
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Индексная концепция машинного обучения
, независимый исследователь, Санкт-Петербург
*****@***ru
Аннотация
Предлагается индексная концепция машинного обучения, основанная на двухуровневой метрике соответствия объекта и класса. Находятся оценки вероятности того, что индексы значения признаков объекта и объект в целом принадлежат каждому из заданных классов. Правило разделения на классы следует из метода максимума правдоподобия. Концепцию реализует универсальный и простейший алгоритм, приводящий к робастным результатам.
Введение
Характерной особенностью биологических систем является многоступенчатая схема оценки многочисленных характеристик внешнего воздействия, стимула, для его распознавания и классификации [1]. В задачах машинного обучения каждый объект и его признаки является аналогом стимула и его характеристик соответственно. Указанную особенность отражает двухуровневая метрика, согласно которой для каждого объекта определяется степень соответствия определенному классу сначала его признаков, а затем всего их набора. Существующие методы машинного обучения учитывают взаимосвязь признаков одного объекта только в рамках искусственно введенного понятия близости объектов в одном из геометрических пространств [2,3].
Метрика предполагает, что значение любого признака можно описать индексом, который однозначно определяет величину или интервал значений признака в выборке [4]. Она вводит вероятностную меру для оценки степени соответствия (близости) объекта и класса в виде измерения вероятности того, что индексы признака объекта и объект в целом принадлежат определенному классу. В отличие от других вероятностных методов здесь оцениваются статистические характеристики каждого объекта [5,6].
Метрика позволяет придать модульный характер решению достаточно широкого круга задач машинного обучения. Эффективность метрики была подтверждена при решении нескольких задач из репозитория [7].
Расчетный модуль метрики
Предполагается, что в любой задаче машинного обучения можно выделить общую подзадачу, решение которой дает расчетный модуль метрики. Эта подзадача имеет вид:
Пусть из бесконечного счетного множества![]() объектов
объектов ![]() случайным образом получена обучающая выборка
случайным образом получена обучающая выборка ![]() ,
, 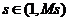 - номер объекта. Каждый объект характеризуются признаками
- номер объекта. Каждый объект характеризуются признаками 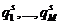 . Известна матрица данных
. Известна матрица данных ![]() и списки
и списки ![]() номеров объектов для непересекающихся классов
номеров объектов для непересекающихся классов ![]() . Требуется найти правило, в соответствии с которым объекты были разделены на классы.
. Требуется найти правило, в соответствии с которым объекты были разделены на классы.
Перейдем к дискретному описанию значений признаков 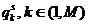 с помощью индексов
с помощью индексов 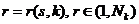 . Для порядковых, символьных или номинальных признаков значения
. Для порядковых, символьных или номинальных признаков значения ![]() и
и ![]() определяются матрицей данных в соответствие с перечнем возможных значений признака. В случае количественных признаков для вычисления индексов используем процедуру квантования, с помощью которой разделим весь диапазон значений признака в выборке на
определяются матрицей данных в соответствие с перечнем возможных значений признака. В случае количественных признаков для вычисления индексов используем процедуру квантования, с помощью которой разделим весь диапазон значений признака в выборке на ![]() интервалов равной длины.
интервалов равной длины.
Выполнив эти преобразования, найдем взаимно однозначные отображения ![]() и матрицы
и матрицы ![]() .
.
Очевидно, что объекты отдельных классов обладают присущими только им свойствами, которые определяются набором значений признаков. Поэтому существует некоторая функция 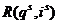 , связывающая свойства объекта и его класс
, связывающая свойства объекта и его класс ![]() , которая равна некоторой константе
, которая равна некоторой константе ![]() :
:
![]() .
.
Эти соотношения выполняется также для объектов ![]() , образующих подмножество
, образующих подмножество ![]() . Предельно близкими, неразличимыми будут объекты, для которых индексы всех признаков будут равными. Однако для большей части объектов класса
. Предельно близкими, неразличимыми будут объекты, для которых индексы всех признаков будут равными. Однако для большей части объектов класса 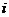 индексы будут совпадать только для отдельных признаков. Отличить такие объекты от объектов других классов, имеющих те же значения индексов, можно только по статистическим характеристикам признаков исходя из предположения об их равенстве для подмножеств
индексы будут совпадать только для отдельных признаков. Отличить такие объекты от объектов других классов, имеющих те же значения индексов, можно только по статистическим характеристикам признаков исходя из предположения об их равенстве для подмножеств ![]() и
и ![]() .
.
Отсюда следует, что признаки объектов одного класса имеют одинаковые статистические характеристики индексов. Поэтому можно определить особенности признаков объектов одного класса, которые являются близкими по любому признаку.
