

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Моделирование параллельной производительности: структура моделей, идентификация, анализ и прогнозирование (лабораторная работа)
С. В. Ковальчук, О. А. Комалева
В лабораторной работе рассматриваются приемы распараллеливания программ с использованием технологии OpenMP (работа выполняется на компьютере с многоядерным процессором, то есть в системе с общей памятью), производится анализ полученных результатов при помощи соответствующей модели производительности. Исследование производится на примере задачи суммирования тригонометрических рядов. В процессе работы изучаются варианты распараллеливания по данным и по задачам, анализируются эффекты применения различных параметров распараллеливания, предоставляемых в рамках рассматриваемой технологии, способов оптимизации параллельных программ и режимов их работы в рамках операционной системы. Результаты измерений производительности сопоставляются с моделью производительности OpenMP, что позволяет оценить параметры модели в применении к реализованному алгоритму, работающему в рамках данной системы, и, как результат, осуществить оценочное прогнозирование изменения производительности при параметрах, выходящих за границы измерений.
Требования к программному обеспечению для выполнения работы: Microsoft Office PowerPoint, MathCAD (не ниже 14 версии), Microsoft Visual Studio 2005.
Исходные данные
Рассматривается задача о нахождении суммы двух тригонометрических рядов:
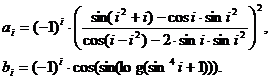
В файле summa.cpp последовательный код, который вычисляет суммы ![]() первых членов рядов
первых членов рядов ![]() ,
, ![]() и выводит результат в файл.
и выводит результат в файл.
Замечания
Отработка навыков распараллеливания программ не является основной целью данной работы. Обучающийся должен научиться получать адекватные экспериментальные оценки производительности и сопоставлять их с теоретическими моделями.
Поэтому, например, для большего контроля над ситуацией следует при выполнении данной работы, не следует использовать оптимизацию. По тем же причинам исполнителю работы предоставляется некоторая свобода выбора параметров программы, при которых будет проводиться эксперимент.
1. Распараллеливание исходного кода
С помощью технологии OpenMP[1] распараллельте исходные алгоритм, используя декомпозицию по данным и по задачам. Для этого вам могут понадобиться директивы for и sections.
С помощью функции omp_get_wtime сравните время работы последовательных и параллельных программ. Сравните ускорения получившихся параллельных алгоритмов. Какая из декомпозиций в данном случае эффективней и почему?
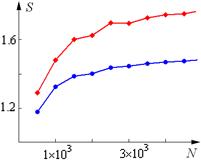
| декомпозиция по данным |
| декомпозиция по задачам |
Рис. 1. Ускорения различных параллельных алгоритмов
2. Оптимальность последовательного алгоритма
Если целью распараллеливания является улучшение производительности программы, то имеет смысл измерять эффективность полученного параллельного алгоритма относительно оптимального последовательного алгоритма (такая мера называется абсолютной). Приведем пример.
При более детальном изучении исходной задачи можно заметить, что выражение для вычисления ![]() можно упростить. Действительно, пусть
можно упростить. Действительно, пусть ![]() , а
, а ![]() :
:
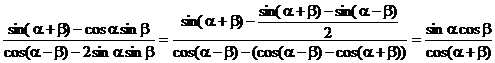 .
.
Очевидно, что в полученном выражении операций меньше, чем в исходном. Логично предположить, что новый алгоритм будет работать быстрее. С другой стороны, так как в новом алгоритме кода, выполняющегося параллельно, стало меньше, значит, относительное ускорение нового алгоритма будет хуже относительного ускорения старого.
| исходный алгоритм |
| оптимизированный алгоритм |
Рис. 2. Различные последовательные алгоритмы
Преобразуйте исходный последовательный алгоритм согласно полученному выражению. Сравните время работы двух последовательных алгоритмов. Распараллельте новый алгоритм.
3. Измерение производительности полученных программ
Для различных значений ![]() (например,
(например, 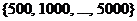 ) измерьте время работы последовательных и параллельных алгоритмов. С помощью программы MathCad (пример в файле laba.mcd) постройте экспериментальные графики зависимостей
) измерьте время работы последовательных и параллельных алгоритмов. С помощью программы MathCad (пример в файле laba.mcd) постройте экспериментальные графики зависимостей ![]() и
и ![]() , где
, где ![]() – время работа программы,
– время работа программы, ![]() – ускорение.
– ускорение.
