

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
if (m[ imax ]<m[ j ])
imax=j;
t=m[ imax ];
m[ imax ]=m[ N-i ];
m[ N-i ]=t;
}
Как можно заметить по результату сортировки на 4-проходе на рис.4, алгоритм сортировки выбором является неустойчивым, поскольку он меняет значения элементов с одним и тем же значением ключа (на 4-м проходе элемент меняется местами с самим собой).
Алгоритм сортировки вставками.
Предположим, что первые k элементов массива уже упорядочены по неубыванию. Берем k+1 элемент и размещаем среди первых k элементов так, чтобы упорядоченными оказались уже k+1 первых элемента. Метод применяется для всех k от 1 до n-1.
Иллюстрирует порядок сортировки того же исходного массива из 5-ти элементов рис.5. На каждом проходе выбирается первый элемент из еще неотсортированной последовательности (для первого прохода за отсортированную последовательность принимаем первый элемент массива) и отыскиваем место, которое он должен занять среди уже отсортированных элементов. Вставляем элемент на свое место и тем самым увеличиваем размер последовательности на один элемент перед следующим проходом.
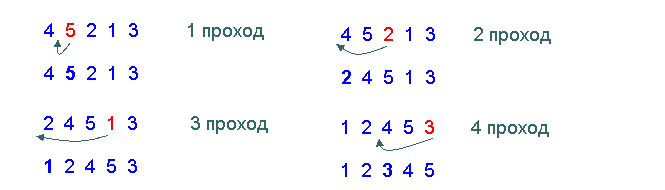

Рис.5. Сортировка массива методом вставками.
Программная реализация метода сортировки вставками на языке Си:
const int N=5;
int m[N]={5,3,4,1,2};
int r,j,imin;
for(int i=1;i<N;i++)
{
r=m[i];j=i-1; //в r запоминаем очередной
//несортированный элемент
while(j>=0 &&r<m[j]) //пока не найдем место элемента j
//или не достигнем начала массива
{
m[j+1]=m[j];
j--;
}
m[j+1]=r;
}
Эффективность алгоритма сортировки оценивают по количеству операций сравнений C и перестановки M элементов, которые выполняются в процессе сортировки. Для рассмотренных алгоритмов оценки этих показателей приведены в таблице 1.
Таблица 1. Сравнительный анализ методов сортировки массивов
| Min | Среднее | Max |
Метод пузырька |
С=(n2-n)/2 M=0
|
С=(n2-n)/2 M=(n2-n)*0,75 |
С=(n2-n)/2 M=(n2-n)*1,5 |
Простой выбор |
С=(n2-n)/2 M=3(n-1)
|
С=(n2-n)/2 M=n(log n+0,57) |
С=(n2-n)/2 M=n2/4+3(n-1) |
Простые вставки |
С=n-1 M=2(n-1)
|
С=(n2+n-2)/4 M=(n2-9n-10)/4 |
С=(n2-n)/2-1 M=(n2+3n-4)/2 |
Анализ содержимого таблицы показывает, что рассмотренные алгоритмы не относятся к классу эффективных, поскольку их показатели C и M далеки от значений O(n)=n*log n, характерных для оптимальной сортировки. Достоинством приведенных в таблице 1 алгоритмов можно назвать простоту реализации, что делает их привлекательными при использовании начинающими программистами, а также, возможно, для обработки небольших по размеру массивов, для которых значения величин C и M не будут критичными. Более эффективный алгоритм сортировки массивов – алгоритм быстрой обменной сортировки по Хоару – имеет рекурсивную природу и рассматривается в соответствующих методических указаниях [1].
Рассматриваемые до этого момента массивы относились к категории статических – для них заранее, еще на этапе компиляции, определяется размер. Если размер массива заранее не известен, то эффективнее использовать динамические массивы. Память под такие массивы выделяется в динамической куче программы и может быть освобождена в любой момент времени. Для обращения к динамическому массиву в программе необходимо определить указатель типа, соответствующего типу элементов массива и сохранить в нем адрес выделенного под массив участка памяти.
Для динамического выделения памяти язык Си предлагает функцию malloc, а язык Си++ операцию new. Освободить память из под массива можно функций free языка Си или операцией delete языка Си++.
//Листинг 1. Выделение динамической памяти под массив в языке Си
#include <malloc. h>
#include <stdio. h>
int main()
{
int * ptm;
int n;
printf("Введите количество элементов массива");
scanf("%d", &n);
ptm=(int *)malloc(n*sizeof(int));
//работа с массивом с ипользованием выражений типа ptm[i]
free(ptm);
}
//Листинг 2. Выделение динамической памяти под массив в языке Си++
#include <iostream.h>
int main()
{
int * ptm;
int n;
cout<<"Введите количество элементов массива";
cin>>n;
ptm=new int[n];
//работа с массивом с ипользованием выражений типа ptm[i]
delete [] ptm;
}
Оба приведенных листинга подчеркивают одно их основных преимуществ динамических массивов – количество элементов массива можно задавать выражением, использующим не только константы, но и переменные. Еще одним преимуществом динамических массивов является возможность эффективно перераспределять память, когда программист выделяет блок памяти под массив в тот момент, когда он понадобился и освобождает этот блок, возвращая его системе, когда массив больше не нужен. Рисунок 6 иллюстрирует связь указателя и массива в памяти.
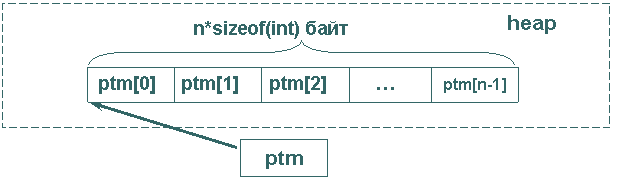