Обозначим через ![]() списки номеров объектов
списки номеров объектов ![]() , которые при данном и
, которые при данном и ![]() имеют одинаковые значения индексов
имеют одинаковые значения индексов ![]() . Эти списки находим из матрицы
. Эти списки находим из матрицы ![]() . Найдем также списки
. Найдем также списки ![]() , соответствующие объедению по всем списков
, соответствующие объедению по всем списков ![]() . Обозначим через
. Обозначим через ![]() ,
, ![]() и
и ![]() количество объектов в классе , а также в списках
количество объектов в классе , а также в списках ![]() и
и ![]() соответственно.
соответственно.
Величины ![]() и
и ![]() представляют собой частоты индексов
представляют собой частоты индексов ![]() для
для ![]() – го признака объекта
– го признака объекта ![]() , вычисленные относительно общего числа объектов класса и объектов всех классов, имеющих те же значения индекса, соответственно. Они дают оценки для условной вероятности
, вычисленные относительно общего числа объектов класса и объектов всех классов, имеющих те же значения индекса, соответственно. Они дают оценки для условной вероятности ![]() .
.
Согласно формуле полной вероятности получим:
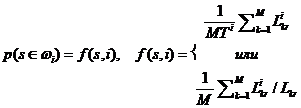 (1)
(1)
Значение ![]() равно средней частоте индекса
равно средней частоте индекса 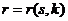 для всех признаков объекта
для всех признаков объекта ![]() . На основании метода максимума правдоподобия получим расчетную оценку
. На основании метода максимума правдоподобия получим расчетную оценку ![]() для величины
для величины ![]() :
:
![]() . (2)
. (2)
В этой формуле функция ![]() играет роль некоторого условного измерителя, эффективность которого зависит от свойств выборки. В зависимости от них можно использовать в (2) один из указанных вариантов формулы (1).
играет роль некоторого условного измерителя, эффективность которого зависит от свойств выборки. В зависимости от них можно использовать в (2) один из указанных вариантов формулы (1).
Если ![]() при
при ![]() , то, очевидно, обучение было успешным. Точность решения будем измерять частотами ошибок
, то, очевидно, обучение было успешным. Точность решения будем измерять частотами ошибок ![]() и
и ![]() , равных отношению числа случаев невыполнения указанного соотношения к общему числу объектов и числу объектов класса
, равных отношению числа случаев невыполнения указанного соотношения к общему числу объектов и числу объектов класса ![]() соответственно.
соответственно.
Рис. 1 Изменение частоты ошибок ![]() для задачи «Glass».
для задачи «Glass».
 |
Рассмотрим случай, когда все признаки являются количественными, а число вариантов индексов при всех
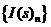 . Вероятностная сходимость на множестве
. Вероятностная сходимость на множестве Задача классификации
Рассмотрим применение модуля для решения следующей типовой задачи классификации (обучения с учителем). Задана обучающая выборка в виде указанной выше выборки ![]() , а также тестируемая выборка
, а также тестируемая выборка ![]() . Требуется определить классы объектов выборки
. Требуется определить классы объектов выборки ![]() .
.
Обозначим через ![]() списки номеров объектов
списки номеров объектов 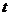 выборки
выборки ![]() . Поскольку
. Поскольку 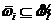 , то статистические характеристики индексов признаков объектов, входящих в списки
, то статистические характеристики индексов признаков объектов, входящих в списки ![]() и
и ![]() , будут равными, если признаки проиндексированы по единым шкалам.
, будут равными, если признаки проиндексированы по единым шкалам.
Поэтому матрицу ![]() будем вычислять для объединенного множества
будем вычислять для объединенного множества ![]() . Поскольку для объектов множества
. Поскольку для объектов множества ![]() параметр
параметр ![]() , то
, то ![]() . Значение
. Значение 
![]() при любом
при любом ![]() находится согласно (2), где
находится согласно (2), где ![]() вычисляется для соответствующего набора значений
вычисляется для соответствующего набора значений ![]() при
при 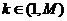 .
.
Укажем некоторые особенности алгоритма. Вычисления практически сводятся к подсчету количества объектов, обладающих равными индексами для отдельных признаков. Алгоритм не относится к группе «жадных», так как результаты расчетов не зависят от последовательности расположения объектов в выборке.
Метрика дает робастную оценку величины ![]() , поскольку при ее вычислении использует группировку объектов по отдельным признакам, что нивелирует влияние резко выделяющихся их значений [8]. Отметим также, что при определении индексов обучающей выборки предусматривается учет объектов тестируемой выборки. Поэтому
, поскольку при ее вычислении использует группировку объектов по отдельным признакам, что нивелирует влияние резко выделяющихся их значений [8]. Отметим также, что при определении индексов обучающей выборки предусматривается учет объектов тестируемой выборки. Поэтому ![]() в определенной мере учитывает ее особенности, что ведет к снижению эффекта переобучения.
