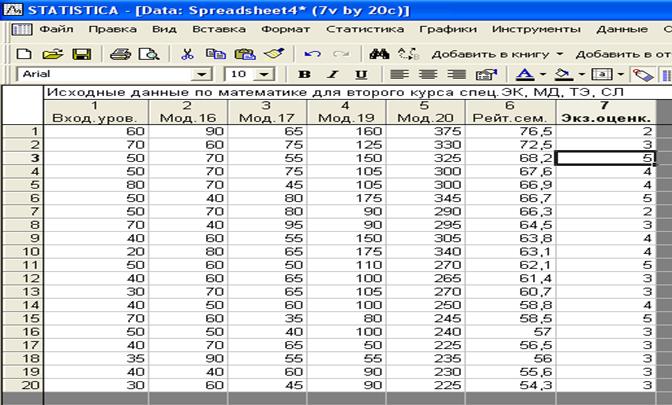
Рис.5. Оформленная и заполненная таблица
3. Расчет основных статистик
Для подсчета основных числовых характеристик щелкните по кнопке «Статистика». На рис.6 она указана стрелкой.

Рис.6. Диалоговое окно перед началом статистической обработки
В результате появится диалоговое окно, представленное на рис.7.

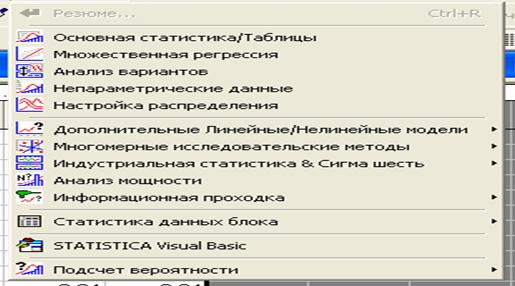
Рис.7. Окно выбора разделов статистической обработки
Щелкнем по кнопке, указанной стрелкой. Появится диалоговое окно, представленное на рис.8.



Рис.8. Окно для выбора методов обработки исходной таблицы
Выберем курсором нужный раздел обработки. В нашем случае раздел указан стрелкой «Descriptive statistics» - описательная статистика и щелкнем по кнопке «ОК». В результате появится окно, представленное на рис.9.
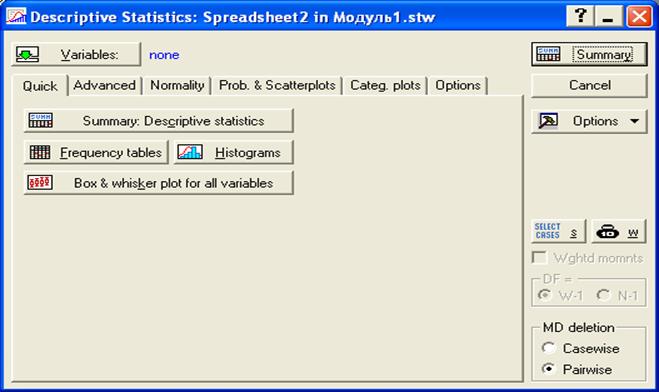
Рис.9. Диалоговое окно для выбора режимов обработки
Здесь кнопка «Variables:» - переменные, предназначена для выбора столбцов из основной таблицы, для которых будет производиться обработка. При щелчке по этой кнопке появится окно, представленное на рис.10.


Рис.10. Диалоговое окно для «селекции» переменных
Можно выделить либо одну какую-то переменную, активизировав её щелчком курсора, либо несколько переменных. При этом для выбора переменных необходимо удерживать клавишу «Ctrl» на клавиатуре. Если обработку необходимо проводить для всех переменных, можно щелкнуть по кнопке «Select All». После выбора переменных необходимо нажать на кнопку «ОК».
Затем вновь появиться диалоговое окно рис.9. Щелкнем по кнопке «Advanced» - расширенный. Появится диалоговое окно, представленное на рис.11.
