

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Практическая работа 3
Вычисление точечных оценок в Excel
Вычисление исправленной дисперсии.
Величина

является несмещённой точечной оценкой для дисперсии случайной величины, и такую оценку называют исправленной дисперсией. Для вычисления выборочного значения этой оценки можно использовать статистическую функцию функцию Excel ДИСП, обращение к которой имеет вид:
=ДИСП(арг1; арг2; …; арг30),
где арг1; арг2; …; арг30 – числа или адреса ячеек, содержащих числовые величины.
Пример 1
При изменении диаметра валика после шлифовки была получена следующая выборка (объемом n = 55):
2.2 2
1.4 1
1.7 2
1.7 2
1.7 1
1.2 2
1.8 2
1.8 1
По выборке вычислить оценку
Решение. Первоначально, начиная с ячейки А3, введем в столбец А 55 элементов выборки (рис. 1). Затем, используя функции КВАДРОТКЛ, ДИСП (как показано на рис. 3), вычислим оценку. Видно ожидаемое совпадение двух вычисленных значений.

Рисунок 1 Вычисление исправленной дисперсии
Вычисление оценок максимального правдоподобия
В общем случае не удается получить простых соотношений и оценки вычисляются непосредственным определением точек максимума функционала правдоподобия, т. е. необходимо решить оптимизационную задачу.
Для решения такой задачи в Excel есть команда Поиск решения пункта меню Сервис. Эта команда позволяет решать не только задачи безусловной оптимизации, но и задачи условной оптимизации, т. е. когда ищется максимум функционала с учетом дополнительных ограничений на значения искомых оценок. Например, значение дисперсии ![]() не может быть отрицательным.
не может быть отрицательным.
Применение команды Поиск решения для вычисления оценок максимального правдоподобия покажем на следующем примере.
♦ Пример 2. По выборке примера 1 вычислить оценки максимального правдоподобия для математического ожидания a и дисперсии σ 2 из условия максимума функционала правдоподобия вида:

предполагая при этом, что выборка порождена случайной величиной, подчиняющейся нормальному распределению.
Решение. Первоначально, начиная с ячейки А3, введем в столбец А 55 элементов выборки (диапазон А3:А57). Затем в ячейку С8 занесем произвольное значение a (например, 10), в ячейку D8 – значение σ (например, значение 4 > 0), в ячейке Е8 вычислим σ 2 .
В ячейках В3:В57 запрограммируем вычисление разностей![]() (рис. 3). В ячейке С5 запрограммируем вычисление величины функционала . В верхней части документа на рис.2 показана запрограммированная формула.
(рис. 3). В ячейке С5 запрограммируем вычисление величины функционала . В верхней части документа на рис.2 показана запрограммированная формула. 
Рисунок 2 Подготовка рабочего листа
После этих подготовительных операций можно перейти к выполнению команды Поиск решения. Для этого необходимо обратиться к пункту основного меню Сервис и в появившемся меню щелкнуть мышью на команде Поиск решения. Затем в появившемся диалоговом окне выполнить следующие действия (см. рис. 3): 
Рисунок 3 Задание параметров команды Поиск решения
· в поле ввода Установить целевую ячейку: ввести адрес ячейки, в которой вычисляется значение минимизируемого функционала (в нашем примере С5);
· включить опцию Равной: максимальному значению (ищутся
значения, при которых функционал достигает максимального значения);
· в поле Изменяя ячейки: ввести адреса ячеек, в которых находятся значения искомых оценок (в нашем примере это ячейки С8:D8);
щелкнув мышью на кнопке Добавить, сформировать ограничения на значения искомых оценок (в нашем примере это требование σ ≥ 0.0 чтобы ln(σ ) не был равен –∞).

