

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Рисунок 4. Результат выполнение программы
Под «чёрным ящиком» понимается объект исследования, внутреннее устройство которого неизвестно. Понятие «чёрный ящик» предложено . В кибернетике оно позволяет изучать поведение систем, то есть их реакций на разнообразные внешние воздействия и в то же время абстрагироваться от их внутреннего устройства.
Манипулируя только лишь со входами и выходами, можно проводить определенные исследования. На практике всегда возникает вопрос, насколько гомоморфизм «чёрного» ящика отражает адекватность его изучаемой модели, то есть как полно в модели отражаются основные свойства оригинала.
Описание любой системы управления во времени характеризуется картиной последовательности её состояний в процессе движения к стоящей перед нею цели. Преобразование в системе управления может быть либо взаимно-однозначным и тогда оно называется изоморфным, либо только однозначным, в одну сторону. В таком случае преобразование называют гомоморфным.
«Чёрный» ящик представляет собой сложную гомоморфную модель кибернетической системы, в которой соблюдается разнообразие. Он только тогда является удовлетворительной моделью системы, когда содержит такое количество информации, которое отражает разнообразие системы. Можно предположить, что чем большее число возмущений действует на входы модели системы, тем большее разнообразие должен иметь регулятор.
В этом методе программа рассматривается как чёрный ящик. Целью тестирования ставится выяснение обстоятельств, в которых поведение программы не соответствует спецификации. Для обнаружения всех ошибок в программе необходимо выполнить исчерпывающее тестирование, то есть тестирование на всевозможных наборах данных. Для большинства программ такое невозможно, поэтому применяют разумное тестирование, при котором тестирование программы ограничивается небольшим подмножеством всевозможных наборов данных. При этом необходимо выбирать наиболее подходящие подмножества, подмножества с наивысшей вероятностью обнаружения ошибок.
Свойства правильно выбранного теста
- Уменьшает более, чем на одно число других тестов, которые должны быть разработаны для разумного тестирования.
-  Покрывает значительную часть других возможных тестов, что в некоторой степени свидетельствует о наличии или отсутствии ошибки до и после ограниченного множества тестов.
Покрывает значительную часть других возможных тестов, что в некоторой степени свидетельствует о наличии или отсутствии ошибки до и после ограниченного множества тестов.
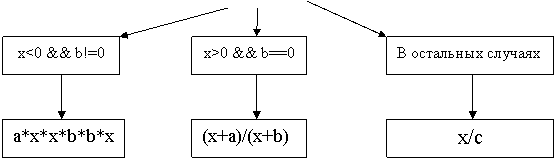 |
Рисунок 5. Дерево разбиений области данных
Приёмы тестирования чёрного ящика
- Эквивалентное разбиение.
- Анализ граничных значений.
- Анализ причинно-следственных связей.
- Предположение об ошибке.
Рассмотрим подробнее каждый из этих методов:
Эквивалентное разбиение
Основу метода составляют два положения:
Исходные данные необходимо разбить на конечное число классов эквивалентности. В одном классе эквивалентности содержатся такие тесты, что, если один тест из класса эквивалентности обнаруживает некоторую ошибку, то и любой другой тест из этого класса эквивалентности должен обнаруживать эту же ошибку.
Каждый тест должен включать, по возможности, максимальное количество классов эквивалентности, чтобы минимизировать общее число тестов.
Разработка тестов этим методом осуществляется в два этапа: выделение классов эквивалентности и построение теста.
Классы эквивалентности выделяются путём выбора каждого входного условия, которые берутся с помощью технического задания или спецификации и разбиваются на две и более группы. Для этого используется следующая таблица:
Входное условие | Правильные классы эквивалентности | Неправильные классы эквивалентности |
Выделение классов эквивалентности является эвристическим способом, однако существует ряд правил:
Если входное условие описывает область значений, например «Целое число принимает значение от 0 до 999», то существует один правильный класс эквивалентности и два неправильных.
Если входное условие описывает число значений, например «Число строк во входном файле лежит в интервале (1..6)», то также существует один правильный класс и два неправильных.
Если входное условие описывает множество входных значений, то определяется количество правильных классов, равное количеству элементов в множестве входных значений. Если входное условие описывает ситуацию «должно быть», например «Первый символ должен быть заглавным», тогда один класс правильный и один неправильный.
