
Затем обязательно обучить нейронную сеть (клавиша F6) (если сеть не обучается, попробовать создать случайную карту (клавиша Alt-F8)).
1.7.2 Порядок распознавания:
· выбрать окном букву (например, В) и поместить ее в буфер (Аlt+C);
· перейти в окно «ТЕСТ» и нажать ENTER;
· поместить распознаваемый образ (букву В) в окно «ТЕСТ» (Alt+P);
· выйти из режима редактирования, нажав Enter;
· запустить режим распознавания (Ctrl+F5);
· нарисовать символ (похожий по начертанию на две-три буквы обучающего множества) с помощью клавиши ПРОБЕЛ, выйти из режима редактирования (клавиша ENTER или ESC) с заменой старого примера, распознать тестовый пример (клавиша CTRL-F5)).
1.7.3 Занести образ какой-либо буквы в тестовый пример. Изменять этот образ, тестируя сеть после каждого изменения(5-7 раз).
1.7.4 В тестовом примере произвести зашумление чистого образа какого-либо символа. Войти в режим редактирования. С помощью клавиш F5, F6, F7 произвести зашумление (уровень шума можно задать, нажав те же самые клавиши с клавишей CTRL).
1.7.5 Исследовать режимы распознавания образов с учетом предобработки (выбрать тип автокоррелятора).
Включить режим сдвигового автокоррелятора (F9, выбрать меню ПАРАМЕТРЫ и в нем выбрать режим «сдвиг+вращение»). Выбрать, для примера, символ “А”. Скопировать изображение в карман (клавиша ALT-C), зайти в режим редактирования тестового примера и вставить изображение из кармана (клавиша ALT-P), с помощью клавиш CTRL-, CTRL-®, PGUP, PGDOWN сдвинуть изображение, выйти из режима редактирования с заменой старого примера и протестировать сеть на данном примере (клавиша CTRL-F5).
1.7.8 В отчете по результатам выполнения лабораторной работы привести таблицу с результатами распознавания образов.
Требования по выполнению 1-ой лабораторной работы
Пример оформления таблицы 1 в отчете по 1-ой лабораторной работе.
Таблица1
Распознаваемый образ | Perseptr | Linear |
1.Чистый образ (В), центр | F, T, E, D, C | F, T, E, D, C |
2.Чистый образ (В), смещение вверх (вниз, вправо, влево) | T, E, F, T, T | T, F, F, T, T |
3.Чистый образ (В); шум (характеристика шума) | ||
3.1 Инвертирование(F3) | T, D, T, T, T | T, F, T, T, T |
3.2 Затенение(F4) | F, T, E, D, C | F, T, E, D, C |
3.3 Инвертирующий шум (F5,Ctrl+F5) | 0,15 F, T, E, D, C | F, T, E, D, C |
3.4 Добавляющий шум (F6,Ctrl+F6) | 0,15 F, T, E, D, C | 0,15 F, T, E, D, C |
3.5 Гасящий шум(F7,Ctrl+F7) | 0,15 F, T, E, D, C | 0,15 F, T, E, D, C |
3.6 Поворот изображения(G) | D, D, D, D, D | T, D, T, D, D |
3.7 Зеркальное отражение(O) | E, T, E, E, E | E, T, E, E, E |
4. Подключение автокоррелятора (программа предобработки). Выбор типа автокоррелятора в меню «Параметры». Чистый образ - С | ||
4.1 Сдвиговый автокоррелятор | F, T, E, D, C | F, T, E, D, C |
4.2 Автокоррелятор «сдвиг+отражение» | F, T, E, D, C | F, T, E, D, C |
4.3Автокоррелятор «сдвиг+вращение» | D, D, D, D, D | F, T, E, D, C |
4.4 Автокоррелятор «сдвиг+вращение+отражение» | D, D, D, D, D | F, T, E, D, C |
В отчет включить следующие результаты:
1. Вариант задания.
2. Вышеуказанную таблицу.
