
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
2. Лексический анализ
2.1. Сущность лексического анализа
Лексический анализ (ЛА) является первой фазой трансляции. Термин «лексика» в обычном языке подразумевает правила составления слов из букв. В языке программирования ЛА соответствует фаза трансляции, в которой из последовательности отдельных литер (символов, букв языка) выделяются слова (лексемы или символы - как сони именуются на сходе следующей фазы - синтаксического анализа). Типичными словами в языке программирования являются такие компоненты как комментарии, идентификаторы, константы, служебные слова, знаки операций. Лексика имеет ряд принципиальных ограничений, которая делает возможной ее распознавание описанными ниже методами:
· лексемы распознаются независимо друг от друга. Единственное, что возможно, это «перекрытие» процесса распознавания двух рядом расположенных лексем на заданное количество литер (которые участвуют в завершении распознавания текущей лексемы и начале распознавания следующей);
· определение лексем включает элементы выбора одного из нескольких вариантов продолжения и повторения;
· вложенность одной лексемы в другую или наличие произвольной вложенности элементов лексемы не допускается.
ЛА является наиболее простой и формализованной фазой трансляции. Любой алгоритм ЛА базируется на последовательном просмотре текста, с возвратом и перечитыванием из входной последовательности не фиксированного числа литер, поэтому программу ЛА иногда называют сканером. Формальной основой описания процесса ЛА являются конечные автоматы.
Простейший лексический анализатор
Простейший лексический анализатор можно построить, не прибегая ни к каким формальным методам, просто анализируя последовательности символов, образующих лексические единицы. Соответствующий пример приведен в файле hardlex.cpp. Из приведенного ниже фрагмента видно, что программа «зацепляет» первый символ, определяющий начало лексической единицы (букву, цифру и т. д.) а затем просматривает строку до конца элемента лексики (идентификатора, константы). Некоторые лексические единицы при этом имеют еще и собственное значение, которое выходит за рамки алгоритма распознавания. Например, для идентификатора и константы важен не только факт их распознавания, но и их значение, заключенное в цепочке символов. Поэтому анализатор перед началом очередного цикла фиксирует начало распознаваемой последовательности символов, для сохранения ее значения.
while (1)
{ fix=i;
switch(s[i])
{
case '"': // Распознавание строковой константы ". . ."
// с двойными "" внутри
mmm: i++; while (s[i] !='"') i++;
i++; if (s[i]=='"') goto mmm;
lexem(1); break;
case '/': i++; // Распознавание / и /*
if (s[i]!='*')
{ lexem(14); break; }
// Распознавание комментария /* ... */
n1: while (s[i] !='*') i++;
i++; if (s[i]=='/')
{ i++; lexem(2); break; }
goto n1;
case '+': i++; // Распознавание += и +
if (s[i]=='=')
{ i++; lexem(5); }
else lexem(15);
break;
case '<': i++; // Распознавание << и <
if (s[i]=='<')
{ i++; lexem(6); }
else lexem(16); break;
default: if (isalpha(s[i]))
// Распознавание идентификатора
{ i++; while (isalpha(s[i])) i++;
lexem(11); break; }
// Распознавание константы
if (isdigit(s[i]))
{ i++; while (isdigit(s[i])) i++;
lexem(12); break; }
Общим принципом проектирования такого рода программ является «зашивание» в текст программы распознаваемого формата непосредственно в управляющие конструкции алгоритма, производящего чтение символов: наличию альтернативных вариантов в распознаваемом формате соответствует ветвление в программе (операторы if или switch), наличию повторяющихся фрагментов – цикл.