Если есть основание считать, что элементы внутри одного класса эквивалентности могут программой трактоваться по-разному, необходимо разбить данный класс на подклассы. На этом шаге тестирующий на основе таблицы должен составить тесты, покрывающие собой все правильные и неправильные классы эквивалентности. При этом составитель должен минимизировать общее число тестов.
Определение тестов:
Каждому классу эквивалентности присваивается уникальный номер.
Если еще остались не включенные в тесты правильные классы, то пишутся тесты, которые покрывают максимально возможное количество классов.
Если остались не включенные в тесты неправильные классы, то пишут тесты, которые покрывают только один класс.
Согласно нашему примеру разобьем входные данные на классы эквивалентности:
Таблица 5. Классы эквивалентности
Входное условие | Правильные классы эквивалентности | Неправильные классы эквивалентности |
-∞<a<∞ | a=; a=; a=0; | - |
-∞<b<∞ | b=; b=; b=0; | - |
-∞<c<∞ | c=; c=; c=0; | - |
-∞<x<∞ | x=; x=; x=0; | - |
По результатам тестирования ошибка алгоритма выявлена в 56 наборах данных в 35 случаях ошибка не была выявлена.
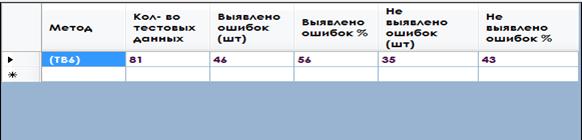
Рисунок 5. Результат работы программы
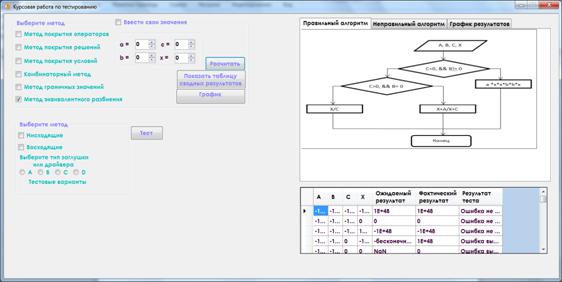
Рисунок 6. Результат выполнения программы
Анализ граничных значений
Граничные условия — это ситуации, возникающие на высших и нижних границах входных классов эквивалентности.
Анализ граничных значений отличается от эквивалентного разбиения следующим:
Выбор любого элемента в классе эквивалентности в качестве представительного осуществляется таким образом, чтобы проверить тестом каждую границу этого класса.
При разработке тестов рассматриваются не только входные значения (пространство входов), но и выходные (пространство выходов).
Метод требует определённой степени творчества и специализации в рассматриваемой задаче.
Существует несколько правил:
Построить тесты с неправильными входными данными для ситуации незначительного выхода за границы области значений. Если входные значения должны быть в интервале [-+1.0], проверяем −1.0, 1.0, −1. 1.000001.
Обязательно писать тесты для минимальной и максимальной границы диапазона.
Использовать первые два правила для каждого из входных значений (использовать пункт 2 для всех выходных значений).
Если вход и выход программы представляет упорядоченное множество, сосредоточить внимание на первом и последнем элементах списка.
Анализ граничных значений, если он применён правильно, позволяет обнаружить большое число ошибок. Однако определение этих границ для каждой задачи может являться отдельной трудной задачей. Также этот метод не проверяет комбинации входных значений.
Согласно нашему примеру исследуем следующие граничные значения:
Таблица 5. Граничные значения
Входное условие | Граничные условия |
-∞<a<∞ | a=00; a=00; a=-0.0; a=0.0; |
-∞<b<∞ | b=00; b=00; b=-0.0; b=0.0; |
-∞<c<∞ | c=00; c=00; c=-0.0; c=0.0; |
-∞<x<∞ | x=00; x=00; x=-0.0; x=0.0; |
По результатам тестирования из 256 наборов входящих данных в 128 ошибка не выявлена, в 128 случаях ошибка выявлена.
