

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лабораторная работа № 3
Снижение размерности пространства признаков
методом факторного анализа
1. Сущность проблемы снижения размерности
В исследовательской и практической работе, связанной с анализом данных, приходится встречаться с ситуациями, когда общее число признаков ![]() ,
, ![]() ,…,
,…,![]() , регистрируемых на каждом из множества обследуемых объектов (стран, городов, предприятий, семей, пациентов, технических или экологических систем) очень велико – порядка ста или более. Имеющиеся многомерные наблюдения
, регистрируемых на каждом из множества обследуемых объектов (стран, городов, предприятий, семей, пациентов, технических или экологических систем) очень велико – порядка ста или более. Имеющиеся многомерные наблюдения
![]() =
= 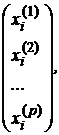 i = 1, 2, …, n. (1)
i = 1, 2, …, n. (1)
следует подвергнуть статистической обработке, интерпретировать, ввести в базу данных, чтобы иметь возможность использовать их в нужный момент.
Поэтому возникает необходимость представить каждое из наблюдений (1) в виде вектора некоторых вспомогательных переменных (показателей) с существенно меньшим, чем р числом компонент ![]() = m. Новые признаки могут выбираться из числа исходных или определяться по какому–либо правилу по совокупности исходных признаков, например, как их линейная комбинация. Новые признаки должны удовлетворять ряду требований:
= m. Новые признаки могут выбираться из числа исходных или определяться по какому–либо правилу по совокупности исходных признаков, например, как их линейная комбинация. Новые признаки должны удовлетворять ряду требований:
1) наибольшая информативность,
2) взаимная некоррелированность,
3) наименьшее искажение геометрической структуры множества исходных данных.
2. Модель факторного анализа
Модель факторного анализа (ФА) объясняет структуру связей между исходными показателями ![]() ,
, ![]() ,…,
,…,![]() тем, что поведение каждого из них статистически зависит от одного и того же набора так называемых общих факторов
тем, что поведение каждого из них статистически зависит от одного и того же набора так называемых общих факторов ![]() ,
, ![]() ,…,
,…, ![]() и одного характерного (специфического) фактора, т. е.
и одного характерного (специфического) фактора, т. е.
![]() =
= ![]() +
+ 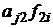 +…+
+…+ 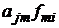 +
+![]() ,
,
j = 1, …, p, r = 1,…, m, i = 1, …, n, (2)
где ![]() –значение j–го показателя у i–го объекта,
–значение j–го показателя у i–го объекта,
![]() – r –й общий фактор;
– r –й общий фактор;
![]() – j –й характерный (специфический) фактор, присущий только данной
– j –й характерный (специфический) фактор, присущий только данной
j –й переменной;
![]() – значение r –го общего фактора на i –м объекте исследования;
– значение r –го общего фактора на i –м объекте исследования;
![]() – значение j –й характерного фактора на i –м объекте исследования;
– значение j –й характерного фактора на i –м объекте исследования;
![]() – весовой коэффициент j –й переменной на r –м общем факторе или нагрузка j –й переменной на r –м общем факторе;
– весовой коэффициент j –й переменной на r –м общем факторе или нагрузка j –й переменной на r –м общем факторе;
![]() – нагрузка или весовой коэффициент j –й переменной на j – м характерном факторе.
– нагрузка или весовой коэффициент j –й переменной на j – м характерном факторе.
Обычно предполагают, что характерные факторы некоррелированы между собой и с общими факторами. Факторы, связанные значимыми весовыми коэффициентами более чем с одной переменной, называются общими.
Стандартизованная форма факторной модели. В выражении (2) ![]() имеют свою размерность. Для того, чтобы перейти к безразмерным переменным, удобно провести нормирование исходных показателей.
имеют свою размерность. Для того, чтобы перейти к безразмерным переменным, удобно провести нормирование исходных показателей.
Выполним центрирование
![]() =
= ![]() –
– ![]() , (3)
, (3)
где ![]() – среднее значение j –й переменной.
– среднее значение j –й переменной.
