


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Временная диаграмма работы КПДП изображена на рисунке 2.4.2.
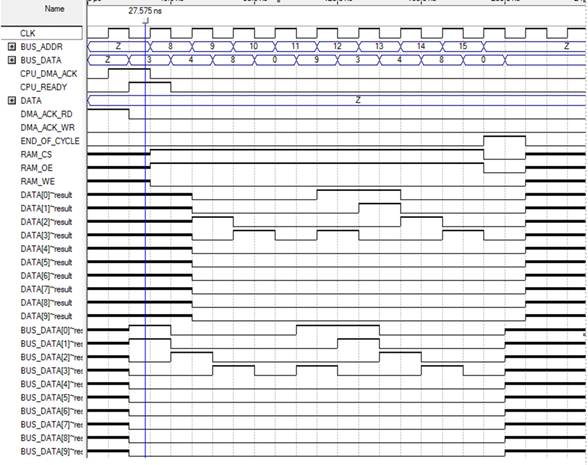
Рисунок 2.13 – Временная диаграмма работы КПДП.
Возникает запрос на чтение данных из памяти ЭВМ. Запрос сразу же передается устройству управления, после чего оно, освободив шины адреса и данных, передает сигнал на вход DMA_CPU_READY. Получив этот сигнал, КПДП начинает работу с памятью, выставив сигналы разрешения работы и чтения ОЗУ, а также начальный адрес. В результате данные с шины данных ЭВМ (BUS_DATA) транслируются на шину данных внешнего устройства (DATA). После записи 8 байт информации КПДП выставляет сигнал DMA_CYCLE_END, сигнализирующий о завершении цикла обмена с памятью. Функциональная схема контроллера прямого доступа к памяти изображена на рисунке 2.14.
Программный код реализации КПДП на языке VHDL представлен в листинге 2.5.
Листинг 2.5 Реализации КПДП:
library ieee;
use ieee. std_logic_1164.all;
use ieee. std_logic_unsigned. all;
use ieee. numeric_std. ALL;
use ieee. std_logic_arith. all;
entity dma is
generic (
ADDR_WIDTH :integer := 10;
DATA_WIDTH :integer := 8;
START_ADDR :integer := 4;
BYTE_CNT :integer := 6
);
port (
DMA_ACK_WR :in std_logic;
DMA_ACK_RD :in std_logic;
DATA :inout std_logic_vector (data_width-1 downto 0) := (others => 'Z');
CPU_READY :in std_logic;
CLK :in std_logic;
BUS_ADDR :out std_logic_vector (addr_width-1 downto 0) := (others => 'Z');
BUS_DATA :inout std_logic_vector (data_width-1 downto 0) := (others => 'Z');
RAM_CS :out std_logic := 'Z';
RAM_WE :out std_logic := 'Z';
RAM_OE :out std_logic := 'Z';
CPU_DMA_ACK :out std_logic := '0';
END_OF_CYCLE:out std_logic := '0'
);
end entity;
architecture rtl of dma is
procedure SetRam( r_cs :in std_logic;
r_we :in std_logic;
r_oe :in std_logic;
r_addr : in std_logic_vector (addr_width-1 downto 0) := (others => 'Z');
r_data : std_logic_vector (data_width-1 downto 0) := (others => 'Z')) is
begin
ram_cs <= r_cs;
ram_we <= r_we;
ram_oe <= r_oe;
bus_addr <= r_addr;
bus_data <= r_data;
end procedure;
-- Overloaded subprogram to set memory control signals --
procedure SetRam( r_cs :in std_logic;
r_we :in std_logic;
r_oe :in std_logic;
r_addr : in integer;
