

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Методы статистического анализа
Задачи статистического анализа
При экспериментальных исследованиях объектов или процессов исследователя, в конечном счёте, интересуют закономерности функционирования данного объекта, которые проявляются в зависимостях выходных величин от входных (сюда могут включаться и некоторые промежуточные величины, представляющие интерес для исследователя), влияние различных внешних условий (которые могут задаваться наличием или отсутствием каких-то влияющих факторов) и влияние объекта на внешнюю среду. При этом возможны случаи, когда все входные величины являются независимыми (т. е. могут изменяться независимо одна от другой), но могут быть и случаи, когда между их изменениями наблюдается статистическая взаимосвязь (если эта взаимосвязь является строго детерминированной, то зависимые входные величины можно просто исключить из рассмотрения, т. к. их значения полностью определяются значениями остальных входных величин). В случае же статистической взаимной зависимости исключать зависимые величины нельзя. Но это означает, что данный набор входных величин не характеризует первопричины, определяющие функционирование исследуемого объекта, а, значит, может возникать задача отыскания истинных первопричин, определяющих функционирование объекта. Формально эта задача сводится к нахождению ортогонального базиса факторного пространства, т. е. минимального набора искусственно сконструированных (математических) факторных признаков, не зависящих друг от друга и полностью определяющих функционирование данного объекта (значения его выходных величин). Конечной задачей является, как правило, построение математической модели исследуемого объекта (т. е. математической зависимости, аппроксимирующей экспериментально выявленные количественные связи между выходными и входными величинами объекта), а также доказательство адекватности данной модели.
Как следует из приведенного перечня, данные задачи во многом перекликаются с основными задачами экспериментальных исследований. Все они фактически сводятся к извлечению полезной информации (т. е. нового знания об исследуемом объекте) из полученных в результате эксперимента данных. И все они решаются с использованием различных методов статистического анализа. К основным из этих методов относятся:
- корреляционный анализ;
- регрессионный анализ;
- факторный анализ и, связанный с ним, метод главных компонент.
Дисперсионный анализ
Термин «дисперсионный анализ» впервые ввёл и определил его как отделение дисперсии, приписываемой одной группе причин, от дисперсии, приписываемой остальным причинам. Применение дисперсионного анализа предполагает нормальное распределение рассеяния выходной величины относительно значений, предсказываемых моделью данного объекта. И применяют его, преимущественно, для изучения источников этого рассеяния.
Рассмотрим математический аппарат дисперсионного анализа на примере однофакторной модели (т. е. модели, позволяющей исследовать влияние одного фактора на общее рассеяние выходной величины Y). Такая модель не лишает нас общности подхода, поскольку каждый из влияющих на выходную величину Y факторов может быть исследован с помощью такой модели поочерёдно. В общем случае этот фактор, обозначаемый как Хi может принимать k различных уровней (как количественных, так и качественных, причём в последнем случае таких уровней обычно два: 0 и 1, т. е. либо фактор отсутствует, либо присутствует, хотя, в принципе, и в этом случае возможна градация этого фактора по силе воздействия, определяемая несколькими качественными уровнями, например, «нулевое», «слабое», «умеренное», «сильное» и т. п.).
Эксперимент ставится таким образом, чтобы каждому фиксированному j-му уровню исследуемого фактора соответствовала группа nj опытов со случайными значениями всех остальных факторов. Таким образом, общее число опытов в эксперименте 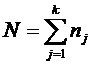 .
.
Модель дисперсионного анализа в этом случае записывается в виде
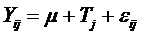 ,
,
где: i = 1, 2, …, nj – порядковые номера опытов в j-ой группе;
j = 1, 2, …, k – порядковые номера групп опытов;
m – математическое ожидание выходной величины Y;
mj – математическое ожидание Y в j-ой группе опытов;
Тj=(mj – m) – эффект влияния j-го уровня исследуемого фактора;
eij – случайная ошибка наблюдений.