Проведем стандартизацию признаков ![]() = (
= (![]() –
– ![]() ) /
) / ![]() , (4)
, (4)
где ![]() – нормированное значение j – й переменной на i –м объекте,
– нормированное значение j – й переменной на i –м объекте,
![]() – среднее квадратическое отклонение j – го признака.
– среднее квадратическое отклонение j – го признака.
После этих преобразований получим
![]() =
= ![]() + +…+
+ +…+ ![]() +
+ ![]() ,
,
(j = 1, …, p, r = 1,…, m, i = 1, …, n). (5)
Средние значения переменных Y равны нулю, а дисперсии ![]() = 1.
= 1.
Матричная форма факторной модели. Перейдем к матричной форме представления нагрузок и модели (5). Матрица нагрузок общих факторов имеет вид:
А = 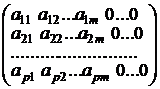 . (6)
. (6)
Матрица А не содержит весовых коэффициентов характерных факторов, поэтому ее р последних столбцов имеют нулевые значения.
Матрица Ψ нагрузок характерных факторов характеризует только индивидуальные факторы, каждый из которых связан только с одним признаком. Эта матрица является диагональной и не содержит коэффициентов при общих факторах. Ее первые т столбцов имеют нулевые значения (13):
Ψ = 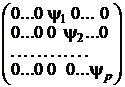 (7)
(7)
Обобщенная модель факторного анализа имеет вид
Y = AF + U, (8)
где А – (р![]() т)–матрица (неслучайных) нагрузок общих факторов F (т
т)–матрица (неслучайных) нагрузок общих факторов F (т![]() 1) и U – (р
1) и U – (р![]() 1)–матрица (случайных) характерных факторов. Обычно предполагают, что характерные факторы некоррелированы между собой и с общими факторами. Все предположения модели можно записать следующим образом:
1)–матрица (случайных) характерных факторов. Обычно предполагают, что характерные факторы некоррелированы между собой и с общими факторами. Все предположения модели можно записать следующим образом:
ЕF = 0 (математические ожидания общих факторов равны нулю);
Var (F) = Im (матрица ковариаций общих факторов единичная);
Е U = 0 (математические ожидания характерных факторов равны нулю):
Cov (Ui, Uj) = 0 (характерные факторы некоррелированы между собой);
Cov (F, U) = 0 (общие и характерные факторы некоррелированы между собой).
Определим матрицу дисперсий характерных факторов как
Var (U) = Ψ = diag (ψ11,…, ψрр).
Это приводят к следующей структуре матрицы ковариаций исходных признаков:
Σ = AAТ + Ψ. (9)
Обобщенная модель (8) совместно с указанными ограничениями составляют ортогональную модель факторного анализа.
Идея сжатия данных методом факторного анализа заключается в переходе от (р ![]() n) – матрицы Y к (m
n) – матрицы Y к (m ![]() n) матрице F.
n) матрице F.
Из трех матриц выражения (8) не известны две – А и F, не известно также число общих факторов т.
Неединственность факторных нагрузок. Представление (8), если оно существует, не единственно. Это можно показать следующим образом. Перейдем от F с помощью ортогонального преобразования С к новым переменным Т = СF. Тогда вместо (8) будем иметь соотношение
Y = (AС)(СТF) + U.
Это означает, что если представление Х с помощью m факторов F и нагрузок A верно, то m – факторная модель с факторами СТF и нагрузками AС также верна. При применении факторного анализа эта неединственность дает преимущество. Умножение слева вектора F на ортогональную матрицу соответствует повороту координатных осей, причем направление первой новой оси задается первой строкой этой ортогональной матрицы. Далее будет показано, что выбор соответствующего метода вращения дает в результате матрицу нагрузок AС, которую будет легче интерпретировать.
Число степеней свободы в модели факторного анализа с т общими факторами равно
d = (½ р(р +1) – (рт + р –½ т(т –1)) = ½(р – т)2– ½(р+т).
