


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
Федеральное государственное образовательное учреждение
среднего профессионального образования
«Ростовский государственный колледж информатизации и управления»
Комплект лекционных материалов по дисциплине
“Разработка и эксплуатация удаленных баз данных”
для подготовки к итоговой государственной аттестации
по специальностям
2203 -«Программное обеспечение вычислительной техники и автоматизированных систем»
2204 «Техническое обслуживание средств вычислительной техники и компьютерных сетей»
г. Ростов-на-Дону
2009
Рассмотрено на заседании цикловой методической комиссии программирования и информационных технологий Протокол № ___ от «_____»_________________ ______г. |
Председатель комиссии ______________________________ |
Составитель:
ВОПРОСЫ
1. Основные понятия и свойства реляционной модели данных
2. Этапы проектирования баз данных
3. Нормализация отношений
4. Архитектуры распределенной обработки данных
5. Сервер InterBase. Назначение и возможности. Структура базы данных InterBase
6. Базовая технология доступа COM
7. Понятие транзакции.
8. Средства восстановления баз данных
9. Управление доступом к данным
10. Хранимые процедуры и триггеры. Команда создания триггеров.
ОСНОВНЫЕ ПОНЯТИЯ И СВОЙСТВА РЕЛЯЦИОННОЙ МОДЕЛИ ДАННЫХ
В конце 60-х годов появились работы, в которых обсуждались возможности применения различных табличных даталогических моделей данных, т. е. возможности использования привычных и естественных способов представления данных. Наиболее значительной из них была статья сотрудника фирмы IBM д-ра Э. Кодда, где, вероятно, впервые был применен термин "реляционная модель данных".
Будучи математиком по образованию Э. Кодд предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение). Он показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение – relation (англ.).
Наименьшая единица данных реляционной модели – это отдельное атомарное (неразложимое) для данной модели значение данных. Так, в одной предметной области фамилия, имя и отчество могут рассматриваться как единое значение, а в другой – как три различных значения.
Доменом называется множество атомарных значений одного и того же типа. Смысл доменов состоит в следующем. Если значения двух атрибутов берутся из одного и того же домена, то, вероятно, имеют смысл сравнения, использующие эти два атрибута (например, для организации транзитного рейса можно дать запрос "Выдать рейсы, в которых время вылета из Москвы в Сочи больше времени прибытия из Архангельска в Москву"). Если же значения двух атрибутов берутся из различных доменов, то их сравнение, вероятно, лишено смысла: стоит ли сравнивать номер рейса со стоимостью билета?
Отношение на доменах D1, D2, ..., Dn (не обязательно, чтобы все они были различны) состоит из заголовка и тела..
Заголовок состоит из такого фиксированного множества атрибутов A1, A2, ..., An, что существует взаимно однозначное соответствие между этими атрибутами Ai и определяющими их доменами Di (i=1,2,...,n).
Тело состоит из меняющегося во времени множества кортежей, где каждый кортеж состоит в свою очередь из множества пар атрибут-значение (Ai:Vi), (i=1,2,...,n), по одной такой паре для каждого атрибута Ai в заголовке. Для любой заданной пары атрибут-значение (Ai:Vi) Vi является значением из единственного домена Di, который связан с атрибутом Ai.
Пусть даны n множеств D1, D2, … Dn, тогда отношение R есть множество упорядоченных кортежей <d1, d2, …dn>, где dkÎDk, dk – атрибут, Dk – домен отношения R.
Степень отношения – это число его атрибутов. Отношение степени один называют унарным, степени два – бинарным, степени три – тернарным, ..., а степени n – n-арным.
Кардинальное число или мощность отношения – это число его кортежей.
Поскольку отношение – это множество, а множества по определению не содержат совпадающих элементов, то никакие два кортежа отношения не могут быть дубликатами друг друга в любой произвольно-заданный момент времени. Пусть R – отношение с атрибутами A1, A2, ..., An. Говорят, что множество атрибутов K=(Ai, Aj, ..., Ak) отношения R является возможным ключом R тогда и только тогда, когда удовлетворяются два независимых от времени условия:
1. Уникальность: в произвольный заданный момент времени никакие два различных кортежа R не имеют одного и того же значения для Ai, Aj, ..., Ak.
