
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
17.4. Работа с сокетами
Представьте, что перед вами стоит задача создать чат или многопользовательскую игру. Как вы будете действовать? Как вы реализуете связующее звено на сервере, которое будет служить для передачи сообщений от одного пользователя другому (или другим)? Наиболее простой вариант — написать необходимый код на одном из серверных языков и обмениваться с ним данными по протоколу HTTP. Однако у такого подхода имеются существенные недостатки, связанные с особенностями протокола HTTP. Дело в том, что данный протокол основан на запросах, то есть соединение между клиентом и сервером непостоянное. Оно создается при необходимости отправить запрос. После получения ответа на этот запрос соединение обрывается.
Протокол HTTP был разработан с целью минимизации нагрузки на сервер при работе с HTML-сайтами, и он весьма эффективен, когда данные должны импортироваться строго по команде пользователя. Но с использованием HTTP довольно проблематично организовать непрерывный обмен данными. Например, при создании чата серверный код нужно написать таким образом, что-бы при поступлении сообщения от одного посетителя оно тут же пересылалось другим пользова-телям. Можно ли реализовать этот механизм, например, при помощи РНР? Нет! Сервер не может отправить HTTP-запрос клиенту, даже если он запишет в базе данных его IP-адрес. В случае HTTP взаимодействие одностороннее: клиент отправляет серверу запрос, сервер на него отвечает (но не наоборот). Это означает, что сервер никак не сможет проинформировать пользователя о том, что у него есть новые данные.
Единственный способ организовать нечто подобное на непрерывный обмен информацией заклю-чается в том, что клиентская машина должна периодически отправлять на сервер запрос относи-тельно того, не поступили ли для нее новые данные. Если они есть, то сервер отправит их пользо-вателю в своем ответе. Если же данные еще не поступили, то запрос следует повторить через не-которое время.
Метод эмулирования непрерывного соединения при использовании для обмена данными протоко-ла HTTP, основанный на периодических запросах со стороны клиента, называется методом опроса (polling method). Метод опроса ввиду своей простоты широко используется на практике при соз-дании чатов и других систем, в которых мгновенная реакция на поступление новых данных не критична. Но если вы создаете сетевую игру вроде Quake, биржевое приложение или видеочат, то метод опроса оказывается неэффективным. Конечно, вы можете отправлять запросы на HTTP-сервер каждые 0,1 секунды. Однако это чревато перегрузкой сервера и необоснованно большим трафиком (каждый запрос сопровождается пересылкой объемного заголовка), которые сделают задержку в поступлении данных просто огромной.
Главный недостаток обмена данными по HTTP заключается в однонаправленности соединения, т. е. инициатива обмена данными может исходить от клиента, но не от сервера. Плохо и то. что со-единение при использовании HTTP создается только на один запрос. Нельзя ли как-то между кли-ентом и сервером организовать непрерывное двунаправленное соединение? Оказывается, можно. Для этого нужно сделать шаг вниз в иерархии сетевых протоколов, перейдя с HTTP, протокола более высокого прикладного уровня, напрямую на TCP, основной протокол транспортного уровня. Важно понимать, что данные в Интернете доставляются именно при помощи протокола TCP. Про-токол же HTTP — это лишь надстройка для TCP, созданная для внедрения концепции запросов, Смысл ее существования заключается в ограничениях, от которых мы хотим избавиться. Поэтому,
пересылая данные напрямую по TCP, можно получить и двунаправленность, и непрерывность со-единения.
Основой протокола TCP являются сокеты. Сокет — это просто конечная точка транспортного со-единения. Если представить соединение как трубопровод, по которому перекачиваются данные с одной машины на другую, то сокетам будут соответствовать насосные станции на концах трубо-провода. Каждый сокет однозначно адресуется IP-номером компьютера и портом. Кратко опишем эти понятия.
IP-номер чем-то напоминает обычный телефонный номер. У каждого подключенного к Сети ком-пьютера есть свой IP, который представляет собой 32-битовое цело число, которое принято запи-сывать в виде четырех десятичных чисел от 0 до 255, разделенных точками (например, 171.34.78.14). Если один компьютер хочет связаться с другим, то он должен предоставить средст-вам маршрутизации его IP-номер. Подобно тому, как телефонный номер включает код страны, ре-гиона, города, так и по IP можно получить довольно точную информацию о местонахождении компьютера. В общем, нет различий между IP сервера и IP компьютера обычного пользователя Сети. Само деление на «сервер» — «клиент» не проявляется на уровне сетевых протоколов. Явно
его можно увидеть только на прикладном уровне, к которому относятся, например. HTTP и служ-ба DNS. Единственное различие между клиентскими машинами и сервером на сетевом уровне за-ключается в том, что у сервера IP постоянный, а у подключающегося через модем пользователя IP динамичный и выделяется случайным образом из доступного провайдеру интервала (но это не строгое правило; если пользователь имеет выделенную линию, то его IP вполне может быть по-стоянным). Благодаря тому что серверы постоянно подключены к Сети и имеют неизменный IP, к предоставляемым ими ресурсам всегда можно получить доступ.
Это кажется удивительным, но компьютер может иметь IP-номер, даже если у него нет в данный момент доступа к Сети. Этот IP имеет постоянное значение (127.0.0.1) и полезен, если вы хотите протестировать любую систему клиент-сервер локально. Для флешеров наличие подобного IP очень важно, так как это позволяет проверить работу сокета-сервера до того, как он будет уста-новлен на нужном домене.
Итак, чтобы на сетевом уровне один компьютер мог установить соединение с другим, он должен знать его IP-номер. Однако IP-номера удобны для машин, но не для людей (запомнить число из 12 цифр сложно). Поэтому в Интернет была введена служба доменных имен (DNS), дающая возмож-ность адресовать ресурс не IP, а именем. Согласитесь, что запомнить сочетание www. проще, чем 204.87.25.56. Для перевода доменных имен в IP существуют специальные DNS-серверы, на которых хранятся таблицы с IP всех серверов, имеющих доменное имя. IP-адреса основных DNS-серверов есть у отвечающих за соединение служб операционной
системы. Когда браузер или Flash-плейер встречают ссылку с доменным именем, он отправляет запрос на известный операционной системе DNS-сервер. Если он сможет установить соответствие доменного имени IP, то IP-адрес пересылается пользователю. И уже исходя из него устанавливает-ся соединение.
Кстати, в URL можно использовать не только доменные имена, но и напрямую IP (например, http://223.78.56.12/index. html). Однако на практике эта возможность применяется редко.
IР-номер адресует компьютер. Однако на одном компьютере может работать несколько служб, получающих или посылающих данные по Сети. Например, одновременно может быть запущен файловый менеджер, браузер, видеочат, программа электронной почты. Как определить, для какой из служб поступили данные? Очевидно, что каждая система должна обмениваться данными по от-дельному «трубопроводу». Чтобы разделить большую «трубу», по которой перекачиваются дан-ные с одного компьютера на другой, на маленькие «трубопроводы», распределяющие данные ме-жду приложениями, было введено понятие порта.
Порт — это некий чисто виртуальный канал, по которому приложение получает данные. На уров-не реализации никакого физического устройства, соответствующего порту, нет (многие путают сетевые порты и порты ввода-вывода на персональном компьютере, вроде СОМ или LPT). Просто когда формируется пакет с данными, в нем указывается, на какой порт он должен поступить. При-нимающая сторона, получив этот пакет, смотрит, какое приложение занимает целевой порт, и пе-редает данные ему. Если упрощать, то IP можно представить как номер дома, а порты как кварти-ры.