2.2. Конечные автоматы
Формальной основой ЛА являются конечные автоматы (КА). Конечный автомат является принципиально более простой формальной моделью, нежели компьютерная программа (машина Тьюринга). Программа включает в себя две компоненты: алгоритм и произвольным образом организованные неограниченного объема данные. Конечный автомат не содержит данных и представляет собой алгоритмическую часть программы в чистом виде. Т. е. он представляет собой систему, которая реагирует только на изменение состояния внешней среды, но не способна к запоминанию. Она не имеет изменяемой памяти, сама управляющая информация о структуре автомата хранится в постоянной памяти (обычно в табличной форме). Единственным хранимым параметром автомата является его текущее состояние, которое характеризует текущий шаг выполняемого алгоритма (аналог регистра текущей команды процессора - IP).
Отсутствие собственной памяти задает принципиально другую «модель поведения», аналог которой имеется в животном мире:
· конечный автомат моделирует «инстинктивное» поведение, основанное на воспроизведении программы действий, меняющейся в зависимости от последовательности внешних событий, но не запоминающей информации из внешней среды;
· компьютерная программа моделирует «рефлекторное» поведение, принципиально связанное с запоминанием и обработкой информации о внешних событиях и настройкой (адаптацией) к ним.
Конечный автомат – алгоритмическая компонента программы «без данных», моделирующая «инстинктивное» поведение, неадаптируемое к последовательности воздействий внешней среды.
Теперь приведем формальное определение КА в терминах дискретной математики и теории множеств. Конечный автомат определяется шестью компонентами
A = { I, O,S, S0,P, D }
· множество (алфавит) входных символов I={Ii};
· множество (алфавит) входных символов O={Oj};
· множество состояний автомата S={Sk};
· начальное состояние S0ÎS;
· функция переходов P(S,I) ® S , ставящая в соответствие каждой паре «состояние - входной символ» новое состояние;
· функция выходов D(S,I) ® O , ставящая в соответствие каждой паре «состояние - входной символ» выходной символ.
Опишем, как выглядит работа такой системы:
· КА является дискретной системой, работающей по тактам (шагам), в каждом из которых он получает на вход один из символов входного алфавита;
· последовательность символов на входе КА образует входную цепочку;
· на каждом шаге КА находится в одном из возможных состояний, которое называется текущим. Текущее состояние – единственная характеристика внутреннего описания КА, которая меняется при его работе (изменяемая память). Все остальные элементы его описания являются статическими (т. е. в любой реализации представляют собой постоянную память);
· шаг работы КА состоит в переходе из текущего состояния в новое состояние при получении на вход очередного символа входной цепочки. Этот переход определяется функцией переходов;
· результат работы КА заключается в записи в выходную цепочку символов, генерируемых функцией выходов КА. Т. е. параллельно с переходом в новое состояние формируется выходной символ, определяемый парой «текущее состояние – входной символ». Выходной символ может быть и пустым;
Работа КА заключается в преобразовании входной цепочки символов в выходную. Закон этого преобразования определяет поведение КА. Задача проектирования КА состоит в создании КА, обеспечивающем заданные правила преобразования цепочек. Очевидно, что отсутствие у КА внутренней памяти ограничивает его возможности по преобразованию цепочек (общепринятый термин - моделирующая способность). С другой стороны, эти же ограничения позволяют решать в общем случае многие проблемы (термин – алгоритмическая разрешимость, т. е. принципиальная возможность разработать соответствующий алгоритм).
Хотя автоматы и можно представить в традиционной для алгоритма технологии блок-схем (управляющие КА так и строятся на основе разметки блок-схемы алгоритма), наиболее удобной формой их представления для человека является графическая - диаграмма состояний-переходов, а для программирования и формальных преобразований – табличная. Основные элементы диаграммы состояний – переходов:
· состояние представляет собой окружность, содержащую номер или наименование состояния;
· направленная дуга, соединяющая состояния Sk и Sm, определяется значениями функций переходов и действий: если Sm=P(Sk,Ii) и On=D(Sk,Ii), то имеется переход КА из Sk в Sm , который обозначается дугой, соединяющей эти вершины. Дуга подписывается парой символов Ii/On . Это означает, что переход по дуге при поступлении на вход символа Ii сопровождается формированием выходного символа On.
