
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лабораторная работа № 000
ПОСТРОЕНИЕ И РЕАЛИЗАЦИЯ ЭФФЕКТИВНЫХ КОДОВ
Целью работы является усвоение принципов построения и технической реализации кодирующих и декодирующих устройств эффективных кодов.
1.1. Указания к построению кодов
Учитывая статистические свойства источника сообщений, можно минимизировать среднее число двоичных символов, требующихся для выражения одной буквы сообщений, что при отсутствии шума позволяет уменьшить время передачи или емкость запоминающего устройства. Такое эффективное кодирование базируется на основной теореме Шеннона для каналов без шума.
К. Шеннон доказал, что сообщения, составленные из букв некоторого алфавита, можно закодировать так, что среднее число двоичных символов на букву будет сколь угодно близко к энтропии источника этих сообщений, но не менее этой величины.
Теорема не указывает конкретного способа кодирования, но из нее следует, что при выборе каждого символа кодовой комбинации необходимо стараться, чтобы он нес максимальную информацию. Следовательно, каждый символ должен принимать значения 0 или 1 по возможности с равными вероятностями, и каждый выбор должен быть независим от значений предыдущих символов.
Для случая отсутствия статистической взаимосвязи между буквами конструктивные методы построения эффективных кодов были даны впервые Шенноном и Фено. Их методики существенно не отличаются, и поэтому соответствующий код получил название кода Шеннона - Фено.
Код строится следующим образом: буквы алфавита сообщений выписываются в таблицу в порядке убывания вероятностей их встречаемости. Затем их разделяют на две группы так, чтобы суммы вероятностей встречаемости букв в каждой из групп были бы по возможности одинаковыми. Всем буквам верхней половины в качестве первого символа записывается – 1, а всем нижним – 0. Каждая из полученных групп, в свою очередь, разбивается на две подгруппы с одинаковыми суммарными вероятностями и т. д. Процесс повторяется до тех пор, пока в каждой подгруппе не останется по одной букве.
Все буквы будут закодированы различными последовательностями символов из “0” и ”1” так, что ни одна более длинная кодовая комбинация не будет начинаться с более короткой, соответствующей другой букве. Код, обладающий этим свойством, называется префиксным. Это позволяет вести запись текста без разделительных символов и обеспечивает однозначность декодирования.
Рассмотрим алфавит из 8 букв. Ясно, что при обычном (не учитывающем вероятностей встречаемости их в сообщениях) кодировании для представления каждой буквы требуется 3 символа (![]() ), где M – количество букв в алфавите.
), где M – количество букв в алфавите.
Наибольший эффект "сжатия" получается в случае, когда вероятности встречаемости букв представляют собой целочисленные отрицательные степени двойки. Среднее число символов на букву в этом случае точно равно энтропии. В более общем случае для алфавита из 8 букв среднее число символов на букву будет меньше трех, но больше энтропии алфавита H(M).
![]()
Для алфавита, приведенного в табл.1.1, энтропия H(M) равна 2.76, а среднее число символов на букву:
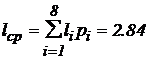 ,
,
где li – количество символов для обозначения i-ой буквы.
Таблица 1.1
Буква | Вероятности | Кодовая комбинация | № деления |
A1 A2 A3 A4 A5 A6 A7 A8 | 0.22 0.20 0.16 0.16 0.10 0.10 0.04 0.02 | 11 101 100 01 001 0001 00001 00000 | II III I IV V VI VII |
Следовательно, некоторая избыточность в кодировании букв осталась. Из теоремы Шеннона следует, что эту избыточность можно устранить, если перейти к кодированию блоками.
Рассмотрим сообщения, образованные с помощью алфавита, состоящего всего из двух букв А1 и А2 с вероятностями появления соответственно
Р1 (А1)=0,9 и Р2(А2)=0,1.
Поскольку вероятности не равны, то последовательность из таких букв будет обладать избыточностью. Однако, при побуквенном кодировании мы никакого эффекта не получим.
Действительно, на передачу каждой буквы требуется символ либо 1, либо 0, в то время как энтропия равна 0,47. При кодировании блоками, включающими по две буквы, получим табл. 1.2. Так как буквы статистически не связаны, вероятности встречаемости блоков определяют как произведение вероятностей составляющих их букв.
Таблица 1.2
Буква | Вероятности | Кодовая комбинация | № деления |
А1А1 А1А2 А2А1 А2А2 | 0.81 0.09 0.09 0.01 | 1 01 001 000 | I II III |
Среднее число символов на блок получается равным 1.29, а на букву – 0.645.