2. Минимальность: ни один из атрибутов Ai, Aj, ..., Ak не может быть исключен из K без нарушения уникальности.
Каждое отношение обладает хотя бы одним возможным ключом, поскольку по меньшей мере комбинация всех его атрибутов удовлетворяет условию уникальности. Один из возможных ключей (выбранный произвольным образом) принимается за его первичный ключ. Остальные возможные ключи, если они есть, называются альтернативными ключами.
Ключи используют в следующих целях:
1. для исключения дублирования записей;
2. упорядочения кортежей (по возрастанию, по убыванию, смешанное);
3. ускорения работы с кортежами;
4. организации связывания таблиц
Пусть в отношении R1 имеется неключевой атрибут А, значения которого являются значениями ключевого атрибута В другого отношения R2. Тогда говорят, что атрибут A отношения R1 есть внешний ключ.
С помощью внешних ключей устанавливаются связи между отношениями.
Вышеупомянутые и некоторые другие математические понятия явились теоретической базой для создания реляционных СУБД, разработки соответствующих языковых средств и программных систем, обеспечивающих их высокую производительность, и создания основ теории проектирования баз данных. Однако для массового пользователя реляционных СУБД можно с успехом использовать неформальные эквиваленты этих понятий:
Отношение – Таблица (иногда Файл),
Кортеж – Строка (иногда Запись),
Атрибут – Столбец, Поле.
При этом принимается, что "запись" означает "экземпляр записи", а "поле" означает "имя и тип поля".
Остановимся теперь на некоторых важных свойствах отношений, которые следуют из приведенных ранее определений:
Отсутствие кортежей-дубликатов
То свойство, что отношения не содержат кортежей-дубликатов, следует из определения отношения как множества кортежей. В классической теории множеств по определению каждое множество состоит из различных элементов.
Из этого свойства вытекает наличие у каждого отношения так называемого первичного ключа - набора атрибутов, значения которых однозначно определяют кортеж отношения. Для каждого отношения по крайней мере полный набор его атрибутов обладает этим свойством. Однако при формальном определении первичного ключа требуется обеспечение его "минимальности", т. е. в набор атрибутов первичного ключа не должны входить такие атрибуты, которые можно отбросить без ущерба для основного свойства - однозначно определять кортеж. Понятие первичного ключа является исключительно важным в связи с понятием целостности баз данных.
Отсутствие упорядоченности кортежей
Свойство отсутствия упорядоченности кортежей отношения также является следствием определения отношения-экземпляра как множества кортежей. Отсутствие требования к поддержанию порядка на множестве кортежей отношения дает дополнительную гибкость СУБД при хранении баз данных во внешней памяти и при выполнении запросов к базе данных. Это не противоречит тому, что при формулировании запроса к БД, например, на языке SQL можно потребовать сортировки результирующей таблицы в соответствии со значениями некоторых столбцов. Такой результат, вообще говоря, не отношение, а некоторый упорядоченный список кортежей.
Отсутствие упорядоченности атрибутов
Атрибуты отношений не упорядочены, поскольку по определению схема отношения есть множество пар {имя атрибута, имя домена}. Для ссылки на значение атрибута в кортеже отношения всегда используется имя атрибута.
Атомарность значений атрибутов
Значения всех атрибутов являются атомарными. Это следует из определения домена как потенциального множества значений простого типа данных, т. е. среди значений домена не могут содержаться множества значений (отношения). Принято говорить, что в реляционных базах данных допускаются только нормализованные отношения или отношения, представленные в первой нормальной форме.
ЭТАПЫ ПРОЕКТИРОВАНИЯ БАЗ ДАННЫХ
Проектирование БД
Весь процесс проектирования БД подразделяется на три основных этапа: концептуальное, логическое и физическое проектирование.
Концептуальное проектирование БД начинается с создания концептуальной модели данных предприятия, полностью независимой от любых деталей реализации, включающей определение типов важнейших сущностей и существующих между ними связей и атрибутов.
