

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Содержание:
Стр.
1. Динамические модели прогнозирования выпуска продукции автокоррелированными остатками ……………………………………………. 2
1.1. Доверительные интервалы прогноза ………………………………………… 5
1.2. Кривая Гомперца и логическая кривая ……………………………………… 8
2. Задача ………………………………………………………………………….. 11
Литература ……………..…………………………………………………………. 13
Динамические модели прогнозирования выпуска продукции автокоррелированными остатками.
Автокорреляцией называется корреляция, возникающая между уровнями изучаемой переменной. Это корреляция, проявляющаяся во времени. Наличие автокорреляции чаще всего характерно для данных, представленных в виде временных рядов.
Автокорреляцией остатков модели регрессией (или случайных ошибок регрессии модели βi) называется корреляционная зависимость между настоящими и прошлыми значениями остатков.
Автокорреляция может быть следствием ошибочной спецификации эконометрической модели. Кроме того, наличие автокорреляции остатков может означать, что необходимо ввести в модель новую независимую переменную.
Временным лагом называется величина сдвига между рядами остатков модели регрессии.
Величина временного лага определяет порядок коэффициента автокорреляции. Например, если между остатками en и en-1 существует корреляционная зависимость, то временной лаг равен единице. Следовательно, данную корреляционную зависимость можно охарактеризовать с помощью коэффициента автокорреляции первого порядка между рядами остатков e1…en-1 и e2…en.
Одно из условий, которое учитывается при построении нормальной линейной модели регрессии, заключается в некоррелированности случайных ошибок модели регрессии, т. е. ковариация случайных ошибок любых двух разных наблюдений равна нулю:
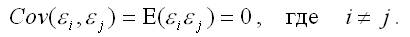
Если в модели регрессии случайные ошибки коррелированны между собой, то данное условие нарушается.
Последствия, к которым может привести наличие в модели регрессии автокорреляции остатков, совпадают с последствиями, к которым может привести наличие в модели регрессии гетероскедастичности:
1) оценки неизвестных коэффициентов нормальной линейной модели регрессии являются несмещёнными и состоятельными, но при этом теряется свойство эффективности;
2) существует большая вероятность того, что оценки стандартных ошибок коэффициентов модели регрессии будут рассчитаны неверно, что конечном итоге может привести к утверждению неверной гипотезы о значимости коэффициентов регрессии и значимости модели регрессии в целом.
Наиболее наглядным способом обнаружения автокорреляции случайных остатков регрессионной модели является графический метод. При этом осуществляется построение графиков автокорреляционной и частной автокорреляционной функций.
Автокорреляционной функцией называется функция оценки коэффициента автокорреляции в зависимости от величины временного лага между исследуемыми рядами.
Графически автокорреляционная функция изображается с помощью коррелограммы. Коррелограмма отражает численно и графически коэффициенты автокорреляции и их стандартные ошибки для последовательности лагов из определённого диапазона (например, от 1 до 25). При этом по оси Х откладываются значения τ (тау) – величины сдвига между рядами остатков, которые совпадают с порядком автокорреляционного коэффициента. Также на коррелограмме отмечается диапазон в размере двух стандартных ошибок коэффициентов автокорреляции на каждом лаге.
Частная автокорреляционная функция является более углублённой версией обычной автокорреляционной функции. Её отличительной особенностью является исключение корреляционной зависимости между наблюдениями внутри лагов, т. е. частная автокорреляционная функция на каждом лаге отличается от обычной автокорреляционной функции на величину удалённых автокорреляций с меньшими временными лагами. Следовательно, частная автокорреляционная функция более точно характеризует автокорреляционные зависимости внутри временного ряда.
Существуют два наиболее распространенных метода определения автокорреляции остатков. Первый метод ─ построение графика зависимости остатков от времени визуальное определение наличия или отсутствия автокорреляции. Второй метод ─ использование критерия Дарбина ─ Уотсона и расчет величины:
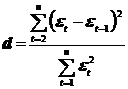 .
.
Таким образом, d есть отношение суммы квадратов разностей последовательных значений остатков к остаточной сумме квадратов по модели регрессии.
Коэффициент автокорреляции остатков первого порядка определяется, как:
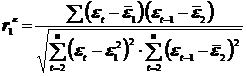 ;
;
где 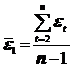 ;
; 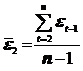
После соответствующих преобразований получим:
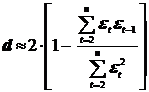
Итак, соотношение между критерием Дарбина ─ Уотсона и коэффициентом автокорреляции остатков имеет следующий вид:
d ≈ 2 · (1 - ![]() ).