Кодирование блоков, включающих по три буквы, дает еще больший эффект. Среднее число символов на блок в этом cлучае равно 1,59, а на букву – 0,53, что всего на 12% больше энтропии. Теоретический минимум Н(M)=0,47 может быть достигнут при кодировании блоков, включающих бесконечное число букв:
![]()
Следует подчеркнуть, что уменьшение lср при увеличении числа букв в блоке не связано с учетом статистических связей между соседними буквами, так как нами рассматривались алфавиты с некоррелированными буквами. Повышение эффективности определяется лишь тем, что набор вероятностей, получающийся при укрупнении блоков, можно делить на более близкие по суммарным вероятностям подгруппы.
Для учета взаимосвязи между буквами текста, кодирование очередной буквы необходимо вести с учетом предыдущей последовательности букв в зависимости от глубины этой связи. При таком кодировании энтропия на одну букву уменьшается, но существенно усложняется система кодирования, поскольку приходится учитывать не один столбец вероятностей, а Mm столбцов, где m – глубина взаимосвязи между соседними буквами.
Рассмотренная нами методика Шеннона - Фено не всегда приводит к однозначному построению кода, так как, разбивая на подгруппы, большей по суммарной вероятности можно сделать как верхнюю, так и нижнюю подгруппы.
Вероятности, приведенные в табл.1.1, можно было бы разбить иначе (табл. 1.3):
Таблица 1.3
Буква | Вероятности | Кодовая комбинация | № разбиения |
A1 A2 A3 A4 A5 A6 A7 A8 | 0.22 0.20 0.16 0.16 0.10 0.10 0.04 0.02 | 11 10 011 010 001 0001 00001 00000 | II I IV III V VI VII |
При этом среднее число символов на букву оказывается равным 2.80. Таким образом, построенный код может оказаться не самым лучшим. При построении эффективных кодов с основанием m>2 неопределенность становится еще больше. От указанного недостатка свободна методика Хаффмена. Она гарантирует однозначное построение кода с наименьшим для данного распределения вероятностей средним числом символов на букву. Для двоичного кода методика сводится к следующему.
Буквы алфавита сообщений выписываются в первый столбец в порядке убывания вероятностей. Две последние вероятности объединяются в одну вспомогательную, которой приписывается суммарная вероятность. Вероятности букв, не участвующих в объединении, и полученная суммарная вероятность снова располагаются в порядке убывания вероятностей в дополнительном столбце, а две последние вероятности снова объединяются. Процесс продолжается до тех пор, пока не получим единственную вспомогательную вероятность равную единице. Поясним методику на примере (табл. 1.4). Значения вероятностей примем те же, что и в табл. 1.1.
Для получения кодовой комбинации, соответствующей данной букве, необходимо проследить путь перехода ее вероятности по строкам и столбцам табл. 1.4. Для наглядности построим кодовое дерево. Из точки, соответствующей вероятности 1, направим две ветви, причем ветви с большей вероятностью присвоим символ 1, а с меньшей – 0. Такое последовательное ветвление продолжим до тех пор, пока не дойдем до вероятности каждой буквы. Кодовое дерево для алфавита букв, рассматриваемого в нашем примере, приведено на рис. 1.1.
Таблица 1.4
Буква | Вероятности | Вспомогательные столбцы | ||||||
A1 A2 A3 A4 A5 A6 A7 A8 | 0.22 0.20 0.16 0.16 0.10 0.10 0.04 0.02 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
0.22 0.20 0.16 0.16 0.10 0.10 0.06 | 0.22 0.20 0.16 0.16 0.16 0.10 | 0.26 0.22 0.10 0.16 0.16 | 0.32 0.26 0.22 0.20 | 0.42 0.32 0.26 | 0.58 0.42 | 1 |
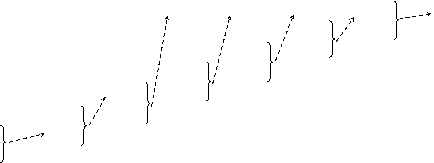
Теперь, двигаясь по кодовому дереву от единицы через промежуточные вероятности к вероятностям каждой буквы, можно записать соответствующую ей кодовую комбинацию: А1 - 01, А2 - 00, А, А, А, А6-1011, А, АПри этом получим lср =2,80 символа на букву.
