

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Министерство образования и науки РФ
Федеральное бюджетное государственное
образовательное учреждение
высшего профессионального образования
«Тульский государственный университет»
Политехнический институт
Кафедра "Автоматизированные станочные системы"
доцент, к. т.н.
МЕТОДИЧЕСКИЕ УКАЗАНИЯ
ПО ВЫПОЛНЕНИЮ ЛАБОРАТОРНОЙ РАБОТЫ №5
по дисциплине
ПРОГРАММИРОВАНИЕ
Направление подготовки:
230100 Информатика и вычислительная техника
Профиль подготовки:
Системы автоматизированного проектирования
Форма обучения – очная, очно-заочная, заочная
Тула 2011 г.
Рассмотрено на заседании кафедры "Автоматизированные станочные системы"
протокол №1 от "31" августа 2011 г.
Зав. кафедрой________________
Содержание
1. Общие сведения о базах данных. 4
2. Проектирование структуры БД.. 5
3. Нормализация структур баз данных. 7
4. Начало работы с MS Access. 10
1.1. Задание на работу. 11
1.2. Порядок выполнения работы.. 11
5. Список использованных источников. 20
1. Общие сведения о базах данных
В любом наборе исходных данных самая надежная величина,
не требующая никакой проверки, является ошибочной.
Из законов Мэрфи
Среда программирования Delphi имеет встроенные и очень удобные средства для работы с реляционными базами данных (БД). Реляционная БД (Рис. 1.1) представляет собой прямоугольную таблицу. Столбцы таблицы называются полями, а строки – записями. Каждое поле имеет уникальное имя и тип данных, который можно хранить в этом поле. Число полей в БД фиксировано, а записи можно добавлять и удалять.
 |
![]()
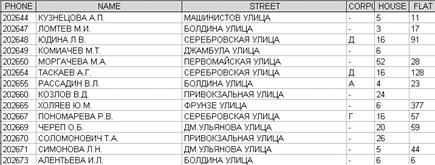
Рис. 1.1 – Типичная реляционная БД.
Существует несколько форматов файлов баз данных. Наиболее часто применяются базы форматов Access (расширение. mdb), Paradox (.db), InterBase (.gdb). Программа, написанная на Delphi, может взаимодействовать как с этими, так и с многими другими видами БД (dBase, FoxPro, Access) на основе единого подхода. С точки зрения написания программы нет никакой разницы, работаете вы с базами Paradox, dBase или Access. Это достигается тем, что операции с БД могут выполняться при помощи специального языка SQL (Structural Query Language). Кроме того, SQL обеспечивает многопользовательский доступ к БД, что автоматически делает вашу программу сетевой.
2. Проектирование структуры БД
Информация, ведущая к обязательному изменению проекта, поступит к автору
этого проекта тогда и только тогда, когда чертежи уже выполнены.
Из законов Мэрфи
Программировать БД "наскоком" невозможно. Сначала необходимо тщательно продумать структуру БД, типы данных полей и организацию связей между таблицами. Ошибки в организации БД, выявленные на поздних стадиях, приведут к необходимости программировать все заново. Помните, что БД важнее, чем работающая с ней программа, поскольку программу изменить гораздо легче, чем базу.
Проектирование БД ставит перед собой следующие цели:
1. Возможность хранения в БД всех необходимых данных.
2. Исключение избыточности данных.
3. Сведение числа хранимых в БД таблиц к минимуму.
4. Нормализация отношений для легкого обновления и удаления записей.
Для выполнения условия хранения всех данных первым шагом проектирования структуры БД является определение всех атрибутов объектов реального мира, информация о которых должна храниться в БД. Набор этих атрибутов для одного и того же объекта может оказаться различным в зависимости от предназначения БД. Например, рассмотрим объект "машиностроительная деталь". Если нам нужно спроектировать базу данных для хранения конструкторской спецификации, в ней достаточно иметь атрибуты "обозначение", "наименование", "куда входит", "имя файла с чертежом". Если же проектируется БД тех же деталей, но уже для решения задачи расчета норм расхода материалов на изготовление деталей, то нам понадобятся атрибуты "длина", "ширина", "высота", "материал", "вид заготовки" и т. д.
При проектировании БД необходимо стремиться к уменьшению избыточности хранимой в ней информации. Это обусловлено следующими причинами:
1. Требование редактируемости БД. Если одна и та же информация хранится в разных местах, то при необходимости ее обновления/удаления придется просмотреть все записи в базе, что неприемлемо.