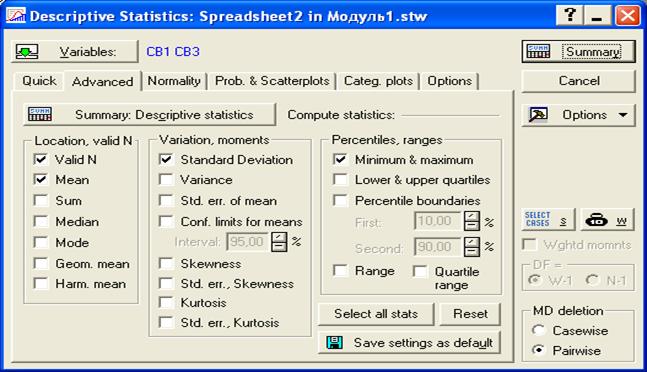
Рис. 11. Диалоговое окно для выбора необходимых числовых характеристик
Здесь
в первой левой колонке представлены:
Valid N - объем выборки;
Ниже приведены точечные оценки.
Mean – математическое ожидание;
Sum - сумма вариант;
Median – медиана;
Mode – мода;
Geom. mean – среднее геометрическое;
Harm. Mean – среднее гармоническое;
во второй колонке представлены:
Standard Deviation - среднеквадратичное отклонение;
Variance - дисперсия;
Std. err. mean - стандартная ошибка математического ожидания;
Conf. limits for means – концы доверительного интервала для математического ожидания;
Skewness - асимметрия;
Std. err. Skewness - стандартная ошибка асимметрии;
Kurtosis - эксцесс;
Std. err. Kurtosis - стандартная ошибка эксцесса;
во третьей колонке представлены:
Minimum & maximum – максимальная и минимальная варианты;
Lower& upper quartiles - нижний и верхний квартили;
Percentile boundaries - границы процентилей;
Range - размах варианты;
Quartile range - размах квартиля.
Отметив галочками необходимые числовые характеристики, щелкнем по кнопке «Summary» - вычислить.
Например, в нашем случае были выбраны характеристики, представленные на рис.12.
После того, как будет нажата кнопка «Summary», произойдет расчет отмеченных характеристики и результаты появятся в окне, представленном на рис.13 и 14. Если все результаты не помещаются в окне, используются полосы прокрутки, как вертикальные, так и горизонтальные. На рис.13. стрелкой указана вертикальная полоса прокрутки.
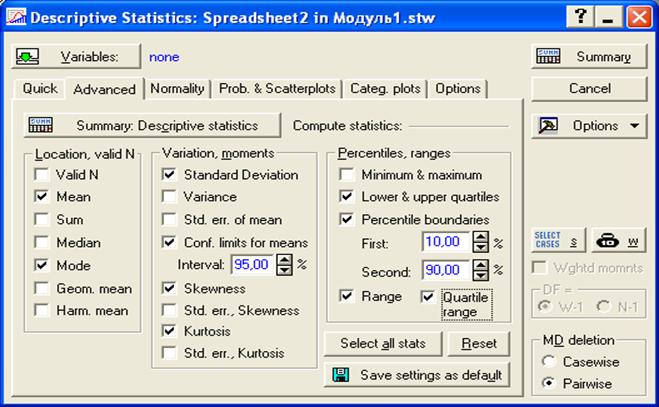
Рис.12. Галочками отмечены числовые характеристики, которые будут вычисляться
![]()
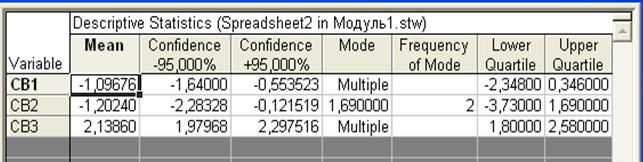
Рис.13. Результаты статистической обработки; левая половина таблицы результатов
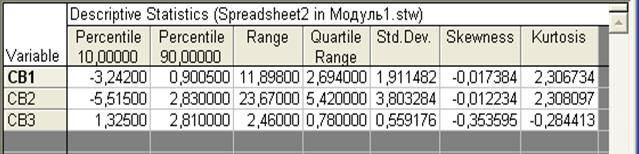
Рис.14.Результаты статистической обработки; правая половина таблицы результатов
4. Построение гистограмм
Путь для построения гистограмм с различными модификациями следующий (в фигурных скобках показаны возможные модификации). Указана последовательность нажатия кнопок.