Номер порта задается 16-битовым числом-. Это означает, что всего имеетсяпортов. Теоре-тически, обращаясь к какой-то службе ресурса, мы должны указывать номер занимаемой ею пор-та. Но реально U RL с портом можно встретить очень редко (но они есть и имеют приблизительно следующий вид: hitp://www. *****:8080). Дело в том, что все стандартные Интернет-сервисы имеют зарезервированные порты. Так, HTTP соответствует 80 порт, FTP — 12, РОРЗ-110, Telnet — 23 и т. д. Зарезервированные порты имеют номера от 0 до 1023. Браузер знает, что HTTP-сервер всегда занимает 80 порт, поэтому он автоматически использует его при обращении к ресурсу, ад-ресуемому ссылкой с префиксом «http://».
Если вы создадите собственную службу, то системный администратор должен будет выделить для нее порт или интервал портов. Наверняка номер предоставленного вам порта будет лежать в ин-тервале от 5001 допорты с номерами 0—1023 занимают стандартные службы, порты 1024—5000 зарезервированы для временного использования при установлении соединения). Обычно для чата или сетевой игры бывает необходим интервал портов. Это связано с тем, что лю-бое TCP-соединение является двухточечным, поэтому к одному порту одновременно может быть подключен только один клиент. Кстати, во многом из-за невозможности широковещания в TCP и был разработан протокол HTTP: кратковременные запросы дают возможность одновременно взаимодействовать с 80-м портом сервера сразу нескольким клиентам.
Итак, «действующими лицами» протокола TCP являются сокеты, которые адресуются номерами IP и порта. Как происходит взаимодействие между ними? Один сокет должен находиться в режиме прослушивания, постоянно ожидая вызова из Сети. Ему соответствует проигрываемая в бесконеч-ном цикле программа, называемая демоном. Такой сокет принято называть сокетом-сервером. Другой сокет присылает сокету-серверу запрос на установку соединения. Этот сокет называется клиентом. Если сокет-сервер не занят, то он отправляет клиенту подтверждение готовности уста-новить соединение, после чего начинается обмен данными.
После того как соединение будет открыто, какие-либо различия между сокетом-сервером и соке-том-клиентом теряются. Они оба могут как отправлять, так и получать данные. Причем получение и отправка данных может происходить одновременно (т. е. TCP-соединение является полнодуп-лексным). Это резко отличает обмен данными напрямую по TCP от использования HTTP. В HTTP понятия «клиент» и «сервер» легко различить, а отправка запроса и получение ответа во времени четко разделены.
HTTP-соединение существует только в течение одного запроса. Соединение между сокетами про-токола TCP может быть активно сколь угодно долго. Чтобы разорвать его, одна из сторон должна дать соответствующую команду (или просто выйти из Сети).
Используя ActionScript, можно создать сокет-клиент. Для этого предназначен класс XMLSocket, о котором поговорим в п. 17.4.1. Чтобы создать сокет-сервер, можно использовать любой универ-сальный язык (чаще всего применяется Java) или же серверный скрипт вроде РНР. Написать сокет-
клиент довольно легко. Однако реализация качественного сокета-сервера очень непростая задача, требующая глубоких познаний в сетевых технологиях и программировании. Поэтому при созда-
нии флеш-проектов чаще используют готовые сокеты-серверы, которых довольно много (их обзор дан в п. 17.4.2), причем большинство из них бесплатные или продаются по более-менее доступной цене.
Заканчивая это краткое введение в технологию сокетов, перечислим основные достоинства пере-дачи данных напрямую по протоколу TCP по сравнению с применением HTTP.
• Данные может пересылать как клиент, так и сервер (впрочем, такое деление в TCP условно). Это позволяет осуществлять значительно более оперативный обмен данными, чем при исполь-зовании метода опросов, применяемого для эмуляции непрерывного обмена информацией в
HTTP.
• HTTP-запросы имеют довольно объемные заголовки. Пакетам же TCP характерна весьма ком-пактная служебная часть (всего 40 байтов). Поэтому применение сокетов приводит к ощути-
мому сокращению трафика. Это важно, если поток данных интенсивный (что вполне вероят-но, например, в случае игры вроде Quake).
• Используя сокет-соединение, вы всегда знаете, «па проводе» ли еще принимающая сторона. Поэтому, например, вы сможете сразу же удалить пользователя из числа посетителей чата, ес-ли связь с ним оборвется. Если же вы создадите тот же чат на основе HTTP, то сервер не будет иметь абсолютно никакого представления о том, находятся ли посетители еще в Сети или уже нет. Конечно, можно удалять посетителя из чата, если от него довольно долго нет запросов. Однако при этом 5-10 минут будет неопределенность.
• С использованием сокетов можно обмениваться данными со стандартными службами. Напри-мер, во Flash 7 уже вполне реально создать почтовый клиент, который будет отправлять пись-ма напрямую почтовому серверу (ранее для этого требовался прокси-сцепарий вроде того, ко-торый мы написали в п. 17.3.2).
Казалось бы, если сокеты так хороши, то почему бы не использовать их для взаимодействия с сер-вером всегда. Увы, но у сокетов есть свои недостатки, которые прямо противоположны достоин-ствам протокола HTTP.
• Сокет-сервер представляет собой демон — непрерывно работающую программу. Чтобы иметь возможность установить и запустить такую программу (а также выделить для сервера порт или интервал портов), вы должны иметь статус администратора. Это возможно, если у вас есть свой Интернет-сервер или же вы купили очень качественный хостинг. И первый, и второй случай подразумевают довольно ощутимые денежные расходы. Если же вы пользуетесь бес-платным хостингом, то запустить сокет-сервер вам никто не позволит. Например, на таких хостингах заблокированы даже безобидные функции РНР вроде gethostbyname(), позволяю-щие получить IP номер ресурса на основании доменного имени. Что уж говорить про сокеты, отвечающие за создание которых функции крайне небезопасны!
• Чтобы создать хороший сокет-сервер, вы должны на очень высоком уровне владеть сетевыми технологиями и знать один из универсальных языков. Купить же готовый сервер могут позво-лить себе далеко не все.
17.4.1. Класс XMLSocket
Класс XMLSocket() предназначен для создания сокета-клиента. Довольно странное название этого класса объясняется тем, что чаще всего в случае многопользовательских игр и качественных чатов клиент и сервер обмениваются данными в формате XML. Однако при помощи XMLSocket() мож-но отправить на сервер или получить от него любую текстовую информацию, а не только доку-менты ХМ L (поэтому правильнее было бы назвать класс XMLSocket просто Socket). Организация любого TCP-соединения начинается с создания объекта класса XMLSocket;
var socket:XMLSocket=new XMLSocket();
Затем нужно отправить предложение установить соединение необходимому сокету-серверу. Для этого служит метод connect(), имеющий следующий синтаксис:
socket. connect(server, port);
где:
• server — Интернет-сервер, на котором располагается программа-демон, исполняющая роль
сокета-сервера. Может адресоваться как IP-номером, гак и доменным именем. По умолчанию
фильм может создать соединение лишь с сокетом-сервером, располагающимся на том же до-
мене, с которого он был получен сам. Как можно обойти это ограничение, читайте в п. 17.1.5;
Если соединение должно быть организовано с сокетом-сервером па том же домене, откуда был получен фильм, то его адрес прописывать необязательно.
В качестве первого параметра методу connect() можно передать просто null или пустую строку;
• port — целое число, задающее номер порта, с которым связан целевой сервер-сокет. По умолчанию нельзя подключиться к порту с номером меньше 1024. Это ограничение введено с целью предотвращения атак на порты стандартных служб. Однако если у вас имеется высокий административный доступ к домену, с которым будет устанавливаться соединение, то данное ограничение можно преодолеть. Как это сделать, описано в п. 17.1.5.
В качестве результата метод connect() возвращает true, если запрос на открытие соединения был успешно отправлен. Если же параметры были заданы неверно, то connect() возвратит false.