r_data : std_logic_vector (data_width-1 downto 0) := (others => 'Z')) is
begin
SetRam(r_cs, r_we, r_oe, std_logic_vector(to_unsigned(r_addr, ADDR_WIDTH)), r_data);
end procedure;
shared variable addrcnt :integer:=start_addr;
shared variable wordcnt :integer:=byte_cnt;
shared variable wr :boolean;
shared variable cycle :boolean:=false;
begin
process(clk)
begin
if ( rising_edge(clk)) then
if (dma_ack_wr = '1' or dma_ack_rd = '1') then
cpu_dma_ack <= '1';
if (dma_ack_wr = '1') then
wr := true;
elsif (dma_ack_rd = '1') then
wr := false;
end if;
else
cpu_dma_ack <= '0';
end if;
if (cpu_ready = '1') then
cycle := true;
addrcnt := start_addr;
wordcnt := byte_cnt;
end if;
if (cycle) then
if (wordcnt>0) then
if (wr) then
SetRam('1', '1', '0', addrcnt, data);
else
if (wordcnt/=byte_cnt) then
data <= bus_data;
end if;
SetRam('1', '0', '1', addrcnt);
end if;
addrcnt := addrcnt + 1;
wordcnt := wordcnt - 1;
else
if (not wr) then
data <= bus_data;
end if;
SetRam('0', '0', '0');
end_of_cycle <= '1';
cycle := false;
end if;
else
data <= (others => 'Z');
SetRam('Z', 'Z', 'Z');
end_of_cycle <= '0';
end if;
end if;
end process;
end rtl;
Устройство должно постоянно хранить в себе маску прерываний. Маска прерываний представляет собой 5-разрядное число, каждый разряд которого хранит информацию о текущем состоянии соответствующей линии прерывания. Если в разряде хранится логическая единица, то это означает, что данная линия прерывания работает. Также контроллер прерываний хранит в себе все начальные адреса обработчиков для каждой из линий. Эти адреса в случае возникновения прерывания передаются устройству управления.
Условное обозначение данного устройства изображено на рисунке 2.14.
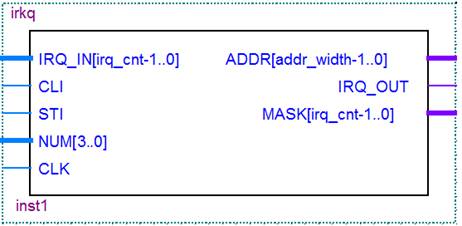
Рисунок 2.14 – Условное графическое изображение контроллера прерываний.
Временная диаграмма работы устройства изображена на рисунке 2.15.
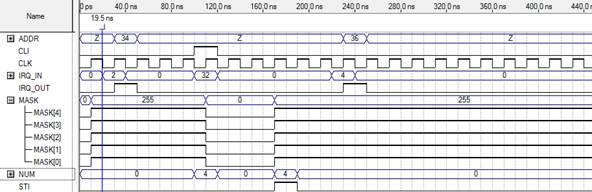
Рисунок 2.15 – Временная диаграмма работы контроллера прерываний.
При выставленном сигнале STI разрешаются все прерывания, и маска устанавливается в единицы, поступающие прерывания обрабатываются. При сигнале CLI все прерывания запрещаются маска устанавливается в ноль и прерывания не обрабатываются.