Если d < 0, то модель не определена: она имеет бесконечное число решений относительно (9). Это означает, что число параметров факторной модели больше, чем число параметров исходной модели (т значительно больше, чем р). Если d = 0, это единственное решение задачи, исключая вращение. На практике мы обычно имеем d > 0: уравнений больше, чем параметров, поэтому точного решения не существует. В этом случае используется приближенное решение.
3. Компоненты дисперсии в ФА
Структура матрицы ковариаций исходных признаков определяется следующим выражением:
Σ = AAТ + Ψ. (10)
Отсюда дисперсия признака равна
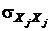 = Var (
= Var (![]() ) =
) = 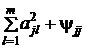 .
.
Величина ![]() называется общностью, а
называется общностью, а ![]() – специфичной дисперсией.
– специфичной дисперсией.
В практике анализа данных, поскольку мы располагаем только результатами наблюдений Х, требуется оценить компоненты (10), получив ![]() – оценку матрицы нагрузок и
– оценку матрицы нагрузок и ![]() – оценку матрицы специфичной дисперсии. Тогда по аналогии с (10) можно будет записать выражение для вычисления выборочной матрицы ковариации S:
– оценку матрицы специфичной дисперсии. Тогда по аналогии с (10) можно будет записать выражение для вычисления выборочной матрицы ковариации S:
S = ![]()
![]() +
+ ![]() .
.
При заданной оценке ![]() можно найти диагональные элементы матрицы
можно найти диагональные элементы матрицы ![]() :
:
![]() = –
= – ![]() .
.
Оценками общностей будут ![]() =
= ![]() .
.
Если число степеней свободы d = 0, мы имеем точное решение. Обычно же d больше нуля, поэтому мы находим ![]() и
и ![]() из условия, что S аппроксимируется выражением
из условия, что S аппроксимируется выражением ![]()
![]() +
+ ![]() .
.
Поскольку в реальных статистических задачах мы располагаем лишь оценками ![]() и
и ![]() соответственно матриц нагрузок общих A и характерного Ψ факторов, то в дальнейшем под A понимается
соответственно матриц нагрузок общих A и характерного Ψ факторов, то в дальнейшем под A понимается ![]() , а под Ψ –матрица
, а под Ψ –матрица ![]() . Кроме того, мы будем рассматривать стандартные признаки.
. Кроме того, мы будем рассматривать стандартные признаки.
Дисперсия ![]() стандартного признака
стандартного признака ![]() равна
равна ![]() = 1. С другой стороны, дисперсия
= 1. С другой стороны, дисперсия ![]() признака
признака ![]() равна сумме относительных вкладов в дисперсию этого признака каждого из m общих факторов и одного характерного фактора:
равна сумме относительных вкладов в дисперсию этого признака каждого из m общих факторов и одного характерного фактора:
![]() =
= 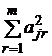 +
+![]() . (11)
. (11)
Выражение
= ![]() (12)
(12)
называется общностью признака ![]() , т. е. суммой относительных вкладов всех m общих факторов в дисперсию признаков. Вклад в дисперсию
, т. е. суммой относительных вкладов всех m общих факторов в дисперсию признаков. Вклад в дисперсию ![]() характерного фактора
характерного фактора ![]() , или специфичность (характерность), представляет компонента
, или специфичность (характерность), представляет компонента![]() . Специфичность характеризует остаточную дисперсию, не объяснимую m общими факторами.
. Специфичность характеризует остаточную дисперсию, не объяснимую m общими факторами.
Вклад фактора ![]() в суммарную дисперсию всех признаков находится как
в суммарную дисперсию всех признаков находится как
![]() =
= 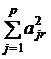 =
= ![]() (13)
(13)
Вклад всех общих факторов в суммарную дисперсию всех признаков рассчитывается следующим образом:
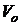 =
= 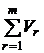 =
= 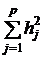 . (14)
. (14)
Пример 1. Определение вкладов факторов и переменных на основании представления дисперсии в ФА |
4. Матрица коэффициентов парной корреляции и ее преобразование
Матрица R коэффициентов парной корреляции (корреляционная матрица), воспроизводящая все связи между исходными переменными Y, может быть получена следующим образом:
R = (А + Ψ) (А + Ψ)T = (А + Ψ)(АТ + ΨТ) = ААТ + А ΨТ + ΨAТ + Ψ ΨТ.