).
Таким образом, если в остатках существует полная положительная автокорреляция и ![]() = 1, то d = 0. Если в остатках полная отрицательная автокорреляция, то
= 1, то d = 0. Если в остатках полная отрицательная автокорреляция, то ![]() = -1, следовательно, d = 4. Если автокорреляция остатков отсутствует, то
= -1, следовательно, d = 4. Если автокорреляция остатков отсутствует, то ![]() = 0 и d = 2. Следовательно, 0 ≤ d ≤ 4.
= 0 и d = 2. Следовательно, 0 ≤ d ≤ 4.
Алгоритм выявления автокорреляции остатков на основе критерия Дарбина ─ Уотсона следующий. Выдвигается гипотеза Н0 об отсутствии автокорреляции остатков. Альтернативные гипотезы Н1, Н1* состоят, соответственно, в наличии положительной или отрицательной автокорреляции остатков. Далее рассчитываются критические значения критерия Дарбина ─ Уотсона dL и dv для заданного числа наблюдений n, числа независимых переменных модели К и уровня значимости α. По этим значениям числовой промежуток [0; 4] разбивают на пять отрезков, принятые или
Есть положительная автокорреляция остатков (Н0) отклоняется с вероятностью р = (1 - α) принимается H1 | Зона неопределенности | Нет оснований отклонять (Н0) (автокорреляция остатков отсутствует) | Зона неопределенности | Есть отрицательная автокорреляция остатков. (Н0) отклоняется с вероятностью р = (1 - α) принимается H1* |
Отклонение каждой из гипотез с вероятностью (1 - α) осуществляется в зависимости от значений коэффициента автокорреляции.
Если значение Дарбина ─ Уотсона попадает в зону неопределенности, то на практике предполагают существование автокорреляции остатков и отклоняют гипотезу Н0.
1.2. Доверительные интервалы прогноза.
Доверительный интервал — это интервал, построенный с помощью случайной выборки из распределения с неизвестным параметром, такой, что он содержит данный параметр с заданной вероятностью.
Заключительным этапом применения кривых роста является экстраполяция тенденции на базе выбранного уравнения. Прогнозные значения исследуемого показателя вычисляют путем подстановки в уравнение кривой значений времени t, соответствующих периоду упреждения. Полученный таким образом прогноз называют точечным, так как для каждого момента времени определяется только одно значение прогнозируемого показателя.
На практике в дополнении к точечному прогнозу желательно определить границы возможного изменения прогнозируемого показателя, задать "вилку" возможных значений прогнозируемого показателя, т. е. вычислить прогноз интервальный.
Несовпадение фактических данных с точечным прогнозом, полученным путем экстраполяции тенденции по кривым роста, может быть вызвано:
1. субъективной ошибочностью выбора вида кривой;
2. погрешностью оценивания параметров кривых;
3. погрешностью, связанной с отклонением отдельных наблюдений от тренда, характеризующего некоторый средний уровень ряда на каждый момент времени.
Погрешность, связанная со вторым и третьим источником, может быть отражена в виде доверительного интервала прогноза. Доверительный интервал, учитывающий неопределенность, связанную с положением тренда, и возможность отклонения от этого тренда, определяется в виде:
![]()
где n - длина временного ряда;
L - период упреждения;
yn+L - точечный прогноз на момент n+L;
ta - значение t-статистики Стьюдента;
Sp - средняя квадратическая ошибка прогноза.
Предположим, что тренд характеризуется прямой:
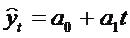
Так как оценки параметров определяются по выборочной совокупности, представленной временным рядом, то они содержат погрешность. Погрешность параметра ао приводит к вертикальному сдвигу прямой, погрешность параметра a1- к изменению угла наклона прямой относительно оси абсцисс. С учетом разброса конкретных реализаций относительно линий тренда, дисперсию S2p можно представить в виде:
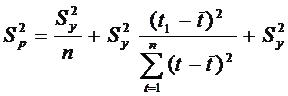
где ![]() - дисперсия отклонений фактических наблюдений от расчетных;
- дисперсия отклонений фактических наблюдений от расчетных;
t1 - время упреждения, для которого делается экстраполяция
t1 = n + L
где t - порядковый номер уровней ряда, t = 1,2,..., n;
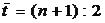 - порядковый номер уровня, стоящего в середине ряда,
- порядковый номер уровня, стоящего в середине ряда,
Тогда доверительный интервал можно представить в виде:
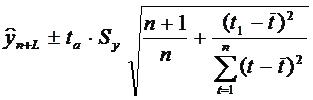
Обозначим корень в выражении (1.3.) через К. Значение К зависит только от n и L, т. е. от длины ряда и периода упреждения. Поэтому можно составить таблицы значений К или К*= taK. Тогда интервальная оценка будет иметь вид:
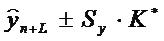
Выражение, аналогичное (1.3.), можно получить для полинома второго порядка:
Дисперсия отклонений фактических наблюдений от расчетных определяется выражением:

где yt - фактические значения уровней ряда,
yt - расчетные значения уровней ряда,
n - длина временного ряда,
k - число оцениваемых параметров выравнивающей кривой.