Значимость влияния исследуемого фактора можно проверить, разложив общую дисперсию выходной величины на дисперсию, вызванную вариацией уровня данного фактора (дисперсию между группами) и дисперсию ошибки (дисперсию рассеяния внутри групп)
Dобщ = Dур + Dост ,
где:
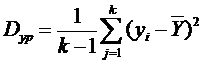
есть дисперсия между группами, а
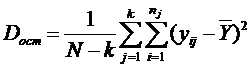
– усреднённая дисперсия рассеяния внутри групп (вызванная влияниями всех прочих факторов кроме Хj, а потому её можно считать остаточной дисперсией). (Здесь в качестве общего среднего выступает 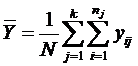 ).
).
Эта дисперсия будет иметь число степеней свободы равное N – k, т. к. k степеней свободы израсходовано на вычисление средних значений по группам:
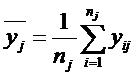 .
.
Если отношение дисперсий 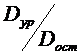 будет больше критического значения критерия Фишера F(P, k-1, N-k), найденного по таблицам F-распределения для принятого значения доверительной вероятности Р (или уровня значимости a =1– Р) и чисел степеней свободы k – 1 и N – k, то нулевая гипотеза о несущественности влияния фактора Хj отвергается, т. е. влияние этого фактора значимо:
будет больше критического значения критерия Фишера F(P, k-1, N-k), найденного по таблицам F-распределения для принятого значения доверительной вероятности Р (или уровня значимости a =1– Р) и чисел степеней свободы k – 1 и N – k, то нулевая гипотеза о несущественности влияния фактора Хj отвергается, т. е. влияние этого фактора значимо:
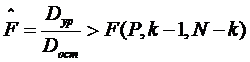 .
.
При активном эксперименте не представляет затруднений в каждой группе установить своё значение уровня Хj и поддерживать его неизменным. При пассивном же эксперименте приходится сортировать все проведенные опыты по группам таким образом, чтобы в каждой группе значение исследуемого фактора оставалось бы постоянным (конечно с какой-то погрешностью, поскольку во всех опытах этот фактор принимает случайные значения). Конечно, в этом случае и сами уровни в группах имеют случайные значения. Выделить такие группы при пассивном эксперименте удаётся далеко не всегда. В этом и состоит основное ограничение применения дисперсионного анализа в пассивном эксперименте. Если же исследуемый признак является качественным, то чаще всего эксперимент включает всего две серии опытов: в одной влияние данного фактора имеет место, в другой – исключено.
Корреляционный анализ
Корреляционный анализ, как и дисперсионный, применяется для исследования тесноты взаимосвязей между факторами. Его основным преимуществом перед дисперсионным анализом является то, что он не требует принудительного управления значениями исследуемых факторов, а поэтому может с равным успехом применяться и при активном, и при пассивном эксперименте. Более того, при пассивном эксперименте его область применения шире, чем при активном, поскольку с его помощью можно количественно оценивать тесноту взаимосвязи не только между выходными параметрами с каждым из входных, но и взаимосвязи входных параметров между собой. Правда, все исследуемые факторы должны быть количественными. Но зато корреляционный анализ позволяет получить не только утверждения о значимости или незначимости влияния того или иного фактора, но и количественно оценить тесноту взаимодействия между исследуемыми параметрами. Конечно, в какой-то мере это позволяет сделать и дисперсионный анализ: если сравнивать влияние на выходную величину нескольких факторов, то по величине превышения дисперсии рассеяния между группами Dур над дисперсией внутри групп Dост можно судить о силе влияния каждого из исследуемых факторов. Однако такие суждения являются скорее качественными, чем количественными, в то время как корреляционный анализ позволяет получать чёткие количественные оценки тесноты взаимосвязей в виде значений коэффициентов корреляций (для линеаризованных зависимостей) или корреляционных отношений (при нелинейных зависимостях). В этом состоит его второе достоинство по сравнению с дисперсионным анализом.
Рассмотрим более простой случай линейной корреляции.
Коэффициентом корреляции ρ между двумя случайными величинами Х и Y называется математическое ожидание произведения их нормированных отклонений:
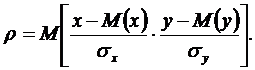 .
.