Рисунок 4 Результаты выполнения команды Поиск решения
Из рис. 4 видно, что вычисленные значения оценок находятся в ячейках С8, D8 и равны а = 17.907, σ = 2.933. Ячейка С5 содержит значение максимизируемого функционала, равное –137.22.
Сравнивая вычисленные значения оценок a =17.907 и σ 2 = 8.601 с выборочными оценками, видим их полное совпадение.
Вычисление описательных статистик. Описательные статистики можно разделить на следующие группы:
• характеристики положения описывают положение данных на числовой оси (среднее, минимальное и максимальное значения, медиана и др.);
• характеристики разброса описывают степень разброса данных относительно своего центра (дисперсия, размах выборки, эксцесс, среднеквадратическое отклонение и др.);
• характеристики асимметрии определяют симметрию распределения данных относительно своего центра (коэффициент асимметрии, положение медианы относительно среднего и др.);
• характеристики, описывающие закон распределения (частоты, относительные частоты, гистограммы и др.).
Основные характеристики положения, разброса и асимметрии можно вычислить, используя режим Описательная статистика команды Пакет анализа.
Для вызова режима Описательная статистика необходимо обратиться к пункту Сервис, команде анализ данных, выбрать в списке режимов Описательная статистика и щелкнуть на кнопке ОК. В появившемся диалоговом окне Описательная статистика задать следующие параметры (рис. 5):