Графики / гистограмма / переменные - ОК /  /
/  / Дополнительно /
/ Дополнительно /  /тип показа
/тип показа 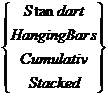 /
/ 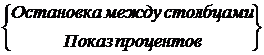 / интервалы / Y ось
/ интервалы / Y ось  / ОК
/ ОК
Одно из диалоговых окон представлено на рис.15.
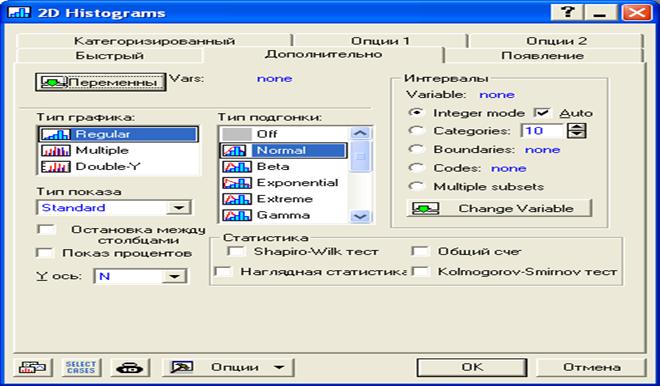
Рис.15. Диалоговое окно для выбора переменных, типа графика, типа подгонки, интервалов и способа показа гистограмм
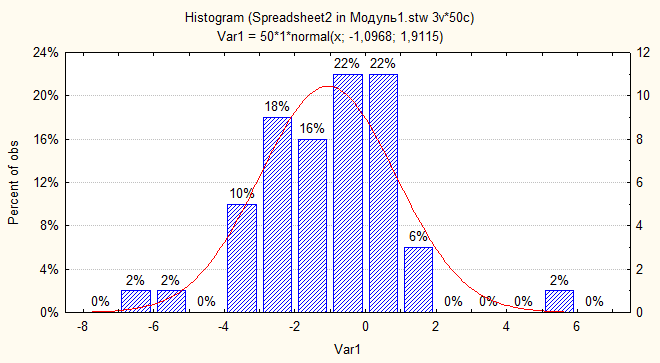
Рис.16. Гистограмма стандартная, с остановкой между столбцами, с указанием процентов, по оси Y проценты и число
На рис.17 для той же СВ построена кумулятивная гистограмма (в окне тип показа выбрано: Cumulative).
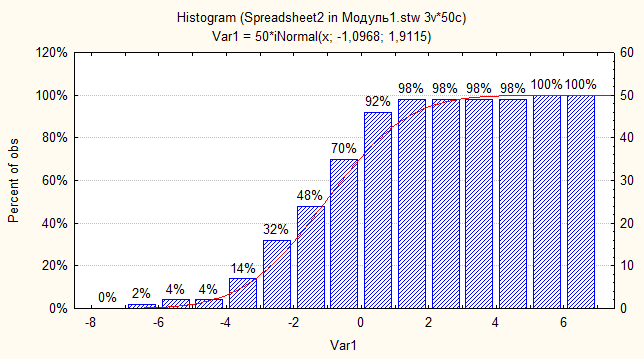
Рис.17. Гистограмма кумулятивная
На рис.18 представлены «Висячая гистограмма» (в окне тип показа выбрано: Hanging Bars).
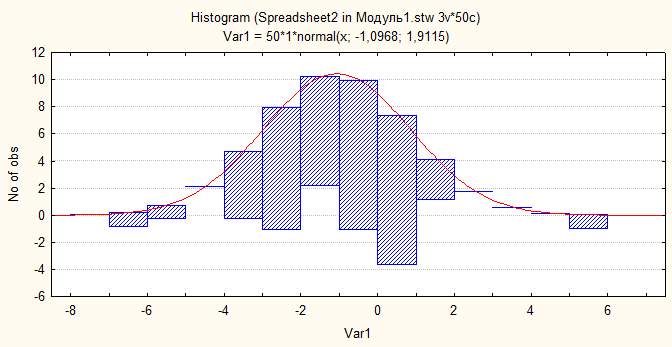
Рис.18. Висячая гистограмма
5. Диаграммы «Коробка – усы»
Статистика / основная статистика / t-test / Ok
В результате появиться диалоговое окно, представленное на рис.19.