Его можно записать и в других формах:
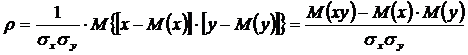 ,
,
причём величина ![]() называется корреляционным моментом.
называется корреляционным моментом.
В этих выражениях:
x и y – случайные значения величин X и Y;
M(x) и M(y) – математические ожидания этих величин;
σx и σy – их среднеквадратические отклонения;
M(xy) – математическое ожидание попарных произведений случайных значений величин X и Y.
Коэффициент корреляции характеризует меру линейной зависимости между величинами x и y. Он представляет собой безразмерную величину и по абсолютному значению не превышает единицу: 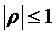 .
.
Если величины X и Y независимы, то коэффициент корреляции будет равен нулю. Однако он может оказаться равным нулю и при зависимых величинах X и Y, если эта зависимость нелинейна. Поэтому равенство нулю коэффициента корреляции позволяет утверждать лишь об отсутствии линейной зависимости между двумя исследуемыми величинами (но не исключает возможности нелинейной зависимости между ними).
Если же величины X и Y связаны линейной функциональной зависимостью, то |ρ|=1, причём, если ρ=1, то зависимость прямопропорциональная, а если ρ=–1, то зависимость обратнопропорциональная.
При переходе к выборкам и выборочным оценкам вместо формул и используется выражение
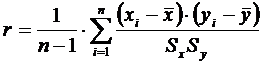 ,
,
где величина r называется эмпирическим парным коэффициентом корреляции между величинами X и Y. Эмпирический коэффициент корреляции даёт состоятельную, но смещённую оценку теоретического коэффициента корреляции ρ, причём величина смещения убывает с ростом объёма выборки N и при N >50 составляет менее 1 %. Корреляционное отношение всегда удовлетворяет неравенству
0 £ |r| £ 1,
т. е. может иметь значения от 0 (при полном отсутствии зависимости между исследуемыми случайными величинами) до 1 (при наличии функциональной зависимости между этими величинами).
Следует заметить, что эмпирический коэффициент корреляции не изменяется при изменении начала отсчёта и масштабов измерения величин X и Y. При небольших объёмах выборок значения эмпирических коэффициентов корреляции практически всегда будут отличаться от нуля, даже если соответствующие случайные величины в действительности являются независимыми. Это происходит из-за случайного разброса выборочных данных. Поэтому для установления значимости эмпирического коэффициента корреляции необходимо величину 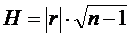 сравнить с критическим значением данного закона распределения для желаемого значения доверительной вероятности Р и объёма выборки n. Если для полученного значения r произведение
сравнить с критическим значением данного закона распределения для желаемого значения доверительной вероятности Р и объёма выборки n. Если для полученного значения r произведение ![]() окажется больше критического значения H, взятого из данной таблицы для выбранного значения доверительной вероятности Р
окажется больше критического значения H, взятого из данной таблицы для выбранного значения доверительной вероятности Р
![]()
то гипотезу о некоррелированности рассматриваемых случайных величин следует отвергнуть.
Регрессионный анализ
Регрессионный анализ является самым широко используемым методом статистического анализа. Он позволяет строить математическую модель объекта по выборочным данным, получаемым в результате активного или пассивного эксперимента. Более общим является случай пассивного эксперимента.
Пусть требуется построить математическую модель изучаемого объекта по данным, полученным в режиме его нормального функционирования в виде некоторой функции ![]() , где
, где ![]() – независимые входные переменные. Выборочные экспериментальные данные содержат n совместных наблюдений независимых переменных
– независимые входные переменные. Выборочные экспериментальные данные содержат n совместных наблюдений независимых переменных ![]() и зависимой от них переменной Y – выходной величины изучаемого объекта.
и зависимой от них переменной Y – выходной величины изучаемого объекта.
