
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Основные вехи в истории создания двухъядерных процессоров таковы:
1999 год – анонс первого двухъядерного процессора в мире (IBM Power4 для серверов)
2001 год – начало продаж двухъядерного IBM Power4
2002 год – почти одновременно AMD и Intel объявляют о перспективах создания своих двухъядерных процессоров
2002 год – выход процессоров Intel Xeon и Intel Pentium 4 с технологией Hyper-Threading, обеспечивающей виртуальную двухпроцессорность на одном кристалле
2004 год – свой двухъядерный процессор выпустила Sun (UltraSPARC IV)
2004 год – IBM выпустила второе поколение своих двухъядерных процессоров (IBM Power5). Каждое процессорное ядро Power5 поддерживает аналог технологии Hyper-Threading
2005 год, 18 марта – Intel выпустила первый в мире двухъядерный процессор архитектуры x86
2005 год, 21 марта – AMD анонсировала полную линейку серверных двухъядерных процессоров Opteron, анонсировала десктопные двухъядерные процессоры Athlon 64 X2 и начала поставки двухъядерных Opteron 8xx
2005 год, 20-25 мая – AMD начинает поставки двухядерных Opteron 2xx
2005 год, 26 мая – Intel выпускает двухъядерные Pentium D для массовых ПК
2005 год, 31 мая – AMD начинает поставки Athlon 64 X2
С момента выхода первых процессоров Intel на архитектуре предыдущего поколения (NetBurst), старые приверженцы (кто сказал «фанаты»?) компании пребывали в состоянии постоянной встревоженности: или по поводу того, что процессоры AMD демонстрировали в среднем более хорошие результаты, или по поводу того, что Intel удавалось AMD обогнать — но всё же не настолько, чтобы можно было успокоиться. В результате, к 2006 году большинство было настроено успокоиться окончательно. Либо одним способом (увидев превосходные результаты новой архитектуры), либо другим (увидев результаты «не превосходные», и окончательно разочаровавшись). Третьего дано не было, и Intel сама это отлично понимала
2006-й год в процессорной отрасли, по-видимому, так навсегда и останется «годом, в который вышел Conroe»-Меrоm-
Микроархитектура Intel Core
Микроархитектура Pentium 4 NetBurst и ее последняя модификация в процессорах Prescott/Nocona были суперконвейерными, нацеленными на максимальные тактовые частоты. Корпорация Intel выпускала уже и двухъядерные процессоры, однако их микроархитектура не была специально оптимизирована для достижения высокой производительности при низком энергопотреблении. Для многоядерных процессоров с более низкими частотами ее понадобилось существенно переделывать, и была создана новая микроархитектура, Core. В ней число стадий основного, целочисленного конвейера было уменьшено более чем вдвое — до 14. Интересно, что почти столько же стадий имеет IBM Power4 — 15, в AMD Opteron — 12 стадий. Самый короткий конвейер в Sun UltraSPARC T1 (шесть стадий), но отдельные его ядра не нацелены на максимум производительности, а тактовая частота не превышает 1,2 ГГц [3].
Конечно, много важных компонентов микроархитектуры остались в Core неизменными. Можно сказать, что базовые особенности были заложены еще в суперскалярном процессоре Pentium Pro, когда появилась перекодировка CISC-команд x86 во внутренние RISC-подобные микрооперации, внеочередное (Out of Order, OoO) спекулятивное выполнение микроопераций из буфера переупорядочения (ReOrder Buffer, ROB) и др.
Однако в распоряжении разработчиков Core были сразу две разные микроархитектуры — кроме «высокочастотной линии» NetBurst-Prescott-Pentium D (двухъядерный процессор для ПК) и Dempsey (двухъядерный серверный процессор Xeon DP), имелись еще израильские разработки Pentium M — Core Duo (бывшее кодовое название Yonah) для мобильных ПК, в которых частоты и тепловыделение ниже. И микроархитектура Core взяла лучшие черты от обеих линий.