Листинг 2.6. Реализации контроллера прерываний:
library ieee;
use ieee. std_logic_1164.all;
use ieee. numeric_std. all;
entity irkq is
generic (
IRQ_CNT:integer := 5;
ADDR_WIDTH :integer := 10
);
port (
IRQ_IN : in std_logic_vector (irq_cnt-1 downto 0);
CLI : in std_logic;
STI : in std_logic;
NUM : in integer range 0 to 4;
CLK : in std_logic;
ADDR : out std_logic_vector (addr_width-1 downto 0);
IRQ_OUT : out std_logic;
MASK : out std_logic_vector (irq_cnt-1 downto 0)
);
end irkq;
architecture rtl of irkq is
shared variable int_mask : std_logic_vector (irq_cnt-1 downto 0) := (others => '1');
begin
process (clk)
variable buf : unsigned (irq_cnt-1 downto 0):= (0=>'1',others=>'0');
begin
if (rising_edge(clk)) then
if (cli = '1') then
if (num < 4) then
int_mask := int_mask and not std_logic_vector(shift_left(buf, num));
else
int_mask := (others=>'0');
end if;
end if;
if (sti = '1') then
if (num < 4) then
int_mask := int_mask or std_logic_vector(shift_left(buf, num));
else
int_mask := (others=>'1');
end if;
end if;
if (irq_in(0) = '1' and int_mask(0) = '1') then addr <= std_logic_vector(to_unsigned(32,addr'length)); irq_out <= '1';
elsif (irq_in(1) = '1' and int_mask(1) = '1') then addr <= std_logic_vector(to_unsigned(34,addr'length)); irq_out <= '1';
elsif (irq_in(2) = '1' and int_mask(2) = '1') then addr <= std_logic_vector(to_unsigned(36,addr'length)); irq_out <= '1';
elsif (irq_in(3) = '1' and int_mask(3) = '1') then addr <= std_logic_vector(to_unsigned(38,addr'length)); irq_out <= '1';
elsif (irq_in(4) = '1' and int_mask(4) = '1') then addr <= std_logic_vector(to_unsigned(42,addr'length)); irq_out <= '1';
else addr <= (others => 'Z'); irq_out <= '0';
end if;
mask <= int_mask;
end if;
end process;
end rtl;
3 РАЗРАБОТКА ПРИНЦИПИАЛЬНОЙ СХЕМЫ УСТРОЙСТВА
3.1. Описание работы устройства на вентельно-регистровом уровне
Устройство управления — узел микропроцессора, выполняющий управление прочими компонентами. В задачи устройства управления входит выборка и декодирование потока инструкций, выдача кодов функций в исполнительные устройства, принятие решений по признакам результатов вычислений, синхронизация узлов микропроцессора.
В состав устройства управления входят следующие блоки:
· Блок генерации адресов инструкций. Он содержит в себе регистр программного счётчика (program counter или instruction pointer), хранящий адрес считываемой из памяти инструкции, и модифицирующийся после выборки каждой инструкции.
· Блок выборки инструкции, обеспечивающий считывание программ из памяти через устройство ввода-вывода. Он получает на вход адрес с блока генерации адреса инструкции, передаёт его на УВВ, получает с него данные по переданному адресу, и выдаёт на блок декодирования интсрукций.
· Блок декодирования инструкций, производящий преобразование кодов инструкций в последовательность кодов функций, передаваемые на исполнительные устройства.
· Блок переходов. Получает функциональные коды переходов и ветвлений, признаки результатов операций с функциональных устройств, проверяет истинность условия перехода, и передаёт сигнал на изменение программного счётчика.
На рисунке 3. 1 приедено условно-графическое изображение блока генерации адресов инструкций.

Рисунок 3.1 – УГО блока генерациии адресов инструкций
При поступление каждого пятого такта, на блоке генерации формируется следующей команды, значение на три отличное от предыдущего, при этом при условии безусловного перехода значение адреса инструкций может задаваться принудительно при помощи входа input[9..0].

Рисунок 3.2 – УГО блока выборки инструкций
После формирования каждой из инструкция блок выборки инструкций обращается к памяти комманд и извлекает из нею текущую комману, при этом сразу после извлечения формирует специальный сигнал got_comand, который сообщает о том что текущая команда получена, что бы сохранить актуальность сигнала, сигнал автоматически сбрасывается каждые три такта.
Блок лекодирования инструкций представляет собой обынчный трехвходовы дешефратор. Так как при заданном условии курсового проекта все команды, необходимын для реализации в у стройсве управления, могут быть представлены в виде трех битов информации.
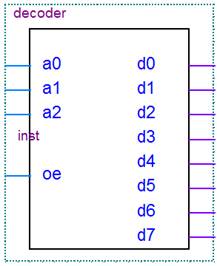
Рисунок 3.3. – УГО блока декодирвани инструкий
Принципиальная схема блока декодирования инструкий представлена ниже, на рисунке 3. 4.