Если сокет-сервер будет найден и он примет предложение организовать соединение, то им клиен-ту будет отправлено подтверждение. Аналогичное сообщение будет послано сервером, если он
отклонит запрос. При получении ответа от сокета-сервера, сокет-клиент Flash-фильма вызовет со-бытие onConnect. Это событие также произойдет, если необходимый сервер просто не будет най-ден, компьютер не имеет активного соединения с Сетью или же не были учтены ограничения, свя-занные с политикой сетевой безопасности. Об успешности попытки установить соединение можно
будет судить по значению параметра, переданного обработчику события onConnect. Если оно бу-дет true, то TCP-соединение установлено и можно посылать данные (или ожидать их прихода от сервера). Если же оно равно false, то сервер отклонил запрос (или же он просто не был найден).
var socket:XMLSocket=new XMLSocket();
if (!socket. connect("www. *****",9875)) {
trace("He удалось отправить запрос");
}
socket. onConnect=function(success:Boolean):Void {
if (!success) {
trace("He удалось установить соединение");
} else {
trace("Соединение успешно установлено");
}
};
Событие onConnect обычно используется для установки некоего флага, который будет показывать остальному коду, что можно начать отправлять данные или ожидать их прихода от сервера.
Чтобы отправить данные сокету-серверу, нужно воспользоваться методом send(). В качестве пара-метра данный метод принимает строку с подлежащим пересылке текстом. Он дополняет текст этой строки нулевым байтом (первый символ любой кодировки, основанной на ASCII) и отправля-
ет ее серверу. Например:
socket. send("Привет всем!");
Распространено заблуждение (основанное, отчасти, на названии класса XMLSocket), что в качест-ве параметра метод send() принимает объект класса XML. На самом деле это не так. Аргументом send() может быть любой объект данных. Перед отправкой же он будет преобразован в строку. Приведение к типу string объекта XML даст соответствующий XML-документ, поэтому объекты
XML можно передавать методу send() напрямую.
Ограничений на объем пересылаемых по TCP данных нет. В крайнем случае, информация будет просто распределена между несколькими ТСР-сегментами.
Класс XMLSocket не дает возможности узнать, было ли получено сообщение сервером или же оно оказалось потеряно (что с учетом надежности TCP крайне маловероятно). Нельзя также напрямую определить, с какой задержкой данные были доставлены. Если факт получения сервером данных должен быть подтвержден, то просто настройте его так, чтобы он отправлял клиенту простое со-
общение в ответ на приход от него информации.
Огромным достоинством передачи данных с использованием сокетов по сравнению с HTTP явля-ется то, что при этом данные может послать не только клиент, но и сервер. Причем отправка ими сообщений происходит абсолютно взаимонезависимо.
Однако эти преимущества TCP имеют не очень приятное следствие: заведомо нельзя сказать, ко-гда в фильм поступят данные от сервера. К счастью, в ActionScript эта проблема легко решается. Зарегистрировать момент поступления данных позволяет событие onData. В качестве параметра его обработчику передается переданный сервером текст:
// В Output будут выводиться все присылаемые сервером сообщения
socket. onData=function(text:String):Void {
trace("Сервер сообщает:"+text);
}
О том, что текст поступил полностью, сокет-клиент судит по нулевому байту, которым сервер должен завершать любое сообщение. Наличие нулевого байта очень важно, так как иначе сообще-ния будет проблематично разделить (вполне может оказаться так, что часть одного сообщения придет в TCP-сегменте с другим сообщением). Собственно, событие onData происходит именно тогда, когда обнаруживается нулевой байт. Текстом же сообщения считается весь текст, получен-ный от сервера между двумя событиями onData (т. е. участок данных, ограниченный двумя нуле-
выми байтами).
Кстати, хотя нулевой байт и завершает любое сообщение, в его текст, передаваемый обработчику
события onData в параметре, он не включается.
На практике сокеты чаше обмениваются данными в формате XML, нежели простыми сообщения-ми или строками с парами имя-значение. Чтобы это учесть, разработчики класса XMLSocket доба-вили в него возможность разбора XML-документов с преобразованием их в соответствующие объ-екты класса XML. Разбор XML-документа запускается в том случае, если у события on Data нет обработчика (его наличие говорит о том, что пользователь хочет работать с полученным от серве-ра текстом напрямую). Если документ корректный и разбор прошел успешно, то возникает собы-
тие onXML, обработчику которого передается созданный на основании документа объект класса
XML.
Когда соединение выполнит свою функцию, его нужно закрыть. Для этого недостаточно просто удалить объект класса ХМ LSocket. Особое сообщение должно быть отправлено сокету на другом конце соединения. Для этого служит метод close():
socket. close();
Метод close() не удаляет объект класса XMLSocket. Поэтому он может быть использован повтор-но.
Соединение может закрыть не только сокет-клиент, но и сокет-сервер. Кроме того, может про-изойти сбой или обрыв связи, который повлечет за собой разрушение соединения. Естественно, что качественно разработанное приложение должно адекватно реагировать на подобные ситуации (например, при этом можно попробовать восстановить соединение, а при неудаче вывести сооб-
щение для пользователя). Узнать, что соединение было оборвано, можно благодаря наличию со-бытия onClose.. Например:
// При обрыве связи пытаемся восстановить соединение
socket. onClose=function():Void {
this. connect("www. ",8080);
};
Событие onClose происходит, когда соединение обрывается сокетом-сервером или разрушается из-за какой-то ошибки, но вызов метода close() не сопровождается событием onClose.
17.4.2. Создание сокета-сервера
Создание хорошего сокета-сервера — это задача, на порядок превосходящая по сложности реали-зацию сокета-клиента. Для ее решения, естественно, нельзя использовать ActionScript. Сокет-сервер можно написать на любом универсальном языке программирования или же используя та-кие серверные скриптовые языки, как Perl или РНР. Чаще же всего сокеты-серверы создаются на
Java, который, с одной стороны, прекрасно приспособлен для сетевого программирования, а с дру-гой — обеспечивает высокую производительность сервера и удовлетворительную степень безо-пасности для компьютера, на котором запускается сервер.
Подробное описание создания сокета-сервера выходит за пределы тематики этой книги. Но для демонстрации приведем код небольшого сервера на РНР, который просто пересылает полученные от клиента сообщения ему же. Единственное, о чем нужно всегда помнить, создавая такой сервер, — конец сообщения должен обозначаться нулевым байтом (в РНР нулевой байт задается escape-последовательностью \0).
<?php
// Разрешаем скрипту выполняться неограниченно долго
// (сервер - это программа-демон, которая работает в бесконечном цикле)
set_time_limit (0);
// Записываем в переменную IP-номер домена, на котором располагается скрипт
$address=gethostbyname($_SERVER['SERVER_NAME']);
$port=10000; // Записываем номер порта, отведенный под сокет-сервер
// Инициализируем новый сокет
$sock=socket_create(AF_INET, SOCK__STRSAM, 0);
// Связываем сокет с IP и портом
socket_bind($sock,$address,$port);
// Включаем сокет-сервер в режим прослушивания вызовов от сокетов-клиентов
socket_listen($sock,5);
// Запускаем бесконечный цикл, в котором проверяем, не присоединился ли
// к сокету-серверу клиент
while (1) {
$acc=socket_accept($sock);
// Если соединения нет, то сразу перехолим к следующей итерации
if (!$acc) {
continue 1;
}
// Если клиент присоединился, то запускаем цикл, в котором считываем
// поступающие от неге данные, и записываем их в строку $buf
$buf='';
while(1) {
$buf.=socket_read[$acc,204S); // Считываем доступные данные
// Если от клиента поступает команда close, то отключаем соединение if {$buf=='close\0") {
socket_close($acc);
break 2;
}
// Если от клиента поступает команда quit, то останавливаем работу
// сервера
if ($buf=='quit\0') {
break 1;
}
// Если новую партию считанного текста завершает нулевой байт,
// значит сообщение закончено. Его нужно переслать назад клиенту,
// и начать цикл сначала.
if(substr($buf, strlen($buf)-1,1)=='\0')){
socket_write($acc,$buf);
$buf='';
}
}
}
Запустить такой сервер можно обычным запросом метода send() класса LoadVars. Правда, чтобы он работал, интерпретатор РН Р, установленный на домене, должен поддерживать библиотеки функций сокетов. Кроме того, не должен быть включен безопасный режим, в котором эти функ-ции будут заблокированы.