2. Требование компактности БД. Дублирование информации приводит к разрастанию БД, что не только расходует место в памяти машины, но и замедляет работу СУБД с такой базой. Использование специальных методов нормализации БД, которые будут рассмотрены ниже, приводит к резкому сокращению размеров БД. Например, размер справочника телефонов Тулы в исходном виде составляет 10Мб, а после нормализации - менее 3Мб (обратите внимание, что речь не идет о сжатии информации, а только о ее более рациональной организации).
В качестве примера неправильно спроектированной БД рассмотрим базу, в которой нужно хранить данные о покупателях продукции предприятия. Первая структура БД, которая приходит в голову, выглядит примерно так (Рис. 2.1):
Имя поля | Тип данных | Длина, символов |
PRODUCT | текст | 200 |
FIRM | текст | 200 |
Рис. 2.1 – Первоначальная структура БД.
Здесь в поле PRODUCT хранится наименование изделия, а в поле FIRM - наименование покупателя. Сама БД выглядит примерно следующим образом:
PRODUCT | FIRM |
Привод | ОАО "Электроприбор" |
Задвижка | ООО "Арматура" |
Задвижка | ОАО "Электроприбор" |
Привод | ООО "Арматура" |
Рис. 2.2 – Заполненная БД.
Приведенная здесь структура БД является в корне неверной! Предположим, что в связи с модификацией продукт "Привод" теперь называется "Привод 2.0", а ОАО "Электроприбор" было переименовано в ОАО "Электропривод". Для внесения всего одного фактического изменения придется просмотреть все кортежи в БД (а она может оказаться огромной). Так же обстоит дело с поиском и фильтрацией: если мы хотим узнать, какие клиенты покупают приводы, придется выполнять последовательный поиск во всей БД.
3. Нормализация структур баз данных
Ни одно приспособление универсального кухонного
комбайна не будет работать нормально.
Из законов Мэрфи
Рассмотрим основные способы нормализации БД, т. е. устранения избыточности информации. Будем называть нормализованной такую БД, в которой избыточность информации устранена. В принципе все способы нормализации сводятся к одной идее:
1. Создается универсальная БД, хранящая все атрибуты всех описываемых объектов и не являющаяся нормализованной.
2. Универсальная БД анализируется на предмет необходимости дробления выбранных атрибутов.
3. Выполняется декомпозиция: универсальная БД разбивается на ряд отношений, в каждом из которых дублирование данных исключено.
4. Для сформированных на предыдущем этапе отношений устанавливаются уникальные ключи, обеспечивающие однозначную идентификацию каждой записи в каждом отношении.
5. Между отношениями формируются связи, объединяющие их в законченную БД.
Рассмотрим пример декомпозиции. Пусть нам нужно создать телефонный справочник простейшего вида, содержащий только фамилии абонентов и их телефоны. Универсальная БД (шаг 1) будет иметь следующий вид:
NAME | PHONE |
123456 | |
123457 | |
345678 | |
9876543 |
Рис. 3.1 – Структура телефонного справочника.
Избыточность универсальной БД в данном случае заключается в том, что фамилии в базе повторяются (число однофамильцев огромно). Это приводит к бессмысленному разрастанию базы. С другой стороны, очевидно, что чаще всего совпадают только фамилии, а инициалы остаются различными. Поэтому (шаг 2) сначала нужно выполнить дробление атрибутов путем выделения инициалов в отдельные поля:
NAME | I1 | I2 | PHONE |
Иванов | А | Б | 123456 |
Иванов | В | Г | 123457 |
Петров | Д | Е | 345678 |
Сидоров | М | В | 9876543 |
Рис. 3.2 – Дробление атрибутов.
Смысл дробления - в увеличении схожести записей. Теперь можно перейти к этапу 3 - декомпозиции нашей универсальной БД. В любом случае декомпозиция выполняется по следующему простому правилу:
Атрибут, содержащий повторяющуюся информацию,
выделяется в отдельную таблицу
В нашем случае атрибут NAME следует выделить в отдельную таблицу (обозначим ее Т1, а таблицу с телефонами - Т0).
Таблица Т1 уже является нормализованной: в ней все записи уникальны. Но как же установить соответствие между фамилией абонента и его номером? Сейчас эта связь потеряна. Очевидно, в таблице Т0 отсутствует какой-то важный атрибут.
T1 T0
NAME | I1 | I2 | PHONE | |
Иванов | А | Б | 123456 | |
Петров | В | Г | 123457 | |
Сидоров | Д | Е | 345678 | |
М | В | 9876543 |
Рис. 3.3 – Разделение БД на таблицы.
Для установления связи между двумя отношениями одно из них должно иметь уникальный ключ, а другое - атрибут связи, в котором будут храниться значения ключа.