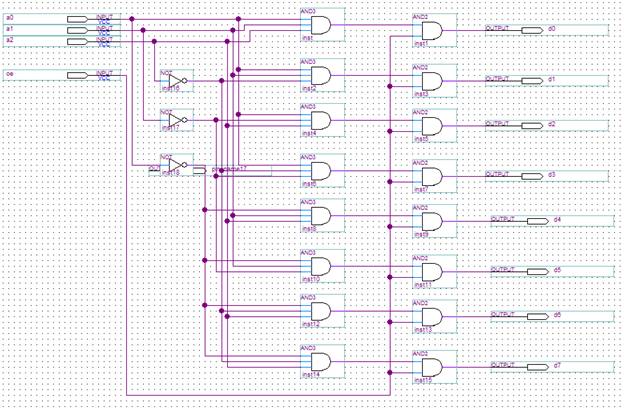
Рисунок 3.4. - Принципиальная схема блока декодирования команд
В связи с отсутсвием как таковом, влияния результатов работы функциональных устройств на текущие команды или команды необходимы исполнять далее в ходе работы микроЭВМ, в блокепереходво как таковм необхлдимость отчутсвует.
3.2 Описание времнной диаграмы устройства
Услвоно-графическое изображение устройства управления приведено на рисунку 3.5.

Рисунок 3.5. – УГО устройства управления
Векторная диаграмма устройства управления описана в приложении.
В зависимости от поступления тактового сигнала CLK, происходит изменение значения сигнала ADR[9..0], формирующего адрес выполняемой команды, затем в соответствии от результатов извлечения данной команды, запрашиваются адреса операндов и значения операндов формируются на соответствующих выходах. В случае высоко уровня сигнала на входе IRQ_IN работа устройства приостанавливается и выполняется команда лежащую по адресу, заданному на вхоже устройства IRQ_ADR[9..0]. В случае высокого уровня сигнала DMA_ACK работа устройства также приостанавливается, а на выходах устройства формируются сигналы DMA_READY, сигнализирующий о том, что память свободна и КПДП может работать и сигнал DMA_CONTROL служащий сигналом запуска КПДП. При поступлении сигнала RESET счетчик формирования адреса команды сбрасывается.
4 ОПТИМИЗАЦИЯ МИКРОЭВМ
Оптимизация микроЭВМ как правило подразумевает под собой повышение его производительности. Относительно данного курсового проекта, его производительность может быть улучшена следующими способами.
1) Повышением частоты работы основного тактового генератора
Для оптимизации работы устройства в схеме ищется цепочка, вносящая наибольшую задержку при прохождении сигнала. Частоту тактового генератора можно выбрать немного больше, чем задержка самой медленной цепочки.
2) Сокращением длительности выполнения фаз отдельных команд
Сокращение длительности выполнения отдельных фаз команд можно достичь путем увеличения частоты тактового генератора, что приведет к увеличению количества выполняемых команд в единицу времени.
3) Реализацией одновременного выполнения некоторых фаз отдельных команд
Для поддержания максимальной загрузки УУ должен использоваться параллелизм уровня команд, основанный на выявлении последовательностей несвязанных команд, которые могут выполняться в конвейере с совмещением. Чтобы избежать приостановки конвейера зависимая команда должна быть отделена от исходной команды на расстояние в тактах, равное задержке конвейера для этой исходной команды.
4) Реализацией конвейерного выполнения фаз последовательностей команд
Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями, и выделении для каждой из них отдельного блока аппаратуры. Так обработку любой машинной команды можно разделить на несколько этапов (несколько ступеней), организовав передачу данных от одного этапа к следующему. При этом конвейерную обработку можно использовать для совмещения этапов выполнения разных команд. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах.
Выполнение типичной команды можно разделить на следующие этапы:
– выборка команды (по адресу, заданному счетчиком команд, из памяти извлекается команда);
– декодирование команды / выборка операндов из регистров;
– выполнение операции / вычисление эффективного адреса памяти;
– обращение к памяти;
– запоминание результата.
