
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Избыточное кодирование информации.
Избыточное кодирование информации можно разделить на два метода – это блочное кодирование и сверточное.
При блочном кодировании информация делится на блоки определенной длины, и каждый блок кодируется отдельно. Простейшим примером блочного кодирования является дополнение до четности. В этом случае каждый блок делится на группы,
 |
которые дополняются одним битом со значением единица или ноль, в зависимости от того четное или нечетное количество единиц в исходной группе.
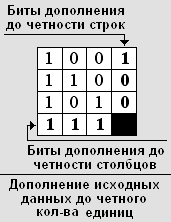
Рассмотрим, как можно использовать дополнение до четности для исправления ошибки на примере кодирования массива из 9 бит:
Запишем этот массив в виде матрицы три на три и дополним каждую строку и столбец матрицы до четного количества единиц.
Таким образом, исходный массив после кодирования примет вид: 111.
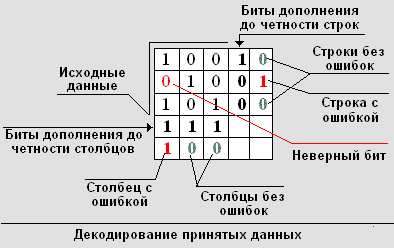 |
Допустим, что после передачи данных произошла ошибка в 4-ом бите сообщения, и полученный массив принял вид: 111.
Произведем его декодирование, для чего запишем в виде матрицы 4 на 4, где матрица 3 на 3 - исходные данные, которые надо было передать, остальные элементы матрицы – коды дополнения до четности. Проведя суммирование бит в строках и столбцах, видим, что в первом столбце и второй строке количество единиц - нечетное, а, следовательно, в них содержатся ошибки.
Так как дополнение до четности позволяет обнаружить только одну ошибку, то примем за аксиому, что в блоке только одна ошибка. Теперь становится очевидным, что ошибочный бит может быть только на пересечении строки и столбца с нечетным количеством единиц. Инвертировав его на противоположный, мы восстановим
 |
испорченные данные.
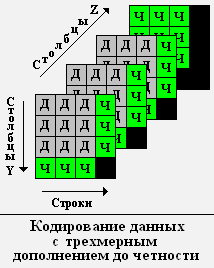
Данный метод позволяет исправлять только однократные ошибки, поэтому использовать его для передачи большого массива информации нецелесообразно. Однако, его можно легко усовершенствовать, разбив исходный массив на блоки данных с N слоями, M строками и К столбцами и проведя дополнение до четности всех строк, столбцов и элементов с одинаковыми индексами строк и столбцов. Для простоты изложения столбцы назовем столбцами Y, а элементы с одинаковыми индексами строк и столбцов назовем столбцами Z.
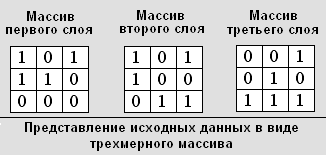
Рассмотрим этот алгоритм на примере кодирования следующего массива данных: 111.
1) Формируем 3 массива из 9 элементов. В первый массив записываем первые девять бит исходных данных, во второй массив - элементы с 10 по 18, в третий массив – оставшиеся данные.
2) Дополняем все строки, столбцы Y и Z до четности. (В таблицах биты дополнения до четности выделены жирным шрифтом).
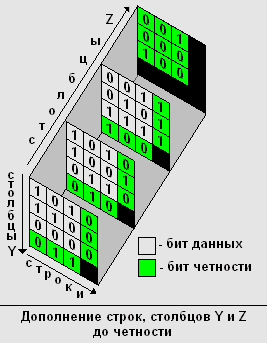
3) Закодированная исходная последовательность приняла вид:
4) Предположим, что при передаче данных ошибки произошли во втором, шестом и двенадцатом битах информации, и полученные данные имеют вид:
5) Проведем декодирование принятого блока и проверим на четность все строки, столбцы Y и Z.
Среди этих бит могут быть, как биты с ошибками, так и верные биты, которые необходимо исключить.