Из матриц (6) и (7) следует, что
А ΨТ = ΨAТ = 0.
Следовательно,
R = ААТ + Ψ ΨТ,
ААТ = ![]() , (15)
, (15)
а ΨΨТ= Ψ2, так как Ψ – диагональная матрица. Возведение ее в квадрат приводит к диагональной матрице, у которой на главной диагонали стоят элементы матрицы Ψ в квадрате.
Таким образом, матрица коэффициентов парной корреляции исходных признаков, имеет представление:
R = ![]() + Ψ2 или R = ААТ + Ψ2 .
+ Ψ2 или R = ААТ + Ψ2 .
Матрица R – это матрица с единицами на главной диагонали, а матрица ![]() – это корреляционная матрица с общностями на главной диагонали (редуцированная матрица). Матрица R является симметричной, элементы ее главной диагонали являются дисперсиями соответствующих случайных величин. Так
– это корреляционная матрица с общностями на главной диагонали (редуцированная матрица). Матрица R является симметричной, элементы ее главной диагонали являются дисперсиями соответствующих случайных величин. Так ![]() – дисперсия случайной величины – признака
– дисперсия случайной величины – признака ![]() , а
, а ![]() – дисперсия k-го признака
– дисперсия k-го признака ![]() . Все дисперсии, стоящие на главной диагонали равны единицам, так как у – стандартизованные величины. Следовательно, суммарная дисперсия всех изучаемых признаков будет равна следу матрицы R (сумме ее диагональных элементов), т. е. сумме дисперсий признаков. В рассматриваемом случае суммарная дисперсия равна размерности р вектора наблюдения Y.
. Все дисперсии, стоящие на главной диагонали равны единицам, так как у – стандартизованные величины. Следовательно, суммарная дисперсия всех изучаемых признаков будет равна следу матрицы R (сумме ее диагональных элементов), т. е. сумме дисперсий признаков. В рассматриваемом случае суммарная дисперсия равна размерности р вектора наблюдения Y.
Корреляционная матрица R может быть представлена как произведение векторов Y:
R = ![]() Y Y Т, (16)
Y Y Т, (16)
где п – объем выборки.
Воспользуемся формулой (9) и преобразуем матрицу R в редуцированную матрицу
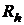 =
= 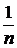 AF(AF)T = AFFT AT = AFFT AT.
AF(AF)T = AFFT AT = AFFT AT.
Выражение, стоящее между А и AT, по аналогии с (16) является корреляционной матрицей связей общих факторов. Обозначим ее
FFT = С,
тогда
![]() = A
= A![]() С AT. (17)
С AT. (17)
Если общие факторы не коррелированны между собой, то С будет единичной матрицей ![]() , тогда
, тогда
![]() = A AT. (18)
= A AT. (18)
Выражения (17) и (18) называются фундаментальной теоремой факторного анализа.
Каждый элемент 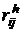 редуцированной матрицы вычисляется по формуле
редуцированной матрицы вычисляется по формуле
= 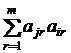 ,
,
что соответствует скалярному произведению векторов нагрузок 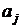 и
и 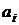 .
.
Пример 2. Воспроизведение матрицы корреляций с помощью нагрузок |
5. Задачи факторного анализа
Основными задачами факторного анализа являются:
1) определение числа т общих факторов,
2) определение нагрузок и общностей,
3) вращение факторов с целью нахождения простой структуры и содержательной интерпретации найденных факторов,
4) вычисление значений факторов.