В общем случае может быть несколько выходных величин, т. е. 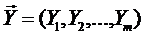 . Но в таком случае математическая модель объекта представляется совокупностью функций
. Но в таком случае математическая модель объекта представляется совокупностью функций
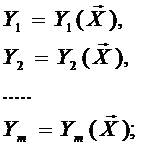
причём каждая из них находится независимо. Поэтому представление модели объекта в виде
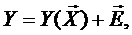
где: Y – выходная величина;
![]() – случайный вектор ошибок наблюдения,
– случайный вектор ошибок наблюдения,
не лишает её общности и для случая, когда объект характеризуется несколькими выходными величинами.
Вид функции ![]() может быть неизвестен. Однако из априорных данных должны быть известны её общие свойства. Чаще всего полагают непрерывность и гладкость этой функции. А в этом случае её можно разложить в степенной ряд Тейлора, ограничиваясь конечными отрезками этого ряда, что приводит к полиномиальным функциям того или иного порядка. В простейшем случае (при небольшом диапазоне варьирования значений входных переменных) можно ограничиться полиномом первой степени, т. е. линейным многочленом
может быть неизвестен. Однако из априорных данных должны быть известны её общие свойства. Чаще всего полагают непрерывность и гладкость этой функции. А в этом случае её можно разложить в степенной ряд Тейлора, ограничиваясь конечными отрезками этого ряда, что приводит к полиномиальным функциям того или иного порядка. В простейшем случае (при небольшом диапазоне варьирования значений входных переменных) можно ограничиться полиномом первой степени, т. е. линейным многочленом
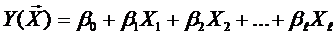 .
.
Тогда в матричном виде математическая модель объекта записывается
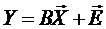 ,
,
где:
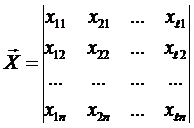 – матрица наблюдений входных переменных;
– матрица наблюдений входных переменных;
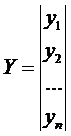 – вектор-столбец наблюдений выходной величины Y;
– вектор-столбец наблюдений выходной величины Y;
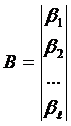 – многомерный скаляр постоянных коэффициентов;
– многомерный скаляр постоянных коэффициентов;
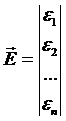 – вектор-столбец случайных ошибок наблюдений.
– вектор-столбец случайных ошибок наблюдений.
Таким образом, задача регрессионного анализа сводится к нахождению наилучших оценок постоянных коэффициентов {B}, минимизирующих вектор случайных ошибок
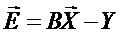 .
.
Существует несколько подходов к решению этой задачи. Однако наибольшее распространение получил метод наименьших квадратов (МНК). Метод наименьших квадратов определяет оптимальные выборочные оценки ![]() параметров модели
параметров модели ![]() , как значения, минимизирующие сумму квадратов отклонений между наблюдаемыми значениями выходной переменной {Y} и расчётными значениями этой переменной
, как значения, минимизирующие сумму квадратов отклонений между наблюдаемыми значениями выходной переменной {Y} и расчётными значениями этой переменной ![]() , полученными по регрессионной модели при тех же значениях входных переменных:
, полученными по регрессионной модели при тех же значениях входных переменных:
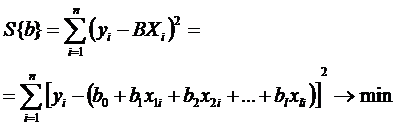 .
.
Выборочные оценки МНК параметров модели {b} можно получить, приравнивая нулю частные производные 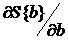 и решая полученную систему нормальных дифференциальных уравнений:
и решая полученную систему нормальных дифференциальных уравнений:
![]()
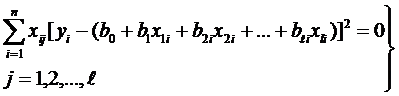 .
.
При использовании матричных обозначений минимизируемая сумма квадратов отклонений запишется в виде:
![]()
а система нормальных дифференциальных уравнений – в виде:
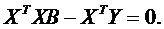
Решение этой системы уравнений получается в виде:
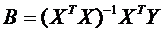 ,
,
где значок Т означает транспонированную матрицу, а обозначение
( )-1 – обратную матрицу.