В каждом наборе из трех бит (строке, столбце Y или столбце Z), проверяемом на четность, может быть зафиксирована только одна ошибка (две ошибки не приведут к изменению четности на нечетность). Основываясь на этом свойстве, исключаем из бит с возможными ошибками биты, лежащие на одной строке или столбце Y, или столбце H.
На одной строке лежат биты: [1,2,1], [1,3,1].
На одном столбце Y лежат биты: [2,3,1], [1,3,1].
На одном столбце Z лежат биты: [1,3,2] , [1,3,1].
Таким образом, если убрать бит [1,3,1], исключается ситуация, когда на одной строке, столбце Y или Z лежат биты с возможными ошибками. Следовательно, бит [1,3,1] – верен, а остальные биты с возможными ошибками действительно их содержат. Инвертируя неверные биты, мы исправляем ошибки и получаем корректный исходный массив.
Повысить эффективность работы кодирования можно, например, заменив дополнение до четности на контрольное суммирование, позволяющее фиксировать большее количество ошибок.
Блочное кодирование обладает высокой надежностью, простотой реализацией, и получило широкое распространение. Существует большое разнообразие блочных кодов, обладающих различными возможностями по обнаружению и исправлению ошибок, среди которых наиболее известны коды Хемминга.
Сверточные коды работают со всем массивом данных, не деля его на части. В простейшем случае, в исходные данные добавляются проверочные символы, представляющие собой сумму двух символов исходных данных.
Рассмотрим для примера работу сверточного кода, в котором проверочные символы вставляются между всеми символами исходного кода и представляют собой сумму двух смежных символов исходного кода.
Закодируем с помощью этого метода следующую бинарную последовательность данных:
Для удобства изложения, информационные биты будем обозначать символом ‘И’ с индексом, соответствующим номеру информационного бита в исходной последовательности (И5 – пятый информационный бит). Проверочные биты будем обозначать символом ‘П’ с индексом соответствующим номеру проверочного бита (П3 – третий проверочный бит).
1) Для получения первого проверочного символа сложим первый и второй информационные символы исходной последовательности (П1=И1+И2=1+0=1) и запишем результат между ними: 110. Красным цветом выделен проверочный символ.
2) Для получения второго проверочного символа повторим описанную выше операцию со вторым и третьим битами исходной последовательности (П2=И2+И3=0+0=0), и запишем результат между ними. Аналогичные действия проводим со всеми остальными информационными битами последовательности. В результате получим следующую закодированную последовательность:
В данной последовательности информационные символы выделены черным цветом, а проверочные – красным.
При приеме данных происходит их декодирование, т. е. суммируются соседние биты исходных данных и сравниваются с их проверочным битом. Если для двух соседних проверочных битов была зафиксирована ошибка, то общий информационный бит для этих двух проверочных битов - неверен. Для исправления ошибки необходимо заменить его на противоположный.
Если для одного проверочного символа была зафиксирована ошибка, а два соседних проверочных символа ошибку не показали, это означает, что сбой произошел в проверочном символе, а информационные биты корректны.
Предположим, что при передаче данных сбой произошел в пятом и десятом битах, и принятая последовательность имеет вид:
Рассмотрим алгоритм декодирования и корректировки принятых данных:
1. Суммируем первый и второй информационные биты (первый и третий биты принятых данных): И1+И2= 1+0 = 1 = П1. Полученный результат совпадает с проверочным битом (второй бит принятых данных).
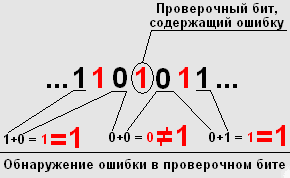
2. Проводим аналогичную операцию со вторым и третьим информационными битами (третий и пятый биты принятых данных): И2+И3 = 0+1 = 1 ![]() П2. Полученный результат не совпадает с проверочным битом (четвертый бит принятых данных) этой пары информационных бит. Следовательно, либо один из информационных битов - неверен, либо неверен проверочный бит. Для уточнения ошибки, необходимо проверить следующую пару информационных битов, что и будет сделано в следующем пункте алгоритма.