Таким образом, ширина доверительного интервала зависит от уровня значимости, периода упреждения, среднего квадратического отклонения от тренда и степени полинома.
Чем выше степень полинома, тем шире доверительный интервал при одном и том же значении Sy, так как дисперсия уравнения тренда вычисляется как взвешенная сумма дисперсий соответствующих параметров уравнения.
Доверительные интервалы прогнозов, полученных с использованием уравнения экспоненты, определяют аналогичным образом. Отличие состоит в том, что как при вычислении параметров кривой, так и при вычислении средней квадратической ошибки используют не сами значения уровней временного ряда, а их логарифмы.
По такой же схеме могут быть определены доверительные интервалы для ряда кривых, имеющих асимптоты, в случае, если значение асимптоты известно (например, для модифицированной экспоненты).
1.3. Кривая Гомперца и логическая кривая.
Исследование динамики социальных и экономических процессов выявило довольно сильную распространенность эффекта насыщения: выхода на асимптоту при достижении определенных значений показателей. В силу этого в эконометрике большое распространение получили так называемые кривые с насыщением. К этому типу кривых относится кривая Гомперца – s-образная кривая, предложенная Б. Гомперцем (), которая имеет вид:
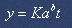
где K, a, b – параметры;
t - время (1,2,...).
Кривая Гомперца используется для аналитического выражения тенденции развития показателя во времени, имеющего ограничения на рост (рис. 1.2).
Если, то верхний предел для показателя у равен параметру K, а нижний – 0. Если, то кривая имеет лишь нижний предел, равный величине параметра K (рис. 1.2в, г).
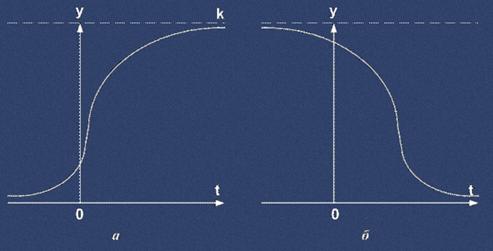
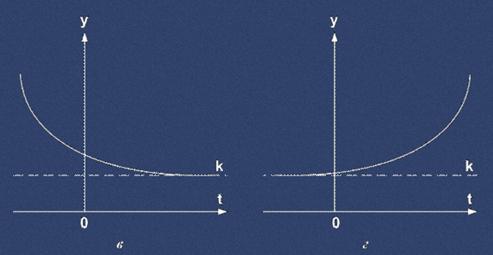
Рис. 1.2. Кривая Гомперца:
а - при log a < 0 при b < 1
б - при log a < 0 при b > 1
в - при log a > 0 при b < 1
г - при log a > 0 при b > 1
Для определения параметров тренда и может использоваться метод наименьших квадратов, только если задан параметр K. В противном случае возможно лишь приближенное оценивание параметров. Кривая Гомперца применяется в демографических расчетах и страховом деле.
К этому же типу кривых относится логистическая кривая (рис. 1.3), т. е. кривая с насыщением вида:
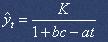
где t - время (1,2,...);
K, a, b – параметры;
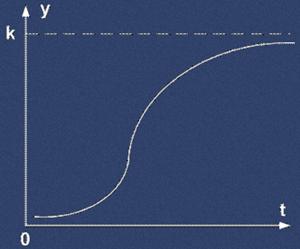
Эта кривая характеризует развитие показателя во времени, когда ускоренный рост в начале периода сменяется замедляющимся темпом роста вплоть до полной остановки, что на графике соответствует отрезку кривой, параллельному оси абсцисс. Используется для описания развития производства новых товаров, роста численности населения и т. д.