Матрицы ![]() и
и 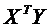 представляют собой
представляют собой
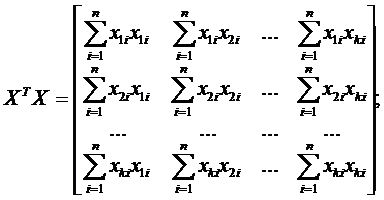
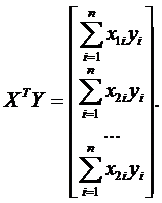
Метод наименьших квадратов даёт результаты, совпадающие с методом максимального правдоподобия в случае нормального распределения вектора наблюдений Y. При этом нормально распределённым будет и вектор ошибок ![]() . В этом случае МНК обладает следующими свойствами:
. В этом случае МНК обладает следующими свойствами:
1. Оценки МНК параметров модели ![]() являются состоятельными, несмещёнными и эффективными оценками коэффициентов модели
являются состоятельными, несмещёнными и эффективными оценками коэффициентов модели ![]() среди всех линейных моделей.
среди всех линейных моделей.
2. Несмещённой оценкой дисперсии ошибок модели является остаточная дисперсия, определяемая по формуле
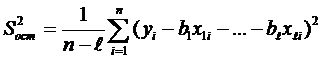 (4.145)
(4.145)
или в матричном виде
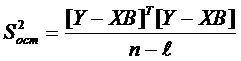 . (4.146)
. (4.146)
3. Наилучшей линейной оценкой функции отклика 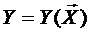 является найденная модель
является найденная модель ![]() для любой из точек факторного пространства
для любой из точек факторного пространства ![]() .
.
Но в общем случае метод наименьших квадратов не требует предположения о нормальном распределении наблюдений, сохраняя при этом оптимальные свойства полученной линейной модели. Это и позволяет использовать его не только для пассивного, но и для активного эксперимента.
Помимо нахождения модели объекта регрессионный анализ позволяет оценить дисперсии каждого из коэффициентов ![]() и, сравнивая их с остаточной дисперсией, проверить значимость этих коэффициентов.
и, сравнивая их с остаточной дисперсией, проверить значимость этих коэффициентов.
Дисперсии оценок коэффициентов ![]() могут быть найдены по формуле:
могут быть найдены по формуле:
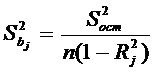 .
.
Теперь можно поочередно проверить нулевые гипотезы 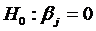 , для всех
, для всех 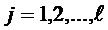 , тем самым, определив значимость каждого коэффициента
, тем самым, определив значимость каждого коэффициента ![]() , а значит, и соответствующего фактора
, а значит, и соответствующего фактора ![]() . Для этого можно воспользоваться критерием Стьюдента. Для данного случая t-статистика имеет вид:
. Для этого можно воспользоваться критерием Стьюдента. Для данного случая t-статистика имеет вид:
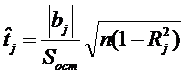 .
.
Если ![]() больше чем
больше чем  , определяемое для доверительной вероятности Р и числа степеней свободы
, определяемое для доверительной вероятности Р и числа степеней свободы ![]() , то нулевая гипотеза неверна, т. е. коэффициент
, то нулевая гипотеза неверна, т. е. коэффициент ![]() является значимым. В противном случае коэффициент (и соответствующий фактор) можно считать незначимым и отбросить его. Значение
является значимым. В противном случае коэффициент (и соответствующий фактор) можно считать незначимым и отбросить его. Значение ![]() определяется по таблицам t-распределения для
определяется по таблицам t-распределения для ![]() и выбранного значения Р.
и выбранного значения Р.
Исключив все незначимые факторы (соответственно сократив матрицу дисперсий-ковариаций), необходимо пересчитать значения всех оставшихся коэффициентов ![]() . На этом основан один из возможных путей отбора наилучшего множества факторных признаков, базирующийся на стратегии исключения.
. На этом основан один из возможных путей отбора наилучшего множества факторных признаков, базирующийся на стратегии исключения.
Общая адекватность построенной модели относительно той выборки данных, по которой эта модель была построена, может быть оценена с помощью критерия Фишера:
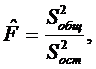
где 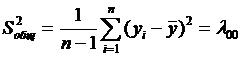 – дисперсия выходной величины Y.