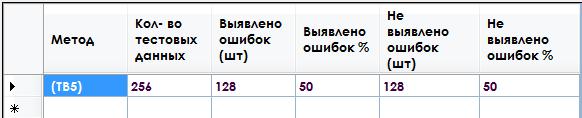
Рисунок 7. Результат выполнения программы
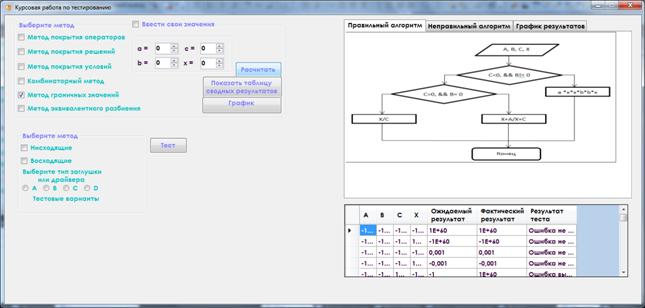
Рисунок 8. Результат выполнения программы
Анализ причинно-следственных связей
Этапы построения теста:
Спецификация разбивается на рабочие участки.
В спецификации определяются множество причин и следствий. Под причиной понимается отдельное входное условие или класс эквивалентности. Следствие представляет собой выходное условие или преобразование системы. Здесь каждой причине и следствию присваивается номер.
На основе анализа семантического (смыслового) содержания спецификации строится таблица истинности, в которой последовательно перебираются всевозможные комбинации причин и определяются следствия для каждой комбинации причин.
Таблица снабжается примечаниями, задающими ограничения и описывающими комбинации, которые невозможны. Недостатком этого подхода является плохое исследование граничных условий.
Нисходящее тестирование
Модули объединяются сверху вниз по управляющей иерархии, начиная с главного управляющего модуля. Подчиненные модули добавляются в структуру или в результате поиска в глубину, или в результате поиска в ширину.
1. Главный управляющий модуль (вершина иерархии) используется как тестовый драйвер. Все непосредственно подчиненные ему модули временно замещаются заглушками.
2. Одна из заглушек заменяется реальным модулем. Модуль выбирается поиском в ширину или глубину.
3. После подключения каждого модуля (и установки в нем заглушек) проводится набор тестов, проверяющий полученную структуру.
4. Если в модуле-драйвере уже нет заглушек, производится смена модуля драйвера (поиском в глубину или ширину).
5. Выполняется возврат на шаг 2 (до тех пор пока не будет построена целая структура).
Достоинство нисходящей интеграции: ошибки в главной, управляющей части системы выявляются в первую очередь.
Недостаток: трудности в ситуациях, когда для полного тестирования на верхних уровнях нужны результаты обработки нижних уровней.
Для борьбы с указанным недостатком существуют три решения:
1) откладывать некоторые тесты до замещения заглушек модулями;
2) разрабатывать заглушки, частично выполняющие функции модулей;
3) подключать модули движением снизу вверх.
Первое решение вызывает сложности в оценке результатов тестирования.
Для реализации второй возможности выбирается одна из следующих категорий заглушек:
- заглушка А – отображает проходящий параметр;
- заглушка В – отображает трассируемое сообщение;
- заглушка С - возвращает величину из таблицы;
- заглушка D – выполняет табличный поиск по ключу (входному параметру) и возвращает связанный с ним выходной параметр.
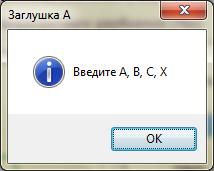
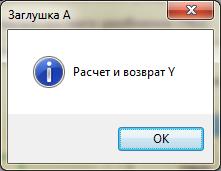
Рисунок 9. Выполение нисходящего тестирования (заглушка А)
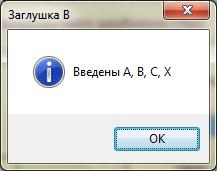
Рисунок 10. Выполение нисходящего тестирования (заглушка В)

Рисунок 11. Выполение нисходящего тестирования (заглушка С)
Рисунок 12. Выполение нисходящего тестирования (заглушка D)
Восходящее тестирование
При восходящем тестировании интеграции сборка и тестирование системы начинается с модулей- атомов (нижний уровень иерархии). Модули подключаются движением снизу вверх. Подключенные модули всегда доступны, и нет необходимости в заглушках.
Шаги методики восходящей интеграции.
1. Модули нижнего уровня объединяются в кластеры (группы, блоки), выполняющие определенную программную функцию.
2. Для координации вводов – выводов тестового варианта пишется драйвер, управляющий тестированием кластеров.
3. Тестируется кластер.