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. В действительности, она даже несколько увеличивает время выполнения каждой команды из-за накладных расходов, связанных с управлением регистровыми станциями. Однако увеличение пропускной способности означает, что программа будет выполняться быстрее по сравнению с простой неконвейерной схемой.
ЗАКЛЮЧЕНИЕ
В соответствии с заданием на курсовое проектирование была реализована Гарвардская архитектура. Основное её преимущество заключается в разделении памяти команд и данных, что позволяет значительно повысить производительность системы, так как появляется возможность работ и с командами, и с данными. Благодаря этому можно рационально использовать и перераспределять ресурсы системы. Для систем с Гарвардской архитектурой легче разрабатывать программы, также устройства, построенные на данной архитектуре имеют повышенную отказоустойчивость. Несмотря на ряд ключевых преимуществ Гарвардская система, в связи со своей дороговизной, не получила широкого распространения. Однако она часто используется в системах требовательных к повышенной отказоустойчивости и производительности.
В данном курсовом микроЭВМ была реализована в среде Quartus II. МикроЭВМ устроена по принципу Гарвардской архитектуры.
Шина адреса имеет разрядность 10 бит, шина данных 8 бит. Блок РОНов содержит 12 регистров. Разработанное устройство управление выполняет следующие команды: MOV, JUMP, CMP, AND, HLT, CLI. STI. Также был разработан КПДП для прямого доступа к памяти с начальным адресом 8 бит и количеством байт для передачи 4 и система прерываний с 5 линиями прерывания.