2. Решение задачи
Имеются данные:
у(спрос) {18,3; 19,4; 20,9; 21,4; 22,3};
х1(цена) {22,9; 23,4; 24,8; 25,8; 26,4};
х2 (н. р.) {122,9; 123,4; 125,9; 126,8; 127,7}.
Требуется дальнейшее поведение спроса.
Решение. Выбираем функцию:
![]()
Составляем систему стандартных уравнений:
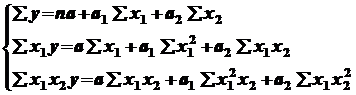
Составляем рабочую таблицу:
у (спрос) | х2(емкость) | х1 (цена) | ух1 | х12 | х1х2 | ух1х2 | х2х12 | х1х22 | |
18,3 | 122,9 | 22,9 | 419,07 | 524,41 | 2814,41 | 51503,7 | 64449,99 | 345891 | |
19,4 | 123,4 | 23,4 | 453,96 | 547,56 | 2887,56 | 56018,66 | 67568,9 | 9 | |
20,9 | 125,9 | 24,8 | 518,32 | 615,04 | 3122,32 | 65256,49 | 77433,54 | 1 | |
21,4 | 126,8 | 25,7 | 549,98 | 660,49 | 3258,76 | 69737,46 | 83750,13 | 8 | |
22,3 | 127,7 | 26,4 | 588,72 | 696,96 | 3371,28 | 75179,54 | 89001,79 | 5 | |
∑ | 102,3 | 626,7 | 123,2 | 2530,05 | 3044,46 | 15454,33 | 9 | 4 | 1939039 |
После решения получим функцию спроса:
у = -75,5352 + 0,0007347х1 + 0,7737х2
уt1 = 18,57 уt2 = 19,56
уt3 = 21,89 уt4 = 22,59
уt5 = 23,29
Спрос увеличивается на 6,0%.
Для расчета параметров системы стандартных уравнений
№ пп | у | х | z | x2 | z2 | xy | xz | xyz | zx2 | xz2 | y2 | z2y |
1 | 29,4 | 28,3 | 84,5 | 800,89 | 7140,25 | 832,02 | 2391,35 | 70305,69 | 67675,265 | 08 | 864,36 | 2484,3 |
2 | 29,9 | 31,2 | 85,6 | 973,77 | 7327,36 | 932,88 | 2670,72 | 79854,528 | 23326,464 | 63 | 894,01 | 2559,44 |
3 | 30,1 | 33,5 | 86,9 | 1122,25 | 7551,61 | 1008,35 | 2911,15 | 87625,615 | 97523,525 | 94 | 906,01 | 2615,69 |
4 | 20,4 | 36,4 | 87,8 | 1324,96 | 7708,84 | 1106,56 | 3195,92 | 97155,968 | 49 | 78 | 924,16 | 2669,12 |
5 | 30,9 | 37,5 | 89,5 | 1406,25 | 8010,25 | 1158,75 | 3356,25 | 13 | 38 | 38 | 954,81 | 2765,55 |
6 | 31,4 | 38,8 | 90,8 | 1505,44 | 8244,64 | 1218,32 | 3523,04 | 46 | 95 | 03 | 985,96 | 2851,12 |
Сумма | 182,1 | 205,7 | 525,1 | 7133,23 | 45982,95 | 6256,88 | 18048,43 | 38 | 01 | 183 | 5529,31 | 15945,22 |
Расчет коэффициента множественной корреляции:
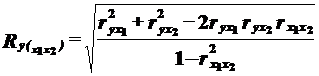 .
.
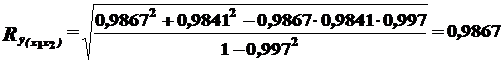
DR = R2∙ 100 = 97,3%
Вывод. Полученные данные позволяют спрогнозировать дальнейшее развитие ситуации на рынке. С достоверностью 97,3% можно утверждать, что при дальнейшем увеличении цены на продукцию спрос будет расти.
Литература:
1. . Эконометрика. Учебно-практическое пособие. М., МГТА, 2004.
2. . Практическое пособие по курсу: "Эконометрика". М., изд. Комплекс. 2005.
3. . Практикум по курсу: "Эконометрика". М., МГУ ТУ, 2007.
4. Бендат Дж., Применения корреляционного и спектрального анализа: Пер. с анг. М., Мир. 2010.
5. Дуброва методы прогнозирования. М., ЮНИТИ, 2003.