Драйверы удаляются, а кластеры объединяются в структуру движением вверх
Драйверы могут быть различных типов:
- драйвер А – вызывает подчиненный модуль;
- драйвер В – посылает элемент данных (параметр) из внутренней таблицы;
- драйвер С – отображает параметр из подчиненного модуля;
- драйвер D – является комбинацией драйверов В и С.
Сравнение нисходящего и восходящего тестирования интеграции
Нисходящее тестирование
1) основной недостаток – необходимость заглушек и связанные с ним трудности тестирования;
2) основное достоинство – возможность раннего тестирования главных управляющих функций.
Восходящее тестирование
1) основной недостаток – система не существует как объект до тех пор, пока не будет добавлен последний модуль;
2) основное достоинство –упрощается разработка тестовых вариантов, отсутствуют заглушки.
Возможен комбинированный подход, при котором для верхних уровней интеграции применяют нисходящую стратегию, а для нижних уровней – восходящую.
При проведении тестирования интеграции очень важно выявить критические модули. Признаки критического модуля:
1) реализует несколько требований к программной системе;
2) имеет высокий уровень управления (находится достаточно высоко в программной структуре);
3) имеет высокую сложность или склонность к ошибкам (как индикатор может использоваться цикломатическая сложность – ее разумный верхний предел составляет 10);
4) имеет определенные требования к производительности обработки.
Критические модули должны тестироваться как можно раньше. Кроме того, к ним должно применяться регрессионное тестирование (повторение уже выполненных тестов в полном или частичном объеме).
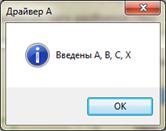
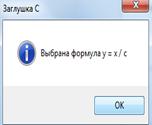
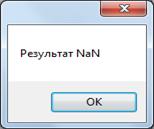
Рисунок 13. Выполение восходящего тестирования (драйвер А)
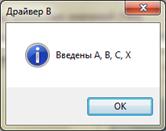
Рисунок 14. Выполение восходящего тестирования (драйвер В)
Рисунок 15. Выполение восходящего тестирования (драйвер С)
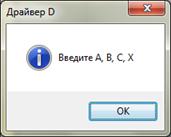
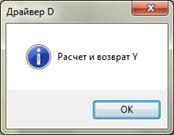
Рисунок 16. Выполение восходящего тестирования (драйвер D)
3. Описание структуры программного комплекса
Программа состоит из модуля кодирования, который состоит из:
1) Подпрограмма решения уравнения с исходным алгоритмом.
2) Подпрограмма решения уравнения с внесенными ошибками.
3) Подпрограмма постройки графика по результатам тестирования.
4) Подстановка в уравнение тестовых данных сформированных методами:
- Метод покрытия операторов
- Метод покрытия решений
- Метод покрытия условий
- Комбинаторный метод
- Метод эквивалентного разбиения
- Метод граничных значений
- Нисходящее тестирование
- Восходящее тестирование
5) Вывода результатов тестирования.
Пользователь запускает программу, и мгновенно используется модуль кодирования, в котором заложен алгоритм решения уравнения и тестирования.
4. Описание структуры программы
Программа состоит из одного диалогового окна.
1. В правом верхнем углу окна находится четыре поля для ручного ввода данных a, b, c, x. Поставив галочку «Ввести значения вручную» данные будут подставлены в исходный алгоритм и алгоритм с ошибками и полученные результаты выводятся в таблицу расположенную в нижней части окна.
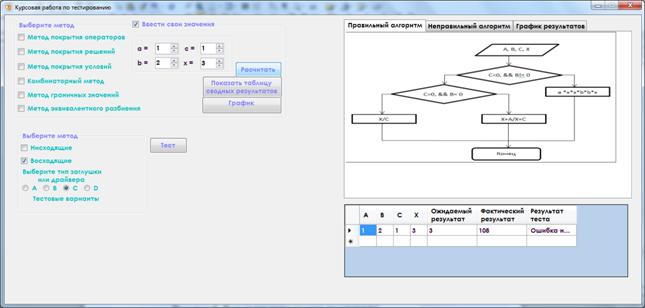
Рисунок 9. Результат выполнения программы
2. Выбрав нисходящее или восходящее тестирование, необходимо выбрать тип заглушки/драйвера, после чего нажать кнопку «Тест». Результаты данных методов тестирования будут отображаться в диалоговых окнах.