3. Выполнить сравнительный анализ распознавания искаженных и смещенных образов с помощью программ perseptr.exe, linear.exe при использовании искажения, "зашумления", смещения, вращения и сформировать выводы по качеству распознавания.
4. Выбрать программную модель, которая лучше распознает образы при указанных изменениях параметров.
5. Для программы linear.exe указать наилучший метод вычисления «средней точки»
6. Привести пояснения применения автокоррелятора для улучшения распознавания образов.
7. Выбрать программную модель, которая лучше распознает образы при указанных изменениях параметров.
8. Какие проблемы возникли при распознавании образов.
2 Лабораторная работа №2
Тема: «Распознавание образов с помощью программ pade1.exe, sigmoid.exe, Hopfild.exe”
Внимательно прочитать теоретическую часть лабораторной работы. Целью данной работы является знакомство с нейронными сетями некоторых видов, применяемыми для распознавания образов на основе их моделей (программные модели: pade1.exe, sigmoid.exe, hopfild.exe”).
2.1 PADE
В данной программе реализована полносвязная сеть с рациональными (Паде - в честь изобретателя Паде аппроксимации) нейронами. Эта сеть может обучаться различными способами. Разделяющая функция является нелинейной, что позволяет этой программе распознавать более сложные образы, чем сетям из программ Linear и Perceptr.
Нейронная сеть, имитируемая данной программой, является полносвязной (каждый нейрон получает на каждом шаге сигналы со всех нейронов), с выделенными связями для получения входных данных. Число нейронов в сети может варьироваться от 5 до 10. Число срабатываний сети может изменяться от 1 до 5. Любую полносвязную сеть можно представить в виде слоистой сети с идентичными слоями. В рамках такого представления число срабатываний сети равно числу слоев нейронной сети, следующему за входным слоем.
|
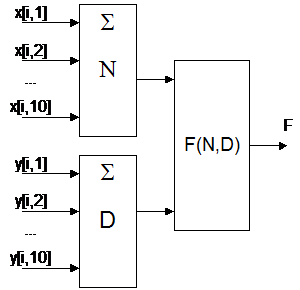
Рациональный нейрон состоит из 4 частей: входных синапсов (x[i, j] — входы сети, y[i, j] — связи с другими нейронами), сумматоров (N, D) и функционального преобразователя (F) и работает по следующему алгоритму. В каждый момент времени со всех нейронов на него поступают сигналы. Перед сумматором каждый сигнал умножается на синаптический вес x[i, j] для сумматора N и y[i, j] для сумматора D (индекс i показывает номер нейрона получающего, а индекс j — номер передавшего сигнал нейрона). Отметим, что в силу ограничений, принятых в данной модели нейронной сети, все синаптические веса неотрицательны. После этого сигналы поступают на сумматоры. Вычисленные сумматорами сигналы передаются на функциональный преобразователь F. В данной программе все нейроны одинаковы (во всем, кроме синаптических весов, поскольку они являются характеристиками не нейронов, а нейронной сети в целом) и преобразуют сигнал по следующему правилу:
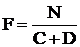 , где C — характеристика нейрона (задается в настройках модели).
, где C — характеристика нейрона (задается в настройках модели).
В данной программе реализован "генетический" подход к формированию стратегии обучения. У Вас в руках ряд процедур, с помощью которых Вы можете подобрать стратегию обучения сети. Комбинации с позадачной организацией обучения и использованием MParTan недопустимы. При построении метода обучения Вы пользуетесь следующей схемой:

MParTan
Входными параметрами процедуры MParTan являются:
1. Начальная карта.
2. Процедура вычисления направления спуска.
3. Локальное обучающее множество.
4. Процедура вычисления оценки.
Процедура ParTan работает по следующему алгоритму:
1. Запоминается текущая карта и оценка текущего обучающего множества, определяемая в соответствии с тремя более низкими уровнями схемы.
2. Используя процедуру вычисления направления спуска, вычисляется направление спуска и производится спуск в этом направлении. Этот шаг алгоритма выполняется дважды.