– дисперсия выходной величины Y.
Если значение ![]() больше
больше ![]() , найденного из таблицы F-распределения для доверительной вероятности Р и для двух чисел степеней свободы: для числителя
, найденного из таблицы F-распределения для доверительной вероятности Р и для двух чисел степеней свободы: для числителя ![]() и для знаменателя
и для знаменателя ![]() , то построенная модель существенно снижает исходную дисперсию выходной величины, а значит, данную модель можно считать адекватной относительно той выборки данных, по которой она была построена.
, то построенная модель существенно снижает исходную дисперсию выходной величины, а значит, данную модель можно считать адекватной относительно той выборки данных, по которой она была построена.
Факторный анализ, метод главных компонент
Факторный анализ применяется в тех случаях, когда наблюдаемые в эксперименте переменные не являются истинными причинами происходящих в исследуемом объекте процессов, а лишь косвенно связаны с ними. При этом размерность пространства наблюдаемых факторов, как правило, является весьма большой, а сами эти факторы могут быть достаточно сильно коррелированны между собой. Эти обстоятельства весьма сильно затрудняют интерпретацию и осмысление результатов эксперимента или пассивного наблюдения. Задачей факторного анализа является вскрытие истинных причин, воздействующих на наблюдаемые факторы, хотя, конечно, под ними понимаются не физические причины, а такие математически построенные из наблюдаемых факторы, которые, будучи линейно независимы друг от друга, полностью определяли бы поведение выходной величины. При этом должна количественно оцениваться сила воздействия каждого из этих искусственно сконструированных факторов. Физическую же интерпретацию этих факторов факторный анализ дать не может.
Исходная информация для факторного анализа задаётся в виде матрицы наблюдений размерностью ![]() , где
, где ![]() - число наблюдаемых факторов (при этом они могут даже не разделяться на входные и выходные величины, так как причинно-следственные связи наблюдаемых факторов могут быть неизвестны).
- число наблюдаемых факторов (при этом они могут даже не разделяться на входные и выходные величины, так как причинно-следственные связи наблюдаемых факторов могут быть неизвестны).
Первый этап анализа заключается в свёртке этой информации путём построения корреляционной матрицы
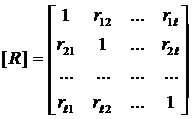 .
.
Затем, для любого ![]() из этих факторов (в первую очередь выбираются те факторы, для которых есть наибольшие априорные основания считать их следствиями воздействия изучаемых скрытых причин, другими словами, которые можно считать выходными величинами) строится модель главных компонент
из этих факторов (в первую очередь выбираются те факторы, для которых есть наибольшие априорные основания считать их следствиями воздействия изучаемых скрытых причин, другими словами, которые можно считать выходными величинами) строится модель главных компонент
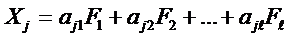 ,
,
где ![]() – новые, искусственно сконструированные переменные (факторы), которые, в отличие от наблюдаемых, не коррелированны между собой, т. е. являются линейно независимыми. Их и называют главными компонентами относительно
– новые, искусственно сконструированные переменные (факторы), которые, в отличие от наблюдаемых, не коррелированны между собой, т. е. являются линейно независимыми. Их и называют главными компонентами относительно ![]() наблюдаемой переменной.
наблюдаемой переменной.
Главные компоненты определяются таким образом, чтобы первая из них давала максимально возможный вклад в суммарную дисперсию всех переменных, вторая – максимальный вклад в дисперсию, оставшуюся после учёта первой главной компоненты и т. д. Тогда задача нахождения главных компонент может быть сформулирована следующим образом: найти такое линейное ортогональное преобразование ![]() наблюдаемых переменных
наблюдаемых переменных ![]() , чтобы получить совокупность
, чтобы получить совокупность ![]() некоррелированных нормированных переменных
некоррелированных нормированных переменных ![]() и дисперсии которых обладают свойством
и дисперсии которых обладают свойством
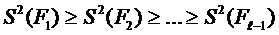 ,
,
а каждая из главных компонент определяется в виде линейного многочлена от наблюдаемых факторов
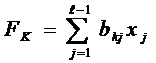 .