В распоряжении исследователя имеется последовательность многомерных наблюдений ![]() ,
, ![]() , …,
, …,![]() и с помощью модели (2) нужно перейти от исходных коррелированных признаков
и с помощью модели (2) нужно перейти от исходных коррелированных признаков ![]() ,
, ![]() , …,
, …, ![]() , являющихся компонентами каждого из наблюдений, к меньшему числу коррелированных вспомогательных признаков, или общих факторов
, являющихся компонентами каждого из наблюдений, к меньшему числу коррелированных вспомогательных признаков, или общих факторов ![]() ,
, ![]() , …,
, …, ![]() . Для этого необходимо определить оценки неизвестных нагрузок
. Для этого необходимо определить оценки неизвестных нагрузок ![]() , общностей
, общностей ![]() , остаточной дисперсии
, остаточной дисперсии ![]() и самих факторов
и самих факторов ![]() .
.
Существуют два подхода к установлению числа т общих факторов.
В первом подходе предварительно устанавливается количество общих факторов т, которое должно быть выделено, а затем подбирают число общих факторов и значения общностей так, чтобы максимизировать долю общей дисперсии, объясняемой выбранными факторами.
Во втором подходе сначала определяют общности, а затем число факторов, стремясь при этом, чтобы редуцированная матрица ![]() как можно меньше отличалась от матрицы R.
как можно меньше отличалась от матрицы R.
Для определения нагрузок и общностей также используются два подхода.
1-й подход использует метод главных компонент. Определение элементов матрицы нагрузок А производится, исходя из условия минимизации отличия ковариационной матрицы Σ исследуемого вектора Х от ковариационной матрицы ΣХ = А·АТ аппроксимирующего вектора Х(т). Выборочная ковариационная матрица приводится к диагональному виду S = LΛLT (L – матрица собственных векторов, Λ – диагональная матрицы собственных значений матрицы S ). Тогда матрицу нагрузк ![]() можно представить с помощью первых т собственных векторов как
можно представить с помощью первых т собственных векторов как
![]() = (
= (![]() l1,…,
l1,…, ![]() lm).
lm).
Оценку дисперсий специфических факторов дадут диагональные элементы матрицы S – ![]()
![]() :
:
![]() =
= 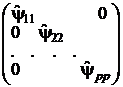 ,
, ![]() = –
= –![]() .
.
По определению диагональные элементы S равны диагональным элементам ![]()
![]() +
+ ![]() . Для того, чтобы установить, насколько удачна эта аппроксимация, рассмотрим остаточную матрицу S – (
. Для того, чтобы установить, насколько удачна эта аппроксимация, рассмотрим остаточную матрицу S – (![]()
![]() +
+![]() ). Аналитически в методе главных компонент показано, что
). Аналитически в методе главных компонент показано, что
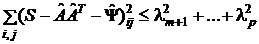 .
.
Это означает, что небольшая величина отбрасываемых собственных значений приводит к незначительной ошибке аппроксимации. Установление числа общих факторов производится на основе критерия информативности (выражение (8) в лекц. 18). Величина этого критерия показывает, какая доля суммарной дисперсии исходных признаков может быть объяснена первыми т общими факторами. Доля дисперсии, вносимая в суммарную выборочную дисперсию j-м фактором, равна
λj /![]() (факторный анализ проводится на основе матрицы ковариаций S),
(факторный анализ проводится на основе матрицы ковариаций S),
λj /р (факторный анализ проводится на основе матрицы корреляций R).
Процесс выделения факторов можно проиллюстрировать таким же графиком «каменистой осыпи», как и в методе главных компонент (лекц. 18).
На рис.1 показаны величины собственных значений корреляционной матрицы R для р = 7 признаков – компонент вектора наблюдений Х .
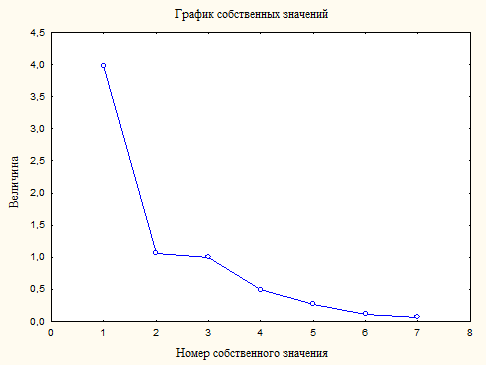
Рис.1. Собственные значения корреляционной матрицы R для р=7 признаков
2-й подход называется методом главных факторов (или главных факторных осей). При его использовании корреляционная матрица R подвергается декомпозиции. Пусть нам точно известна матрица характерных нагрузок Ψ, тогда ограничение, устанавливающее диагональность матрицы AТ Ψ -1A, означает, что столбцы A ортогональны (так как матрица Ψ единична) и они являются собственными векторами AТA = R – Ψ. Так как т первых собственных значений положительны, то A можно вычислить путем спектральной декомпозиции AТA и т будет числом извлекаемых факторов.
