

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Министерство образования и науки Российской Федерации
МОСКОВСКИЙ ФИЗИКО-ТЕХНИЧЕСКИЙ ИНСТИТУТ
(государственный университет)
ФАКУЛЬТЕТ РАДИОТЕХНИКИ И КИБЕРНЕТИКИ
КАФЕДРА ИНФОКОММУНИКАЦИОННЫХ СИСТЕМ И СЕТЕЙ
Сравнительное исследование технологий доступа к реляционным БД на базе нестандартных моделей данных
Магистерская диссертация
студента 517 группы
Научный руководитель
, к. ф.-м. н., доцент
г. Москва
2011
Оглавление
Введение
Постановка задачи
Модели данных
Relational Database
Adaptive Object Model
Универсальная структура данных с метамоделью
Технологии
JDBC
EJB
JPA
Описание реализаций исследуемых технологий
Некоторые усовершенствования
Описание методики тестирования производительности
Окружение, в котором производится тестирование
Сценарии тестирования
Результаты
Описание исследуемых случаев
Результаты
Анализ результатов
«Нестандартная» однотабличная модель данных
Цели
Описание модели, реализации
Результат
Заключение
Список использованных источников
Введение
В условиях постоянно и быстро развивающегося рынка информационных технологий, изменяющихся требований к бизнес-системам, потребности новых решениях для растущего числа задач, перед аналитиками ставится ряд задач, от решения которых кардинально зависит успех разрабатываемой бизнес-системы.
Типичная информационная система содержит следующие составные части:
· База данных
· Бизнес-функциональность
· Пользовательский интерфейс
На данный момент существует немалое множество технологий разработки информационных систем, причем эти технологии затрагивают каждую из перечисленных составных частей ИС. Таким образом, задача аналитика в тесном взаимодействии с ведущим разработчиком – принять решение относительно предпочтительных технологий, их реализаций, способа внедрения в продукт и взаимодействия между собой.
Выбор технологий и способа их внедрения является особенно критичным при проектировании информационной системы. Верно принятое решение на этом шаге зачастую создает условия, при которых разработка продукта сразу направлена в нужное русло, и силами команды разработчиков доводится до готового решения в минимально возможные сроки и с минимальными затратами. Однако ошибка на шаге выбора технологий может оказать существенно негативное влияние на дальнейшую разработку: неоправданные трудозатраты команды разработчиков, невозможность выдать готовое решение к установленному сроку, неоптимальная работа приложения, а в худшем случае – и необходимость пересмотреть выбранный набор технологий и начать разработку с начала.
Таким образом, суть действий аналитика и ведущего разработчика можно выразить следующим. Имеется набор начальных данных (составленных на основе требований заказчика, проработанный аналитиком и вынесенный в документ, обычно называемый Design Specification продукта), к примеру, объем базы данных заказчика, предполагаемое количество пользователей ИС, требуемое время отклика системы, количество и сложность бизнес-процессов, протекающих в системе и т. д. С другой стороны, ведущий разработчик стремится сделать процесс разработки удобным, быстрым, понятным, решая задачи, которые не имеют непосредственного отношения к конкретному продукту, но всегда возникают в программировании: уменьшить объем кода, сделать его по возможности повторно используемым, обеспечить должную масштабируемость системы, позаботиться о поддержке в будущем и даже принять во внимание то, что впоследствии бизнес правила, процессы, модели данных в системе могут измениться, таким образом требуя изменения логики работы приложения. В итоге, на основании бизнес-требований приложения и с учетом требований к разработке, составляется Техническое Задание, по которому работают непосредственно разработчики. Это самое ТЗ и являет собой перечисление технологий, рекомендованных к использованию, и рекомендации по внедрению их в программный продукт.
Помимо предопределенного набора технологий в качестве отправной точки к решению поставленной задачи перед ведущими разработчиками и аналитиками стоит выбор объектной модели данных, а реализация модели целиком и полностью перекладывается на ответственность непосредственно разработчиков. В различных условиях постановки задачи (размеры базы данных, сложность и комплексность бизнес-процессов, количество пользователей приложения) зачастую очень важно на самом первом этапе разработки выбрать подходящую модель данных и воплощать её, согласуя реализацию с соответствующими технологиями, упомянутыми в предыдущем абзаце.