Задачей первого этапа является разбиение проекта на группу относительно небольших (и более простых) задач исходя из представлений о предметной области приложения, свойственных каждому из типов конечных пользователей. Результатом выполнения этого этапа является создание локальных концептуальных моделей данных, представляющих собой полное и точное отражение представлений о предметной области приложения отдельных типов пользователей.
Логическое проектирование БД – конструирование информационной модели предприятия на основе существующих конкретных моделей данных, но без учета используемой СУБД и прочих физических условий реализации.
Логическое проектирование БД заключается в преобразовании концептуальной модели данных в логическую модель с учетом выбранного типа СУБД. Логическая модель является источником информации для этапа физического проектирования. Она предоставляет разработчику физической модели данных средства проведения всестороннего анализа различных аспектов работы с данными, что имеет исключительно важное значение для выбора действительно эффективного проектного решения.
На втором этапе локальные концептуальные модели данных преобразуются в локальные логические модели данных (для реляционной модели данных), состоящие из ER- диаграмм, реляционной схемы и сопроводительной документации. Затем корректность логических моделей проверяется с помощью правил нормализации.
Физическое проектирование БД – описание конкретной реализации БД, размещаемой во внешней памяти. Физический проект описывает базовые отношения, определяет организацию файлов и состав индексов, применяемых для обеспечения эффективного доступа к данным, а также регламентирует все соответствующие ограничения целостности и меры защиты.
Физическое проектирование предусматривает принятие разработчиком окончательного решения о способах реализации создаваемой базы. Поэтому физическое проектирование обязательно производится с учетом всех особенностей используемой СУБД. Между этапами физического и логического проектирования всегда имеется определенная обратная связь, поскольку решения, принятые на этапе физического проектирования с целью повышения производительности разрабатываемой системы, могут потребовать определенной корректировки логической модели данных.
ОБЩИЙ ОБЗОР ЭТАПОВ ПРОЕКТИРОВАНИЯ БД
Концептуальное проектирование БД
1. Создание локальной концептуальной модели данных исходя из представлений о предметной области каждого из типов пользователей.
2. Определение типов сущности.
3. Определение связей.
4. Определение атрибутов и связывание их с типами сущностей и связей.
5. Определение доменов и атрибутов
6. Определение атрибутов, являющихся потенциальными и первичными ключами.
7. Проверка модели на отсутствие избыточности.
8. Проверка соответствия локальной концептуальной модели конкретным пользовательским транзакциям.
9. Обсуждение локальных концептуальных моделей данных с конечным пользователем.
Логическое проектирование БД
1. Создание и проверка локальной логической модели данных на основе представления о предметной области каждого из типов пользователей.
2. Устранение особенностей локальной логической модели, несовместимых с реляционной моделью (необязательный этап).
3. Определение набора отношений исходя из структуры локальной логической модели данных.
4. Проверка отношений с помощью правил нормализации.
5. Проверка соответствия отношений требованиям пользовательских транзакций.
6. Определение требований поддержки целостности данных.
7. Обсуждение разработанных локальных логических моделей данных с конечным пользователем.
8. Создание и проверка глобальной логической модели данных.
9. Слияние локальных логических моделей данных в единую глобальную модель данных.
10. Проверка глобальной логической модели данных.
11. Проверка возможностей расширения модели в будущем.
12. Обсуждение глобальной логической модели данных с пользователями.
Физическое проектирование БД (с использованием реляционной СУБД)
1. Перенос глобальной логической модели данных в среду целевой СУБД
2. Проектирование базовых отношений в среде целевой СУБД
3. Проектирование отношений, содержащих производные данные.
4. Реализация ограничений предметной области.
5. Проектирование физического представления данных.
6. Анализ транзакций
7. Выбор файловой структуры.
8. Определение индексов.
9. Определение требований к дисковой памяти.
10. Разработка пользовательских представлений
11. Разработка механизмов защиты
12. Анализ необходимости введения контролируемой избыточности
13. Организация мониторинга и настройка функционирования операционной системы.
НОРМАЛИЗАЦИЯ ОТНОШЕНИЙ
Нормализация – это разбиение таблицы на две или более, обладающих лучшими свойствами при включении, изменении и удалении данных. Окончательная цель нормализации сводится к получению такого проекта базы данных, в котором каждый факт появляется лишь в одном месте, т. е. исключена избыточность информации. Это делается не столько с целью экономии памяти, сколько для исключения возможной противоречивости хранимых данных.