Метод главных факторов основан на предварительном оценивании общностей ![]() , j = 1,…, p.
, j = 1,…, p.
Рассмотрим четыре метода определения общности ![]() , используемые в рамках 2-го подхода.
, используемые в рамках 2-го подхода.
1) Определение общности ![]() при помощи квадрата коэффициента множественной корреляции
при помощи квадрата коэффициента множественной корреляции 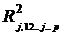 :
:
![]() =
= 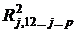 .
.
Квадрат коэффициента множественной корреляции ![]() вычисляется при помощи обратной корреляционной матрицы R-1.
вычисляется при помощи обратной корреляционной матрицы R-1.
= 1 – ![]() ,
,
где ![]() – диагональный элемент обратной матрицы R-1.
– диагональный элемент обратной матрицы R-1.
2) Определение ![]() при помощи наибольшего коэффициента корреляции по строке (столбцу).
при помощи наибольшего коэффициента корреляции по строке (столбцу).
В строке матрицы R, соответствующей данному признаку, выбирается элемент с наибольшим абсолютным значением. Это наибольшее значение коэффициента корреляции записывается на главной диагонали со знаком плюс +.
3) Оценка ![]() при помощи среднего коэффициента корреляции по строке (столбцу):
при помощи среднего коэффициента корреляции по строке (столбцу):
![]() =
= 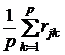 ,
,
где j ≠ k.
4) Метод триад для оценки ![]() .
.
В j - й строке (столбце) матрицы R отыскиваются два наибольших значения коэффициентов корреляции ![]() и
и ![]() и составляется триада
и составляется триада
![]() =
= ![]() ,
,
где ![]() – коэффициент корреляции в строке j, имеющий наибольшее значение как показатель стохастической связи между признаками
– коэффициент корреляции в строке j, имеющий наибольшее значение как показатель стохастической связи между признаками ![]() и
и ![]() ;
;
![]() – коэффициент корреляции, имеющий наибольшее значение, которое не превосходит
– коэффициент корреляции, имеющий наибольшее значение, которое не превосходит ![]() , и характеризующий связь признака
, и характеризующий связь признака![]() с
с ![]() .
.
Определив ![]() = 1 –
= 1 – ![]() , мы можем построить редуцированную корреляционную матрицу R –
, мы можем построить редуцированную корреляционную матрицу R – ![]() =
= 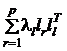 , имеющую собственные значения λ1≥ λ1≥… ≥ λр. Пусть первые т собственных значения λ1,…, λт положительны. Тогда можно записать, что
, имеющую собственные значения λ1≥ λ1≥… ≥ λр. Пусть первые т собственных значения λ1,…, λт положительны. Тогда можно записать, что
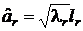 , r = 1,…, m,
, r = 1,…, m,
или
![]() = L1
= L1![]() , где L1= (l1,..., lm) и Λ1= diag(λ1,…, λт).
, где L1= (l1,..., lm) и Λ1= diag(λ1,…, λт).
На следующем шаге определяем ![]() = 1 –
= 1 – ![]() , j = 1,…, p.
, j = 1,…, p.
Эта процедура итерационная: из ![]() мы можем вычислить новую редуцированную корреляционную матрицу R –
мы можем вычислить новую редуцированную корреляционную матрицу R – ![]() , повторив описанные шаги. Вычисления завершаются, когда
, повторив описанные шаги. Вычисления завершаются, когда ![]() будет сходиться к устойчивой величине.
будет сходиться к устойчивой величине.