Рис.19. Диалоговое окно для построения диаграмм «коробка-усы»
Как обычно, нажав на кнопку «Variables:», выбирают необходимые переменные, для которых необходимо построить диаграмму «коробка-усы». Затем щелкнув по кнопке «Box whisker plot», вызывают диалоговое окно, представленное на рис. 20.
Рис.20. Диалоговое окно для выбора форм диаграмм
Здесь
Median/Quar./Range - внутренний квадратик соответствует Me[X], сторона прямоугольника (коробки) равна интервалу, куда попадают 50% значений СВ. Внешний отрезок соответствует размаху значений СВ, т. е. ![]() .
.
Mean/SE/SD - внутренний квадратик соответствует M[X], сторона прямоугольника (коробки) равна стандартной ошибке для математического ожидания. Внешний отрезок соответствует значению среднего квадратического отклонения.
Mean/SD/1.96*SD - внутренний квадратик соответствует M[X], сторона прямоугольника (коробки) равна среднему квадратическому отклонению. Внешний отрезок соответствует значению среднего квадратического отклонения, умноженному на 1.96.
Mean/SE/1.96*SE - внутренний квадратик соответствует M[X], сторона прямоугольника (коробки) равна стандартной ошибке для математического ожидания. Внешний отрезок соответствует значению стандартной ошибке для математического ожидания, умноженному на 1.96.
На рис.21. представлена диаграмма «коробка-усы» для результатов
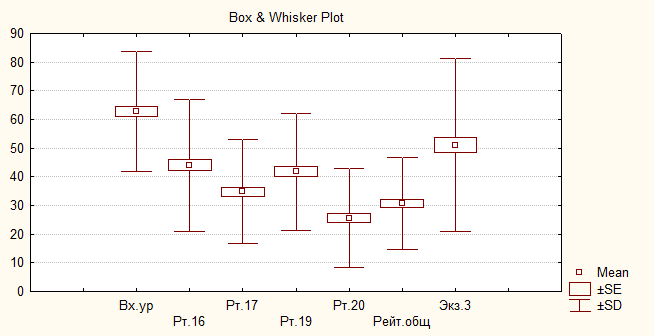
Рис.21. Диаграммы результатов оценки уровня подготовленности второго курса в третьем семестре 2005/2006 учебн6ого года; тип Mean/SE/SD
второго курса: входной уровень, результаты защиты четырех модулей, рейтинг за семестр и результаты экзамена за третий семестр.
На рис.22 представлены диаграммы для тех же СВ типа Median/Quar./Range
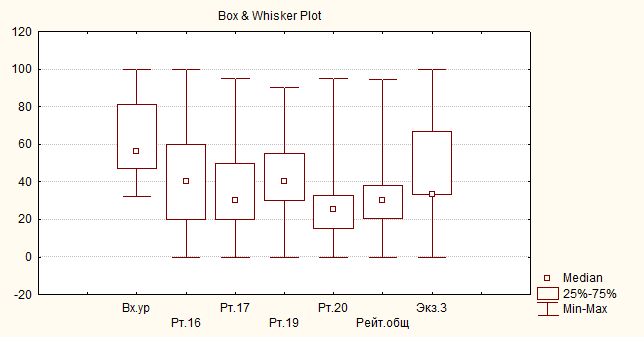
Рис.22. Диаграммы результатов оценки уровня подготовленности второго курса в третьем семестре 2005/2006 учебн6ого года; тип Median/Quar./Range
Замечание. Тип диаграммы указывается в левом нижнем углу рисунка.