Каждая таблица в реляционной БД удовлетворяет условию, в соответствии с которым в позиции на пересечении каждой строки и столбца таблицы всегда находится единственное атомарное значение, и никогда не может быть множества таких значений. Любая таблица, удовлетворяющая этому условию, называется нормализованной. Фактически, ненормализованные таблицы, т. е. таблицы, содержащие повторяющиеся группы, даже не допускаются в реляционной БД.
Теория нормализации работает с 5 нормальными формами. Каждая следующая нормальная форма в некотором смысле лучше предыдущей. При переходе к следующей нормальной форме свойства предыдущих нормальных свойств сохраняются.
Теория нормализации основывается на наличии той или иной зависимости между полями таблицы.
Функциональная зависимость. Поле В таблицы функционально зависит от поля А той же таблицы в том и только в том случае, когда в любой заданный момент времени для каждого из различных значений поля А обязательно существует только одно из различных значений поля В. Отметим, что здесь допускается, что поля А и В могут быть составными.
Полная функциональная зависимость. Поле В находится в полной функциональной зависимости от составного поля А, если оно функционально зависит от А и не зависит функционально от любого подмножества поля А иначе поле В будет частично зависимым (зависит только от части ключа).
Многозначная зависимость. Поле А многозначно определяет поле В той же таблицы, если для каждого значения поля А существует хорошо определенное множество соответствующих значений В.
Первая нормальная форма (1НФ)
Таблица, находящаяся в первой нормальной форме тогда и только тогда, когда ни одна из ее строк не содержит в любом своем поле более одного значения (не содержит группы повторяющихся значений) и ни одно из ее ключевых полей не пусто.
Для приведения к 1НФ можно использовать следующий алгоритм:
1. Определить поле, которое можно назначить первичным ключом. Если такого поля нет, то добавить новое уникальное ключевое поле.
2. Определить группы повторяющихся полей.
3. Вынести группы повторяющихся полей в отдельные таблицы, в основной таблице остается одно поле для организации связи между таблицами.
4. Назначить первичные ключи в новых таблицах. (В качестве ключевых полей можно использовать поля таблицы или добавить новое поле. Если ключевое поле имеет большой размер, предпочтительно добавлять новое поле)
5. Определить тип отношения между таблицами.
Вторая нормальная форма (2НФ)
Таблица, находящаяся во второй нормальной форме, удовлетворяет определению 1НФ и все ее поля, не входящие в первичный ключ связаны полной функциональной зависимостью с первичным ключом (любое неключевое поле однозначно идентифицируется полным набором ключевых полей).
Для приведения ко 2НФ необходимо:
1. вынести все частично зависимые поля в отдельную таблицу;
2. определить ключевые поля;
3. установить отношения между таблицами.
Третья нормальная форма (3НФ)
Таблица, находящаяся в третьей нормальной форме, удовлетворяет определению 2НФ и не одно из ее неключевых полей не зависит функционально от любого другого неключевого поля (в таблице нет полей, не зависящих от ключа).
Для приведения к 3НФ необходимо вынести поля, зависящие от неключевого поля, в отдельную таблицу и установить отношения между таблицами.
АРХИТЕКТУРЫ РАСПРЕДЕЛЕННОЙ ОБРАБОТКИ ДАННЫХ
Почти все модели организации взаимодействия пользователя с базой данных построены на основе модели «клиент — сервер». То есть предполагается, что каждое такое приложение отличается способом распределения функций ранее приведенных групп обработки данных между, как минимум, двумя частями:
· клиентской, которая отвечает за целевую обработку данных и организацию взаимодействия с пользователем;
· серверной, которая обеспечивает хранение данных, обрабатывает запросы и посылает результаты клиенту для специальной обработки.
В общем случае предполагается, что эти части приложения функционируют на отдельных компьютерах, т. е. к серверу БД с помощью сети подключены компьютеры пользователей (клиенты).
