
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
4.2.Побудуйте кодову послідовність індивідуального завдання, використавши результати виконання пункту 4.6 по темі "РОЗРАХУНОК ПАРАМЕТРІВ ДИСКРЕТИЗАЦІЇ СИГНАЛІВ".
4.3.Виходячи з вищезгаданої ходової послідовності та задавшись значення амплітуди Ak=1, частоти w - довільно, фази рівної 0 побудуйте часові діаграми АМ, ЧМ та ФМ маніпуляцій.
4.4.Використовуючи ту ж кодову послідовність та значення z (де z- число біт в кодовій групі) побудуйте часові діаграми для АІМ, ППМ, ЧІМ та ФІМ.
Значення z взяти із таблиці.
4. Запитання для самопідготовки
5.1. Опишіть суть загального принципу модуляції.
5.2. Які методи модуляції гармонійних коливань Вам відомі, та чим вони відрізняються
5.3 Розкажіть про методи імпульсної модуляції та їх особливості.
5.4. Приведіть математичну інтерпретацію АМ з прикладами.
5.5. Наведіть діаграми спектрів модульованих сигналів.
6. Завдання для індивідуальної роботи
Табличка 1.
N вар. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
z | 3 | 2 | 3 | 4 | 5 | 3 | 4 | 2 | 3 | 4 | 2 | 3 | 2 | 4 | 5 |
Тема 5 МЕТОДИ СТИСКАЮЧОГО КОДУВАННЯ
1. Мета роботи
Мета даної роботи витікає з необхідності практичного засвоєння теоретичних знань одержаних на лекційних заняттях з питань побудови стискаючих оптимальних кодів.
1. Завдання на роботу
В процесі виконання роботи необхідно засвоїти теоретичний матеріал відомих методів стискаючого кодування, провести побудову часових діаграм виходячи з заданної кодової послідовності.
3. Основні теоретичні відомості
Алгоритм побудови коду Хафмена зводиться до того, що символи інформаційного повідомлення вписуються в стовпчик в порядку зменшення ймовірності. Два остані символи з найменшими ймовірностями об’єднуються в одне повідомлення таким чином, що зявляється один додатковий символ, який характеризує об’єднане повідомлення з сумарною ймовірністю P=p1+p2. На наступному кроці алгоритму знову об’єднуються символи що мають найменші ймовірності. Цей процес продовжується до тих пір, доки не буде одержана сумарна ймовірність Р=1.
Процес додавання ймовірностей можна зобразити за допомогою кодового дерева, у якого гілка з більшою ймовірністю надається значення "1",а гілкам з меншою ймовірністю "0". Якщо ймовірності однакові, то значення "1" присвоюється верхні гілці, а значення "0" –нижній, в результаті побудови колового дерева ми можемо, рухаючись по кодовому дереві від вузла, з ймовірністю Р=1 до символа, який потрібно закодувати, одержимо певну кодову комбінацію в коді Хафмена [1],[2],[5].
Розглянемо приклад кодування в коді Хафмена інформаційного повідомлення, яке має символи з ймовірністю згідно з даними табл. 1.
A | a1 | a1 | a1 | a1 | a1 | a1 |
Р | 0.1 | 0.2 | 0.05 | 0.4 | 0.2 | 0.05 |
Розміщуємо елементи в порядку зменшення ймовірностей та будуємо кодове дерево:
![]() ______ 0.4 ______________________________________________________________ 0
______ 0.4 ______________________________________________________________ 0
![]() ______ 0.2 __________________________________________________ 0 1.0
______ 0.2 __________________________________________________ 0 1.0
![]() ______ 0.2 _______________________________ 1 0.6 1
______ 0.2 _______________________________ 1 0.6 1
![]() _______ 0.1 _______________ 1 0.4 1
_______ 0.1 _______________ 1 0.4 1
![]() _______ 0.05._______ 1 0.2 0
_______ 0.05._______ 1 0.2 0
0.1 0
![]() _______ 0.05 _______
_______ 0.05 _______
0
Тепер відповідність символів кодовим комбінаціям встановлюється згідно з табл.2.
|
|
|
|
|
|
101 | 10 | 11001 | 0 | 111 | 1100 |
Перевіряється умова роздільності колових комбінацій, тобто, що жодна з кодових комбінацій не може бути початковою частиною інших комбінацій.