Постановка задачи
Главным аспектом предметной области, с которой сопряжено данное исследование, являются информационные системы. В пользу этого выбора можно привести достаточно большое число аргументов. Перечислим лишь некоторые из них
1. Информационные системы востребованы практически в любой отрасли производства и особенно сферы услуг.
2. Сложность и масштаб информационной системы практически неограниченны: это может быть и информационная система небольшого предприятия (например, учет оборудования на производстве), и работающие в пределах целых городов или государств службы автоматического предоставления информации и услуг (on-line справочные, страховые компании, провайдеры связи и т. д.) и поисковые системы, единые по всему миру (Google; Yahoo и т. д.), и
3. Ввиду многообразия и широкой распространенности информационные системы имеют многочисленные возможности по взаимодействию между собой: обмен сообщениями, всевозможные интеграции систем, API открытого доступа.
Таким образом, исследование, примененное к информационным системам, должно иметь немалое значение не только для систематизации и популяризации знаний по существующим технологиям (в частности, применительно к данному исследованию - доступа к данным), но и для обобщения, уточнения и дополнения знаний, численных результатов и рекомендаций к написанию информационных систем в среде бизнеса, образования и для дальнейших исследований.
Напомним, что перед ведущими разработчиками ставятся задачи, в условиях которых фигурируют следующие условия
· Предполагаемый (или известный) объем данных, обрабатываемых приложением
· Количество пользователей системы
· Структура и сложность бизнес-процессов, протекающих в системе
· Требуемое время отклика системы на ввод пользователя
· Время жизни приложения, необходимость поддержки и сложность
· Необходимость интеграции с другими системами и приложениями
При этом с точки зрения программистов, выполняющих ТЗ, выбор пути решения задачи во многом опирается на следующие понятия, стремясь максимизировать или минимизировать соответствующие численные значения
· Объем кода
· Сложность модели данных
· Масштабируемость
· Возможность повторного использования функциональности
· Конфигурируемость приложения
· Возможность изменять логику в режиме реального времени
В таких разнообразных условиях, и при наличии большого набора вариантов для реализации, вопрос о корректном выборе наборов технологий, моделей данных, способов их взаимодействия становится критически важным с точки зрения бизнеса. И основная поставленная задача сейчас – систематизировать знания, результаты и выводы, полученные в ходе исследования, для придания им информационного и возможно даже рекомендательного характера для той области индустрии программирования, которая занимается разработкой информационных систем.
Для того, чтобы разъяснить в общих словах, что поможет выявить это исследование, поставим несколько вопросов, на которые в заключение данной работы постараемся дать как можно более развернутые ответы, с объяснением сделанного выбора и приведением аргументов в его пользу.
Какую технологию выбрать, если…
· Заранее известен объем данных (который можно кратко охарактеризовать как «большой»), на которых должна работать система, и с течением времени этот объем будет только увеличиваться. При этом большая часть данных должна быть доступна в режиме Read-only, то есть изменяться данные, как и структура данных, будут нечасто. («Справочная»)
· Объем данных заранее известен, но структура данных не фиксирована. Таким образом, в приложении должна присутствовать некая «Административная» составляющая – возможность авторизованных пользователей влиять не только на данные, но и на их представление. В процессе жизнедеятельности приложения может потребоваться необходимость небольшого изменения структуры данных, например, изменение наборов атрибутов у объектов, введение новых типов объектов и т. д. («Оператор связи» - при изменении технологической составляющей телефонной/телекоммуникационной сети может потребоваться изменение структуры хранимой информации)
· Структура данных, как и сами данные, будет меняться стихийно – неизвестно ни начального объема данных, ни его динамики, при этом достаточно большая группа пользователей может вносить изменения и в структуру, и в сами данные («Страховая компания», с постоянно меняющимся набором предоставляемых пакетов услуг и большим числом конечных пользователей, пользующихся этими услугами)
· Модель данных имеет очень сложную структуру – иерархии типов объектов, привязки атрибутов к объектам определяются на каждом уровне иерархии в зависимости от привязки к атрибутным схемам, тоже иерархичным. «Административная» составляющая изменяется редко, но должна быть репрезентативна для пользователей-администраторов, то есть иметь наглядное и легко понимаемое представление («Телекоммуникационный оператор» в масштабах страны: Телекоммуникационные сети, оборудование, учет услуг и предоставление услуг, отдельный каталог пакетов услуг и продуктов и т. д.)