Итак, первым делом мы зададим в отношении Т1 уникальный ключ по атрибуту NAME. Это означает, что все записи окажутся отсортированными по выбранному полю, что делает их пригодными для быстрого (двоичного) поиска. С каждой записью оказывается связанным некоторое ключевое выражение - например, номер записи в отношении Т1.
Это ключевое выражение мы и будем хранить в атрибуте связи отношения Т0.
Теперь наша БД нормализована: в ней нет дублирующей информации. Обратите внимание, что для удобства атрибут связи и атрибут с уникальными значениями имеют одинаковые имена.
T1 T0
NAME | NAME | I1 | I2 | PHONE | |
Иванов | 1 | А | Б | 123456 | |
Петров | 1 | В | Г | 123457 | |
Сидоров | 2 | Д | Е | 345678 | |
3 | М | В | 9876543 |
Рис. 3.4 – Установление связи между таблицами.
Следует заметить, что декомпозиция должна быть оправдана не только с точки зрения избежания дублирования, но и с точки зрения минимизации размера БД. Так, в рассматриваемом примере значения атрибутов I1 или I2 отношения T0 могут повторяться, но их вынесение в отдельные отношения было бы нерациональным решением. Давайте посчитаем: в отношении Т0 каждое из этих полей занимает 1 байт. Вынос их в отдельные отношения приведет к тому, что ключевое выражение будет иметь длину также 1 байт (число букв, для русского языка равное 32, вполне умещается в 1 байт). Поле связи, соответственно, тоже будет иметь размер в 1 байт. В итоге не имеем никакого выигрыша в размере отношения Т0 и сверх этого получаем еще два отношения. В данном случае подобная оптимизация неоправданна.
И, наконец, последний, завершающий этап создания БД - установление связей между отношениями. Прежде всего, надо выделить главное отношение. Главным отношением будет, как правило, то, которое содержит поля связи. В нашем случае это Т0. Мы должны установить следующее правило: при переходе с записи на запись в Т0 берется ключевое значение из поля Т0àNAME и по нему выполняется двоичный поиск в отношении Т1. Тогда всегда в отношении Т1 текущей будет запись с фамилией, соответствующей текущему номеру телефона в отношении Т0.
Связь может устанавливаться программным способом, а в ряде БД (InterBase, MS Access) связи хранятся непосредственно в самой БД.
БЫЛО:
PRODUCT | FIRM |
Привод | ОАО "Электроприбор" |
Задвижка | ООО "Арматура" |
Задвижка | ОАО "Электроприбор" |
Привод | ООО "Арматура" |
СТАЛО:
PRODUCT | PRODUCT | FIRM | FIRM | ||
Привод | 1 | 1 | ОАО "Электроприбор" | ||
Задвижка | 2 | 2 | ООО "Арматура" | ||
2 | 1 | ||||
1 | 2 |
Рис. 3.5 – Нормализация связи "многий-ко-многим".
Интересный вопрос возникает при удалении записи из нормализованного отношения, не являющего главным. Скажем, оказалось, что всем абонентам по фамилии "Петров" сняли телефоны. Тогда можно удалить соответствующую запись из отношения Т1. При этом правильно спроектированная БД выполнит каскадное удаление: автоматически удалит все записи в Т0, атрибут связи которых ссылался на запись "Петров" в отношении Т1. Каскадное удаление гарантирует отсутствие в главном отношении "потерянных" записей, которые ссылаются в никуда.
Необходимо знать три вида связей между атрибутами двух отношений. Они называются "один-к-одному", "один-ко-многим" и "многий-ко-многим".
Связь "один-к-одному". Между атрибутами А и В существует связь "один к одному", если каждому значению атрибута А соответствует одно и только одно значение атрибута В. Обратное может быть неверно. Именно такой вид связи установлен между атрибутами "Имя абонента" (А) и "Номер телефона" в ненормализованной базе данных (В): каждому абоненту соответствует один и только один телефонный номер.
В случае связи "один-к-одному" нормализация сводится к устранению возможного дублирования информации в атрибуте А, поскольку атрибут В по определению избыточной информации не содержит.
Связь "один-ко-многим": одному значению атрибута А соответствуют одно или несколько значений атрибута В. Это самый распространенный вид связи. В нашем примере, если рассматривать Т1 как главное отношение, атрибут T1àNAME (A) связан связью "один-ко-многим" с атрибутом T0àPHONE (B), поскольку абоненты с разными номерами телефонов могут иметь одинаковые фамилии. Нормализация такой связи заключается в выделении в отдельное отношение атрибута А.