.
В матричном виде модель главных компонент будет иметь вид
 ,
,
где:
 – вектор столбец наблюдаемых факторов,
– вектор столбец наблюдаемых факторов,
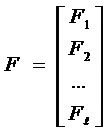 – вектор-столбец главных компонент,
– вектор-столбец главных компонент,
 – матрица ортогонального
– матрица ортогонального
преобразования.
Поскольку матрица [A] является квадратной и симметричной, то ![]() , где I – единичная матрица того же ранга. Следовательно, модель главных компонент может быть преобразована с помощью матричного соотношения
, где I – единичная матрица того же ранга. Следовательно, модель главных компонент может быть преобразована с помощью матричного соотношения
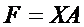 .
.
В математической статистике доказано, что если вектор наблюдаемых факторов X представлен корреляционной матрицей, то существует такое ортогональное линейное преобразование, ![]() , которое даёт диагональную матрицу дисперсий
, которое даёт диагональную матрицу дисперсий

причём матрица [λ] обладает свойствами:
1) 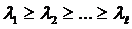 ;
;
2) сумма дисперсий главных компонент (след матрицы ![]() ) равна сумме дисперсий наблюдаемых величин (определяемой следом матрицы R: Tr[R])
) равна сумме дисперсий наблюдаемых величин (определяемой следом матрицы R: Tr[R])
![]() ;
;
3) диагональные элементы матрицы [λ] являются собственными числами матрицы [R];
столбцы матрицы преобразований [A] являются собственными векторами матрицы [R].
4) сумма диагональных элементов матрицы ![]() не только равна сумме диагональных элементов матрицы [R], но и равна числу факторов
не только равна сумме диагональных элементов матрицы [R], но и равна числу факторов ![]() :
:
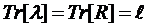 .
.
Таким образом, вычисление главных компонент выборки наблюдений сводится к вычислению собственных чисел и собственных векторов корреляционной матрицы [R] исходной выборки наблюдений.
Преобразование к главным компонентам не меняет сумму дисперсий переменных, а только перераспределяет их таким образом, чтобы на первые компоненты приходилась большая часть всей дисперсии. Благодаря этому, появляется возможность существенного уменьшения числа переменных путём отбрасывания последних компонент, имеющих достаточно малые дисперсии, а потому, являющихся незначимыми.
Анализ главных компонент не требует никаких предварительных гипотез о типе распределения наблюдаемых переменных и возможен при существенной взаимной корреляции наблюдаемых факторов. Более того, именно в этих случаях его применение наиболее эффективно, поскольку именно в этих случаях наиболее существенно может быть сокращено число переменных (главных компонент).
Модель факторного анализа отличается от модели главных компонент тем, что заранее постулируется, что число действующих факторов m существенно меньше числа наблюдаемых переменных ![]() и дополнительным введением характерного фактора
и дополнительным введением характерного фактора ![]() , учитывающего оставшуюся дисперсию, обусловленную ошибками наблюдений:
, учитывающего оставшуюся дисперсию, обусловленную ошибками наблюдений:
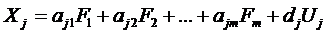 ,
,
где j=1, 2, 3, …, l.
При этом факторы ![]() называются общими, а коэффициенты
называются общими, а коэффициенты ![]() называют нагрузками общих факторов, а фактор
называют нагрузками общих факторов, а фактор ![]() называется характерным фактором. Характерные факторы (для разных j) не связаны между собой и с общими факторами. Что же касается общих факторов, то они могут быть и некоррелированными и коррелированными между собой (в зависимости от принимаемой модификации факторного анализа). Если принять, что общие факторы являются некоррелированными, то дисперсию каждой наблюдаемой переменной
называется характерным фактором. Характерные факторы (для разных j) не связаны между собой и с общими факторами. Что же касается общих факторов, то они могут быть и некоррелированными и коррелированными между собой (в зависимости от принимаемой модификации факторного анализа). Если принять, что общие факторы являются некоррелированными, то дисперсию каждой наблюдаемой переменной ![]() , представленную в нормированном виде, можно разложить на две компоненты:
, представленную в нормированном виде, можно разложить на две компоненты:
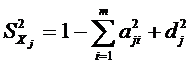 .