Модели данных
Relational Database
Representing Objects as Tables структура
Наиболее простой способ представление объектной информации в реляционной БД это ROT – для каждого объектного типа заводится отдельная таблица, каждый столбец которой представляет собой объектный атрибут. Таким образом, каждый объект со всеми своими параметрами будет представлен одной записью в этой таблице.
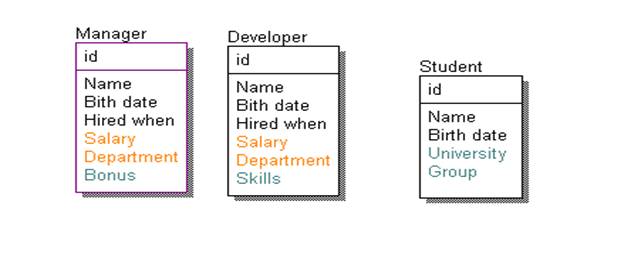
Главное преимущество такого подхода к хранению информации – это его простота. Выборка значения атрибута для любого объекта сводится к выполнению наипростейшего sql запроса:
select * from manager where id = ?;
Так же очень большим плюсом является возможность накладывать ограничения (constratins) на любой отделаьный атрибут (salary not null), не затрагивая остальные.
Данная модель не поддерживает хранение объектов с иерархической структурой типов. Таким образом общие атрибуты (например, salary, department) приходится дублировать в каждой из таблиц. Большое кол-во типов приводит к большому кол-ву таблиц в системе. Это является существенным минусом данного подхода, т. к. существенно ухудшает масштабируемость системы с точки зрения администрирования БД.
Структура соединенных таблиц (Joined Tables)
Добавив поддержку представления объектов с иерархией типов к предыдущему подходу представления объектной информации ROT, получим следующую структуру:
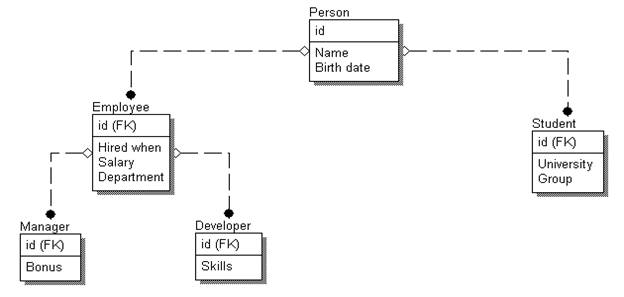
Отличительной чертой является то, что общие атрибуты (hired when, salary, department для типов Manager и Developer) не дублируются в нескольких таблицах, а вынесены в отдельную таблицу, описывающую родительский тип (Employee). Теперь для выборки зарплаты всех сотрудников нужно обратиться только к одной таблице:
select salary from employee
С другой стороны, для получения значения всех атрибутов manager придется обратиться к трем таблицам вместо одной, как это было для ROT:
select *
from person p, employee e, manager m
where p. id = ?
and e. id = p. id
and m.id = p.id;
Аналогично ROT структура с соединенными таблицами имеет недостаток, связанный с большим количеством таблиц.
Adaptive Object Model
Время, когда бизнес-правила глубоко «зашиты» в код приложения исчерпывает себя. Зачастую у пользователей возникает желание изменять логику работы их приложения без написания нового кода. Требуется способность более простой адаптации приложения к изменяющимся нуждам бизнеса, таким образом чтобы каждая система удовлетворяла своим уникальным требованиям.
Сегодня многие информационные системы обязаны быть динамичными и настраиваемыми, так чтобы они могли легко и быстро изменяться чтобы адаптироваться к новым нуждам бизнеса. Обычно это достигается путем вынесения некоторых аспектов системы, таких как бизнес-правила, на уровень базы данных, позволяя тем самым проще и доступнее изменять их. Получающиеся модели позволяют системам адаптироваться быстро за счет только лишь изменения значений в базе данных, а не за счет изменения исполняемого кода. Такой подход также побуждает к разработке и развитию инструментов, позволяющих администраторам систем создавать новые продукты без непосредственно программирования, а также позволяет изменять существующие бизнес-модели прямо в процессе их жизнедеятельности. Это снижает время выдачи новых решений непосредственно заказчику с месяцев до недель и даже дней. Таким образом, настройка системы теперь находится в компетенции тех, кто обладает достаточными знаниями бизнес-процессов, чтобы делать это эффективно.