Тестируя сервер, установите ограничение на время выполнения кода при помощи функции set_time_limit(). Иначе при возникновении ошибки он вполне может вызвать сбой в работе осталь-ных служб домена.
Приведенный сокет-сервер носит чисто учебный характер. Он максимально упрошен, так что в
нем даже не производится обязательная для приложений такого рода обработка ошибок. Он соз-дан с единственной целью — продемонстрировать принципы реализации сокетов-серверов. По-этому не нужно относиться к нему критично, даже если малейший сбой вызывает прекращение его
работы.
Если вы не сильны в сетевом программировании, то не рекомендуем вам браться за создание соке-та-сервера. Это не только займет у вас немало времени, но и потребует отменной усидчивости и готовности читать скучнейшие спецификации. Имеется немало готовых сокетов-серверов, как коммерческих, так и распространяемых бесплатно, которые можно эффективно использовать, имея самые отдаленные представления о том, как они работают. Более того, на рынке есть не-сколько мощных серверов, которые были созданы специально под Flash. Они не очень дорогие и вполне доступны даже российскому разработчику. Кратко опишем наиболее широко используе-
мые сокеты-серверы.
• ElectroServer от компании Electrotank (http://www. ). Высокопроизводительный Java-сервер, предназначенный для создания чатов и многопользовательских игр на Flash. Наи-более популярен среди разработчиков. Принимает команды и данные в формате XML. Однако на практике работать с XML не приходится, потому что написан класс ElectroServerAs, кото-рый позволяет взаимодействовать с сервером так, как будто он также создан на ActionScript. Имеется бесплатная версия ElectroServer, которая поддерживает до 20 соединений.
• Unity Socket Server от Колина Мука (http://www. moock. org/unity/). Хороший сокет-сервер на
Java, однако более слабый, чем ElectroServer. Отлично поддерживает чаты. Значительной до-
лей своей популярности обязан тому, что был создан автором наиболее распространенного на
Западе руководства по ActionScript.
• Fortress от компании Xadra (http://www. ). Мощный и дорогой Java-сервер, созданный
специально для реализации многопользовательских игр.
17.5. Работа с XML
XML — это одна из наиболее важных в истории информатики разработок в, области синтаксиса
документов. За последние 30 лет ХМ L получил очень широкое распространение. Он стал синтак-
сисом новых форматов документов практически во всех сферах применения компьютеров. Чем же
так хорош XML и чем данная технология может помочь Flash-разработчику?
ХМL —самый простой, понятный и гибкий из всех изобретенных синтаксисов документов. В мире
компьютеров же к форме текстового документа можно привести любую структуру данных. Следо-
вательно, ХМL полезен как лучший формат сохранения и передачи структурированных данных.
Конечно, зачастую структуру данных можно представить и в более элементарной, чем ХМL, фор-
ме строки с парами имя-значение. Например, если вам нужно передать на сервер следующий объ-
ект:
var capitals:Object=[England: "London", USA: "Washington", Russia: "Moscow"};
то его вполне приемлемо записать в такой форме:
England=London&USA=Washington&Russia=Moscow
Программа буквально из нескольких строк кода сможет воссоздать на основании такой строки ис-ходный объект (или аналогичную ему структуру данных той системы, в которую вы передаете информацию).
Но что, если в свойстве объекта будет храниться другой объект или массив? При этом представить его линейной структурой, которой является строка с парами имя-значение, будет весьма пробле-матично. А ведь степень вложенности объектов и сложность связей между ними могут быть лю-быми... Чтобы представить подобные древовидные структуры данных, нужен формат, способный однозначно их описать при сколь угодно большой степени вложенности элементов. И таким фор-матом является XML. Например, объект
var peoples:Object={Jonh:{age:24, phones:[, ]}, Bob:{age:31,
phones:[]}},
можно описать таким XML-документом:
<peoples>
<person name='Jonh'>
<age value='24'/>
<phones>
<number>3456459</number>
<number></number>
</phones>
</person>
<person name='Bob'>
<age value='31'/>
<phones>
<number></number>
</phones>
</person>
</peoples>
Подобным образом XML дает возможность представлять в виде текстовых документов структуры данных любой сложности. Воссоздать же на основании XML-документа более подходящую для обработки и анализа языком программирования структуру данных ввиду простоты и однозначно-сти правил синтаксиса XML будет очень легко. Более того, для этого наверняка не придется пи-сать никакой код. Дело в том, что сейчас в любом более-менее широко распространенном универ-сальном или скриптовом языке есть библиотеки, отвечающие за работу с XML. В ActionScript за нее отвечают классы XML и XMLNode, при помощи которых ХМ L-документ представляется как
дерево объектов. Конечно, нечто подобное на ХМ L и, возможно, даже более подходящее для решения какой-то конкретной задачи можно придумать и самостоятельно. Но делать это не стоит. Помимо того, что при этом вам придется дополнительно написать большой фрагмент кода, вы потеряете одно из ос-новных достоинств ХМ L — переносимость. Язык XML является стандартизированным и обще-принятым форматом обмена данными между приложениями. Поэтому, например, преобразовав объект в XML-представление, вы можете передать его серверу, Java-приложению или СУБД. И любая из этих систем сможет преобразовать полученные данные в присущее ей внутреннее пред-
ставление. Но чтобы система смогла разобрать ваш собственный формат описания структур дан-ных, она должна быть создана вами. Данные же в формате XML являются переносимыми, то есть в них сможет разобраться практически любая система, а не только та, в которой соответствующий документ был создан.
Итак, первичная задача, для которой XML используется в ActionScript, связана с преобразованием структур данных в представление, в котором они могут быть сохранены и переданы стороннему приложению, а также на основании которого исходные структуры данных могут быть легко вос-становлены в первоначальном виде. XML полезен также для создания сложных нелинейных опи-саний. Уже знакомая нам сфера использования XML — разметка текста.
Чтобы проиллюстрировать, насколько полезно владеть XML ActionScript-программисту, опишем несколько задач, наиболее эффективное решение которых связано с применением XML.
• Представьте, что вам необходимо создать Flash-приложение, в котором имитируется интер-фейс Windows, Ключевым элементом такого приложения должен быть компонент, изобра-жающий окно. Этот компонент следует сделать так, чтобы его содержимое, пункты главного и контекстного меню можно было задавать произвольно. Подменю главного меню могут иметь любую степень вложенности, Возникает вопрос: как наиболее просто задать главное меню и структуру его подменю? По сути говоря, здесь возникает задача описания дерева. А наиболее просто задать дерево можно как раз при помощи ХМ L.
• Классический пример использования XML — фотогалерея. Как ее создать, чтобы в нее можно было добавлять новые фотографии и удалять старые, не производя перекомпиляцию фильма? Очень просто. Ее структуру нужно описать при помощи XML-документа, в котором будут храниться ссылки на нужные файлы. Разобрав этот документ, фильм подгрузит необходимые фотографии посредством функции loadMovie() или класса MovieClipLoader.
• XML-документ удобно использовать в качестве небольшой базы данных. Например, пред-ставьте, что вы создаете игру и хотите ввести в нее возможность сохранения текущей игровой позиции. Чтобы однозначно воссоздать состояние игры, нужно знать значения всех ключевых свойств и переменных. Следовательно, чтобы сохранить игровую позицию, следует записать в XML-документе эти свойства и переменные, а затем отправить полученный файл на сервер. При необходимости его нужно будет загрузить, разобрать и переопределить нужные перемен-ные и свойства — и игра начнется с того же места, на котором она была приостановлена.