6. Проверка гипотезы о законе распределения
Критерий Пирсона
Путь: Статистика / настройка распределения
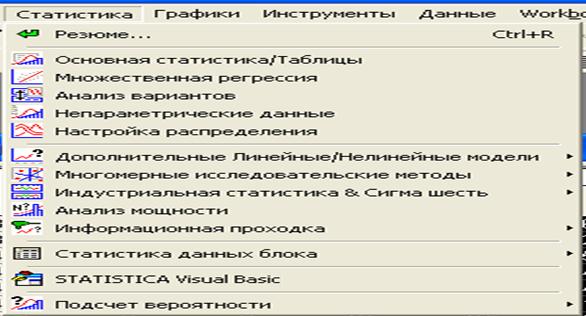
Рис.23. Диалоговое окно для выбора режима проверки гипотезы о законе распределения
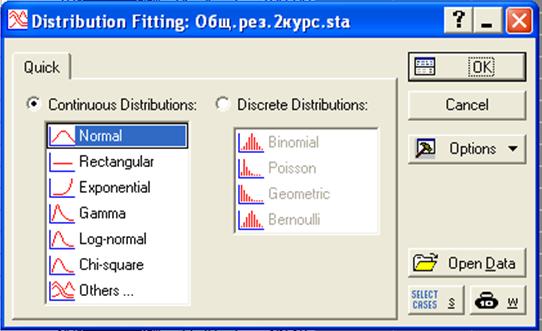
Рис.24. Диалоговое окно для выбора вида закона распределения
Выбрав закон распределения, нажмите на кнопку OK. Появится окно, представленное на рис.25, предназначенное для выбора случайной величины (Variable).
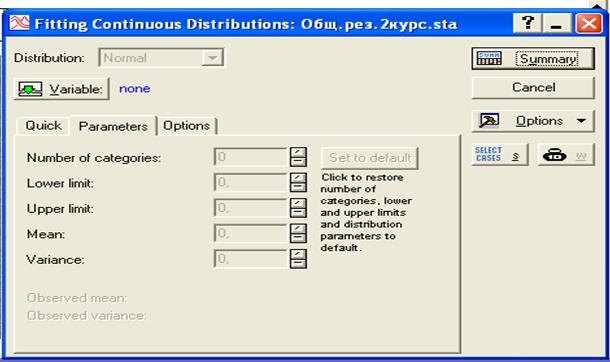
Рис.25. Диалоговое окно для выбора случайной величины
Нажав на кнопку Variable, вызовем диалоговое окно, представленное на рис. 26.
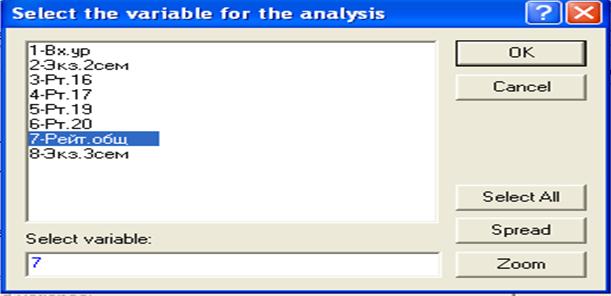
Рис.26. Диалоговое окно для выбора случайной величины: в нашем случае выбрана СВ «Рейтинг общ.»
Для подтверждения необходимо нажать на кнопку «ОК». В результате появится диалоговое окно (в режиме Parameters), представленное на рис.27.
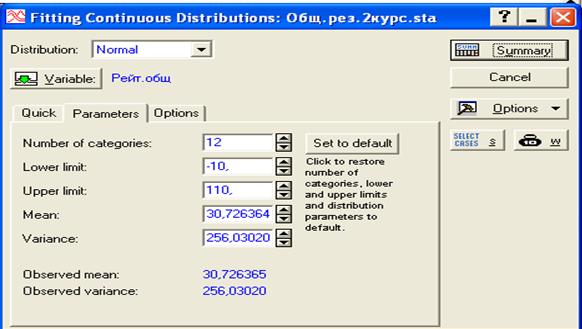
Рис.27. Диалоговое окно для установления диапазона изменения СВ и числа интервалов разбиения
Number of categories – число интервалов разбиения диапазона изменения СВ,
Lower limit - нижний предел; Upper limit - верхний предел изменения.
Установив необходимые значения параметров (можно согласится с предлагаемыми), нажмите на кнопку «Summary». Появятся результаты обработки, представленные на рис.28.