Если поведение какого-либо объекта можно описать набором предложений вида: «Находясь в состоянии A, при получении сигнала S объект переходит в состояние B и при этом выполняет действие D», то такая система будет представлять собой конечный автомат.
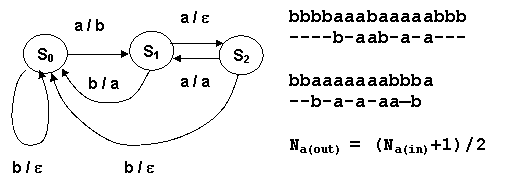 |
Анализируя приведенный здесь пример диаграммы состояний-переходов и вид преобразования цепочек, можно сделать вывод о поведении автомата и сущности выполняемых им преобразований. Нетрудно заметить, что получая входные цепочки, содержащие символы a и b в произвольном порядке, КА формирует аналогичные цепочки более регулярного вида. Так, из подряд идущих символов b он оставляет один, а в последовательности символов a оставляет все нечетные, кроме первого. При нечетном количестве символов a на входе КА добавляет еще один символ a в выходную последовательность. Отсюда можно вычислить закон преобразования длины входной цепочки символов a - Na(out) = (Na(in)+1)/2
Анализируя состояния и условия переходов в них, можно определить их содержательный «смысл»: состояния S1 ,S2 обозначают нечетное и четное число подряд прочитанных символов a.
Табличная форма представления КА включает в себя представление функций переходов и выходов виде таблиц.
P | a | b |
S0 | 1 | 0 |
S1 | 2 | 0 |
S2 | 1 | 0 |
D | a | b |
S0 | b | e |
S1 | e | a |
S2 | a | e |
На диаграмме состояний-переходов не может быть двух и более дуг из одного состояния, помеченных одним и тем же входным символом. Если это не так, то такая неканоническая форма называется недетерминарованным КА. Такой КА не имеет адекватного табличного (функционального) представления, но может быть преобразован в обычный детерминированный.
Автоматные модели в программировании
При разработке программ, характеризующейся сложной логикой управления, можно применять автоматный подход, который позволяет сделать текст программы более регулярным и компактным. То же самое решение можно применить, если программа активизируется внешними событиями (событийное программирование) и требуется отследить заданную последовательность наступления событий. В качестве примера, реализованного в виде автоматной модели, рассмотрим функцию, которая исключает из строки комментарии вида “ /* ... */ ”
Прежде всего, необходимо определить состояния автомата, возможные при просмотре очередного символа строки:
· состояние 0 - идет обычный текст;
· состояние 1 - обнаружен символ “/”;
· состояние 2 - обнаружено начало комментария “/*”;
· состояние 3 - в комментарии обнаружен символ “*”.
Программа будет выглядеть следующим образом:
void f(char in[],char out[])
{int i, s, j; // s – текущее состояние автомата
for(i=0,s=0,j=0; in[i]!=0; i++) // i - индекс текущего символа входной строки
switch(s) // j – индекс текущего символа выходной строки
{
case 0: if (in[i])!=’/’ out[j++] = in[i]; // символы копируются только в состоянии 0
else s=1;
break;
case 1: if (in[i]!=’*’) { out[j++]=in[i-1]; out[j++]=in[i]; s=0; }
else s=2;
break;
case 2: if (in[i]==’*’) s=3;
break;
case 3: if (in[i]==’/’) s=0;
break;
}}
Подробнее рассмотрим характерные особенности этой программы:
· программа представляет собой цикл, в каждом шаге которой анализируется очередной символ из входной строки. Заметим, что только текущий. Программа принципиально не анализирует ни предыдущих, ни последующих символов. Текущий символ играет, таким образом. Роль входного сигнала, по которому автомат переходит из одного состояния в другое.