• Лучший на данный момент сокет-сервер ElectroServer принимает данные и команды в виде XML-документов. Используя данный сервер, вы сможете создать многопользовательскую иг-ру, чат или биржевое приложение.
Примеров применения XML можно привести еще очень много. Недаром данная технология стала столь популярной в последние годы. Хороший ActionScript-разработчик должен обязательно вла-деть XML, так как без этого довольно сложно создать легко настраиваемое и расширяемое прило-жение, а также приложение, взаимодействующее с другими технологиями.
В этом параграфе изучим, как средствами ActionScript можно анализировать существующие и соз-давать новые XML-документы. Но так как не все читатели знают XML, сначала мы обсудим ос-новные принципы данного языка. Ввиду простоты XML и ограниченности его поддержки во Flash небольшого обзора будет вполне достаточно для того, чтобы рассмотреть XML в достаточном для решения основных практических задач объеме. 17.5.2. Объектная модель XML. DOM
XML — текстовый формат, удобный для хранения и передачи структурированных данных. Но ра-ботать с ним напрямую сложно в любом языке программирования. Чтобы можно было легко счи-тывать из ХМ L-документа данные или модифицировать его, сначала его нужно преобразовать в более подходящую форму. На данный момент для решения этой задачи наиболее широко исполь-зуется программная модель D0M, основанная на том, что любой корректный документ может быть представлен в виде дерева объектов. Применяется DOM и Flash-плейером.
DOM (Document Object Model — объектная модель документа) разработана комитетом W3C и реализована в большинстве языков и программных сред. Ее основной конкурент — основанная на событиях модель SAX — распространен гораздо меньше. Причиной столь значительной популяр-ности DOM является ее простота и интуитивность. В ActionScript реализован упрошенный вариант DOM, имеющий много отклонений от стандарта. Его рассмотрению посвящен данный пункт.
Как уже говорилось, основной идеей DOM является то, что для описания XML-документа нужно построить дерево объектов. Каждый объект изображает один узел (проще говоря, тег). У каждого объекта есть массив ссылок на объекты, соответствующие дочерним узлам описываемого им узла дерева XML. Они расположены в том же порядке, в котором прописаны теги, на основании кото-рых они были заданы. У каждого объекта узла также есть свойство, ссылающееся на объект роди-тельского узла. В особом объекте, связанном с объектом узла, в форме свойств хранятся его атри-буты.
В ActionScript есть специальный класс, объекты которого выступают в роли узлов дерева DOM, — ХМLNode. Его свойства и методы дают возможность осуществлять навигацию по дереву, считы-вать данные и производить разнообразные модификации.
Помимо XMLNode, в ActionScript есть еще один класс, связанный с работой с ХМL. Этот класс называется XML, и его объекты олицетворяют документ в целом. Этот класс необходим, чтобы можно было проводить операции, относящиеся ко всему документу. К таким операциям относят-
ся, например, считывание и инициализация XML - и DDT-объявления, загрузка содержимого и от-правка документа на сервер, преобразование XML-текста в дерево объектов DOM и т. д.
Через объект класса XML осуществляется доступ к объекту дерева DOM, соответствующего кор-невому тегу. Для большей интуитивности эта операция осуществляется при помощи тех же инст-рументов, с использованием которых можно перейти от объекта родительского узла к дочернему узлу. Поэтому описывающему документ объекту класса ХМ L должны быть доступны те же свой-ства и методы, что и объектам узлов дерева D0M. Чтобы это было возможно, класс XML был сде-лан подклассом XMLNode. В прототипе ХМLNode хранятся элементы, предназначенные для ра-боты с деревом документа. В прототипе же XML записаны методы и свойства, предназначенные для проведения более общих операций.
На практике объектом класса XML используются лишь свойства класса XMLNode, предназначен-ные для доступа из объекта родительского узла к объекту дочернего узла. Эта операция нужна, чтобы получить доступ к объекту класса XMLNode, описывающему корневой узел документа. То есть формально объект класса XML является родительским узлом для объекта корневого узла, описывающего XML-документ дерева DOM.
Нужно помнить о различиях между классами ХМL и ХМLNode. Попытка задействовать метод или свойство, присущее только классу ХМL, через объект узла приведет к сбою. Также нужно пони-мать, что для того, чтобы сделать некий метод или свойство доступным объектам всех узлов, его нужно записать в прототип класса XMLNode. Если сохранить его в прототипе класса XML, то объекты, образующие дерево DOM, не смогут его использовать.
Довольно странной на первый взгляд особенностью DOM, реализуемой Flash-плейером, является то, что вложенный в тег текст не помещается в свойство описывающего узел объекта, а для его хранения формируется новый объект узла. Этот узел считается дочерним узлом узла, к которому относится текст. Узел, сформированный на основании тега, и узел, заданный исходя из текста, формально относятся к разным типам узлов; ELEMENT и TEXT. Реально же описывающие их объекты предельно схожи, и различия между ними можно обнаружить только посредством свой-
ства nodeType.
В «настоящем» DOM от W3C на основании любого элемента XML создается объект узла. Эти объ-объекты различаются по типу. Обычному узлу, сформированному на основании некорневого тега,
соответствует тип ELEMENT. Узел, описывающий текст, вложенный в тег, относится к типу TEXT. Узел, хранящий атрибут, принадлежит типу Лиги т. д. Всего типов узлов в DOM 12. И лишь два из них (ELEMENT и TEXT) есть в DOM, реализуемой Flash-плейером. Это связано как с тем, что анализатор XML плейера поддерживает не все возможности данного языка, так и с тем, что DOM, применяемая в ActionScript, имеет ряд отклонений от стандарта (например, для каждого
атрибута не создается отдельный объект узла).
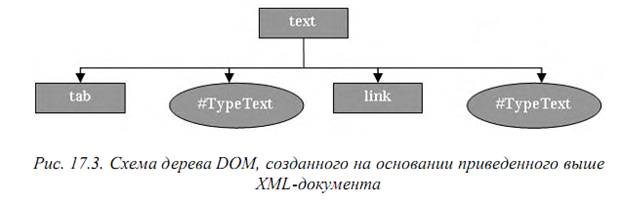
Если текст узла разрывается тегом, то каждая его часть рассматривается анализатором как само-стоятельная (поэтому узел типа TEXT не может иметь дочерних узлов). К примеру, следующий документ даст дерево DOM, у которого будет четыре узла второго уровня (два типа ELEM ENT и два типа TEXT):
<text>
<tab/> Предком XML является <link addr="http://w3c. org"/> SGML
</text>
Схема дерева, которое Flash-плейер создаст на основании этого документа, показана на рис. 17.3.
17.5.3. Преобразование XML-текста в дерево объектов DOM
Чтобы обработка XML-документа посредством ActionScript стала возможной, его нужно преобра-зовать в дерево объектов DOM. Для этого соответствующий текст должен быть передан XML-анализатору ActionScript. Сделать это можно тремя способами.
• Чаще всего XML-текст разбирается на этапе создания объекта класса XML. Как вы помните, этот объект описывает документ в целом (в отличие от класса ХМLNode, объекты которого исполняют роль узлов дерева D0M), и через него осуществляются все манипуляции с данны-ми. Чтобы связать объект класса XML сразу же при его создании с XML-документом, строка с текстом последнего должна быть передана конструктору класса XML:
var xml_doc:String="<doc><link>http://www. </link></doc>";
var xml_data:XML=new XML(xml_doc);
• Если один и тот же объект класса XML по мере проигрывания фильма должен описывать раз-ные XML-документы, то нужно использовать метод parseXML(). Данный метод принимает текст ХМ L-документа в качестве параметра, передает его анализатору, а затем связывает вы-звавший его объект класса ХМ L с полученным деревом DOM. Старое содержимое объекта класса XML при этом уничтожается.
var xml_doc:Strings"<doc><link>http://www. </link></doc>";
var xml_data:XML=new XML("<doc0></doc0>"s);
// Заменяем дерево DOM одного документа деревом другого
xml_data. parseXML(xml_doc);
• Два предыдущих способа преобразования ХМ L-документа в дерево DOM подразумевают, что строка с ним уже имеется в фильме. Но зачастую XML-документ, подлежащий анализу, хра-нится в удаленном текстовом файле. Поэтому перед разбором его необходимо импортировать.