Рис.6. Динамический массив в heap’е программы.
Может вызвать сомнение правомочность обращения к элементу динамического массива с использованием выражения ptm[i]. Но такое обращение к элементам массива преобразуется компилятором к выражению *(ptm+i) и оно корректно адресует элементы массива в динамической куче. Можно также отметить, что имя статического массива рассматривается компилятором как адрес начального элемента массива и использовавшееся ранее для статических массивов выражение mas[i] также интерпретируется компилятором как адресное выражение *(mas+i).
Многомерные массивы в языке Си определяются по правилам, аналогичным рассмотренным ранее для одномерных с добавлением дополнительных размерностей. Рассмотрим определение обобщенное определение двумерного массива в языке Си:
класс_памяти тип
имя_массива[конст._выражение_1][конст._выражение_2]
={иниициализатор};
Здесь константное_выражение_1 и константное_выражение_2 задают, соответственно, количество строк и столбцов в определяемой матрице – массиве.
Примеры определения двумерных массивов в прграмме:
int mas[5][6];
int const N=3, K=4;
double Array[N][K];
char Str[N*2][50];
int arr[3][2]={{1, 2}, { 3, 4}, {5,6}};
Особенностью синтаксиса и обращения к элементам многомерных массивов в языке Си и подобных ему в отличии от таких языков программирования, как Pascal или Basic, является указание каждой размерности массива в отдельной паре квадратных скобок. Это связано с тем, что идеологически в языке нет двумерных массивов, а те объекты, что были определены в примере выше представляют собой одномерные массивы, элементами с одномерными же массивами в качестве элементов.
Логическая структура двумерного массива (рис.7а) описывает матрицу из заданного в определении количества строк N и столбцов M. Номера строк и столбцов нумеруются с нуля. При этом физически все элементы двумерного массива располагаются в памяти подряд, строка за строкой (рис.7б).
В обобщенном определении двумерного массива присутствует инициализатор. Как и в случае одномерного массива он является необязательной частью определения и позволяет задать начальные значения элементам массива.
Инициализатор двумерного массива может в точности совпадать с уже рассмотренным для одномерного случая:
int mas[4][3]={5,3,2,1,4,0,4,5,6,2,4,5};
В таком случае все элементы массива (или не все, в зависимости от длины списка инициализатора) получат свои значения в порядке их следования в памяти согласно рис. 6б. Недостаток такой инициализации очевиден – нет четкого разделения на строки и столбцы, не просматривается логическая структура матрицы.
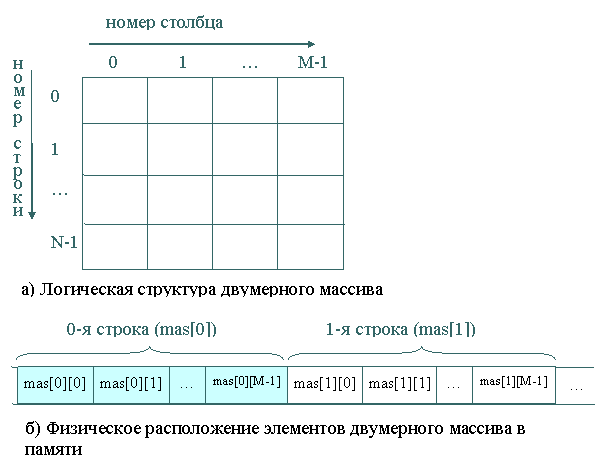