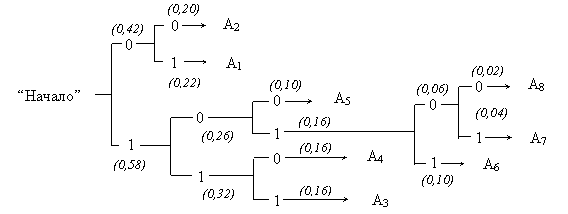 |
Рис. 1.1. Кодовое дерево
Отметим в заключение особенности систем эффективного кодирования.
Одна из особенностей обусловлена различием в длине кодовых комбинаций для разных букв. Если буквы выдаются через равные промежутки времени, то кодирующее устройство через равные промежутки времени выдает комбинации различной длины. Поскольку линия связи используется эффективно только в том случае, когда символы поступают в нее с постоянной скоростью, то на выходе кодирующего устройства должно быть предусмотрено буферное устройство ("упругая" задержка). Оно запасает символы по мере их поступления и выдает их в линию связи с постоянной скоростью. Аналогичное устройство необходимо и на приемной стороне.
Вторая особенность связана с возникновением задержки в передаче информации. Наибольший эффект достигается при кодировании длинными блоками, а это приводит к необходимости накапливать буквы, прежде чем сопоставить им определенную последовательность символов. При декодировании задержка возникает снова. Общее время задержки может быть велико, особенно при появлении блока, вероятность которого мала. Это следует учитывать при выборе длины кодируемого блока.
Еще одна особенность заключается в специфическом влиянии помех на достоверность приема. Одиночная ошибка может перевести передаваемую кодовую комбинацию в другую, не равную ей по длительности. Это повлечет за собой неправильное декодирование целого ряда последующих комбинаций, который называют треком ошибки. Специальными методами построения эффективного кода трек ошибки стараются свести к минимуму.
1.2. Программные и технические средства реализации
Лабораторная работа выполняется на ПЭВМ, подключенных к локальной сети кафедры. При проведении занятий на кафедре ВМСС необходимо при помощи определенных команд войти в кафедральную сеть. Затем запустить на выполнение программ Effectcoding. exe и HUFFMAN. EXE. В HUFFMAN. EXE строится кодирующее устройство по методу Шеннона-Фено, потом – по методу Хаффмена, а наконец, строится дерево Хаффмена.
1.3. Описание сборки устройств для реализации эффективных кодов
Работу рекомендуется начать со сборки кодирующего устройства – кодера (рис.1.2).
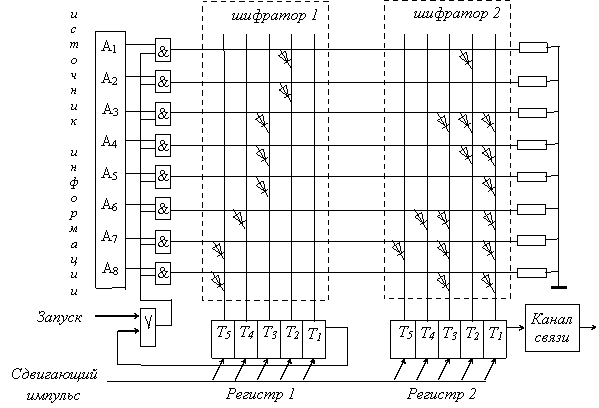 |
Рис. 1.2. Пример схемы кодирующего устройства
Устройство включает схему получения моментов считывания очередной буквы (матричный шифратор 1 с регистром сдвига 1) и шифратор букв (матричный шифратор 2 с регистром сдвига 2). Число горизонтальных шин шифраторов равно числу кодируемых букв, а число вертикальных шин в каждом из них равно числу символов в самой длинной комбинации используемого кода. Схема рассчитана на использование алфавита из 6-8 букв (сообщений). Источник информации удовлетворяет требованиям идеального источника по Хартли, т. е. в каждый данный момент он возбуждает шину только одной буквы, выставляя на нее сигнал "1". В регистре 1 появляется сигнал "1" в разряде соответствующем длине кодовой комбинации буквы, что обеспечивается диодным переходом. В регистре 2 появляется код соответствующий букве, шина которой возбуждена. Что тоже обеспечивается соответствующими диодными переходами с возбужденной шины на триггеры регистра 2. Сдвигающими импульсами код буквы последовательно выталкивается в канал связи, а единица "вытолкнутая" из регистра 1 разрешает источнику выдать очередную букву.
При выполнении домашней подготовки студент должен построить эффективный код, используя методики Шеннона-Фено и Хаффмена. В первой части лабораторной работы применяется кодирование по Шеннону - Фено. На экране представлена заготовка схемы кодера. Необходимо правильно расставить диоды шифраторов. Текущее соединение отображается красной пунктирной линией, которую можно перемещать кнопками управления ←↑→↓. Фиксируется соединение кнопкой +. В случае ошибки снять соединения можно с помощью все той же кнопки. Переключение между схемами осуществляется на главной форме.