Дать команду на закачку файла с документом позволяет метод load() класса XML. Когда до-кумент будет закачан, он подвергнется анализу, а полученное дерево DOM станет связано с вызвавшим load() объектом. Его старое содержимое при этом удаляется. Так как заведомо не-известно, когда будет получен файл с XML-документом, метод load() обычно используется в
сочетании с событием onData (происходит при поступлении данных) или onLoad (возникает по завершении разбора XML-документа). По особенностям использования метод load(), а так-же события onData и onXML идентичны одноименным элементам уже разобранного нами класса LoadVars.
var xml_data:XML=new XML();
xml_data. load("http://www. *****/data. xml");
xml_data. onLoad=function():Void {
trace("XML-документ закачан и разобран");
};
Вне зависимости оттого, как текст ХМ L-документа поступает анализатору, разбирается он по од-ним и тем же принципам. Основные из них обсудим ниже.
У XML, в отличие от HTML, очень строгие правила синтаксиса. Поэтому допустить ошибку, ко-торая приведет к прекращению разбора документа анализатором, просто. К счастью, обнаружить, что поступивший на обработку XML-документ некорректный и на основании его не было сфор-мировано дерево D0M, несложно. С учетом строгости синтаксиса ХМL, точный «диагноз» причин сбоя может поставить сам анализатор XML Flash-плейера. Узнать, был ли разбор XML-документа
успешным, и если нет, то почему, позволяет свойство status класса XML. Оно равно нулю, если преобразование XML-текста в дерево DOM прошло без накладок. При возникновении сбоя status будет хранить отрицательное число от -1 до —10. Каждое число соответствует отдельному типу синтаксической ошибки. В табл. 17.1 показано, какое число означает какую ошибку.

ко разноплановых ошибок, сообщение о какой из них будет помещено в свойство status? Ответ: первой от начала документа. Дело в том, что синтаксический анализатор работает до тех пор, пока ему не попадется ошибка. Текст документа, находящийся после нее, не анализируется. Однако (это важно знать) дерево объектов DOM формируется на основании разобранной части документа, даже если в нем встречается синтаксическая ошибка.
Приведем небольшой пример. Передадим анализатору Flash-плейера документ, в котором атрибут тега не помещен в кавычки:
var xml_data:XML=new XML("<doc><data type=xml></data></doc>");
trace(xml_data. status); // Выводит: -6
В общем, синтаксическую ошибку анализатор нашел, но не совсем точно. Он сообщил, что узел задан неверно. Более информативным было бы значение свойства status, равное —8.
Применяйте свойство status, если XML-документов, которые будет использовать фильм, нет на момент его создания. Это позволит сделать приложение более устойчивым к сбоям.
XML-анализатор Flash-плейера проверяет документ на синтаксическую корректность, но не на действительность. То есть если в документе есть ссылка на DTD, которому он должен соответст-вовать, анализатор плейера не будет сравнивать документ с описанным в DTD шаблоном. Он даже не будет импортировать DTD. Однако объявление типа документа не будет просто выброшено. Оно будет занесено в свойство docTypeDecl в форме строки. Например:
var docTDecl:String="<!DOCTYPE data SYSTEM 'dtd/data. dtd'>";
var xml_body:String=docTDecl+"<data></data>";
var xml_doc:XML=new XML(xml_body);
trace(xml_doc. docTypeDecl); // Выводит: <!DOCTYPE data SYSTEM 'dtd/data. dtd'>
Аналогично объявлению типа документа, анализатор XML Flash-плейера не анализирует объявле-
ние XML-документа. Из этого можно сделать важные выводы:
• если ХМL-документ создается специально для передачи данных фильму Flash, то XML-
объявление наверняка будет излишним;
• невозможно передать в фильм XML-документ, кодировка которого отличается от используе-мой фильмом, просто указав ее в атрибуте encoding ХМL-объявления. В любом случае фильм будет трактовать документ исходя из той кодировки, которую применяет он сам,
Несмотря на то что XML-заголовок не влияет на результат преобразования документа в дерево DOM, он не отбрасывается, а помещается в специальное свойство xmlDecl как строка. Например:
var doc:String="<?xml version='1.0' encoding='UTF-8'?>";
doc+="<data></data>"
var xml__doc:XML=new XML(doc);
trace(xml_doc. xmlDecl>; // Выводит: <?xml version='1.0' enogding='UTF-8'?>
Попробуйте определить, сколько узлов и какого уровня будет иметь описывающее следующий XML-документ дерево DOM:
<data> </data>
«Один узел первого уровня», — скажете вы. И окажетесь неправы. При описании DOM, исполь-зуемой Flash-плейером, мы говорили о том, что текст, вложенный в тег, дает особый текстовый узел. «Но между тегами <data> нет текста», — возразите вы. Да, видимого текста действительно
нет. Но есть пробел. А он является таким же символом, как и любой другой. Следовательно, для его хранения будет создан текстовый узел. То же самое произойдет, если между тегами имеется перенос строки, перевод каретки или символ табуляции.
То, что совершенно любой текст, набранный в теге, преобразуется в текстовый узел, не всегда приемлемо. Например, если вы создаете XML-документ вручную, то для его лучшей читабельно-сти стоит использовать отступы и переносы. Однако при этом в дереве DOM появится масса но-вых текстовых узлов, которые с высокой вероятностью собьют алгоритм с толку. Чтобы этого не произошло, перед передачей текста документа анализатору нужно присвоить значение true свой-ству ignoreWhite. При этом если текст тега состоит из одних пробелов, то он будет просто отбро-шен. Повторные пробелы между словами, а также в начале и в конце текста удаляться не будут.
По умолчанию свойство ignoreWhite равно false. Например:
var xml_obj:XML=new XML("<text> </text>");
trace(xml_obj. firstChild. firstChild. nodeValue == " "); // Выводит: true
// (текстовый узел на основании пробела был создан)
xml obj. ignoreWhite=true;
xml_obj. parseXML("<text> </text>");
trace(xml_obj. firstChild. firstChild); // Выводит: null (узла нет)
Анализатор XML Flash-плейера может распознавать секции CDATA. Эту его возможность нужно использовать, если XML-документ содержит другой XML-документ или, что чаше встречается на практике, HTML-текст. Содержимое секции СDATA не анализируется, а без каких-либо измене-ний преобразуется в текстовый узел. Например:
var xml_text:String="<text><![CDATA[<b>Это<i>HTML</i>-текст</b>]]></text>";
var xml_obj:XML=new XML(xml_text);
trace(xml_obj. firstChild. firstChild. nodeValue); // Выводит:
// <b>Это<i>HTML</i>-текст</b>
17.5.4. Обход дерева DOM
Извлечение данных из XML-документа, его модификация и даже создание — все эти операции сопряжены с обходом описывающего документ дерева DOM. Осуществить этот обход несложно, особенно если структура дерева заранее известна. Для этого предназначен ряд свойств и методов класса ХМLNode, которые мы подробно обсудим в этом пункте.