Чрезвычайно важно отметить, что процессоры с микроархитектурой Core обладают поддержкой 64-битных расширений Enhanced Memory 64 Technology (EM64T). Это существенное отличие новой микроархитектуры от микроархитектуры процессоров Pentium M, которые, как и более современные их последователи Core Duo, 64-битные режимы работы не поддерживают в силу заложенных в них ограничений.
Что же касается более конкретных деталей, то первые процессоры, входящие в Intel Core Microarchitecture, имеют двухъядерный дизайн (выполненный на едином полупроводниковом кристалле), обладают кеш-памятью первого уровня объёмом 64 Кбайта (которая разделяется на две части по 32 Кбайта для кода и данных) и комплектуются общей (разделяемой) на оба ядра кеш-памятью второго уровня объёмом 2 или 4 Мбайта.(См. рис)
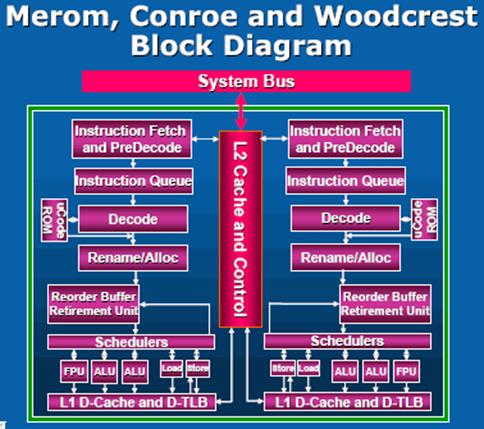

Процессоры с новой микроархитектурой для ноутбуков, получившие кодовое имя Merom, выпускаются исходя из их требуемого типичного тепловыделения, не превышающего 35 Ватт. Это позволит при сохранении того же, как и у мобильных компьютеров на базе современных процессоров Intel Core Duo, времени работы от аккумулятора, достичь более чем 20-процентного прироста в производительности.
Серверные варианты процессоров, названные кодовым именем Woodcrest, по сравнению с предыдущими двухъядерными CPU линейки Xeon, получили 80-процентный прирост в быстродействии, а их типичное энергопотребление снизилось примерно на 35% и составляет около 80 Вт.
Что же касается процессоров для "настольного" сегмента рынка, то им присвоено кодовое имя Conroe. Рост производительности Conroe по сравнению со старшими моделями линейки Pentium D 9XX составляет около 40%. При этом типичное энергопотребление ниже примерно на такую же величину. В результате, энергопотребление процессоров для настольных компьютеров (исключая модели, нацеленные на энтузиастов) лежит в пределах 65 Вт.
Какие же микроархитектурные инновации внесены в Intel Core Microarchitecture.
1. Технология Intel Wide Dynamic Execution призвана обеспечить выполнение большего количества команд за каждый такт, повышая эффективность выполнения приложений и сокращая энергопотребление. Каждое ядро процессора, поддерживающего эту технологию, теперь может выполнять до четырех инструкций одновременно с помощью 14-стадийного конвейера.
2. Технология Intel Intelligent Power Capability, активируя отдельные узлы чипа только по мере необходимости, значительно снижает энергопотребление системы в целом.
3. Технология Intel Advanced Smart Cache подразумевает наличие общей для всех ядер кэш-памяти L2, совместное использование которой снижает энергопотребление и повышает производительность. При этом, по мере необходимости, одно из ядер процессора может использовать весь объём кэш-памяти при динамическом отключении другого ядра.
4. Технология Intel Smart Memory Access повышает производительность системы, сокращая время отклика памяти и оптимизируя, таким образом, использование пропускной способности подсистемы памяти.
5. Технология Intel Advanced Digital Media Boost позволяет обрабатывать все 128-разрядные команды SSE, SSE2 и SSE3, широко используемые в мультимедийных и графических приложениях, за один такт, что увеличивает скорость их выполнения.
Теперь остановимся подробнее на каждом из них.