· программа имеет переменную s, которая и представляет собой текущее состояние КА. В теле основного цикла программы выполняется переключение (switсh) по всем возможным значениям этой переменной - состояниям КА.
· в каждом состоянии реализуется логика его перехода в другие состояния на основе анализа текущего символа - входного сигнала и вырабатывается соответствующее действие. Например, в состоянии 1, когда программа уже обнаружила символ “/” - возможное начало комментария, она проверяет, не является ли текущий символ “*”. Если это так, автомат переводится в состояние 2 - нахождение внутри комментария, если нет, то в выходную строку переписывается предыдущий “/” и текущий символы, а автомат возвращается в состояние 0.
2.3. Конечные автоматы в лексическом анализе
Конечные автоматы (КА) (или другие равные им по уровню представительности формальные модели, например, регулярные грамматики или регулярные выражения) являются основой построения лексических анализаторов. На самом деле, в реальном проектировании трансляторов в качестве языка описания лексики используются регулярные выражения, которые «транслируются» сначала в неканонические (недетерминированные) КА, которые затем преобразуются в обычные КА, минимизируются и т. п..
Однако в простых случаях, когда требуется распознаватель для лексики ограниченного объема, можно использовать формализм КА для непосредственного проектирования распознавателя. При этом технология проектирования такого КА в системе состояний-переходов имеет много общего с «историческим подходом» при разработке алгоритмов с использованием блок-схем:
· в процессе рисования блок-схемы ставится вопрос «Куда направить дугу от текущего блока при выполнении заданного условия?». «Перевод стрелок» на уже нарисованные элементы блок-схемы (переход в уже известную часть алгоритма) или рисование нового элемента (планирование нового действия) является основным технологическим элементом проектирования. При разработке диаграммы состояний-переходов КА требуется выполнять аналогичные действия, проводя дугу из одного состояния в другое при появлении на входе КА определенного символа;
· любой элемент блок-схемы является точкой алгоритма, которую можно содержательно сформулировать в терминах текущего состояния (например, «в этой точке программы при получении символа a алгоритм завершает цикл, а для остальных символов – продолжает его»). Аналогично, каждое состояние КА имеет свою «смысловую» нагрузку, например «накопление идентификатора», «ожидание символа * после /» и т. п..
Проектирование КА с помощью диаграммы состояний-переходов происходит содержательно. Определяются состояния КА, им присваивается «смысл», а затем определяется, при каких условиях происходит переход из одного в другое.
Особенности автоматов для лексического анализа
Особенностью реализации КА в лексическом анализе является то, что каждой лексеме соответствует свой независимый цикл (последовательность состояний КА). Для этого в КА вводятся особые заключительные состояния:
· достижение автоматом заключительного состояния рассматривается как факт обнаружения некоторой лексемы. Каждому заключительному состояния соответствует своя распознанная лексема. Это позволяет отказаться от выходных сигналов;
· значением накопленной лексемы является часть входной строки, просмотренная автоматом при его работе от начального до конечного состояния;
· при достижении конечного состояния КА принудительно сбрасывается в начальное состояние.
Введение заключительных состояний приводит к появлению еще одного неканонического действия, обусловленного разделением процессов распознавания лексем. С каждым заключительным состоянием КА необходимо связать фиксированное число возвращаемых символов. Дело в том, что процесс распознавания лексем, не имеющих явно заданных ограничителей, завершается чтением символов, являющихся началом следующей. Их необходимо возвратить во входную последовательность (произвести «откат» автомата на фиксированное число символов назад). Этот эффект имеет место в раде других случаев, которые будут прокомментированы ниже в примерах. На диаграмме состояний-переходов это отображается так:
· заключительные состояния обозначаются особенно (например, выделяются цветом), именуются или нумеруются отдельно (например, отрицательными числами);
· рядом с каждым заключительным состоянием записывается количество возвращаемых символов;
· каждая дуга помечается только одним символом (или группой символов) перехода, выходных символов КА не продуцирует.