Рис.7. Логическая и физическая структура двумерного массива
Гораздо удобнее инициализировать двумерный массив построчно, когда каждому элементу массива (одномерному массиву, как уже отмечалось), соответствует свой собственный инициализатор:
int mas[4][3]={{5,3,2,1},
{1,4,0,9},
{4,5,6,7},
{2,4,5,8}};
При подобной инициализации четко просматриваются строки и столбцы матрицы, она ближе сути инициализируемого объекта. К тому же второй способ позволяет не инициализировать элементы в конце каждой строки, если для них нет начального значения:
int triMas[4][3]= {{5},
{1,4,},
{4,5,},
{2,4,5}};
Для матрицы triMas остаются неинициализированными элементы, лежащие выше главной диагонали, они получат свои значения в соответствии с классом памяти массива. Если используется явная инициализация массива, допускается не задавать для него количество строк, оно будет определено по количеству элементов в инициализаторе.
int m3[][3]={{5,3,2,1},
{1,4,0,9},
{4,5,6,7}
};
Массив m3 будет определен с 3-мя строками и 4-мя столбцами. Количество столбцов задается в определении всегда.
После того как двумерный массив определен в программе, к его элементам можно обращаться для получения и изменения элементов. Обращение к элементу двумерного массива выглядит следующим образом:
имя_массива [номер_строки][номер_столбца] ,
где номер_строки и номер_столбца – целочисленные выражения определяющие местоположение того элемента, с которым желает работать программист. Необходимо помнить, что для матрицы NxM номер строки должен находиться в диапазоне [0, N-1], а номер столбца в диапазоне [0, M-1]. Выражение обращения к элементу матрицы является леводопустимым. Примеры обращения к элементам двумерного массива:
int mas[4][5], i, j;
mas[0][0]=0;
cin>>mas[3][2];
i=2,j=1;
mas[i][j]=mas[j][i];
Рассмотрим некоторые типовые алгоритмы работы с двумерным массивом. Вот как можно ввести содержимое массива по строкам и по столбцам соответственно:
//Ввод двумерного массива по строкамconst int N=4, M=5;
| //Ввод двумерного массива по столбцамconst int N=4, M=5;
|
При просмотре содержимого матрицы желательно наблюдать ее элементы построчно с выравниванием содержимого столбцов, поэтому при выводе используются простейшие приемы форматирования
for (int i=0;i<N;i++)
{
for (int j=0;j<M;j++)
cout<<mas[i][j]<<‘\t’; //элементы одной строки отделяем табулятором

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