Связь "многий-ко-многим": нескольким значениям атрибута А соответствуют несколько значений атрибута В. Пример такой связи - уже рассматривавшаяся выше база товаров и их покупателей. Один покупатель может покупать несколько разных товаров, а один и тот же товар может продаваться нескольким разным покупателям. Для нормализации БД разбивается на три отношения: нормализованное А, нормализованное В и отношение связи (рис. 7).
4. Начало работы с MS Access
Рассмотрим создание базы данных в широко распространенной СУБД MS Access.
Каждая БД хранится на диске в виде файла с расширением mdb. При запуске СУБД Access появляется меню для работы с компонентами БД. Далее будут рассматриваться следующие:
Таблицы. Основная информация хранится в таблицах. Таблица – совокупность записей. Столбцы в таблице называются полями, а строки – записями. Количество записей в таблице ограничивается емкостью жесткого диска. Допустимое количество полей – 255. Таблиц в БД может быть несколько. Сведения по разным вопросам следует хранить в разных таблицах. Для работы таблицу необходимо открыть. Перед окончанием работы ее следует закрыть, предварительно сохранив все изменения, произведенные в ходе работы.
С таблицами можно работать в двух режимах – таблицы и конструктора. Переход из режима таблицы в режим конструктора таблицы и обратно производится щелчком по кнопке Вид, расположенной на панели инструментов.
Ключевое поле – поле с уникальными записями. Таблицы связываются по ключам; ключ может состоять из одного или несколько полей.
Все объекты БД можно импортировать, т. е. копировать из других БД, а не вводить заново. Если таблицы были связаны в старой БД, то они таким же образом будут связаны и в новой.
В режиме таблицы обычно просматривают, добавляют и изменяют данные. Можно также добавлять или удалять поля, изменять внешний вид таблицы (ширину столбцов, их порядок, вид и цвет шрифта и т. д.). Можно проверить орфографию и напечатать табличные данные, фильтровать и сортировать данные. В режиме конструктора таблицы можно создать новую таблицу или изменить поля старой.
Формы. Форма представляет собой специальный формат экрана, используемый для разных целей, чаще всего для ввода данных в таблицу и просмотра одной записи. Формы позволяют вводить данные, корректировать их, добавлять и удалять записи. Можно создавать формы для работы одновременно с несколькими взаимосвязанными таблицами. Форма, использующая данные из нескольких таблиц, должна быть основана на запросе, включающем данные из этих таблиц.
С применением форм можно представлять записи в удобном для пользователя виде – в виде привычных документов: бланков, ведомостей, справок и т. д. Формы ввода-вывода позволяют вводить данные в базу, просматривать их, изменять значения полей, добавлять и удалять записи.
Все элементы, добавляемые в форму, - поля, надписи, списки, переключатели, кнопки, линии – являются элементами управления. Способ создания элемента управления зависит от того, какой элемент создается: присоединенный, свободны или вычисляемый.
Запросы. Запрос – это инструмент для анализа, выбора и изменения данных. С помощью запросов можно просматривать, анализировать и изменять данные из нескольких таблиц. Запросы используются также в качестве источника данных для форм и отчетов.
Отчеты. Отчет – это гибкое и эффективное средство для организации данных при выводе на печать в том виде, в котором требуется пользователю. С помощью отчета можно расположить информацию на листе в удобном для пользователя виде с любым оформлением. Можно разработать отчет самостоятельно с помощью конструктора, использовать готовые варианты оформления (автоотчеты) или создать отчет с помощью мастера.
Макросы и модули. Макросом называют набор из одной или более макрокоманд, выполняющих определенные операции, такие, как открытие форм или печать отчетов. Макросы могут быть полезны для автоматизации часто выполняемых задач. Модуль – это программа на языке Access Basic.
1.2. Задание на работу
3.1. Проектирование структуры БД. Создать БД, состоящую из трех таблиц: Список, Группы и Личные данные.
3.2. Конструирование пустых таблиц БД. Новые таблицы Личные данные, Список и Группы создать с помощью Мастера таблиц.
3.3. Создание схемы БД: В данном случае таблицы Группы и Список объединены связью "Один-ко-многим", таблицы Список и Личные данные – связью "Один-к-одному". Таблицы Группы и Личные данные прямо не связаны.
3.4. Ввод данных в таблицу. Создать форму для ввода данных.
1.3. Порядок выполнения работы
1) Вызвать программу Access. При этом откроется окно системы управления БД, в котором появится меню, представленное на Рис. 4.1) Поставить переключатель Новая база данных и нажать ОК. Появится диалоговое окно, представленное на рис. 2. В поле Имя файла в качестве имени БД введите произвольное название.