Протестируйте схему для каждой буквы. Исправьте допущенные ошибки.
Сборка декодирующего устройства – декодера производится аналогично сборке кодера рис 1.3.
Информация поступает из канала связи в приемный регистр 3. Регистр 3 состоит из триггеров, количество которых на один больше, чем самая длинная кодовая комбинация одной из букв алфавита. В начальном состоянии в регистре 3 в триггере T6 записана “1”. Перемещаясь по регистру сдвигающими импульсами по мере приема информации из линии связи, она информирует о приеме очередной буквы. Когда кодовая комбинация буквы разместится в регистре 3 полностью, в этот момент должна схема совпадения “И”, соответствующая принятой букве.
Для этого на все входы схемы "И" этой буквы должны быть поданы сигналы "1" через диоды, подключенные к триггерам регистра 3, состояния которых соответствуют кодовой комбинации принятой буквы. Если триггер находится в состоянии "1", то диод подключается к правому или единичному выходу, а если в состоянии "0", то к левому или нулевому выходу. Срабатывание схемы "И" принятой буквы индицирует ее и через схему “ИЛИ” сбрасывает в ноль все разряды регистра 3, кроме первого, в котором снова выставляется "1". После этого схема декодера готова к приему очередной буквы.
После завершения сборки производится тестирование декодера для каждой буквы.
Схема кодера работает потактно. Причем процессы кодирования и передачи сигналов разделены, что позволяет четко проследить прохождение каждого сигнала по схеме. Закодированная последовательность выходит из схемы в "перевернутом" виде (справа-налево).
Затем производим проверку работы декодера. Управление схемой декодирования аналогично управлению схемой кодирования. После завершения процесса декодирования проверьте соответствие закодированных и декодированных букв. Далее рекомендуется запустить декодер с изменением в одном разряде и выяснить как это отразится на декодировании.
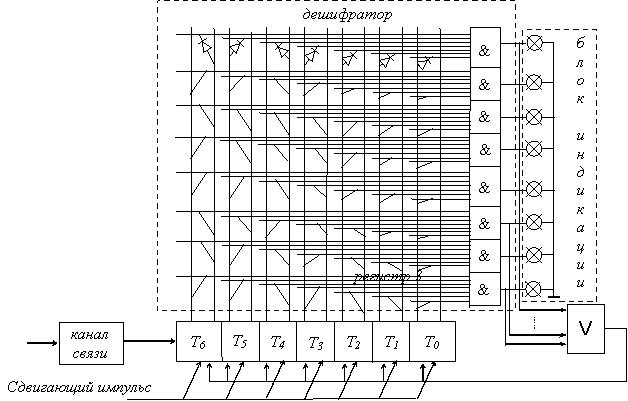
Рис. 1.3. Пример декодирующего устройства
Во второй части лабораторной работы применяется кодирование по Хаффмену. Порядок действий аналогичен выполнению первой части лабораторной работы.
Заключительной частью лабораторной работы является построение дерева Хаффмена для кодирования небольшого текста с помощью программы HUFFMAN. EXE. Эта часть является чисто демонстрационной. В ней шаг за шагом рассматривается процесс кодирования и построения дерева Хаффмена.
В окно с надписью "Текст для кодирования" вводится подготовленный текст. Во всех случаях для продолжения работы нажимается F10, для возврата назад – F9, подсказка – F1. Рядом в окне показывается частота появления букв в тексте. Для удобства можно передвигаться по тексту и выбрав любую букву клавишей <ENTER>, наглядно посмотреть эту букву в тексте. Она будет выделена другим цветом.
На следующем этапе строится дерево Хаффмена. Дерево расшифровывается следующим образом. Красный прямоугольник – узел дерева, соответствующий букве. В нижней половине прямоугольника выводится сама буква, а в верхней – количество вхождений этой буквы в текст. Серые узлы дерева – узлы, которые получились в процессе свертки. Число внутри такого узла показывает общую сумму вхождений. Каждому ребру дерева присваивается “0” или “1”. Чтобы определить код конкретной буквы, входящей в текст, необходимо пройти путь от начала дерева до этой буквы в его конце, накапливая символы (“0” или “1”) при перемещении по ребрам дерева.