Сервер - это программа, реализующая функции собственно СУБД: определение данных, запись — чтение данных, поддержка схем внешнего, концептуального и внутреннего уровней, диспетчеризация и оптимизация выполнения запросов, защита данных.
Клиент — это различные программы, написанные как пользователями, так и поставщиками СУБД, внешние или «встроенные» по отношению к СУБД. Программа-клиент организована в виде приложения, работающего «поверх» СУБД, и обращающегося для выполнения операций над данными к компонентам СУБД через интерфейс внешнего уровня.
Разделение процесса выполнения запроса на «клиентскую» и «серверную» компоненту позволяет:
· различным прикладным (клиентским) программам одновременно использовать общую базу данных;
· централизовать функции управления, такие, как защита информации, обеспечение целостности данных, управление совместным использованием ресурсов;
· обеспечивать параллельную обработку запроса в случае распределенных БД;
· высвобождать ресурсы рабочих станций и сети;
· повышать эффективность управления данными за счет использования ЭВМ, специально разработанных для работы СУБД (серверы баз данных и машины баз данных).
Базовые архитектуры распределенной обработки
Учитывая, что одним из основных показателей эффективности сетевой обработки данных является время обслуживания запроса, рассмотрим различные модели архитектуры распределенной обработки на примере, когда прикладная программа работы с базой данных, расположенной на сервере, загружена на рабочую станцию, и пользователю необходимо получить все записи, удовлетворяющие некоторым поисковым условиям.
В архитектуре «файл — сервер», схема которой представлена на рис. 8.1, средства организации и управления базой данных (в том числе и СУБД) целиком располагаются на машине клиента, а база данных, представляющая собой обычно набор специализированных структурированных файлов, на машине-сервере. В этом случае серверная компонента представлена даже не средствами СУБД, а сетевыми составляющими операционной системы, обеспечивающими удаленный разделяемый доступ к файлам. Таким образом, «файл-сервер» представляет собой вырожденный случай клиент-серверной архитектуры.
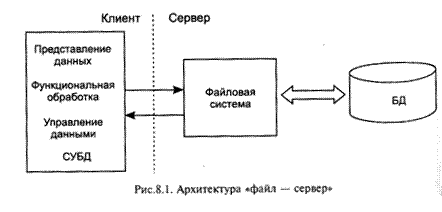

Взаимодействие между клиентом и сервером происходит на уровне команд ввода-вывода файловой системы, которая возвращает запись или блок данных. Запрос к базе, сформулированный на языке манипулирования данными, преобразуется самой СУБД в последовательность команд ввода-вывода, которые обрабатываются операционной системой машины-сервера.
Достоинство — возможность обслуживания запросов нескольких клиентов.
Недостатки:
· высокая загрузка сети и машин-клиентов, так как обмен идет на уровне единиц информации файловой системы — физических записей, блоков или даже файлов, из которых на машине клиента будут выбраны и представлены необходимые для приложения элементы данных;
· низкий уровень защиты данных, так как доступ к файлам БД управляется общими средствами ОС-сервера;
· низкий уровень управления целостностью и непротиворечивостью информации, так как бизнес-правила функциональной обработки, сосредоточенные на клиентской части, могут быть противоречивыми и несинхронизированными.
· В среде файлового сервера программа управления данными, которая выполняется на машине-клиенте, должна осуществить запрос каждой записи базы, после чего она может определить, удовлетворяет ли запись поисковым условиям, лишь после этого передать запись для функциональной обработки. Очевидно, что для этой схемы характерно наибольшее суммарное время обработки информации.
Архитектура «выделенный сервер базы данных»
В архитектуре сервера базы данных, схема которой представлена на рис. 8.2, средства управления базой данных и база данных размещены на машине-сервере.
Взаимодействие между клиентом и сервером происходит на Уровне команд языка манипулирования данными СУБД (обычно SQL), которые обрабатываются СУБД на машине-сервере. Сервер базы данных осуществляет поиск записей и анализирует их. Записи, Удовлетворяющие условиям, могут накапливаться на сервере и после того, как запрос будет целиком обработан, пользователю на клиентскую машину передаются все логические записи (запрашиваемые элементы данных), удовлетворяющие поисковым условиям.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