Когда факторные нагрузки вычислены, можно построить график, показывающий положение каждой переменной в пространстве двух (рис.2) или трех факторов. На этом графике координатами являются значения соответствующих нагрузок.
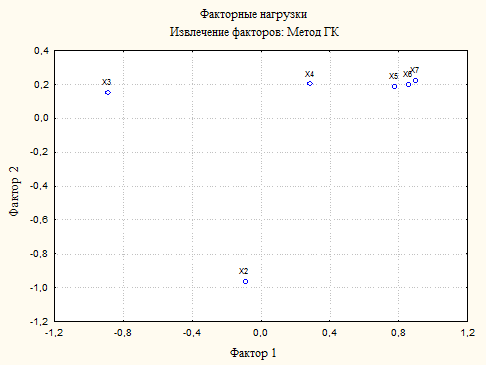
Рис. 2. Факторные нагрузки в пространстве двух общих факторов
Пример 3. Определение числа общих факторов, нагрузок, общностей, редуцированной матрицы корреляций |
Следующим этапом после оценки факторных нагрузок является так называемый этап вращения факторов. Суть его состоит в следующем. Как указывалось выше, представление в виде модели (2) или (9), если оно существует, не единственно. Из модели (2) видно, что при ортогональном преобразовании (ортогональном вращении факторов) ![]() , r = 1,…, m:
, r = 1,…, m:
![]() =
= 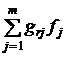 , r = 1,…, m; G = (
, r = 1,…, m; G = (![]() ); GGT = Ir,
); GGT = Ir,
получаем величины ![]() , r = 1,…, m, которые могут быть приняты за новые факторы. При этом новые факторные нагрузки являются линейными комбинациями старых нагрузок, а общности
, r = 1,…, m, которые могут быть приняты за новые факторы. При этом новые факторные нагрузки являются линейными комбинациями старых нагрузок, а общности ![]() остаются неизменными.
остаются неизменными.
Матрицу вращения G выбираем таким образом, чтобы после вращения новая матрица нагрузок ![]() = (
= (![]() ) имела бы простую структуру [1]: большинство элементов
) имела бы простую структуру [1]: большинство элементов ![]() не слишком сильно отличаются от нуля и лишь некоторые из них имеют относительно большие значения; каждая из р исходных компонент вектора наблюдений представляется минимальным числом общих факторов.
не слишком сильно отличаются от нуля и лишь некоторые из них имеют относительно большие значения; каждая из р исходных компонент вектора наблюдений представляется минимальным числом общих факторов.
Аналитический подход. Начнем с ортогональных методов вращения. Наиболее часто используется метод вращения варимакс, предложенный Кайзером (1985). В основе критерия лежит принцип самого экономного описания точки в двумерной системе координат при прохождении через нее одной из осей координат. Критерий должен принимать минимальное значение, когда наибольшее число точек лежит вблизи осей координат, т. е.
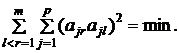
Суть метода варимакс состоит в нахождении значения угла θ, которое максимизирует сумму дисперсий квадратов нагрузок ![]() в каждом столбце матрицы
в каждом столбце матрицы ![]() . Обычно применяют нормированные факторные нагрузки, чтобы
. Обычно применяют нормированные факторные нагрузки, чтобы
избавиться от нежелательного влияния на результат вращения переменных с большой общностью, т. е. нагрузки ![]() заменяются на
заменяются на ![]() =
=![]() . Тогда варимакс–критерий определяет θ так, чтобы максимизировать
. Тогда варимакс–критерий определяет θ так, чтобы максимизировать
ν =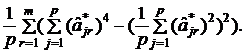
Таким образом, метод варимакс максимизирует разброс квадратов нагрузок для каждого фактора, что приводит к увеличению больших и уменьшению малых факторных нагрузок.
Прямоугольные (ортогональные) и косоугольные (не ортогональные) типы вращения подробно описаны в литературе [2, 3].