1.4. Описание программы Effectcoding. exe
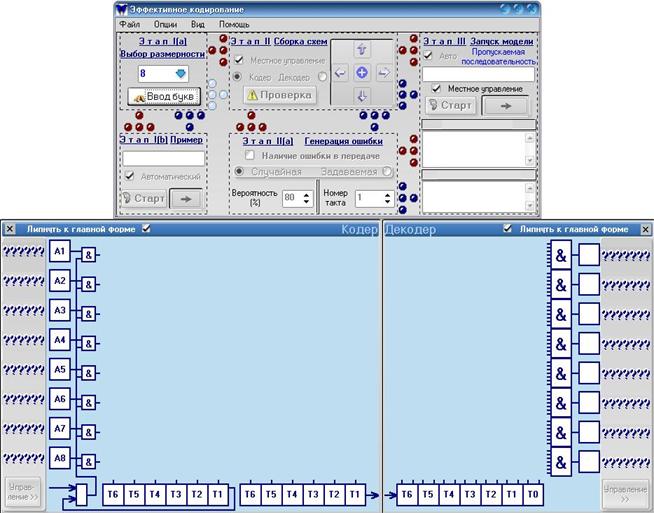
рис.1
На рис.1 представлен общий вид программы. Работа с ней состоит из 5 возможных этапов: 1 – Выборка размерности, 2 – Пример (автоматическое кодирование и запуск устройств по заданным пользователем буквам), 3 – Сборка схем, 4 – Генерация ошибки в сообщении при прохождении его через канал связи, 5 – Запуск модели кодер-канал связи-декодер.
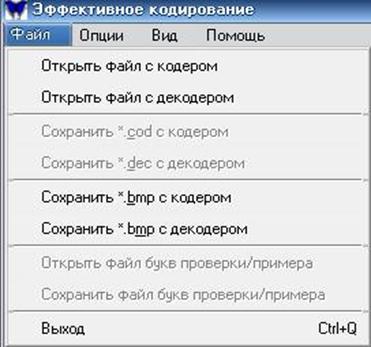
рис.2
На рис.2 показан путь Меню→Файл – здесь: первые четыре опции – открытие и сохранение файлов, хранящих кодеры и декодеры соответственно. Пятая и шестая опции – сохранение картинок кодера и декодера, седьмая и восьмая – открытие и сохранение файлов с сообщениями.

рис.3
На рис.3 показан путь Меню→Вид – здесь: первые три опции скрывают/показывают соответствующие окна, четвёртая – сворачивает главное окно (если не хватает места на экране), пятая – меняет язык интерфейса (в случае отсутствия настроек русского).
Этап Выбора размерности.
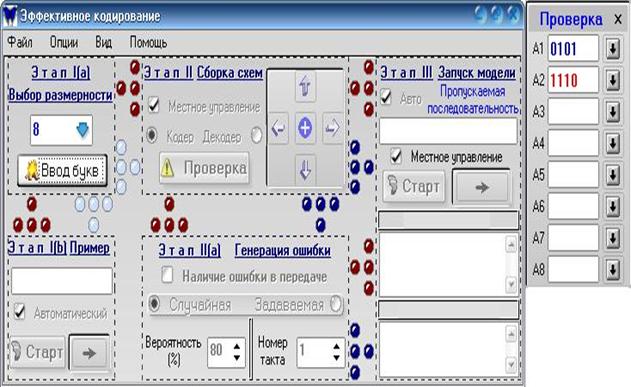
рис.4
На рис.3 показано окно Проверки, вызываемое кнопкой Ввод букв. В данное окно можно вводить слова вашего сообщения, причём: 1) если ваше исходное слово 0010, то ввести следует 0100 (“обернуть”) – именно в таком виде ваше исходное слово должно кодироваться на схеме кодера и подаваться в канал связи; 2) синий цвет то, что данное слово не сохранено, красный – наоборот.
Вводимые в это окно слова используются на Этапе Сборки схемы для проверки и на Этапе Примера как данные, из которых будет возможно произвести выборку.
Этап Примера.
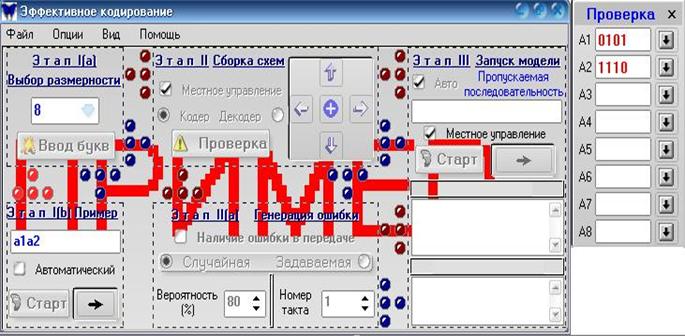
рис.5
Если хоть одна буква введена и сохранена в окне Проверки, то появляется возможность перейти на этап Примера, на котором в поле ввода можно записать любое из сохранённых в окне Проверки слов (на рис.5 – a1a2 {принимаются буквы A и a латинского алфавита}).