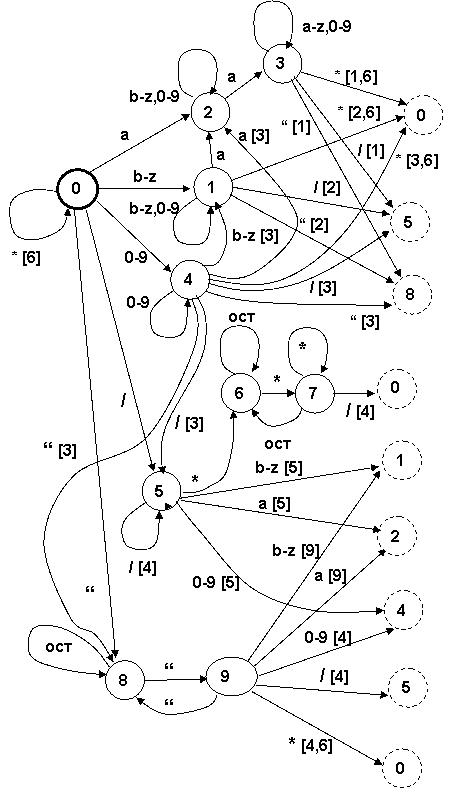
Вот так выглядит диаграмма состояний-переходов для десятичных констант, идентификаторов (в том числе, содержащих не менее 2 символов a), комментариев, отдельных символов / и *, а также строковых констант (вида ”…””……..”).
 |
Полученный КА можно представить и в табличной форме - в виде таблицы переходов и таблицы заключительных состояний. Для этого всё множество входных символов разбивается на непересекающиеся множества - классы. Классы выбираются таким образом, чтобы обеспечивалось однозначное переключение КА по каждому из них:
· цифры 0-9.
· буква a
· буквы b-z.
· символ “/”.
· символ “*”.
· символ “””.
· остальные символы.
Проще говоря, символы, на которые КА должен обеспечивать различную реакцию, должны быть разнесены в отдельные классы. Далее каждому заключительному состоянию ставится в соответствие константа – количество символов, возвращаемых в выходной поток.
Номер состояния | Лексема | Возврат символов |
-1 | Идентификатор с двумя a | 1 |
-2 | Идентификатор | 1 |
-3 | Константа десятичная | 1 |
-4 | Комментарий | 0 |
-5 | Символ / | 1 |
-6 | Символ * | 0 |
-7 | Константа строковая | 1 |
Ост | 0-9 | a | b-z | / | * | “ | |
S0 | 0 | 4 | 2 | 1 | 5 | -6 | 8 |
S1 | -2 | 1 | 2 | 1 | -2 | -2 | -2 |
S2 | -2 | 2 | 3 | 2 | -2 | -2 | -2 |
S3 | -1 | 3 | 3 | 3 | -1 | -1 | -1 |
S4 | -3 | 4 | -3 | -3 | -3 | -3 | -3 |
S5 | -5 | -5 | -5 | -5 | -5 | 6 | -5 |
S6 | 6 | 6 | 6 | 6 | 6 | 7 | 6 |
S7 | 6 | 6 | 6 | 6 | -4 | 7 | 6 |
S8 | 8 | 8 | 8 | 8 | 8 | 8 | 9 |
S9 | -7 | -7 | -7 | -7 | -7 | -7 | 8 |
В табличной форме все клетки должны быть заполнены: это означает полную определенность автомата – в любом состоянии известна его реакция на любой из входных символов. С этих позиций следует рассматривать переходы по «остальным» символам, обычно это понимается в самом широком смысле как переход по всем символам, кроме явно обозначенных в диаграмме для данного состояния.
Полученный КА включается в программу-распознаватель лексики в табличной форме, что позволяет сделать универсальным алгоритм работы КА, не зависящим от программируемой лексики, которая становится в программе компонентой данных. В архиве приведен простейшая реализация такой программы – (файл исходного текста lexan.cpp).