3. Запоминается текущая карта и оценка текущего обучающего множества.
4. Делается спуск в направлении, ведущем из первой запомненной карты во вторую.
5. Если оценка не равна 0, то повторяется вся процедура сначала.
Процедура MParTan несколько отличается от предыдущей, но ее описание слишком сложно. Однако в ее основе лежит та же идея. Если Вы не используете MParTan, то используется следующая процедура:
1. Используя процедуру вычисления направления спуска, вычисляется направление спуска и производится спуск в этом направлении.
2. Если оценка не равна 0, то повторяется вся процедура сначала.
Процедура спуска
Входными параметрами процедуры спуска являются:
1. Начальная карта.
2. Направление спуска.
3. Локальное обучающее множество.
4. Процедура вычисления оценки.
Алгоритм процедуры спуска:
1. Вычисляется оценка по локальному обучающему множеству (Е1).
2. Делается пробный шаг, добавляя к начальной карте вектор направления спуска умноженный на шаг S.
3. Вычисляется оценка по локальному обучающему множеству (Е2).
4. Если Е2<E1, то увеличивается шаг S, полагается E1=E2 и повторяются шаги алгоритма 1-4 до тех пор, пока не станет E2>E1. Карта, которой соответствует оценка E1, и является результатом работы процедуры.
5. Если после первого выполнения шага 3 оказалось, что E2>E1, то уменьшается шаг S, полагается E1=E2 и повторяются шаги алгоритма 1-3 и 5 до тех пор, пока не станет E2<E1. Карта, которой соответствует оценка E1, и является результатом работы процедуры.
Организация обучения
Под организацией обучения будем понимать способ порождения обучающего множества для одного шага обучения. Исторически самым первым был способ позадачного обучения. Если быть более точным — то по примерного. Процедура по примерного обучения состоит из следующих шагов:
1. Подаем на вход сети задачу.
2. Получаем ответ.
3. Вычисляем оценку.
4. Производим корректировку сети (процедура спуска).
Таким образом, локальное обучающее множество для процедур MParTan, процедура спуска и вычисления направления состоит только из одного примера.
Алгоритмы получения локального обучающего множества для различных способов организации обучения:
По примерный — для каждого шага обучения новый пример.
Позадачный — для первого шага обучения - все примеры первой задачи, для второго - второй и т. д.
Задаче номер N - на всех шагах обучения локальное обучающее множество состоит из всех примеров N-ой задачи.
Усредненный - локальное обучающее множество совпадает с полным, то есть включает в себя все примеры всех пяти задач обучающего множества.
Вычисления направления
Данная программа предусматривает два способа вычисления направления спуска. Первый способ известен как случайный поиск, а второй - как метод наискорейшего спуска. В первом случае в качестве направления спуска используется случайный вектор, а во втором - вектор антиградиента функции оценки.
Метод оценивания
В данной программе принят способ кодирования ответа номером канала: номер того из пяти ответных нейронов, который выдал на последнем такте функционирования наибольший сигнал, задает номер класса, к которому сеть отнесла предъявленный образ. Оценка, таким образом, может быть вычислена только для задачи, ответ которой известен. Данная программа предусматривает два различных способа оценивания решения. Различие в способах оценки связано с различием требований, накладываемых на обученную сеть.
Пусть пример относится к N-ой задаче. Тогда требования можно записать так:
1. Метод наименьших квадратов (МНК).
N-ый нейрон должен выдать на выходе 1. Остальные нейроны должны давать на выходе 0 (как можно более близкое к 0 число).
2. Расстояние до множества (РДМ).
В этом случае требование только одно — разница между выходным сигналом N-го нейрона и выходными сигналами остальных нейронов должна быть не меньше УРОВНЯ НАДЕЖНОСТИ.