Если введённые слова доступны – цвет становится синим (в противном случае - красным) и можно запустить пример – либо автоматический, либо потактовый(рис.6).
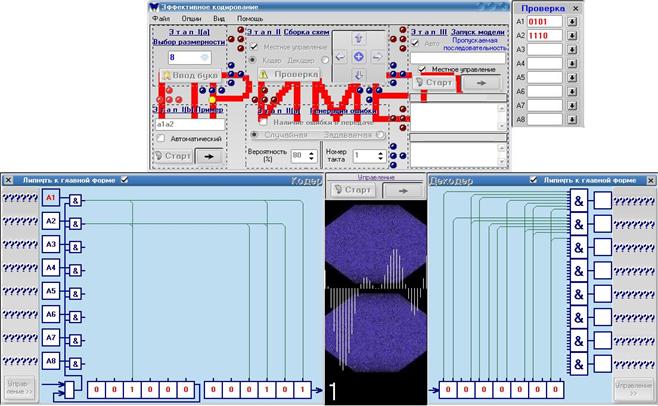
рис.6
Смоделированы будут сборка (нулевой такт), кодирование, прохождение по каналу связи и декодирование (с тактовой задержкой равной 6 тактам).
Перезагрузка процесса производится нажатием появившейся жёлтой точки (см. рис.6), либо переходом обратно на Этап Выбора размерности.
Этап Сборки схем.
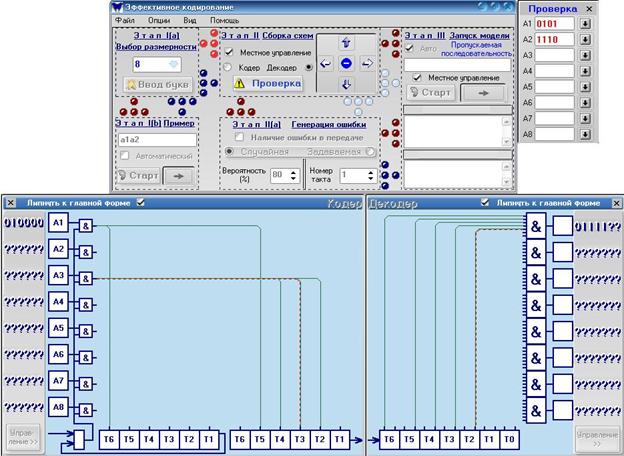
рис.7
Сборка (рис.7) производится на этом этапе в ручную: либо на главной форме, либо на формах кодера или декодера (переключатель Местное управление) .
Кнопка Проверка работает, если в окне Проверки сохранена хотя бы одна буква: проверка (рис.8) возможна лишь при сборке схем на главной форме – к примеру, чтобы осуществить проверку сборки декодера, необходимо переключить управление на него (переключатель Кодер/Декодер).
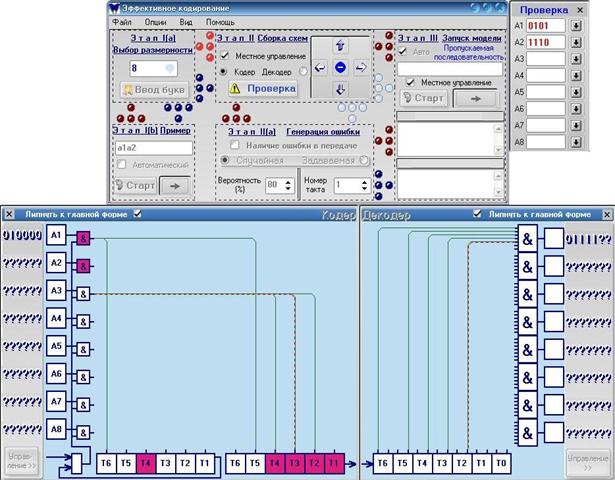
рис.8
Путь Меню→Опции→Свойства процессов приводит к появлению окна Опций, в котором опция Достоверное время проверки есть время в секундах, в течение которого после нажатия кнопки Проверка таковая будет осуществляться вне зависимости от того, правильно собраны схемы или нет.