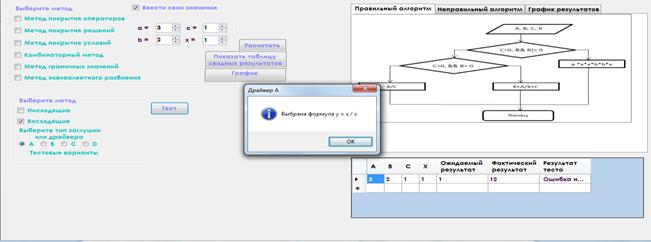
Рисунок 10. Результат выполнения восходящего тестирования (драйвер А)
3. При нажатии на кнопку «Показать таблицу сводных результатов» в нижней части программы отображается таблица, в которой содержатся результаты тестирования. В таблице находится информация о том, сколько ошибок выявлено и сколько не выявлено.
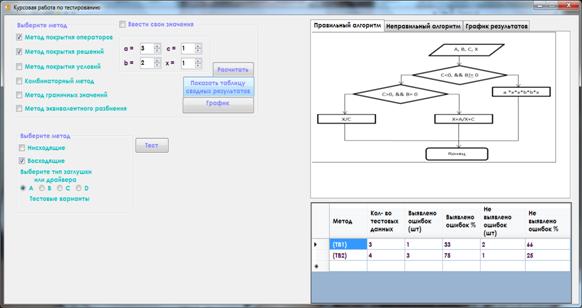
Рисунок 11. Отображение сводной таблицы результатов
3. Таким образом, пользователь может тестировать любым из выбранных методов тестирования, на вкладке «График результатов» выводятся введенные данные и полученные результаты. Результаты тестирования исходного алгоритма и алгоритма с ошибками сравниваются и формируется сводная таблица эффективности тестирования, где учитываются количество наборов данных и количество наборов выявивших ошибки в алгоритме. На основании этих данных строится график.

Рисунок 12. Построение графика результатов тестирования
4. Слева расположена информация о тестируемом алгоритме. Размещен:
- Исходный алгоритм
- Уравнение алгоритма
- Алгоритм с внесенными ошибками
- Сводный график результатов сравнения методов тестирования.
5. Описание программы
Рассмотрим, какие операции выполняются при тестировании алгоритма.
Программа проверяет какие галочки пользователь расставил, и исходя из этого подставляет сформированные данные выбранных методов тестирования. Результаты тестирования выводит в таблицу. При нажатии кнопки на вкладке «График тестирования» выводится сводный график сравнения методов.
Программа тестирует алгоритм следующими методами:
- Метод покрытия операторов
- Метод покрытия решений
- Метод покрытия условий
- Комбинаторный метод
- Метод эквивалентного разбиения
- Метод граничных значений
- Нисходящее тестирование
- Восходящее тестирование
6. Вывод по результатам проектирования
В ходе выполнения курсовой работы проведено тестирование программного алгоритма решения задачи методами «белого ящика», «черного ящика» и интеграционное тестирования. Данные результаты могут быть использованы для сторонних организаций. Закреплены теоретические знания и получены практические навыки. Из проведенного экспериментального исследования следует, что в данном случае самым эффективным методом тестирования оказались «Метод покрытия условий». Он выявил ошибки в алгоритме в 75% из всего набора тестовых данных. На втором месте стоит методы «Покрытия операторов», «Комбинаторный метод» и «Метод эквивалентного разбиения» 66% сформированных наборов данных выявили ошибку.
Вывод: Методы белого ящика показали высокую эффективность выявления ошибок логики. Среди методов черного ящика более эффективным оказался метод эквивалентного разбиения.
Метод тестирования | кол-во наборов данных шт. | Тестовые наборы выявившие ошибку шт. | Процент тестовых наборов выявивших ошибку % | Тестовые наборы не выявившие ошибку шт. | Процент тестовых наборов не выявивших ошибку % |
Метод покрытия операторов | 3 | 2 | 66 | 1 | 33 |
Метод покрытия решений | 4 | 2 | 50 | 2 | 46 |
Метод покрытия условий | 8 | 6 | 75 | 2 | 25 |
Комбинаторный метод | 6 | 4 | 66 | 2 | 33 |
Метод граничных значений | 154 | 128 | 50 | 154 | 50 |
Метод эквивалентного разбиения | 73 | 48 | 66 | 27 | 33 |

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