Адаптивная Объектная Модель (Adaptive Object Model) – система, которая представляет классы, атрибуты, связи между сущностями как метаданные. Такая система основывается в большей степени на экземплярах данных, чем на классах данных. Пользователь изменяет метаданные, чтобы подчеркнуть изменения в доменной модели. Эти изменения влияют непосредственно на поведение системы. Другими словами, такая система сохраняет свою объектную модель в базе данных и имеет сведения о том, как её интерпретировать. Следовательно, объектная модель является активной, когда она изменяется, система изменяется немедленно.
Структура простейшей Адаптивной Объектной модели приведена на рисунке ниже
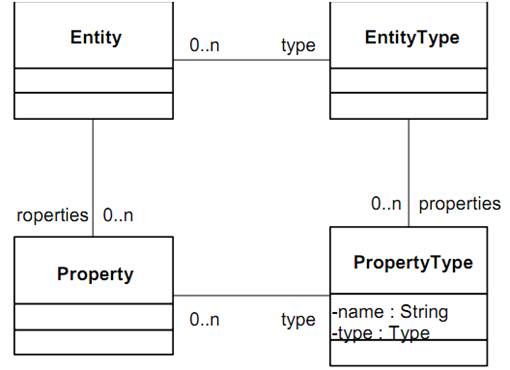
Адаптивная Объектная Модель
EntityType – сущность, представляющая тип (класс, описание) сущности в «стандартной» модели данных. Экземпляры EntityType создаются на каждый тип сущности, содержат информацию об особенностях конкретного типа, могут наследоваться друг от друга.
Entity представляют собой все возможные экземпляры объектов. Entity имеют связь с EntityType, равно как в стандартной модели каждый экземпляр объекта принадлежит какому-нибудь типу, классу или описанию.
PropertyType описывают атрибуты, или поля, объектов. Связь PropertyType с EntityType выражает привязку тех или иных атрибутов к классу или типу. В стандартной модели это соотносится с тем, что внутри описания класса присутствуют и описания полей.
Property представляют непосредственно значение того или иного атрибута. Связь с PropertyType определяет принадлежность конкретного значения тому или иному описанию атрибута. Связь с Entity привязывает значение по конкретному атрибуту к конкретному объекту.
В рамках данной работы используется немного более усложненная адаптивная объектная модель. Наряду с четырьмя сущностями, описанными выше, вводятся атрибутные группы, атрибутные схемы, атрибутные типы, таблица возможных перечислимых значений атрибутов. Связь EntityType-ProprtyType будет типа многие-ко-многим, поэтому появится дополнительная промежуточная таблица для этой множественной связи. Структура используемой модели данных описана в следующем подразделе:
Универсальная структура данных с метамоделью
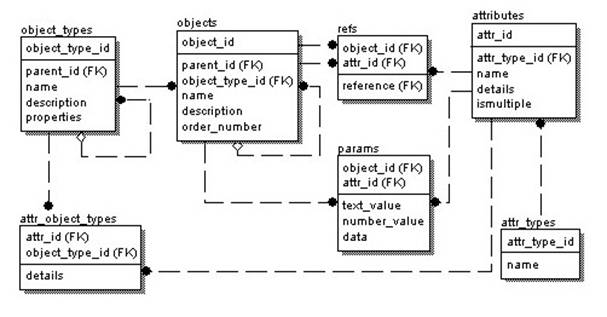
Таблица object_types содержит описание объектных типов (классов) системы. Атрибут object_type_id – уникальный идентификатор, parent_id – ссылка на object_type_id предка в этой же таблице, name – название объектного типа, description – подробное описание объектного типа.
Таблица attributes содержит описание атрибутов. attr_id – уникальный идентификатор атрибута, name – название.