Начинается любой обход с получения ссылки на объект в дереве DOM, описывающий корневой тег документа. Эту ссылку хранит объект класса ХМL, через который текст документа был пере-дан анализатору. Все три способа получить ее приведены ниже:
var xml_doc:XML=new XML("<text>Привет</text>");
var root_node_1:XMLNode=xml_doc. firstChild;
var root_node_2:XMLNode=xml_doc. lastChild;
var root_node_3:XMLNode=xml_doc. childNodes[0];
trace(root_node_1==root_node_2 && root_node_1==root_node_3);
// Выводит: true
Все способы получения доступа к объекту корневого узла основаны на том, что объект класса
ХМL формально считается его родительским узлом. Поэтому можно применять те же средства,
которые используются при обходе дерева DOM для перехода от родительского узла к дочернему.
Успешно перейдя к объекту корневого узла документа (или к объекту любого другого узла), в пер-
вую очередь нужно проверить, есть ли у него дочерние узлы.
Сделать это позволяет метод hasChildNodes() класса XMLNode, который возвращает true, если они
есть, и false, если узел пустой. Например:
var xml_doc:XML=new XML("<text>Привет</text>");
trace(xml_doc. firstChild. hasChildNodes()); // Выводит: true
Перед тем как перейти к исследованию дочерних узлов корневого узла, необходимо считать дан-
ные из его атрибутов. Хранятся атрибуты в виде свойств особого объекта, на который указывает
свойство attributes объекта узла. Имена этих свойств будут такие же, как и атрибутов, на основа-нии которых они были созданы. В этом кроется потенциальная опасность. Дело в том, что синтак-
сис имен XML менее строгий, чем ActionScript. Например, в имя может входить двоеточие. Одна-
ко в ActionScript такой идентификатор вызовет сбой при компиляции. Чтобы этого не произошло,
обращаться к описывающим атрибуты свойствам следует не через оператор «.», а посредством
оператора «[]».
Значения у свойств объекта attributes всегда имеют строковый тип.
var xml_doc:XML=new XML("<text id='#1083'>Привет</text>");
trace(xml_doc. firstChild. attributes["id"]); // Выводит: #1083
Если у объекта корневого узла есть дочерние узлы, то их нужно исследовать. Для этого данные
узлы необходимо последовательно перебрать. Имеется два способа сделать это.
• У класса ХМLNode есть свойство childNodes, которое указывает на массив, хранящий ссылки
на объекты всех дочерних узлов данного узла. Ссылки расположены в том же порядке, в кото-
ром теги дочерних узлов прописаны в теге родительского узла. Следовательно, чтобы иссле-
довать все дочерние узлы, следует запустить цикл и перебрать все элементы массива
childNodes:
var xml_doc:XML=new XML("<text><t1/><t2/><t3/></text>");
var ch_nodes:Array=xml_doc. childNodes[0].childNodes;
for (var i=0; i<ch_nodes. length; i++) {
trace(ch_nodes[i].nodeName); // Выводит: t1, t2, t3
}
• Если XML-документ обрабатывается при помощи рекурсивных функций, то применение мас-
сива childNodes не всегда удобно. Эффективный и компактный рекурсивный алгоритм можно
организовать при условии, что от одного дочернего узла можно перейти к другому, не обра-
щаясь к родительскому узлу. В DOM, используемой ActionScript, это вполне ре&пьно благо-
даря наличию свойств previousSibling и nextSibling, а также firstNode и lastNode.
В дереве DOM все объекты, описывающие дочерние узлы некоторого узла, связаны между собой.
Каждый объект знает, какой узел прописан после соответствующего ему узла, а какой — до.
Ссылку на объект узла, следующего за данным узлом, можно получить через свойство nextSibling.
Ссылку на объект, который описывает узел, предшествующий данному, хранит свойство
previousSimbling.
Чтобы начать обход дочерних узлов посредством свойства nextSimbling или previousSimbling,
нужно иметь ссылку на объект первого или последнего узла.
Получить ее можно при помощи свойства firstChild (первый узел) или lastChild (последний узел).
В качестве примера использования рекурсивного обхода дерева DOM приведем функцию obhod(),
подсчитывающую количество узлов в документе. Ее идея проста. Она получает ссылку на узел и
увеличивает значение переменной-счетчика на единицу. Затем она проверяет, есть ли у узла до-
черние узлы. Если они есть, то создается еще одна активация функции и ей передается ссылка на
первый дочерний узел. Далее функция проверяет, имеется ли узел, который был бы прописан по-
сле данного. Если он обнаруживается, то ссылка на него передается новой активации obhod().
var xml_doc:XML=new XML("<text><t1/><data>Привет</data><t3/></text>");
var col:Number=0; // Переменная-счетчик
function obhod(node:XMLNode):Void {
col++;
if (node. hasChildNodes()) {
obhod(node. firstChild);
}
if (node. nextSibling!=null) {
obhod(node. nextSibling); }
}
obhod(xml_doc. firstChild); // Запускаем обход
trace(col); // Выводит: 5
Рекурсия — это чрезвычайно мощный инструмент для обработки XML. Ее нужно использовать, когда структура обрабатываемого документа неизвестна. При этом возникает задача обхода дерева неизвестной степени вложенности, которую довольно проблематично решить без рекурсии. Если же структура документа проста и заранее известна, то для извлечения из него данных лучше огра-ничиться обычными циклами.
Самым важным ограничителем в применении рекурсии для обработки XML-документов является то, что в стеке не может находиться более 255 активаций. Впрочем, это ограничение можно пре-одолеть, изменив тег scriptLimits SWF-файла при помощи утилиты Flasm. Как это делается, пока-жем в главе 20.
При необходимости, можно перейти не только от родительского узла к дочернему, но и наоборот, от дочернего к родительскому. У любого объекта класса XMLNode есть свойство parentNode, ко-торое хранит ссылку на родительский узел. Пример его использования:
var xml_doc:XML=new XML("<text>Привет</text>");
trace(xml_doc. firstChild. firstChiId. parentNode. nodeName); // Выводит: text
После того как ссылка на объект узла будет получена, нужно определить его тип. Как вы помните, в DOM, используемой ActionScript, реализовано всего два типа узлов: ELEMENT и TEXT. Узнать, является узел обычным или текстовым, позволяет свойство nodeType. Оно равно 1, если узел
обычный, и 3, если узел текстовый. Например;
var xml_doc:XML=new XML("<text>Привет</text>");
trace(xml_doc. firstChild. firstChild. nodeType); // Выводит: 3
На первый взгляд значения, которые может принимать свойство nodeType, кажутся очень стран-ными. Почему 1 и 3? Почему не 0 и 1 или 1 и 2? Дело в том, что в «настоящей» DOM, разработан-ной комитетом W3C, не два типа узлов, а 12. Однако анализатор XML Flash-плейера поддерживает только два из них. Для большего же соответствия стандарту номера для типов поддерживаемых узлов nodeType возвращает такие, какие им соответствуют в DOM от W3C.
Если узел относится к типу ELEMENT, то, чтобы понять, какие данные в нем содержатся, следует прочитать его имя. Для этого служит свойство nodeName класса XMLNode, которое возвращает имя узла в форме строки. Если узел является текстовым, то свойство nodeName будет равно null.
var xml_doc:XML=new XML ( "<text></text>" ) ;
trace(xml_doc. firstChild. nodeName); // Выводит: text
Если узел является текстовым, то единственная операция, которая с ним должна быть проведена,
— это считывание содержащегося в нем текста. Выполнить ее позволяет свойство nodeValue клас-
са XMLNode. Если узел относится к типу ELEMENT, а не к TEXT, то свойство nodeValue будет
равно null. Например:
var xml_doc:XML=new XML("<text>Привет</text>");
trace(xml_doc. firstChild. firstChild. nodeValue); // Выводит: Привет
Официально класс XMLNode не поддерживает пространств имен XML. Однако если снять защиту
от перечисления циклом for-in с прототипа этого класса, то можно обнаружить три свойства и два метода, предназначенных, как следует из их названия, для работы с пространствами имен. Немно-го поэкспериментировав, несложно понять назначение каждого из этих недокументированных
элементов. Кратко опишем их (для более полного описания одних лишь экспериментов недоста-точно):
• namespaceURI — свойство, хранящее UR1 пространства имен, к которому относится узел. Как
вы помните, URI прописывается в атрибуте xmlns тега, который является родительским по от-
ношению к данному;
• prefix — возвращает строку с префиксом пространства имен, используемую в имени узла;
• localName — хранит имя узла без префикса (свойство nodeName возвращает имя вместе с
префиксом);
• getPrefixForNamespace() — метод, определяющий префикс пространства имен по его URI;
• getNamespaceForPrefix() — определяет URI пространства имен по префиксу.