Первое упоминание термина Dynamic Execution (динамическое исполнение) относится к процессорам Pentium Pro, Pentium II и Pentium III. Говоря о динамическом исполнении команд в этих процессорах, Intel подразумевал принципиально новую суперскалярную микроархитектуру P6, способную выполнять анализ потока кода, и обладающую возможностями спекулятивного (упреждающего) и внеочередного исполнения команд. При переводе процессоров для настольных компьютеров на микроархитектуру NetBurst, Intel стал говорить уже об усовершенствованном динамическом исполнении, которое, помимо перечисленных выше свойств, обладало более глубоким уровнем анализа кода и значительно улучшенными алгоритмами предсказания переходов.
Теперь же, в новой микроархитектуре Core, речь идёт о "широком" динамическом исполнении. Широким оно стало благодаря тому, что будущие процессоры Intel смогут исполнять больше операций за такт, нежели их предшественники. Благодаря добавлению в каждое ядро дополнительного декодера и исполнительных устройств, каждое из ядер будущих процессоров сможет выбирать из программного кода и исполнять до четырёх x86 инструкций одновременно, в то время как остальные процессоры AMD и Intel (как "настольные", так и мобильные), могут обрабатывать не более трёх инструкций за такт. На четыре декодера (один для сложных инструкций и три – для простых) микроархитектура Core предполагает наличие шести портов запуска (один – Load, два – Store и три универсальных). Кроме того, микроархитектура Core получила более совершенный блок предсказания переходов и более вместительные буферы команд, используемые на различных этапах анализа кода для оптимизации скорости исполнения.
Следует напомнить, что предшественники микроархитектуры Core, процессоры Pentium M, обладали чрезвычайно интересной технологией micro-ops fusion, направленной на снижение "накладных расходов" при выполнении некоторых x86 команд. Суть технологии micro-ops fusion чрезвычайно проста. В случае если x86 команда распадается на зависимые друг от друга микроинструкции, декодер осуществляет их привязку друг к другу. Такие последовательности микроинструкций, "склеенные" технологией micro-ops fusion для исполнения процессором в определённом порядке, представляются процессором на всех этапах, кроме собственно исполнения, одной командой. Это позволяет избежать ненужных простоев процессора в случае, если связанные микроинструкции оказываются оторванными друг от друга в результате работы алгоритмов внеочередного выполнения.
В дополнение к весьма удачной технологии micro-ops fusion, микроархитектура Core получила технологию macrofusion. Данная технология направлена на увеличение числа исполняемых за такт команд и заключается в том, что ряд пар связанных между собой последовательных x86 инструкций, таких как, например, сравнение со следующим за ним условным переходом, представляются внутри процессора одной микроинструкцией. Такая микроинструкция рассматривается планировщиком и выполняется на исполнительных устройствах как одна команда. Таким путём достигается как увеличение темпа исполнения кода, так и некоторая экономия энергии.
Таким образом, по данным Intel, в общем случае удаётся снизить нагрузку операций до 15% и сократить число микроопераций до 10%. Как видно на иллюстрации ниже, модули префетча (предварительной выборки) подготавливают ряд x86 команд, при этом до пяти из них могут одновременно обрабатываться четырьмя блоками декодирования. В случае возможности слияния двух команд (Macro-Fusion), появляется фактическая возможность параллельной обработки пяти инструкций за такт (единовременно может образовываться не более одной макрокоманды).
Отдельным направлением, по которому выполнялось совершенствование микроархитектуры Core, стала переработка блоков исполнения SIMD инструкций (SSE, SSE2, SSE3). Современное программное обеспечение, например, для обработки изображений, видео и звука, шифрования, научной и финансовой деятельности, достаточно широко использует наборы команд SSE, которые позволяют работать со 128-битовыми операндами различного характера (векторами и целочисленными либо вещественночисленными данными повышенной точности).
Именно этот факт заставил инженеров Intel задуматься об ускорении работы SSE блоков процессора, тем более что до недавнего времени процессоры Intel исполняли одну SSE-инструкцию, работающую с 128-битными операндами, лишь за два такта. Один такт тратился на обработку старших 64 бит, второй такт – на обработку младших. Новая же микроархитектура Core позволила ускорить работу с SSE инструкциями в два раза.