Дополнительно вводится таблица attr_object_types, для реализации связи «многие ко многим» между типами и атрибутами. attr_id – ссылка на attr_id атрибута (в таблице attributes), object_type_id - ссылка на object_type_id (в таблице object_types), к которому относится атрибут.
Таблица objects содержит список экземпляров объектов. Object_id – уникальный идентификтор объекта, object_type_id – ссылка на object_type_id объектного типа (в таблице object_types), к которому относится экземпляр, name – краткое обозначение объекта.
Таблица params содержит значения свойств объектов. Object_id – ссылка на object_id объекта (в таблице objects), attr_id – ссылка на attr_id атрибута (в таблице attributes), text_value, number_value, date – значение этого атрибута для данного объекта в зависимости от типа данных (char, number или date).
Таблица refs содержит значения атрибутов-ссылок на объекты. Здесь object_id – ссылка на object_id объекта, который ссылается (в таблице objects), reference – ссылка на object_id объекта, на который ссылаются (в той же таблице).
Таким образом, таблицы object_types, attributes и attr_object_types содержат описание (метаданные), а таблицы objects, params, refs – сами данные.
Такой подход предполагает явное хранение метаданных об «объектных типах» и их атрибутах, а также (в предельном случае) хранение в одной таблице всех объектов и хранение в одной таблице значений всех (точнее, всех однотипных) атрибутов различных объектов. Дополнительными возможностями подхода является связь «многие ко многим» между атрибутами и объектными типами.
Применение метамодели обладает следующими преимуществами:
· универсальность: предложенная в работе схема может использоваться в любых объектно-ориентированных приложениях без модификации структуры таблиц
· гибкость: изменения в предметной области требуют внесения исправлений только на уровне данных и не влияют на исходный код программы
· по сравнению с известными метамоделями данная модель обладает дополнительными возможностями сложных структур (иерархия объектов, связь многие-ко-многим между атрибутами и объектными типами).
Однако такой подход при всех очевидных плюсах имеет и ряд серьезных технических проблем.
Недостатки метамодели:
· низкая по сравнению с ROT подходом скорость запросов
· большой объем вспомогательных данных
· ослабленный контроль за целостностью данных
· сложность в понимании структуры при выборке данных
Технологии
JDBC
JDBC (Java Database Connectivity) – технология, позволяющая получать доступ практически к любому источнику табличных данных для Java-приложения. Помимо возможности подключения к большому количеству баз данных SQL, JDBC позволяет получать данные из других источников, таких как обыкновенные файлы. JDBC определяет низкоуровневое API, разработанное для поддержки базовых функциональностей языка SQL независимо от какой-либо конкретной реализации базы данных. Другими словами, основное внимание уделяется выполнению SQL запросов и получению их результатов.
EJB
Enterprise JavaBeans (EJB) – это управляемая компонентная архитектура приложений на стороне сервера, предназначенная для модульного построения корпоративных приложений.
Спецификация EJB является одним из нескольких Java API внутри спецификации Java EE. EJB – серверная модель, которая инкапсулирует бизнес-логику приложения.
Спецификация EJB предназначена обеспечить стандартный путь реализации бизнес-кода, который распространен в корпоративных приложениях. Подобный код зачастую решает одни и те же задачи, и было замечено, что решения этих задач постоянно и многократно «изобретаются» программистами заново. Enterprise JavaBeans предназначена регулировать такие общие подходы, как сохранение данных, транзакционная целостность и безопасность стандартным путем, позволяя разработчикам сосредотачиваться на конкретных проблемах, вверенных им.
Соответственно, спецификация EJB раскрывает детали того, как сервер приложений обеспечивает
· Обработку транзакций
· Интеграцию со службами хранения данных
· Управление конкурентным доступом
· … и многое другое
Entity Bean – это разновидность Enterprise JavaBeans, компонент J2EE приложения на стороне сервера, который представляет долгоживущие данные, сохраняемые в БД. Entity Bean может сам управлять сохранением данных (Bean Managed Persistence) или может делегировать эту функцию своему EJB-контейнеру (Container Managed Persistence). Entity bean уникально идентифицируется по своему первичному ключу. Если контейнер, в котором запущен Entity Bean, потерпит неисправность, Entity bean, его первичный ключ, и любые удаленные ссылки сохранятся.