Таким образом, для метода наименьших квадратов оценка примера N-ой задачи равна:
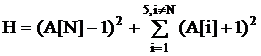
и является обычным Евклидовым расстоянием от правильного ответа до ответа, выданного сетью. Как следует из названия второго метода оценивания, вычисляемая по этому способу оценка равна расстоянию от выданного сетью ответа до множества правильных ответов. Множество правильных ответов для примера N-ой задачи задается неравенствами
A[N]-R > A[I], для всех I¹N.
2.2 SIGMOID
В данной программе реализована полносвязная сеть с сигмоидными нейронами. Эта сеть может обучаться различными способами. Разделяющая функция является нелинейной, что позволяет этой программе распознавать более сложные образы, чем сетям из программ Linear и Perceptr.
Структура сети такая же как в программе Pade.
|
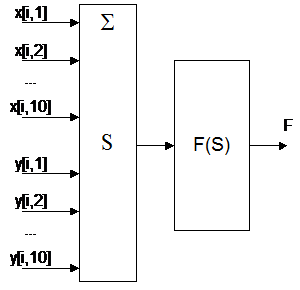
Сигмоидный нейрон состоит из трех частей: входных синапсов (x[i, j], y[i, j]), сумматора (S) и функционального преобразователя и работает по следующему алгоритму. В каждый момент времени со всех нейронов на него поступают сигналы. Перед сумматором каждый сигнал x[i, j] умножается на соответствующий синаптический вес. После этого сигналы поступают на сумматор. Вычисленный сумматором сигнал передается на функциональный преобразователь. В данной программе все нейроны одинаковы (кроме синаптических весов, поскольку они являются характеристиками не нейронов, а нейронной сети в целом) и преобразуют сигнал по следующему правилу:
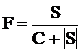 , где C — характеристика нейрона (задается в настройках модели).
, где C — характеристика нейрона (задается в настройках модели).
2.3 HOPFIELD
В данной программе реализована одна из наиболее простых и, в тоже время, наиболее наглядных идеологий нейронных сетей ¾ идеология сетей Хопфилда. Это единственная идеология нейронных сетей распознавания образов, которая не является классификационной по своей сути. Это, однако, часто приводит к эффекту ложной памяти, то есть на некоторые входные данные обученная сеть в качестве ответа выдает химеры ¾ образы, не входившие в обучающее множество.
Идеология сетей Хопфилда предполагает простой алгоритм построения синаптической карты. Говоря точнее, веса связей между нейронами не подстраиваются в ходе обучения, а вычисляются по заданному правилу при предъявлении обучающего множества. В данной программе реализованы два алгоритма вычисления синаптической карты ¾ классический алгоритм Хопфилда и проекционный алгоритм, который повышает запоминающую способность сети Хопфилда.
Нейронная сеть в данной программе является полносвязной (каждый нейрон связан с каждым, в том числе и с самим собой), однородной (все нейроны одинаковы), сто нейронной (поскольку в сетях Хопфилда каждой точке изображения соответствует свой нейрон, а в этой программе используются изображения 10*10) сетью Хопфилда.
Алгоритм работы нейрона:
Пусть N=100 — число элементов входного вектора; X[k] — k-ая компонента входного вектора; M[i, k] — вес передачи k-ого сигнала i-ому нейрону (элемент синаптической карты); a[i] — сигнал i-ого нейрона.
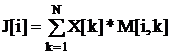 , где i — номер нейрона.
, где i — номер нейрона.
При вычислении синаптической карты в данной программе предусмотрено использование одного из двух заложенных алгоритмов (“Классический или проекционный Хопфилд”). Выбор алгоритма производится в подменю "Параметры" главного меню.
Классический метод Хопфилда:
Поскольку мы имеем дело со сто нейронной сетью исходные данные любого примера можно, представить в виде стомерного вектора. Обозначим вектора соответствующие обучающему множеству через A[1],...,A[k], вес n-ого примера ¾ W[n], а ij-ый элемент синаптической карты ¾ X[i,j]. Тогда алгоритм вычисления синаптической карты можно представить в виде формулы:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