П2. Полученный результат не совпадает с проверочным битом (четвертый бит принятых данных) этой пары информационных бит. Следовательно, либо один из информационных битов - неверен, либо неверен проверочный бит. Для уточнения ошибки, необходимо проверить следующую пару информационных битов, что и будет сделано в следующем пункте алгоритма.
3. Суммируем третий и четвертый информационные биты (пятый и седьмой биты принятых данных): И3+И4 = 1+1 = 0 ![]() П3. Полученный результат опять не совпал с проверочным битом. Так как произошло несовпадение с двумя соседними проверочными битами, то неверен информационный бит, общий для двух проверяемых пар информационных бит, и его следует инвертировать для устранения ошибки. В данном случае неисправен третий информационный бит (И3).
П3. Полученный результат опять не совпал с проверочным битом. Так как произошло несовпадение с двумя соседними проверочными битами, то неверен информационный бит, общий для двух проверяемых пар информационных бит, и его следует инвертировать для устранения ошибки. В данном случае неисправен третий информационный бит (И3).

4. Продолжаем, по описанной выше технологии, проверять принятые данные. При проверке пятого и шестого информационных битов результат суммирования не совпал с проверочным битом (И5+И6 = 0+0 = 0 ![]() П5). Очевидно, что в одном из проверяемых битов(в пятом или шестом информационных битах или в проверочном бите) содержится ошибка.
П5). Очевидно, что в одном из проверяемых битов(в пятом или шестом информационных битах или в проверочном бите) содержится ошибка.
Для уточнения, где именно произошла ошибка, надо проверить соседние пары информационных бит:
И4+И5 = 1+0 = 1 = П4
И6+И7 = 0+1 = 1 = П6
Так как при проверке смежных пар информационных бит ошибка не была зафиксирована, то неисправен пятый проверочный бит, а, следовательно, пятый и шестой информационные биты - верны.
5. Продолжаем, по описанной выше технологии, проверять принятые данные. В результате дальнейшей проверки ошибок зафиксировано не будет.
6. Отбрасываем проверочные биты и получаем корректную исходную последовательность.
Таким образом, в результате передачи информации было искажено два бита, которые при декодировании были успешно исправлены. Естественно, количество ошибок, которые можно исправить, - ограничено. Существуют неудачные последовательности единиц и нулей, которые так же приводят к уменьшению надежности распознавания и коррекции ошибок. Однако, для повышения надежности можно прибегать к множеству других способов формирования проверочных битов или даже проверочных массивов.
Сверточные коды нашили широкое применение в области повышения надежности передачи данных. Разработано множество алгоритмов кодирования, различающихся надежность, сложностью и трудоемкостью декодирования.
На практике часто применяют, одновременно, блочное и сверточное типы кодирования. Например, в начале проводят блочное кодирование, а затем полученную информацию кодируют сверточным кодом. Такой метод называется каскадным кодированием. Он значительно повышает надежность передачи и хранения информации.
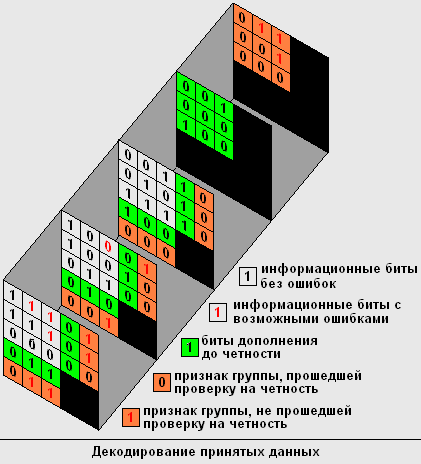
Биты с возможными ошибками будут расположены на пересечении строк, столбцов Y и Z. В нашем случае - это будут биты c координатами: [1 (номер строки), 2 (номер столбца Y), 1 (номер слоя)], [1,3,1], [2,3,1], [1,3,2].