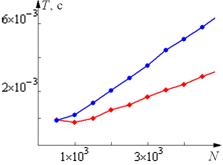
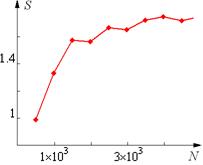
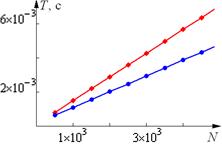
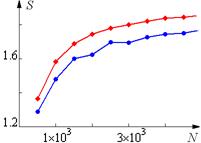
| параллельный алгоритм |
| последовательный алгоритм |
Рис. 3. Стохастичность результатов измерения ускорения и времени работы
На рисунках приведены примеры полученных результатов. Графики времени выполнения выглядят достаточно гладко, этого нельзя сказать о кривой для ускорения. И это не худший результат, который вы можете получить (например, эффективность большую единицы). Время выполнения любой программы – случайная величина, зависящая от многих параметров, таких как приоритет, используемый компилятор и т. п. Нам интересно скорее не распределение этой случайной величины, а характеристика ее среднего, например, медиана. Для измерения характеристик нужно повторять эксперимент по несколько раз (например, 100 или 1000). Для оценки качества полученных результатов можно также вычислять характеристики разброса, такие как среднеквадратическое отклонение ![]() . Чем больше будет
. Чем больше будет ![]() , тем больше доверительный интервал полученной оценки среднего. Для уменьшения величины
, тем больше доверительный интервал полученной оценки среднего. Для уменьшения величины ![]() можно, различными способами снижать влияние внешних факторов на программу, например, увеличивать ее приоритет (на рис. 4 приведен пример). В первую очередь влияние приоритета определяется тем, что в рамках операционной системы одновременно работают множество процессов. Изменить приоритет запуска можно, запустив программу командой start с соответствующим параметром:
можно, различными способами снижать влияние внешних факторов на программу, например, увеличивать ее приоритет (на рис. 4 приведен пример). В первую очередь влияние приоритета определяется тем, что в рамках операционной системы одновременно работают множество процессов. Изменить приоритет запуска можно, запустив программу командой start с соответствующим параметром:
START /HIGH <исполняемый файл>
| высокий приоритет |
| нормальный приоритет |
| низкий приоритет |
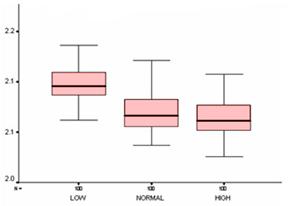
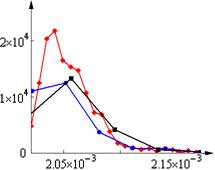
Рис. 4. Распределения времени работы в зависимости от приоритета
Видно, что время работы программы зависит от того, с каким приоритетом она запущена. Также отметим, что разброс времени работы программы, запущенной со средним приоритетом, больше остальных. Это связано с тем, что во время проведения эксперимента на компьютере работало еще несколько программ, все со средним приоритетом. То есть при выполнении эксперимента нужно постараться минимально загружать процессор посторонними программами.
Для каждого значения ![]() несколько раз измерьте время работы программы. Постройте новые графики
несколько раз измерьте время работы программы. Постройте новые графики ![]() и
и ![]() . Попытайтесь получить как можно более гладкие кривые.
. Попытайтесь получить как можно более гладкие кривые.
4. Анализ полученных результатов
Сравните ускорения алгоритмов, полученные при различных значениях опции schedule директивы for. Пересекаются ли экспериментальные графики? Объясните полученные результаты. Для произвольного параллельного (и соответствующего ему последовательного) алгоритма определить входные параметры, для которых ускорение меньше 1.
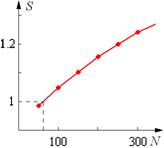
Рис. 5. Ускорение меньше единицы
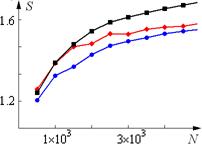
| guided |
| dynamic |
| static |
Рис. 6. Зависимость ускорения от параметров опции schedule директивы for
5. Построение модели
Приведем пример построения модели для систем с общей памятью, с последующим сопоставлением с экспериментальными данными. На рис. 7 приведена структурная схема работы программы, использующей OpenMP.
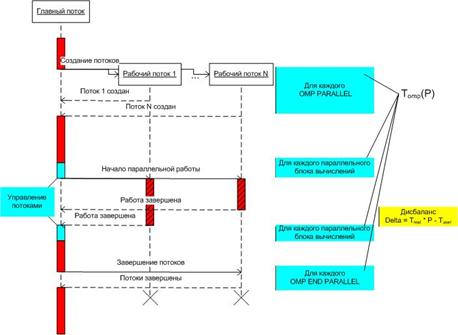
Рис. 7. Работа программы, использующей OpenMP
Анализируя составные части времени работы последовательного и параллельного варианта программы можно вывести следующую теоретическую модель производительности системы, использующей OpenMP:
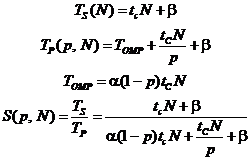
Где ![]() – время работы последовательного варианта программы при обработке
– время работы последовательного варианта программы при обработке ![]() элементов входных данных;
элементов входных данных; ![]() – время работы параллельного варианта программы;
– время работы параллельного варианта программы; ![]() – накладные расходы на управление потоками OpenMP;
– накладные расходы на управление потоками OpenMP; ![]() – ускорение, получаемое благодаря использованию параллельного варианта программы.
– ускорение, получаемое благодаря использованию параллельного варианта программы.
Вопрос: в чем отличие приведенной модели от классического закона Амдала?
При помощи файла speedup. xmcd можно подобрать параметры модели и проанализировать соответствие ее результатам измерений. Используются следующие файлы с экспериментальными данными:
Имя файла | Описание |
Nin. txt | Количество входных данных для измерения времени работы |
Pin. txt | Количество процессоров |
Tin. txt | Двумерная таблица, содержащая время работы для указанного количества входных данных и процессоров |
Пример результатов анализа приведен на рис. 8.
|
|
а) зависимость ускорения от количества данных | б) зависимость ускорения от количества процессоров |
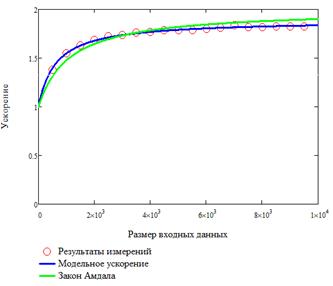
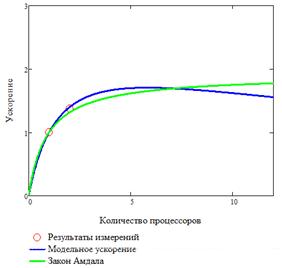
Рис. 8. Соответствие модели результатам измерения
Вопрос: как влияет добавление накладных расходов на получаемое ускорение?
[1] https://computing. llnl. gov/tutorials/openMP/