Пример 4. Нахождение простой факторной структуры с помощью вращения факторов |
Рассмотрим задачу получения значений факторов для каждого индивидуального объекта исследования. На основе исходных данных в виде матрицы значений Y и матрицы А возможно получить оценки элементов матрицы F = (![]() ) факторных значений. Будем строить линейную оценку для
) факторных значений. Будем строить линейную оценку для ![]() . Обратимся к методу регрессионного анализа, выбрав в качестве зависимой переменной значение фактора
. Обратимся к методу регрессионного анализа, выбрав в качестве зависимой переменной значение фактора ![]() , а в качестве р независимых переменных – исходные признаки
, а в качестве р независимых переменных – исходные признаки ![]() :
:
![]() =
=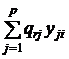 , r = 1, …, m, i = 1, …, n. (19)
, r = 1, …, m, i = 1, …, n. (19)
Теперь задача нахождения оценок факторов сводится к нахождению оценок коэффициентов Q = (![]() ).
).
Рассмотрим совместное распределение (Х – μ) и F для того, чтобы воспользоваться регрессионным анализом. Для факторной модели (8) ковариационная матрица (Х – μ) и F равна
Var![]() =
= 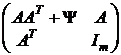 .
.
Верхний левый элемент этой матрицы равен ковариационной матрице Σ исходных признаков Х, размер матрицы (р + т)![]() (р + т).
(р + т).
При предположении совместной нормальности (Х – μ) и F условное распределение F|Х будет многомерным нормальным с условным математи-ческим ожиданием
Е(F|Х = х) = AТ Σ-1 (Х – μ)
и ковариационной матрицей
Var (F|Х = х) = ![]() – AТ Σ-1A.
– AТ Σ-1A.
Так как истинные значения A, Σ, μ неизвестны, мы заменяем их соответствующими выборочными оценками и вычисляем значения факторов для каждого объекта:
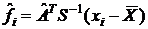 . (20)
. (20)
Если мы используем стандартизованные признаки ![]() , то вместо (20) значения факторов будут определяться как
, то вместо (20) значения факторов будут определяться как
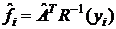 ,
,
при этом нагрузки ![]() вычисляются на основе корреляционной матрицы R.
вычисляются на основе корреляционной матрицы R.
Если производилось вращение факторов с помощью ортогональной матрицы G, значения факторов должны быть тоже повернуты, т. е.
![]() = GТ
= GТ![]() .
.
Пример 5. Определение коэффициентов регрессии факторов по признакам и значении общих факторов |
Задание
1. Вычислить матрицу факторных нагрузок А, специфичности 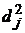 , общности
, общности 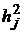 .
.
2. Оценить матрицу корреляции, редуцированную корреляционную матрицу, остаточную корреляционную матрицу.
3. Получить простую факторную структуру, выполнив варимакс-вращение, дать интерпретацию полученному факторному решению.
4. Оценить матрицу факторных значений F.
Данные
Agd1.sta – 7 переменных, 25 наблюдений; результаты измерения 25 параллелепипедов, имеющих случайную длину сторон:
Х1 – длинная ось,
Х2 – средняя ось,
Х3 – короткая ось,
Х4 – самая длинная диагональ,
Х5 – отношение (радиус наименьшей описанной сферы / радиус наибольшей вписанной сферы),
Х6 – отношение (длинная ось + средняя ось)/ короткая ось,
Х7 – отношение площадь поверхности / объем.
Agd2.sta –7 переменных, 50 наблюдений; результаты 50 гранулометрических анализов проб осадков, взятых со дна залива Баратария в западной части дельты Миссисипи. В качестве переменных рассматриваются процентные содержания фракций определенного размера в каждой пробе: Х1 – фракция 1, Х2 – фракция 2, Х3 – фракция 3, Х4 – фракция 4, Х5 – фракция 5, Х6 – фракция 6, Х7 – фракция 7.
Указание. Вычисления выполнить с помощью программного модуля Factor Analysis системы STATISTICA.
Литература
1. Статистический анализ. Подход с использованием ЭВМ. М.: Мир, 1982.
2. Факторный анализ. М.: Статистика, 1978.
3. Современный факторный анализ. М.: Статистика, 1972.