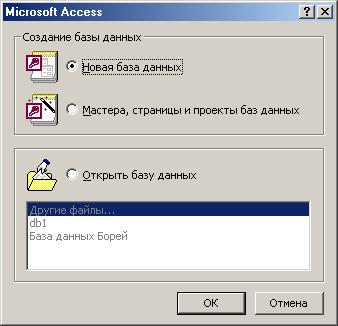
Рис. 4.1 - Окно запуска СУБД Access.
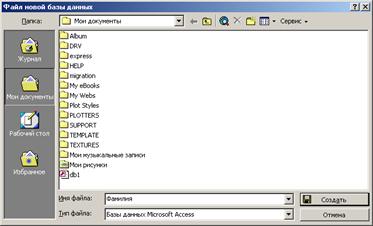
Рис. 4.2 - Окно ввода имени БД.
(Рис. 4.2) Выбрать тип создаваемого документа: Таблица в режиме конструктора (Рис. 4.3). Выбрать действие создать.
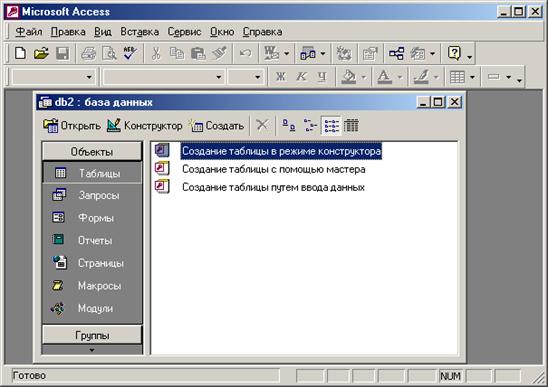
Рис. 4.3 - Выбор объекта
В следующем диалоговом окне выбрать режим Конструктор (Рис. 4.4). Введите в верхней левой клетке имя поля: Фамилия и нажмите клавишу Enter (Рис. 4.5). В соседней клетке появится тип данных, по умолчания он задан как Текстовый. Любой другой тип выбирается с помощью ниспадающего меню.
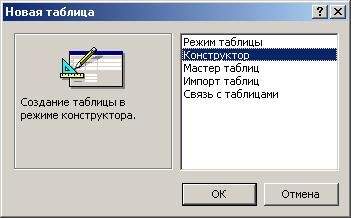
Рис. 4.4 - Выбор способа задания параметров объекта
2) Создать структуру таблиц Список и Группы, не заполняя информацию. При этом поле Группа в таблице Список должно заполняться из таблицы Группы (Рис. 4.5).
Таблица 1. Содержимое таблицы Группы
Группа | Преподаватель |
620281 | |
620481 | |
621881 | |
622181 |
Таблица 2. Содержимое таблицы Список
Код | Фамилия | Имя | Отчество | Год | Специальность | Группа |
1 | Иванникова | Анна | Ивановна | 1991 | САПР | 622181 |
2 | Баранова | Ирина | Алексеевна | 1990 | САПР | 622181 |
3 | Корнилова | Ольга | Владимировна | 1991 | Станки | 620481 |
4 | Воробьев | Алексей | Петрович | 1990 | САПР | 622181 |
5 | Воробьев | Алексей | Иванович | 1990 | Станки | 620481 |
6 | Скоркин | Александр | Евгеньевич | 1991 | САПР | 622181 |
7 | Володина | Анна | Алексеевна | 1990 | САПР | 622181 |
8 | Воробьев | Олег | Григорьевич | 1991 | Станки | 620481 |
9 | Новоселов | Алексей | Антонович | 1990 | Станки | 620481 |
10 | Александрова | Елена | Алексеевна | 1990 | САПР | 622181 |
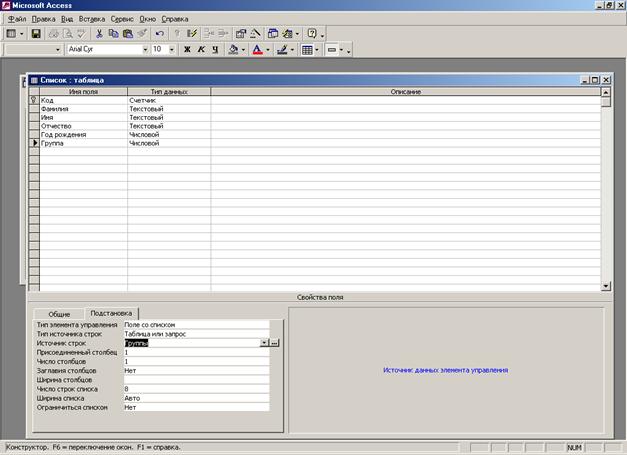
Рис. 4.5 – Привязка значений поля Группа в таблице Список со
значениями поля Группа в таблицы Группы
Сохранить и закрыть таблицу.