.
Здесь первая компонента 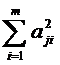 называется общностью и характеризует часть дисперсии, обусловленную действием общих факторов, а вторая компонента
называется общностью и характеризует часть дисперсии, обусловленную действием общих факторов, а вторая компонента ![]() называется дисперсией характерности и характеризует часть дисперсии, обусловленную действием характерного фактора
называется дисперсией характерности и характеризует часть дисперсии, обусловленную действием характерного фактора ![]() .
.
Таким образом, основная задача, решаемая в факторном анализе, заключается в определении числа общих факторов m и оценке 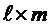 факторных нагрузок.
факторных нагрузок.
В отличие от анализа главных компонент, факторный анализ требует некоторых предпосылок и ограничений:
1. Исследуемый набор наблюдаемых переменных должен подчиняться многомерному нормальному закону распределения. Это требование необходимо для осуществления возможности проверки гипотез о числе общих факторов, а также для получения выборочных оценок факторных нагрузок*.
2. Должны отсутствовать прямые причинно-следственные связи между наблюдаемыми переменными (особенно если они выражаются нелинейными зависимостями).
3. Специфические факторы ![]() , рассматриваемые как помехи, должны быть некоррелированными между собой и с общими факторами.
, рассматриваемые как помехи, должны быть некоррелированными между собой и с общими факторами.
4. Чтобы система уравнений для оценки ![]() факторных нагрузок была определённой, количество предполагаемых общих факторов должно быть значительно меньше числа наблюдаемых переменных. Соотношение между ними должно удовлетворять неравенству
факторных нагрузок была определённой, количество предполагаемых общих факторов должно быть значительно меньше числа наблюдаемых переменных. Соотношение между ними должно удовлетворять неравенству
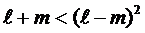 .
.
5. Корреляционная (или ковариационная) матрица наблюдаемых переменных должна быть устойчивой от выборки к выборке, т. е. выборка должна быть представительной, а её объём должен обеспечивать надёжные оценки коэффициентов корреляции (или ковариаций).
К этим предпосылкам следует добавить одно важное ограничение факторного анализа. Оно заключается в том, что полученное в результате факторного анализа факторное пространство общих факторов может быть подвергнуто любым преобразованиям (например, ортогональному вращению или косоугольным преобразованиям системы координат). В результате таких преобразований мы можем получить сколько угодно решений, одинаково хорошо описывающих исходные данные. Возможность получения при факторном анализе множества возможных решений обусловлено тем, что при построении факторной модели мы отказываемся от требования упорядоченности дисперсий факторов (![]() ), которое и приводило к единственности решения в методе главных компонент. Но, с другой стороны, это не следует расценивать как недостаток метода факторного анализа, т. к. в ряде случаев возможность изменения получаемой системы координат позволяет легче интерпретировать получаемую факторную модель с точки зрения её физического смысла. Поэтому факторный анализ обычно включает в себя две процедуры: 1) оценка размерности факторного пространства (m) и получение оценок факторных нагрузок
), которое и приводило к единственности решения в методе главных компонент. Но, с другой стороны, это не следует расценивать как недостаток метода факторного анализа, т. к. в ряде случаев возможность изменения получаемой системы координат позволяет легче интерпретировать получаемую факторную модель с точки зрения её физического смысла. Поэтому факторный анализ обычно включает в себя две процедуры: 1) оценка размерности факторного пространства (m) и получение оценок факторных нагрузок ![]() , адекватно описывающих исходные данные; 2) ортогональное вращение системы координат (факторов) с тем, чтобы получить наиболее хорошо интерпретируемую модель с точки зрения её физического смысла.
, адекватно описывающих исходные данные; 2) ортогональное вращение системы координат (факторов) с тем, чтобы получить наиболее хорошо интерпретируемую модель с точки зрения её физического смысла.