Метод Шеннона-Фано освоїти самостійно за матеріалами лекцій та рекомендованої літератури.
4. Порядок виконання роботи.
4.1. Ознайомтеся з теоретичними викладками.
4.2. виберіть самостійно будь-який текст об’ємом не менше 50 символів.
4.3. Визначте ймовірність появи в тексті всіх символів, включаючи букви, цифри, знаки розділу і т. д. ймовірності визначаються виходячи з того, що загальна ймовірність дорівнює одиниці.
4.4. Побудувати кодові дерева:
а) для коду Шеннона-Фано;
б) для коду Хафмена.
4.5. Виходячи з кодових дерев побудуйте таблиці відповідності та кодовий еквівалент вибраного тексту.
4.6.Підготуйте звіт та захистіть його.
5. Запитання для самопідготовки
5.1. Розкажіть про задачі стискаючого кодування, його переваги та недоліки.
5.2. Поясніть алгоритм кодування в коді Шеннона-Фано.
5.3. Поясніть алгоритм кодування в коді Хафмена.
5.4. Знайдіть коефіцієнт стискання для ваших завдань.
5.5. Розкажіть про особливості декодування стискаючих кодів.
Тема 6 МЕТОДИ ПЕРЕШКОДОСТІЙКОГО КОДУВАНЯ
1. Мета роботи
Мета даної роботи полягає в практичному засвоєнні методів кодування, що дозволяють як виявити, так і усунути помилки в каналі передачі дискретної інформації.
2. Завдання на роботу
В процесі виконання роботи необхідно засвоїти теоретичний матеріал відомих методів перешкодостійкості кодування, та використання його для кодування та декодування інформації..
3. Основні теоретичні відомості
Однією з найбільш важливих вимог, що ставляться до систем передачі дискретної інформації являється забезпечення високої достовірності дискретної інформації, що передається. Ця вимога забезпечує введення надлишковості в інформацію перед її передачею [1],[3].
До найпростіших методів кодування відносять код з перевіркою на парність. Цей метод кодування має найменшу надлишковість, тому що є кодові комбінації з довжиною n вводиться всього лише один додатковий символ, який утворює парну кількість одиниць в кодовій комбінації. При наявності помилки умова парності порушується. Даний код дозволяє тільки виявляти помилки, але не дозволяє їх виправляти.
Одним з найпоширеніших і доволі простих методів кодування, що дозволяють не тільки виявляти, а і виправляти одиночні помилки являються код Хеммінга. Цей код довжини n має k основних інформаційних символів та m додаткових перевірочних символів, причому значення m можна визначити з нерівності:
2m - m ≥ k+1 ,
наприклад, яіащо k=5. то значення m=4, якщо m=3 , то умова не задовільняється. Граничні значення m будуть- 3,4,5 для значення n=7.15.27, а k=4.11.22 і т. д.
Кодову комбінацію у коді Хеммінга можна зобразити у вигляді:
Р1 Р2 I1 Р3 I2 I3 I4
де І — інформаційні символи;
Р— перевірочні символи.
Причому значення перевірочних символів Р1 Р2 P3 формується як сума по модулю два рядки породжуючої матриці:
![]()
![]()
![]()
![]() або
або 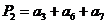
![]()
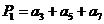
Визначення помилок проводиться за допомогою обчислення синдромів S1, S2 та S3, що являють собою визначені перевірочні співвідношення, що отримуються з перевірочної матриці Нпов у вигляді:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