В программе определяется переменная - текущее состояние КА (переменная ST). Определением класса символа занимается отдельная функция. Функция возвращает номер класса символов, к которому относится ее входной символ, что соответствует номеру столбца матрицы переходов. Матрица переходов в программе - это двумерный массив, который для каждой пары «состояние (строка) и класс символа (столбец)» определяет новое состояние, в которое он переводится. Номер этого состояния и находится в матрице. Принцип заполнения матицы прост: если в состоянии S1 и входном символе L1 на диаграмме имеется дуга (переход) в состояние S2 то элемент массива D[S1][K1] должен быть инициализирован значением S2, где K1=class(L1). В рассматриваемом примере матрица будет выглядеть так:
.
int D[9][8]= {
{ 0, 2, 2, 1, 3, 0, 6, 0 },
{ -1, 1, 1, 1, -1, -1,-1, -1 },
……..
};
Цикл работы КА в программе выглядит так:
for (ST=0,i=0;S[i]!=0;i++) {CL=class(S[i]);ST=D[ST][CL];}
Заключительные состояния нумеруются отрицательными числами, начиная с –1. Для последовательности заключительных состояний –1,-2,-3… в программе заведены два массива: имен лексем и числа возвращаемых символов:
int W[]={ 1,1,0,0,0 };
char *out[]={
"Ident", // Заключительное состояние –1
“Const” // -2
"Сomment", // -3
"String", // -4
"Error", // -5
};
Для фиксации начала цепочки символов, образующих лексему (слово), в программе вводится переменная FIX, которая при любом переходе в начальное (нулевое) состояние запоминает расположение в строке текущего символа.
Сравнение лексического распознавателя с каноническим конечным автоматом
Итак, основная идея лексического анализа состоит в том, что распознать последовательность символов (литер), не имеющих произвольной вложенности, можно при помощи устройства, обладающего только памятью текущего состояния. Единственное средство запомнить какое-либо факт или событие во входной последовательности – ввести соответствующее состояние в диаграмму автомата. Тогда каждое состояние автомата несет в себе смысловую нагрузку, связанную с запоминанием – «находимся внутри идентификатора», «обнаружили символ s внутри идентификатора» и т. п.. Проектирование автоматного распознавателя на уровне диаграммы состояний/переходов на самом деле представляет собой одну из вариаций доисторической технологии «исторического программирования» с использованием блок-схем. Далее мы увидим, что есть средства описания лексики более высокого уровня, базирующиеся на формальных грамматиках.
Наличие специально введенных конечных состояний и связанного с ними процесса возврата символов во входной поток также имеет вполне естественное объяснение. Кроме лексем, имеющих явные символы-ограничители, существуют лексемы, в которых ограничение вводится неявно (например, по отсутствию буквы-цифры как символа продолжения идентификатора). В более сложных случаях ограничителем текущей лексемы может являться начало любой следующей (по принципу «все остальное кроме явно перечисленного»). В таких случаях обнаружение начала следующей лексемы создает такую последовательность событий:
· завершение распознавания предыдущей лексемы;
· возврат символов, соответствующих началу текущей лексемы;
· сброс автомата в исходное состояние;
· повторное распознавание начала текущей лексемы.
Подобное решение позволяет сделать независимыми цепочки состояний распознавания для разного типа лексем. Если же отказаться от такой «опции» и вернуться к каноническому автомату, то в нем могут появиться состояния, соответствующие сразу паре лексем (окончание предыдущей и начало текущей), причем их количество будет пропорционально числу возможных сочетаний таких пар (напомним, что автомат обладает только памятью текущего состояния), либо возникнут множественные переходы, сопровождаемые выходным сигналом (символом) распознавания лексемы. Проиллюстрируем сказанное предыдущим примером (в квадратных скобках указаны номера классов распознаваемых лексем – выходные сигналы автомата).
 |