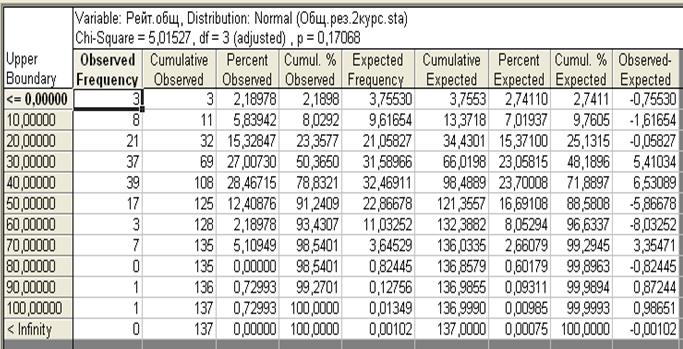
Рис.27. Диалоговое окно для установления диапазона изменения СВ и числа интервалов разбиения
Здесь в верхней шапке таблицы указывается имя переменной (СВ), расчетное значение распределения Пирсона (![]() ), число степеней свободы и значение уровня значимости (
), число степеней свободы и значение уровня значимости (![]() = 0,17068), при котором расчетное значение распределения Пирсона меньше квантиля распределения Пирсона (табличного значения распределения Пирсона). В этом случае с вероятностью
= 0,17068), при котором расчетное значение распределения Пирсона меньше квантиля распределения Пирсона (табличного значения распределения Пирсона). В этом случае с вероятностью ![]() (в нашем случае
(в нашем случае ![]() ) можно принять гипотезу о данном законе распределения.
) можно принять гипотезу о данном законе распределения.
df=3 (adjusted) – число степеней свободы с учетом объединения интервалов, содержащих частоту менее 5.
Observed Frequency – наблюдаемая частота (эмпирические частоты),
Cumulative observed - накопленная (эмпирические) частота,
Percent observed – наблюдаемый процент (эмпирических частот),
Cumulative observed % - накопленная (эмпирических) частота в %,
Expected frequency – ожидаемая частота (теоретические частоты),
Cumulative observed - накопленная (теоретическая) частота,
Percent Expected – процент ожидаемый (теоретическая частота в %),
Cumulative % Expected - накопленная (теоретическая ) частота в %,
Observed – Expected – разность между эмпирической и теоретической частотами.
7. Корреляционный анализ
Путь: Статистика / основная статистика / Correlations matrices / ok
В результате появиться диалоговое окно вида
Рис.28. Окно для выбора режимов корреляционного анализа
Нажмем на клавишу One variable list (список переменных), Появится окно вида
Рис.29. Окно для выбора переменных (СВ), для которых будет определяться корреляционная матрица
Выбрав переменные, необходимо нажать кнопку ОК . В результате появиться окно, представленное на рис.30.
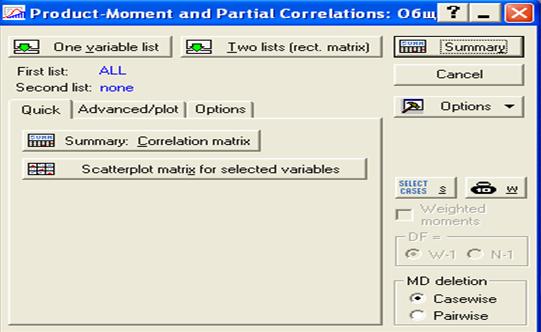
Рис.30. Окно для выбора вариантов обработки
Вариант 1. Нажамите на клавишу Two list (rect. matrix), появится окно.
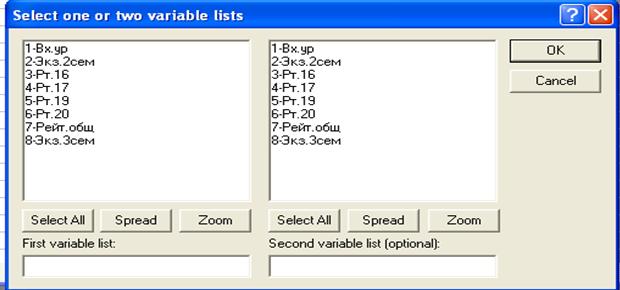
При этом режиме можно из всего списка переменных, выбрать лишь те, для которых необходимо найти коэффициенты корреляции.
Вариант 2. Нажмите на клавишу Summary: Correlation matrix или Summary (рис.30), появится окно.
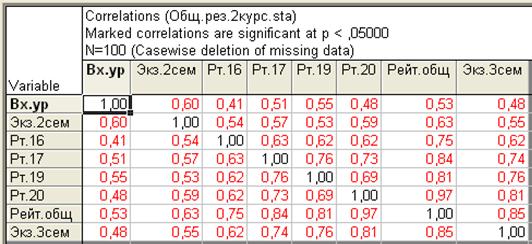

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