Блоки SSE в процессорах полностью 128-битовые, что даёт возможность увеличить количество данных, обрабатываемых процессором за такт. И особенно в тех задачах, которые используют SIMD инструкции наиболее активно, а это, в первую очередь, различного рода мультимедиа-приложения.
Помимо увеличения скорости работы блоков исполнения SIMD инструкций, Intel в очередной раз провёл ревизию системы команд SSE. Результатом стало то, что уже ставший привычным набор инструкций SSE3 был вновь дополнен восемью новыми командами. Вообще говоря, указанное расширение набора команд SSE3 задумывалось ещё при внедрении процессоров с кодовым именем Tejas, но в силу их отмены соответствующая модификация нашла своё место в микроархитектуре Core.
Поскольку микроархитектура Core изначально проектировалась в двухъядерном варианте, разработчики получили возможность оптимизировать отдельные функциональные блоки процессоров с учётом их этой особенности. Так, в отличие от предыдущих CPU для настольных компьютеров, процессоры с микроархитектурой Core получили разделяемый между вычислительными ядрами L2 кеш. Алгоритмы работы этой кеш-памяти во многом подобны тем механизмам, которые реализованы в настоящее время в двухъядерных мобильных процессорах Intel Core Duo.
Плюсов такого подхода к реализации кеш-памяти видится несколько. Во-первых, у процессора появляется возможность гибко регулировать размеры областей кеша, используемых каждым из ядер. Иными словами, доступ ко всему объёму L2 кеша может получить любое из ядер процессора с микроархитектурой Core. Это, в частности, значит и то, что когда одно из ядер бездействует, второе получает в своё полное распоряжение весь объём кеш-памяти. Если же одновременно работают два процессорных ядра, то кеш делится между ними пропорционально, в зависимости от частоты обращений каждого ядра к оперативной памяти. Более того, если оба ядра работают синхронно с одними и теми же данными, то хранятся они в общем L2 кеше только однократно. То есть, разделяемый интеллектуальный L2 кеш процессоров с микроархитектурой Core гораздо более эффективен и, даже можно сказать, более вместителен, чем два отдельных кеша, разделённых между ядрами.
Разделяемая кеш-память может оказаться полезной двухъядерным процессорам и в некоторых других случаях. Например, в технологии Core Multiplexing Technology, обеспечивающей механизм динамического отключения второго ядра, в зависимости от характера нагрузки на процессор. Очевидно, что в этом случае единый на два ядра кеш второго уровня решил массу проблем с технической реализацией этой технологии.
Второй значительный плюс объединённой кеш-памяти второго уровня заключается в том, что благодаря такой его организации значительно снижается нагрузка на оперативную память системы и на процессорную шину. Дело в том, что в этом случае перед системой не стоит задача контроля и обеспечения когерентности кеш-памяти различных ядер. В системах с двухъядерными процессорами с раздельными кешами, в случае, если оба ядра работают с одними и теми же данными, эти данные дублируются в кеш-памяти каждого из ядер. Таким образом, возникает необходимость в контроле их актуальности. Перед тем, как извлечь такие данные из L2 кеша для обработки, каждое процессорное ядро должно проверить, не изменило ли эти данные другое ядро. И если это так, то требуется обновление содержимого кеш-памяти, которое в системах на базе процессоров с микроархитектурой NetBurst выполняется через системную шину и оперативную память. Общий же на два ядра кеш позволяет полностью отказаться от этого неэффективного алгоритма.
Кроме того, посредством управляющей логики, предусмотренной в процессорах с микроархитектурой Core, стал возможным более простой обмен данными и между кеш-памятью первого уровня каждого из ядер через общий L2 кеш, что в итоге даёт возможность гораздо более результативного взаимодействия ядер при совместной работе над одной задачей.
Технологии, объединенные под этим собирательным названием, направлены на уменьшение задержек, которые могут возникнуть при доступе процессора к обрабатываемым данным. Очевидно, что для этой цели как нельзя лучше подходит предварительная выборка данных из памяти в обладающие гораздо более низкой латентностью L1 и L2 кеши процессора. Надо сказать, что алгоритмы предварительной выборки данных эксплуатируются в процессорах Intel достаточно давно. Однако с выходом микроархитектуры Core соответствующий функциональный узел был усовершенствован.