Р.S. Чтобы нумерация индекса после удаления данных из таблицы снова началась с 1, выполните команду Сервис-Служебные программы-Сжать и восстановить базу данных. Подождите некоторое время, чтобы программа отработала.
3) Используя Мастер таблиц, создать таблицу Личные данные с ключевым полем.
3.1) Выбрать закладку Таблица.
3.2) Щелкнуть мышкой по кнопке Создать. В результате перейдем к работе со следующим диалоговым окном: Новая таблица. Выбрать Мастер таблиц и щелкнуть по клавише ОК. Появится диалоговое окно, представленное на Рис. 4.6.
3.3) В этом окне следует выбрать: в поле Образцы таблиц – поле Студенты; в поле Образцы полей – поля КодСтудента, Адрес, НомерТелефона, щелкая после каждого выбора по кнопке ![]() . Эти поля попадут в Поля новой таблицы. Щелкните по кнопке Далее.
. Эти поля попадут в Поля новой таблицы. Щелкните по кнопке Далее.
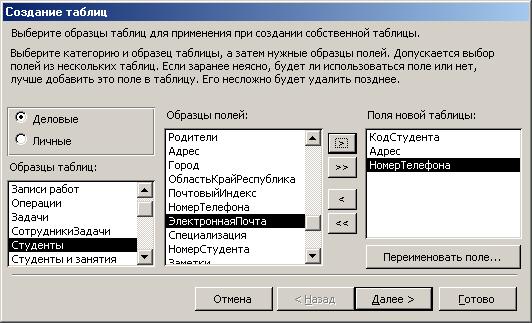
Рис. 4.6 – Мастер таблиц
3.4) В диалоговом окне задайте имя новой таблицы Личные данные. Оставьте автоматический выбор ключа. Щелкните по клавише Далее.
Замечание. Access проверит связи данной таблицы с другими таблицами. Так как связи еще не установлены, то они не будут найдены автоматически. В этот момент можно установить новые связи, но мы пока этого делать не будем.
3.5) Щелкните по клавише Далее.
3.6) После появления вопроса о действиях выбирайте ввод в режиме таблицы, но можно изготовить и форму. Щелкните по кнопке Готово. Вы попадете в пустую таблицу, у которой есть поля, но отсутствуют записи.
3.7) Добавьте в таблицу Личные данные еще три поля Основы ТМС, Информатика и Автоматизированные БД и БЗ c типом данных – числовой.
3.8) Сохраните таблицу.
3.9) Перейдите в режим таблицы.
3.10) Закройте таблицу, предварительно сохранив ее. В результате вы получите три таблицы, две из которых связаны, а третья нет.
4) Создание схемы данных.
4.1) Щелкните по кнопке ![]() - Схема данных.
- Схема данных.
4.2) Щелкните по кнопке ![]() - Добавить таблицу. В появившемся окне Добавление таблицы выделите таблицу Личные данные и щелкните по кнопке Добавить. Щелкните по кнопке Закрыть окна Добавление таблицы.
- Добавить таблицу. В появившемся окне Добавление таблицы выделите таблицу Личные данные и щелкните по кнопке Добавить. Щелкните по кнопке Закрыть окна Добавление таблицы.
4.3) Поставьте мышку на имя поля Кодстудента в таблице Личные данные и, не отпуская кнопку мыши, перетащите ее на поле Код в таблице Список. Отпустите мышь. Появится диалоговое окно Изменение связей.
4.4) Включите значок Обеспечение целостности данных. Это невозможно сделать, если типы обоих полей заданы не одинаково.
4.5) Щелкните по кнопке Создать. Появится связь "Один-к-одному". Схема данных представлена на Рис. 4.7.
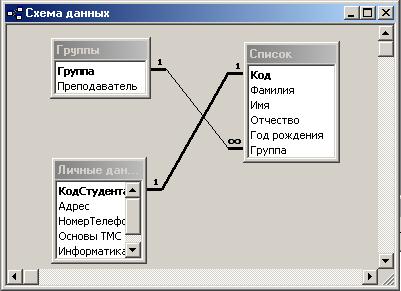
Рис. 4.7 – Схема данных со связью
4.6) Закройте схему данных, сохранив ее.
Пояснение. Теперь встает задача ввода записей одновременно в разные таблицы: Список и Личные данные. ФИО мы храним в одной таблице, а адрес и номер телефона – в другой. Можно попробовать ввести значения в каждую таблицу отдельно, но удобнее видеть клетки обеих таблиц для ввода данных одновременно. Эту задачу легко решить вводом значений через специально созданную форму, в которой присутствуют поля всех необходимых таблиц. Данные вводим в форму, а в результате заполняются таблицы.
