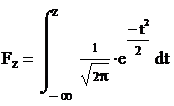Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Формулы, применяемые в Налоговом Аудите.
_________________________________________________________________________
Объем выборки определяется как
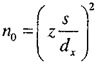 для стоимостных показателей, где:
для стоимостных показателей, где:
n0 – предварительный объем выборки;
s – предварительная оценка стандартной ошибки выборочной средней, среднеквадратичное отклонения или попросту выборочная дисперсия значения средней в совокупности;
z – квантиль нормального распределения, функция нормального распределения, определяемая по таблице значений функции распределения;
dx – приемлемая ошибка, которая соответствует принятому аудиторскому риску, полученному аудитором при предварительном планировании аудита.
При исследовании качественных показателей признак наличия отклонения p в заданном количестве k определяет значение функции биномиального распределения, определяемое по соответствующей таблице. Значение функции биномиального распределения находится так:
При исследовании количественных показателей фигурируют нормированные по s (стандартное отклонение в выборке) отклонения х (здесь х=∑ x(i)) (выборочная сумма) от среднего значения в выборке ![]() , которые обозначаются z и определяются как:
, которые обозначаются z и определяются как:
Функция нормального распределения отклонений z определяется по таблице нормального распределения.
Оценивание при исследовании качественных показателей осуществляется следующим образом. При известном показателе объема выборки n и известном количестве отклонений b определяется вероятность наступления событий p (выявление существенных отклонений в выборочной совокупности, удовлетворяющих принятому уровню доверительной вероятности D).
Для этого используется формула
При заданном уровне надежности D (он равен значению функции биномиального распределения Fk при атрибутивных выборках) – D=Fk по таблице значений функции биномиального распределения определяется расчетный верхний предел точности U.
Оценивание ошибок при исследовании стоимостных показателей производится методом оценивания отношений (относительные ошибки).
При монетарной выборке единиц наблюдения ошибка в расчете на 1 руб. стоимостной характеристики документа составляет
hi= ei / xi.
По выборочным данным находим значения hi и затем их обобщающую оценку
Эту величину можно трактовать как среднюю ошибку в расчете на один рубль стоимостной характеристики единицы наблюдения. В силу этого оценкой ![]() можно воспользоваться для получения точечной оценки суммы ошибок для совокупности:
можно воспользоваться для получения точечной оценки суммы ошибок для совокупности:
Стандартная ошибка выборочной средней получается
Предельную ошибку выборки для средней находим так:
Предельная ошибка для суммы составит
∆s=
Интервальная оценка суммарной ошибки для совокупности
Значение вероятности того, что случайная величина X лежит в интервале А определяется по функции нормального распределения Fz, где z – нормированное отклонение.