в определенной мере учитывает ее особенности, что ведет к снижению эффекта переобучения.
Задача кластеризации
Рассмотрим следующую задачу кластеризации (обучения без учителя). Задана обучающая выборка в виде приведенного выше множества ![]() , но с неизвестными списками
, но с неизвестными списками ![]() . Требуется разбить выборку на
. Требуется разбить выборку на ![]() непересекающихся классов.
непересекающихся классов.
Будем использовать метод последовательных приближений, считая известными на каждом шаге списки, кластеры, ![]() . Согласно формулам (1), (2) найдем расчетное значение класса
. Согласно формулам (1), (2) найдем расчетное значение класса ![]() для всех объектов . Если при
для всех объектов . Если при 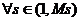 окажется, что
окажется, что 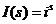 , то классы всех объектов определены правильно и рассматриваемое приближение является окончательным. Если это соотношение не выполняется для каких-то объектов, то эти объекты нужно перенести из соответствующего списка и выполнить следующее приближение. Однако предварительно следует выполнить анализ, чтобы решить, достаточна ли точность результатов, достигнутых на рассматриваемом шаге [9].
, то классы всех объектов определены правильно и рассматриваемое приближение является окончательным. Если это соотношение не выполняется для каких-то объектов, то эти объекты нужно перенести из соответствующего списка и выполнить следующее приближение. Однако предварительно следует выполнить анализ, чтобы решить, достаточна ли точность результатов, достигнутых на рассматриваемом шаге [9].
Примем во внимание следующие моменты. Задача кластеризации не имеет единственного решения. С другой стороны, величина ![]() дает оценку случайной величине. Ее значение является детерминированным, если среди признаков нет признаков количественного типа. В противном случае
дает оценку случайной величине. Ее значение является детерминированным, если среди признаков нет признаков количественного типа. В противном случае ![]() является случайной величиной и при любом варианте разбивки выборки на кластеры можно добиться
является случайной величиной и при любом варианте разбивки выборки на кластеры можно добиться ![]() путем увеличения
путем увеличения ![]() . Однако, возрастание
. Однако, возрастание ![]() ведет к повышению роли ошибок измерения и соответствующему снижению надежности результатов.
ведет к повышению роли ошибок измерения и соответствующему снижению надежности результатов.
Поэтому в общем случае задача сводится к поиску приемлемых для данной задачи решений, которые характеризуются допустимым количеством ошибок при выполнении соотношения и зависят от особенностей задачи.
На первом шаге кластеры формируются следующим образом. Каждый из них будет состоять из примерно равного количества объектов ![]() . В кластер
. В кластер ![]() войдут объекты с номерами
войдут объекты с номерами ![]() , последующие
, последующие ![]() объектов войдут в состав
объектов войдут в состав ![]() , и так далее (при сохранении общего числа объектов).
, и так далее (при сохранении общего числа объектов).
Приводятся результаты решения нескольких частных задач классификации и кластеризации.
Заключение
Индексная концепция машинного обучения основана на двухуровневой метрике соответствия объекта и класса. Она относится к выборкам, состоящим из объектов непересекающихся классов, признаки которых являются количественными или их можно описать элементами конечных множеств. Применение метрики придает модульный характер решению задач машинного обучения. Вычисления практически сводятся к подсчету количества объектов с равными индексами для каждого признака и класса.
Представляется, что новая концепция найдет широкое применение при разработке программных комплексов и получит аппаратную реализацию.
Литература
1. Шац в самоорганизующейся системе. Новые концепции и методы машинного обучения. – Саарбрюкен:. LAP LAMBERT Academic Publishing, 2013, P.105.
2. Hastie, T., Tibshirani R., Friedman J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. - 2nd ed. - Springer-Verlag, 2009, P. 764.
3. и др. Прикладная статистика: Классификация и снижение размерности: Справочное издание. М: Финансы и статистика. 1989. С. 607.
4. Шац модель самоорганизующейся системы // Стохастическая оптимизация в информатике, 2012, Т. 8, С. , http://www. math. *****/user/gran/soi8/Shats8.pdf.
5. , Червоненкис распознавания образов (статистические проблемы обучения).- М.: Наука, 1974. С. 416.
6. Webb J. I., Boughton. R.J., Wang Z. Not So Naive Bayes: Aggregating One-Dependence Estimators // Machine Learning, 2005, Vol. 58, P. 5–24.
7. Asuncion A., Newman D. J. (2007). UCI Machine Learning Repository. Irvine CA: University of California, School of Information and Computer Science.
8. Робастность в статистике. - М.: Мир, 1984, С. 303.
9. Вапник зависимости по эмпирическим данным.- М: Наука. 1979. С. 448.