Было разработано АЛУ, реализующее следующие операции: операцию CMP – операция сравнения двух целых положительных чисел, и операцию AND – операция логического умножения.
При проведении оптимизации микроЭВМ были рассмотрены следующие возможные варианты:
Повышение частоты работы основного тактового генератора;
Сокращение длительности выполнения фаз отдельных команд;
Реализацией одновременного выполнения некоторых фаз отдельных команд
Конвейерное выполнение фаз последовательностей команд.
В ходе выполнения курсового проекта мною были приобретены навыки построения микроЭВМ, изучены особенности Гарвардской архитектуры и языка VHDL, приобретены навыки работы в Quartus II и изучены принципы построения отдельных блоков в нём.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
1. Калинцев и функциональная организация ЭВМ. Учебно-методический комплекс. –Новополоцк.:ПГУ, 2008–284c.
2. Угрюмов схемотехника. – М.: С-Петербург, 2001 – 518с.
3. Угрюмов элементов и узлов ЭВМ. – М.: Высшая школа, 1987 – 318с.
ЭЛЕКТРОННЫЕ ИСТОЧНИКИ
Э1 http://www. – Альтера. Режим доступа: 18.09.2013, 23-59
Э2 http://www. *****/html. cgi/txt/doc/micros/arm/arh_sam7s/24.htm –Рынок микроэлектроники. Режим доступа: 11.12.2013, 14-15
ПРИЛОЖЕНИЕ А
(обязательное)
ОБЩАЯ СХЕМА МИКРО-ЭВМ
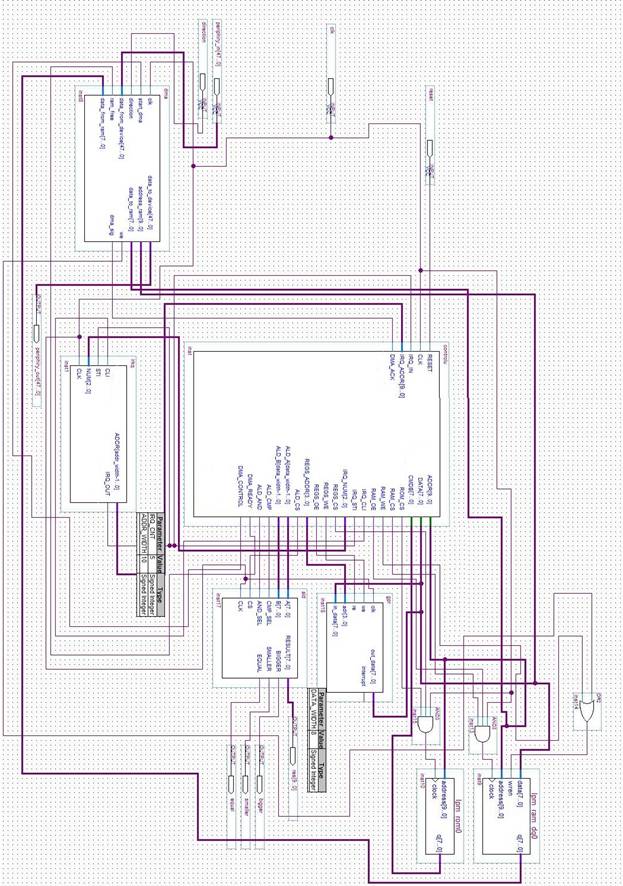
ПРИЛОЖЕНИЕ Б
(обязательное)
ПРИНЦИПИАЛЬНАЯ СХЕМА УПРАВЛЯЮЩЕГО УСТРОЙСТВА
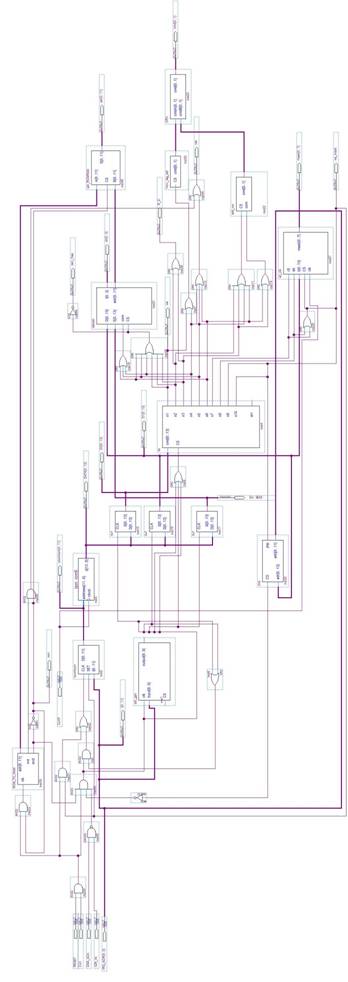
ПРИЛОЖЕНИЕ В
(обязательное)
ВРЕМЕННАЯ ДИАГРАММА РАБОТЫ УПРАВЛЯЮЩЕГО УСТРОЙСТВА
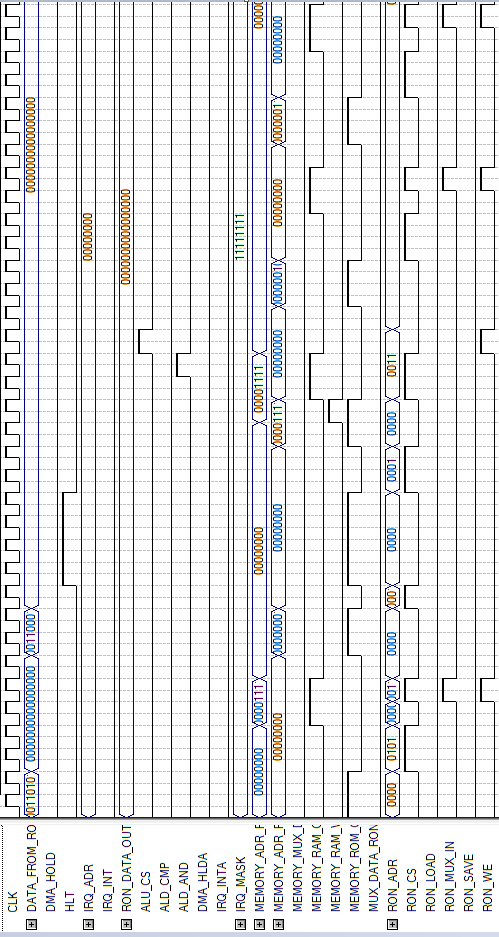

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