Замечание: при проверке отмечаются регистры и триггеры, которых не хватает до правильной схемы (соответствующей введённым в окно Проверки словам), и не отмечаются те триггеры, что отмечены неверно.
Этап Генерации ошибки.
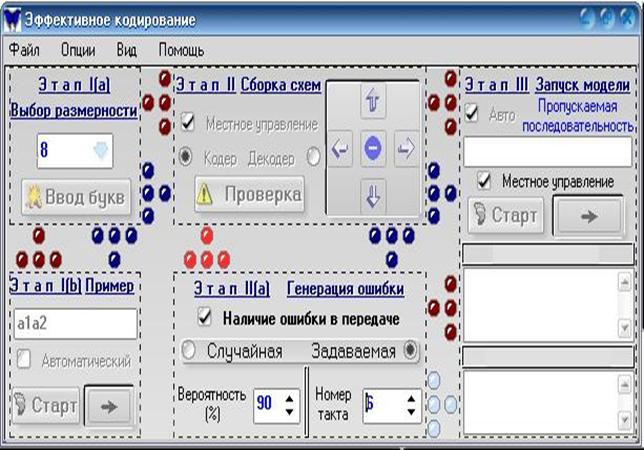
рис.9
Переключатель Наличие ошибки в передаче включает и отключает генерацию ошибки. Ошибка может быть случайной с задаваемой вероятностью появления и задаваемой с вероятностью появления на заданном такте равной 1.
Этап Запуск модели.
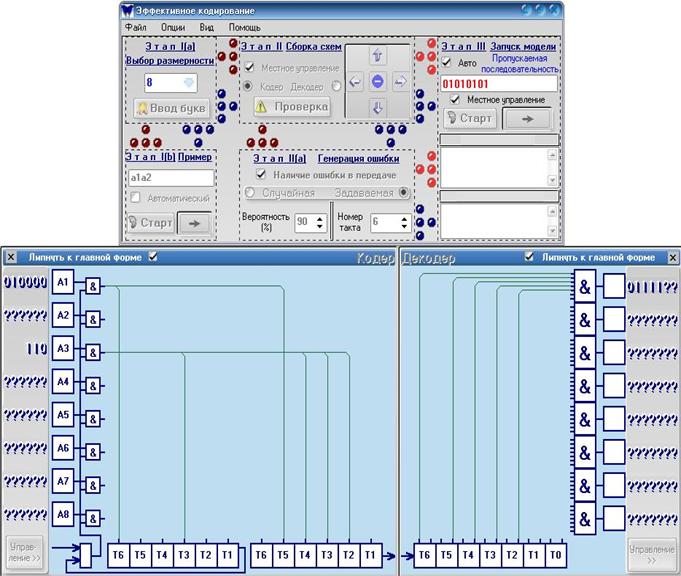
рис.10
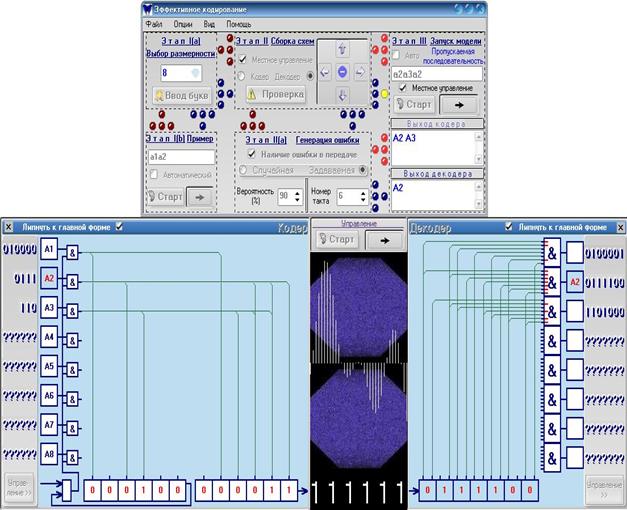
рис.11
В поле ввода этого этапа(рис.10,рис.11) можно ввести либо последовательность из {A1,A2…}, либо из {0,1} – смешивать их нельзя. Необходимым условием возможности моделирования является в первом случае наличие полностью собранных слов кодера и декодера (полностью означает, что цифры напротив соответствующего слова кодера или декодера не должны содержать “?”) с теми номерами, которые были введены в поле ввода данного этапа (например, при вводе a1a3a6a7 – первое, третье, шестое и седьмое слова кодера и декодера, считая сверху вниз, не должны содержать “?”); во втором случае необходима лишь полная сборка хотя бы одного слова декодера.