5) Создать форму для ввода данных.
5.1) В окне базы данных выбрать закладку Формы и пункт Создание формы с помощью мастера.
5.2) Появится окно создания форм, представленное на Рис. 4.8.
5.3) Выберите все поля из таблицы Список и все поля – из таблицы Личные данные. Для этого выберите имя таблицы Список в поле Таблицы и запросы. В результате появится список полей в окне Доступные поля. Щелкните по кнопке ![]() , которая переносит все поля списка. Затем выберите имя таблицы Личные данные в поле Таблицы и запросы и вновь щелкните по кнопке
, которая переносит все поля списка. Затем выберите имя таблицы Личные данные в поле Таблицы и запросы и вновь щелкните по кнопке ![]() .
.
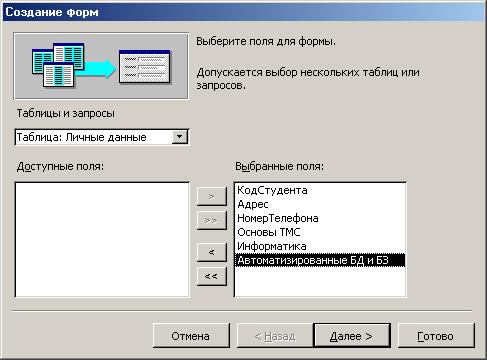
Рис. 4.8 – Окно создания форм
5.4) Щелкните по кнопке Далее.
5.5) Оставьте внешний вид в один столбец (выбран по умолчанию).
5.6) Щелкните по кнопке Далее.
5.7) Выберите требуемый стиль (например, Стандартный). Щелкните по кнопке Далее.
5.8) Задайте имя формы: Общая форма. Щелкните по кнопке Готово. В результате вы получите форму, в которой можно менять существующие данные и вводить новые значения. Эти значения будут попадать в ту таблицу, в которую нужно (часть значений – в одну таблицу, часть – в другую).
6) Заполнить таблицы данными.
Замечание: Поля Код и КодСтудента заполняются автоматически.
Данные таблицы Список приведены в таблице 2, а таблицы Личные данные – в таблице 3.
Таблица 3. Содержимое таблицы Личные данные
Код Студента | Адрес | Номер телефона | Основы ТМС | Информатика | Автоматизированные БД и БЗ |
1 | пр. Ленинский 71 – 45 | 4 | 5 | 3 | |
2 | – 1 | 4 | 5 | 5 | |
3 | пр. Красноармейский 100 – 25 | 4 | 5 | 4 | |
4 | – 43 | 3 | 5 | 3 | |
5 | 3 | 5 | 4 | ||
6 | – 17 | 3 | 5 | 5 | |
7 | 4 | 5 | 5 | ||
8 | пер. Косой 2 | 3 | 4 | 5 | |
9 | 03 | 5 | 4 | 3 | |
10 | площадь Гримма 12 | 3 | 5 | 5 |
6.1) Закройте форму, предварительно сохранив ее.
6.2) Перейдите на закладку Таблицы.
6.3) Откройте таблицу Список и убедитесь, что в них появились данные. Закройте таблицу.
6.4) Откройте таблицу Личные данные и убедитесь, что в них появились данные. Закройте таблицу.
7) Добавить новое поле Портрет (рисунки или фотографии) в таблицу Список.
Пояснение. Возможен вариант, когда появляется необходимость добавить новые поля в существующую таблицу. Это можно сделать, например, описанным ниже способом.
7.1) Открыть таблицу Список.
7.2) Перейти в режим Конструктора.
7.3) Добавить еще одно поле (введите имя поля ниже поля Группа), имя которого Портрет, тип данных – Поле объекта OLE, общие свойства поля оставить по умолчанию.
7.4) Сохранить.
7.5) Перейти в режим таблицы.
7.6) Щелкнуть по клетке, где должно быть значение поля Портрет.
7.7) Выполнить команду Вставка-Объект-Точечный рисунок-Paintbrush-OK.
7.8) Нарисовать Автопортрет.
7.9) Щелкнуть по кнопке ![]() в правом верхнем углу окна рисунка, в результате чего вы вернетесь в таблицу. Рисунок будет обозначен словами. Чтобы увидеть портрет, дважды щелкните мышкой по названию рисунка, возвращаясь в программу, где изготовлен портрет.
