

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
КЛАССИФИКАЦИЯ ПОСЛЕДОВАТЕЛЬНОСТЕЙ, ПОРОЖДЕННЫХ БЛИЗКИМИ СКРЫТЫМИ МАРКОВСКИМИ МОДЕЛЯМИ,
ПРИ НАЛИЧИИ ШУМА, РАСПРЕДЕЛЕННОГО ПО ЗАКОНУ КОШИ
,
НГТУ, Новосибирск
E-mail: *****@***ru
Скрытые марковские модели (СММ) являются мощным средством моделирования различных процессов и распознавания образов. По своей природе марковские модели позволяют непосредственно учитывать пространственно-временные характеристики последовательностей, и поэтому получили широкое применение. СММ, тем не менее, не всегда демонстрируют необходимые дискриминирующие свойства, важные в свою очередь для задач классификации.
СММ полностью описывается ненаблюдаемой (скрытой) марковской цепью (которая в свою очередь может быть описана матрицей вероятностей переходов), вероятностями наблюдаемых символов и вероятностями начальных состояний: ![]() . В данной работе рассматривается случай, когда функция распределения вероятностей наблюдаемых символов описывается смесью нормальных распределений. Параметры смеси задаются таким образом, что бы скрытое состояние ассоциировалось лишь с одним своим наблюдаемым состоянием.
. В данной работе рассматривается случай, когда функция распределения вероятностей наблюдаемых символов описывается смесью нормальных распределений. Параметры смеси задаются таким образом, что бы скрытое состояние ассоциировалось лишь с одним своим наблюдаемым состоянием.
Традиционно в качестве пространства для классификации сигналов, порожденных СММ, используется пространство логарифма функции – тестовая последовательность ![]() считается порожденным моделью
считается порожденным моделью ![]() , если выполняется (1):
, если выполняется (1):
| (1) |
Иначе – считается, что последовательность порождена моделью ![]() .
.
Для приближения к реальной ситуации все наблюдаемые последовательности при моделировании подвергались искажению. Задача состояла в сравнении в этих условиях возможностей традиционной методики классификации, основывающейся на (1) с классификатором k ближайших соседей (kNN) в пространстве признаков, в качестве которых использовались первые производные от логарифма функции правдоподобия по параметрам СММ.
Зашумление производилось по двум различным схемам:
| (2) |
| (3) |
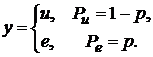
Схема (2) использовалась для моделирования аддитивного шума, а (3) – для вероятностного шума. Оба случая также подразделялись на схему с шумом, имеющим одинаковые параметры в каждом скрытом состоянии модели, и схему с разными параметрами.
Исследования проводились при следующих условиях. Две модели определены на одинаковых по структуре скрытых марковских цепях и различаются только в матрицах переходных вероятностей. В качестве признаков использовались первые производные от логарифма функции правдоподобия по элементам матрицы ![]() конкурирующих моделей. Проводились исследования при разном уровне шума
конкурирующих моделей. Проводились исследования при разном уровне шума ![]() и
и ![]() , различной длине последовательностей, степени близостей моделей по матрице
, различной длине последовательностей, степени близостей моделей по матрице ![]() , количестве обучающих последовательностей. Распределение шума выбиралось как нормальное, так и Коши. Это было сделано для того, чтобы посмотреть, как ведет себя традиционный классификатор в сравнении с классификатором, базирующимся на kNN. Подробную схему предложенного классификатора, а также признаки, используемые для формирования характеристических векторов, в пространстве которых происходит разделение на классы, можно посмотреть в [1], [2]. На рис.1 – рис.4 приведены зависимости процента верно классифицированных сигналов от уровня шума при различном распределении ошибок. На всех рисунках график, отражающий результаты классификации для kNN, имеет пунктирную линию, а график для традиционного подхода – сплошную линию.
, количестве обучающих последовательностей. Распределение шума выбиралось как нормальное, так и Коши. Это было сделано для того, чтобы посмотреть, как ведет себя традиционный классификатор в сравнении с классификатором, базирующимся на kNN. Подробную схему предложенного классификатора, а также признаки, используемые для формирования характеристических векторов, в пространстве которых происходит разделение на классы, можно посмотреть в [1], [2]. На рис.1 – рис.4 приведены зависимости процента верно классифицированных сигналов от уровня шума при различном распределении ошибок. На всех рисунках график, отражающий результаты классификации для kNN, имеет пунктирную линию, а график для традиционного подхода – сплошную линию.
|
|
а) | б) |
Рис.1. Аддитивный шум одинаковый в каждом скрытом состоянии с распределением: | |
|
|
а) | б) |
Рис.2. Аддитивный шум разный в каждом скрытом состоянии с распределением: | |
|
|
а) | б) |
Рис.3. Вероятностный шум одинаковый в каждом скрытом состоянии с распределением: | |
|
|
а) | б) |
Рис.4. Вероятностный шум разный в каждом скрытом состоянии с распределением: |
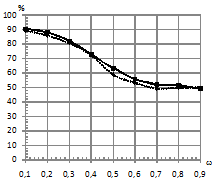
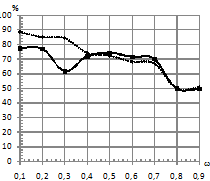
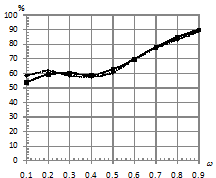
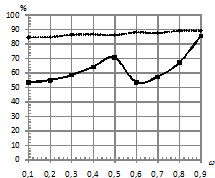
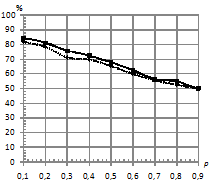
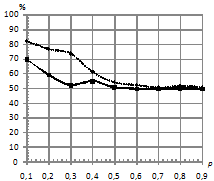
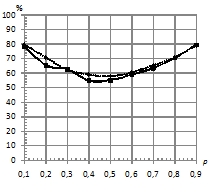
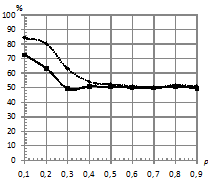
По проведенным экспериментам можно сделать вывод, что традиционный классификатор не проявляет свойство робастности к шуму, распределенному по закону Коши. Объясняется это тем, что данный вид распределения помехи относится к распределениям с тяжелыми хвостами, и в этих условиях оценки параметров нормального распределения, полученные по методу максимального правдоподобия, становятся смещенными (метод максимального правдоподобия задействуется на этапе оценки параметров СММ). При этом оценки дисперсии имеют не просто смещение, а тенденцию к неограниченному росту, что приводит к эффекту сближения моделей в части параметров эмиссионного процесса. Исследования показали, что если использовать классификатор kNN, то при близких по своим параметрам моделях и последовательностях, искаженных помехой, имеющей распределение Коши, удается повысить качество классификации. При этом прирост процентов верной классификации в сравнении с традиционным подходом достигает 30%.
Литература
А. Повышение классификационных свойств скрытых марсковских моделей / Т. А. Гультяева // Информатика и проблема телекоммуникаций: Материалы российской науч.-технич. конф. - Новосибирск: Изд-во СибГУТИ, 2010. - Том I. - с.52-54. Гультяева, Т. А. Вычисление первых производных от логарифма функции правдоподобия для скрытых марковских моделей / // Сборник Научных трудов НГТУ.. – Новосибирск : Изд-во НГТУ, 2010. – № 2(60). – с. 39-46.