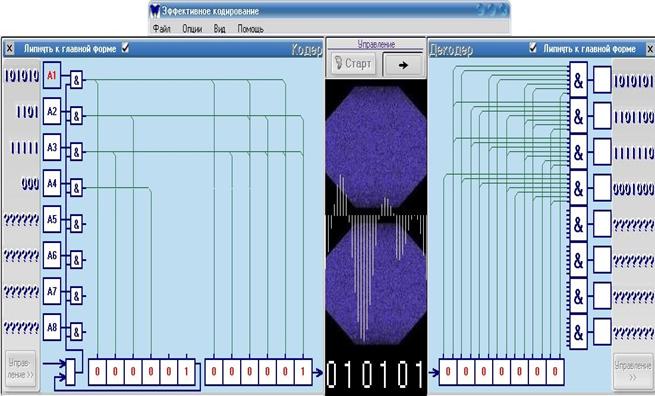
рис.12
На рис.11 показан момент моделирования (управление им аналогично управлению Примером с той лишь разницей, что возможно управлять не с главной формы (переключатель Местное управление) – например, для того, чтобы, скрыв основную форму, увеличить пространство для визуальной среды модели кодер-канал связи-декодер(рис.12)). На кодере загораются слова, которые в данный момент кодируются и передаются в канал связи (со сдвигом по регистрам 1 и 2), на декодере с тактовой задержкой равной 6 тактам происходит распознавание сигнала/кода (со сдвигом по регистру 3) {использование в качестве слов не префиксных кодов приведёт к неверному декодированию}: красные штрихи у сумматоров означают соответствие сигнала с триггера и схемы, их отсутствие означает обратное; цветом выделяются сумматоры, в которых распознано слово, и триггеры, нашедшие хотя бы одно вышеуказанное соответствие.
ПРИМЕЧАНИЕ: предположим, имеются слова 000101 и 01111. Тогда кодировать необходимо последовательность (если смотреть на схеме кодера слева направо по регистру 2) 101000 и 11110. На декодере (регистр 3 слева направо) – 1010001 и 1111010. В окно Проверки следует ввести 101000 и 111010. При моделировании (если вводить последовательность из {0,1}) – 1000101 и 101111.
Примечание 2: учтите, программа плохо переносит “общение” с Microsoft Word!
Примечание 3: программа нестабильна.
Примечание 4: программу нельзя запустить дважды
Примечание 5: если на схеме кодера закодировать две одинаковые буквы, то декодироваться будет лишь первая из них.
ЗАДАНИЕ
Выполняется при домашней подготовке
1. Изучить описание и рекомендованную литературу, изучить методы построения и технической реализации эффективных кодов.
2. По конкретным значениям вероятностей встречаемости букв, заданных студенту преподавателем или выбранно самостоятельно (отличающихся от рассмотренного в описании, не более 8 букв и нетривиальный случай), построить эффективный код, используя методики Шеннона-Фено и Хаффмена.
3. Вычислить энтропию источника и среднюю длину комбинации полученного кода.
4. Подготовить небольшой текст на 150–200 букв для построения дерева кодирования демонстрационной программой.
Выполняется в лаборатории
1. Используя построенный код по методу Шеннона-Фено и Хаффмена правильно расставить диоды в схемах кодирующего и декодирующего устройства.
2. Проверить работоспособность системы передачи.
3. Ввести текст для построения дерева кодирования.
4. Зарисовать таблицу и дерево Хаффмена.
5. Подсчитать выигрыш от записи текста эффективным кодом.
Требования к отчету
Отчет должен включать:
1. таблицу построения эффективного кода по методике Шеннона-Фено;
2. схемы шифратора и дешифратора для построенного кода;
3. таблицу и кодовое дерево, иллюстрирующие построение эффективного кода по методике Хаффмена.
4. Результаты расчетов энтропии источника и среднюю длину кода для буквы, отдельно для заданного Вами алфавита из 8 букв и текста.
Контрольные вопросы
1. Когда целесообразно использовать эффективное кодирование?
2. Каковы сложности в реализации систем передачи с применением эффективных кодов?
3. До какого предела может быть сокращена средняя длина кодовой комбинации?
4. Каковы преимущества методики Хаффмена?
5. Какой код называется префиксным?
6. Как учесть взаимосвязь букв в тексте? Что произойдет с энтропией, если учесть взаимосвязь букв?
ЛИТЕРАТУРА
1. Прикладная теория информации. – M.: Высш. шк., 1989. – 320 с. (С. 184–196).
2. , , Теоретические основы информационной техники. М.: Энергия, 1979.– 512с. (С. 119-131).