Так как описанные методы и свойства являются недокументированными, компилятор о них не знает. Поэтому обращаться к ним следует не через оператор «.», а посредством оператора «[]».
Например:
var xml_text:String="<text xmlns:new='http://www. *****'><new:node/> </text>"
var xml_obj:XML=new XML(xml_text);
var ch_node:XMLNode=xml_obj. firstChild. firstChild;
trace(ch_node["namespaceURI"]); // Выводит: http://www. *****
trace(ch_node["prefix"]); // Выводит: new
trace(ch_node. nodeName); // Выводит: new:node
trace(ch_node["localName"]); // Выводит: node
trace(ch_node["getPrefixForNamespace"]("http://www. *****")»;
// Выводит: new
trace (ch_node["getNarnespaceForPrefix"]("new"));
// Выводит: http://www. *****
17.5.5. Создание и модификация XML-документа
Чтобы создать при помощи ActionScript XML-документ, нужно сформировать описывающее его дерево DOM. Эта задача решается в несколько этапов. На первом этапе следует создать объект
класса XML, который послужит фундаментом для дерева DOM:
var doc:XML=new XML();
Теперь можно начать формирование дерева DOM. Для этого нужно создать объекты класса XMLNode и связать их в нужном порядке. Имеется три способа изготовить объект, описывающий узел.
• Если нужно создать узел типа ELEMENT, то следует использовать метод createElement() клас-са XML. В качестве параметра данный метод принимает строку с именем узла. Обратите вни-мание, что на момент создания узел не связан с каким-либо родительским узлом и не имеет дочерних узлов. Как его встроить в дерево D0M, мы покажем чуть ниже. Например:
var doc:XML=new XML();
var new_node:XMLNode=doc. createElement("data");
• Чтобы создать объект, описывающий текстовый узел, следует обратиться к методу
createTextNode() класса XML. Текст узла передается методу в параметре в виде строки:
var doc:XML=new XML();
var new_text_node:XMLNode=doc. createTextNode("Привет");
• Довольно часто XML-документы содержат несколько экземпляров одного узла, но с разными значениями атрибутов или различными дочерними узлами. В этом случае создавать каждый узел индивидуально нетехнично. Проще задать лишь один узел, а затем просто размножить его копированием. Для этого служит метод cloneNode() класса XMLNode.
У метода cloneNode() имеется два режима работы, определяемых значением параметра. В первом режиме (параметр равен true) узел копируется со всеми дочерними узлами. Во втором режиме (па-раметр равен false) клонируется лишь сам узел, без дочерних узлов. Атрибуты узла копируются в обоих режимах.
var doc:XML=new XML("<doc><text>Привет</text></doc>");
var cloned_node:XMLNode=doc. childNodes[0].childNodes[0].cloneNode(true);
trace(cloned_node); // Выболит: <text>Привет</text>
Если у узла должны быть атрибуты, то соответствующие свойства должны быть созданы у объек-
та, на который указывает свойство attributes:
var doc:XML=new XML();
var new_node:XMLNode=doc. createElement("text");
new_node. attributes. author="Pushkin", new_node. attributes. title="Onegin";
Создав объект узла, его нужно встроить в дерево документа. Для этого служат методы
appendChild() и insertBefore() класса XMLNode. Метод appendChild() используется, если новый
узел должен быть встроен в качестве последнего дочернего узла того узла, через объект которого
был вызван данный метод. Метод appendChild() применяется и в том случае, если последователь-
ность расположения дочерних узлов не имеет значения. В качестве параметра метод appendChild()
принимает описывающий узел объект класса XMLNode. Например:
var doc:XML=new XML();
var node_1:XMLNode=doc. createElement("doc");
var node_2:XMLNode=doc. createElement("text");
var text_node_3:XMLNode=doc. createTextNode("Привет");
node_2.appendChild(text_node_3);
node_1.appendChild(node_2);
doc. appendChild(node_1);
trace(doc); // Выводит: <doc><text>Привет</text></doc>
Обратите внимание, что для создания корневого узла дерева DOM метод appendChild() должен быть применен к объекту класса XML. При формировании же структуры дерева данный метод вы-зывается соответствующими узлами объектами класса XMLNode.
Если последовательность расположения дочерних узлов важна, то вместо метода appendChild()
следует использовать метод insertBefore(newChild, beforeChild), где newChild — описывающий узел объект класса XMLNode, beforeChild — ссылка на объект дочернего узла, перед которым должен быть вставлен данный узел. Например:
var doc:XML=new XML("<doc><tag1/><tag2/><tag3/></doc>");
var new_child:XMLNode=doc. createElement("tag4");
doc. firstChild. insertBefore(new_cnild, doc. firstChild. childNodes[2]);
trace(doc); // Выводит: <doc><tag1/><tag2/><tag4/><tag3/></doc>
При необходимости к XML-документу можно добавить XML-объявление или DTD-объявление.
Для этого служат рассмотренные ранее свойства docTypeDecl и xmlDecl.
17.5.6. Обмен XML-данными с сервером
XML-документ—это просто текстовый файл. Поэтому нет принципиальных различий между пе-редачей данных на сервер (или получением их с него) в формате пар имя-значение и XML. Для этого используются уже хорошо знакомые нам по классу LoadVars элементы: методы send(), load(), sendAndLoad(), getBytesTotal(), gctBytesLoaded(), addRequestHeader(); свойства contentType, loaded; события onData и onLoad. Ввиду того что эти элементы мы изучили весьма подробно, а
также что между их реализациями в классах LoadVars и XML нет существенных различий, по-вторно рассматривать их не будем. Ограничимся приведением некоторых неочевидных фактов, связанных с пересылкой XML-данных.
• Для отправки XML-документа на сервер стоит использовать HTTP-метод POST, но ни в коем случае не GET. Дело в том, что длина URL зачастую ограничена 256 символами, поэтому до-кумент может просто не поместиться. Однако нужно помнить, что применять метод POST можно лишь в том случае, если фильм воспроизводится в браузере. Если же он проигрывается автономным плейером, то метод POST будет недоступен.
• Загрузив XML-документ, Flash-плейер пытается произвести его разбор. По завершении этой попытки возникает событие onLoad. Однако имеется возможность работы с XML-текстом на-прямую. Для этого нужно обратиться к событию on Data, которое возникает непосредственно после того, как заканчивается загрузка документа. Текст документа передается обработчику onData в качестве параметра. Если в коде есть обработчик события onData, то ХМ L-документ не преобразовывается в дерево объектов DOM.
• По умолчанию в качестве заголовка типа содержимого Flash-плейер использует application/x-www-form-urlencoded. Это не всегда приемлемо. Если вы используете серверную технологию, поддерживающую разбор XML-данных, то заголовок по умолчанию следует заменить строкой text/xml. Для этого нужно переопределить свойство contentType.
• Если XML-данные передаются на сервер не в UTF-8, то информацию об этом обязательно сле-дует включить в XML-объявление при помощи атрибута encoding.
Для оперативного обмена XML-данными с сервером нужно использовать класс XMLSocket, кото-рый отлично приспособлен для выполнения работы такого рода. Любой полученный текст переда-ется XML-анализатору по умолчанию. Если преобразование в дерево DOM выполняется успешно, то возникает событие onXML, обработчику которого передается полученный объект класса ХМL.