JPA
Одна из главных направленностей пятой версии Java Platform, Enterprise Edition является простота разработки. Изменения в платформе делают разработку корпоративных приложений с использованием Java технологии намного проще, с гораздо меньшим объемом кода. Следует заметить, что эти упрощения не изменили мощности самой платформы: платформа Java EE 5 поддерживает весь богатый набор функциональности предыдущей версии, J2EE1.4
Разработчики корпоративных систем должны были заметить значительное упрощение технологии Enterprise JavaBeans. Значимым улучшением в технологии EJB стало введение Java Persistence API, который упрощает модель сохранения сущностей в долговременную память и добавляет возможности, недоступные технологии EJB2.1. Java Persistence API управляет тем, как данные из реляционных таблиц отображаются на Java-объекты, на то, как эти объекты сохраняются в базу данных с целью доступа к ним в дальнейшем, и продолжительным поддержанием состояния сущности даже после того, как приложение, использующее её, заканчивает свою работу. В добавок к упрощению модели поддержания состояния сущностей, Java Persistence API стандартизует объектно-реляционные отображения.
Другими словами, с введением Java Persistence API технология EJB3.0 предлагает разработчикам модель программирования сущностей, которая одновременно проще и богаче предыдущих.
Описание реализаций исследуемых технологий
Для реализации технологий было разработано простое Web-приложение с использованием технологии Java Server Pages. Создана универсальная страница, отображающая объект со всеми его параметрами и дочерними объектами. Страница обращается к стандартному классу-помощнику, который предоставляет данные для отображения. В зависимости от исследуемой технологии, этот класс настроен на использование JPA или EJB соответственно. Настройки переключаются на использование другой технологии между испытаниями.
К этому же приложению подключена вспомогательная Web-страница на JSP, в теле которой реализовывались соответствующие сценарии доступа к данным, такие, как доступ к заданному числу объектов последовательно, доступ к объектам и их иерархиям, полям и так далее.
В этом же приложении были встроены подключаемые модули – соответственно, EJB модуль и JPA как часть приложения. Именно эти модули отвечали за доступ непосредственно к данным.
В базе данных была создана структура метамодели. Наполнение данными происходило копированием с эталона базы данных одной из версий реального программного продукта (системы OSS). Дополнительно к этому, в тестовую базу была мигрирована структура телекоммуникационной сети одного из заказчиков. Эта же структура сети заказчика присутствовала в базе и в виде «плоских» таблиц, которые были использованы для исследования реляционной модели хранения данных.
Наряду с реализацией указанных двух технологий доступа, были проведены некоторые усовершенствования подходов, о которых сказано в следующих подразделах.
Некоторые усовершенствования
Поверх рассматриваемых технологий зачастую силами команды разработчиков вводятся некоторые усовершенствования, предназначенные для работы именно в обозначенных условиях конкретной информационной системы и нацеленные на повышение производительности работы системы. Некоторые из этих усовершенствований успешно внедрены и используются известными системами, некоторые будут упомянуты в последующих разделах данного исследования, но некоторые существуют лишь как теоретическая предпосылка для реализации и исследования.
Кэширование данных на стороне Application-сервера
Зачастую данные, которые использует приложение, одновременно или с некоторым небольшим интервалом могут читаться несколькими пользователями (или многократно одним пользователем), при этом на каждое чтение будет приходится обращение к базе данных через сетевой протокол, дисковые операции самой базы данных и процессорное время сервера приложений, затрачиваемое на интерпретацию этих данных. Чтобы избежать избыточных накладок при работе с сетью, дисковыми подсистемами и процессором, вводят кэширование данных на стороне сервера приложений. В этом случае данные, к которым происходит обращение, сразу после считывания из базы помещаются во временное хранилище – кэш сервера приложений, и при последующем обращении к тем же данным (например, по уникальному идентификатору), поиск сперва будет производиться именно по этому временному хранилищу. Если за время между последовательными обращениями к одним и тем же данным они не успели «вытесниться» из кэша – сервер не будет обращаться к базе данных, а использует уже загруженные и интерпретированные данные из кэша. Плюсы и минусы такого подхода очевидны
· + экономия процессорного времени сервера приложений на интерпретацию данных

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