в правом верхнем углу окна рисунка, в результате чего вы вернетесь в таблицу. Рисунок будет обозначен словами. Чтобы увидеть портрет, дважды щелкните мышкой по названию рисунка, возвращаясь в программу, где изготовлен портрет.
Самостоятельное задание. Нарисуйте портреты всех участников из таблицы Список.
Справочная информация. Выражения в фильтре могут состоять из точных значений, которые Access использует для сравнения в том виде, в котором они вводятся. Числа вводятся без ограничителей, например, 22. Текст должен быть заключен в кавычки, например, "Александров". Даты ограничиваются символами #, например, #10/01/99#. Элементы выражения могут быть связаны операторами:
арифметическими: *, +, -, /, ^;
логическими AND, NOT, OR;
сравнения:<,<=,>,>=,=,<>;
Like – для использования логики замены в выражениях;
In – для определения, содержится ли элемент данных в списке значений;
Between…And – для выбора значений из определенного интервала.
8) Использование фильтра.
8.1) Щелкнуть по кнопке ![]() - Изменить фильтр. Появится окно выбора, представленное на Рис. 4.9
- Изменить фильтр. Появится окно выбора, представленное на Рис. 4.9
8.2) Щелкните мышью по полю Год рождения. У активного поля появится стрелка выбора.

Рис. 4.9 – Окно выбора фильтра
8.3) Выберите Год рождения 1990 и щелкните по кнопке ![]() - Применить фильтр. Вы автоматически попадете в таблицу, в которой будут только выбранные записи.
- Применить фильтр. Вы автоматически попадете в таблицу, в которой будут только выбранные записи.
8.4) Отмените выбор. Для этого необходимо отжать эту же кнопку, которая теперь называется Удалить фильтр.
8.5) Щелкните по кнопке ![]() - Изменить фильтр.
- Изменить фильтр.
8.6) Удалите все в поле Год рождения, выделив значение и нажав клавишу Delete.
8.7) Измените фильтр так, чтобы в таблице были видны только студенты 620года рождения (одновременный запрос в двух полях – Группа и Год рождения).
8.8) Щелкните по кнопке ![]() - Применить фильтр.
- Применить фильтр.
8.9) Измените фильтр. Допустимо указывать границы изменения значений. В поле Год рождения наберите >1990. Щелкнув по кнопке Применить фильтр, вы получите таблицу, в которой присутствуют записи с годами рождения больше 1990.
8.10) Чтобы получить записи студентов, у которых фамилии начинаются на букву "В", в соответствующем поле наберите Like "В*" (В – в данном случае русская буква).
8.11) Запрос Not"В*" будет означать все записи, кроме указанных (в данном случае все записи, у которых фамилии не начинаются на букву "В"). Составьте этот запрос, щелкнув по кнопке ![]() - Применить фильтр.
- Применить фильтр.
Самостоятельное задание:
Выберите студентов всех групп, кроме 620281.
Выберите всех студентов группы фамилии которых начинаются на "Б".
Выберите студентов из групп 620481 и 620281 (запрос 620481 OR 620281).
Отмените все запросы.
Замечание. Кнопка ![]() - Фильтр по выделенному позволяет оставить видными в таблице только те записи, в которых есть предварительно выделенный элемент.
- Фильтр по выделенному позволяет оставить видными в таблице только те записи, в которых есть предварительно выделенный элемент.
5. Список использованных источников
1. Борри, Borrie H. Руководство разработчика баз данных: пер. с англ. / Х. Борри .— 2-е изд.,испр. — СПб. : БХВ-Петербург, 2007 .— 1104с. : ил. — (В подлиннике) .— Парал. тит. л.англ. — ISBN -757-6(рус.)
2. Золотова, С. И. Практикум по Access : подготовительный курс, предваряющий более глубокое изучение технологии баз данных / .— М. : Финансы и статистика, 2007 .— 144с. : ил. — (Диалог с компьютером) .— ISBN -7
Мак-Федрис Формы, отчеты и запросы в Microsoft Access 2003 / П. Мак-Федрис; пер. с англ. и ред. .— М.;СПб.; Киев : Вильямс, 2005 .— 416с. : ил. — (Бизнес-решения) .— Парал. тит. л.англ. — ISBN -0(рус.)
Советов, Б. Я. Базы данных. Теория и практика: учебник для вузов / , , .— М.: Высш. шк., 2005 .— 463с. — Библиогр. в конце кн. — ISBN -4 /в пер./
О'Хара, Ш. Абсолютно ясно о Microsoft Office Access 2003 : [учеб. пособие] / Ш. О'Хара;пер. с англ. .— М. : Триумф, 2005.— 240с. : ил. — (Визуальный курс) .— ISBN -7