Рисунок 5 Диалоговое окно описательной статистики
Входной интервал: – адреса ячеек, содержащих элементы вы-
борки.
Группирование: – задает способ расположения (по столбцам
или по строкам) элементов выборки.
Метки в первой строке – включается, если первая строка
(столбец) во входном интервале содержит заголовки. Выходной интервал: / Новый рабочий лист: / Новая рабочая
книга – определяет место вывода результатов вычислений. При
включении Выходной интервал: в поле вводится адрес ячейки, начиная с которой будут выводиться результаты.
Итоговая статистика: – включается, если необходимо вывести по одному полю для каждой из вычисленных характеристик.
Уровень надежности: – включается, если необходимо вычислить доверительный интервал для математического ожидания с задаваемым ( в % ) уровнем надежности γ .
К-й наименьший: – включается, если необходимо вычислить к-й наименьший (начиная с min x ) элемент выборки. При к = 1 вычисляется наименьшее значение.
К-й наибольший: – включается, если необходимо вычислить к-й наибольший (начиная с max x ) элемент выборки. При к = 1 вычисляется наибольшее значение.
Пример задания параметров приведен на рис. 5.
Результаты работы режима Описательная статистика выводятся в виде таблицы, в левом столбце которой приводится название вычисленной характеристики, позволяющее однозначно трактовать характеристику. Тем не менее, поясним следующие названия характеристик:
• Интервал – определяет размах выборки ;
;
• Сумма – определяет сумму всех элементов выборки;
• Счет – определяет число обработанных элементов выборки;
• Уровень надежности – определяет величину x Δ , от которой зависит доверительный интервал для математического ожидания, имеющий вид
[xв − Δx, xв + Δx],
где xв – выборочное среднее.
Пример 3.
По выборке примера 1 вычислить описательные статистики, используя режим Описательная статистика.
Решение. Первоначально, начиная с ячейки А3, введем в столбец А 55 элементов выборки. После этого обратимся к пункту Сервис, команде Пакет анализа. В списке режимов выберем Описательная статистика. В появившемся диалоговом окне включим параметры, показанные на рис. 3.6, и щелкнем ОК. Вычисленные характеристики приведены в таблице 1.
Таблица 1 –Описательная статистика
Столбец1 | |
Среднее | 17,90727 |
Стандартная ошибка | 0,399089 |
Медиана | 18,1 |
Мода | 17,8 |
Стандартное отклонение | 2,959721 |
Дисперсия выборки | 8,759946 |
Эксцесс | -0,07792 |
Асимметричность | -0,38619 |
Интервал | 13,7 |
Минимум | 10,1 |
Максимум | 23,8 |
Сумма | 984,9 |
Счет | 55 |
Наибольший(2) | 23,3 |
Наименьший(1) | 10,1 |
Уровень надежности(95,0%) | 0,800125 |
Задание 2 Определить параметры описательной статистики по данным объёма поступления продукции за 10 дней
Дни | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
Объём | 300 | 280 | 400 | 350 | 480 | 350 | 480 | 250 | 330 | 440 |
Вычисление интервальных оценок
Границы доверительных интервалов зависят от некоторой величины, которая зависит от распределения точечной оценки и доверительной вероятности. Эта величина находится по специальным таблицам. Поэтому часто возникает необходимость интерполяции или экстраполяции табличных данных и, следовательно, требуются дополнительные вычисления. В табличном процессоре Excel определены функции, позволяющие вычислять величины, входящие в интервальные оценки для различных числовых характеристик случайной величины.
Вычисление величины xγ , входящей в доверительный интервал:
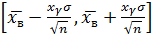 .
.
Величина xγ корнем нелинейного уравнения и вычисляется с помощью функции НОРМСТОБР:
x γ =НОРМСТОБР((γ+ 1) / 2),
где γ – надежность интервальной оценки.
Вычисление величины ![]() осуществляется с помощью функции ДОВЕРИТ:
осуществляется с помощью функции ДОВЕРИТ:
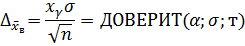
где α =1−γ , σ – известное среднеквадратичное отклонение, n –объем выборки.
Тогда интервальную оценку можно записать в виде 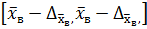
Вычисление величины t(γ ,n) , входящей в доверительный интервал
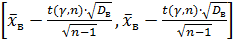 осуществляют с использованием функции СТЬЮДРАСПОБР, обращение к которой имеет вид:
осуществляют с использованием функции СТЬЮДРАСПОБР, обращение к которой имеет вид:
t(γ ,n) = СТЬЮДРАСПОБР(α;n) где α =1−γ , n – число степеней свободы (обратите на это внимание).
Вычисление величин
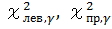
входящих в доверительный интервал для дисперсии σ 2 :
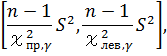
где S2 – исправленная дисперсия.
Используется функция ХИ2ОБР:
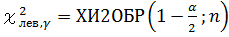 ;
;
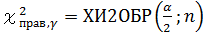 ,
,
где α =1−γ , γ – надежность интервальной оценки.
Задание 3
В каждом задании необходимо :
· подобрать исходные данные;
· определить параметры описательной статистики;
· дать точечную оценку средней величины генеральной совокупности;
· указать доверительный интервал для генеральной средней величины.
Варианты заданий
1. Исходные данные – значения температуры воздуха за 10 дней. Генеральная совокупность – данные за месяц.
2. Исходные данные – объём продаж за 10 дней. Генеральная совокупность – данные за месяц.
3. Исходные данные – выработка 12 рабочих. Генеральная совокупность – данные 25 рабочих.
4. Исходные данные – значения прибыли за полугодие. Генеральная совокупность – данные за год.
5. Исходные данные – товарооборот за 15 дней. Генеральная совокупность – данные за месяц.
6. Исходные данные – показания прибора в 20 измерениях. Генеральная совокупность – 30 измерений.
7. Исходные данные - значения роста 15 человек. Генеральная совокупность – 25 человек.
8. Исходные данные – значения веса 12 человек. Генеральная совокупность – 25 человек.
9. Исходные данные – стоимость акций за 15 дней. Генеральная совокупность – данные за месяц.
10. Исходные данные – количество деталей, выточенных токарем за день в течение 10 дней. Генеральная совокупность - данные за 20 дней.
11. Исходные данные – годовой процент автомобилей импортного производства в России с 2009 по 2012 гг. Генеральная совокупность – данные с 1985 по 2013 годы.
12. Исходные данные – влажность зерна в % за 15 дней. Генеральная совокупность – данные за месяц.
13. Исходные данные – размер 16 выточенных деталей на станке автомате. Генеральная совокупность – 30 деталей.
14. Исходные данные – вес 20 упаковок с макаронными изделиями, изготовляемых автоматической линией. Генеральная совокупность – 35 упаковок.
15. Исходные данные температура технологической установки за 15 дней. Генеральная совокупность – данные за месяц.
16. Исходные данные – сумма издержек торговой фирмы за 15 дней. Генеральная совокупность – данные за месяц.