Микроархитектура Core предполагает реализацию в процессоре шести независимых блоков предварительной выборки данных. Два блока нагружаются задачей предварительной выборки данных из памяти в общий L2 кеш, ещё по два блока работают с кешами первого уровня каждого из ядер CPU. Каждый из этих блоков независимо друг от друга отслеживает закономерные обращения (потоковые, либо с постоянным шагом внутри массива) исполнительных устройств к данным. Базируясь на собранной статистике, блоки предварительной выборки стремятся подгружать данные из памяти в процессорный кеш ещё до того, как к ним последует обращение.
Также, L1 кеш каждого из ядер процессоров, построенных на базе Intel Core Microarchitecture, имеет по одному блоку предварительной выборки инструкций, работающий по аналогичному принципу.
Кроме улучшенной предварительной выборки данных, Intel Smart Access предполагает ещё одну интересную технологию, названную memory disambiguation (устранение противоречий в памяти). Данная технология направлена на повышение эффективности работы алгоритмов внеочередного исполнения инструкций, осуществляющих чтение и запись данных в памяти. Дело в том, что в современных процессорах, осуществляющих внеочередное исполнение команд, не допускается выполнение команды чтения до того, как не будут завершены все инструкции сохранения данных. Объясняется это тем, что планировщик заранее не обладает информацией о зависимости загружаемых и сохраняемых данных.
Однако достаточно часто последовательные инструкции сохранения и загрузки данных из памяти не имеют между собой никакой взаимной зависимости. Поэтому, отсутствие возможности изменения порядка их выполнения зачастую снижает загрузку исполнительных устройств и эффективность работы CPU в целом. Для решения этой проблемы и предусматривается новая технология memory disambiguation. Она предусматривает специальные алгоритмы, позволяющие с достаточно высокой вероятностью устанавливать зависимость последовательных команд сохранения и загрузки данных, и даёт возможность, таким образом, применять внеочередное выполнение инструкций к этим командам.
Таким образом, при условии правильной работы алгоритмов memory disambiguation процессор получает возможность более эффективного использования собственных исполнительных устройств. В случаях же ошибок в определении зависимых инструкций загрузки и сохранения данных, которые, согласно информации разработчиков, случаются достаточно редко, технология memory disambiguation детектирует возникший конфликт, перезагружает корректные данные и инициирует повторное исполнение "ошибочно" выполненной ветви кода.
Совместное использование предварительной выборки данных и технологии memory disambiguation повышает эффективность работы процессора с памятью не только за счёт минимизации возможных простоев исполнительных устройств, но и благодаря более эффективному использованию пропускной способности шины и снижению латентностей при обращениях к памяти.
Так как при разработке новой микроархитектуры Core инженеры стремились к оптимизации параметра "производительность на ватт", а также из-за того, что данная микроархитектура используется и в основе процессоров для ноутбуков, разработчики Intel сразу предусмотрели набор технологий, направленных на снижение энергопотребления и тепловыделения. Безусловно, процессоры получили в своё распоряжение хорошо зарекомендовавшие себя технологии семейства Demand Based Switching (в первую очередь, Enhanced Intel SpeedStep и Enhanced Halt State). Но речь в данном случае идёт не о них.
Процессоры, основанные на микроархитектуре Core, получили возможность интерактивного отключения тех собственных подсистем, которые не используются в данный момент. Причём речь в данном случае идёт не о ядрах целиком. Декомпозиция процессора на отдельные функциональные узлы выполнена на гораздо более низком уровне. Каждое из процессорных ядер поделено на большое количество блоков и внутренних шин, питание которыми управляется раздельно посредством специализированных дополнительных логических схем. Главной особенностью этих схем, входящих в Intel Intelligent Power Capability, является то, что их работа не влечёт за собой увеличение времени отклика процессора на внешние воздействия, вызванное необходимостью приводить отключенные блоки в функциональное состояние.
Следует отметить, что возможность деактивации различных блоков CPU во время его работы заставило разработчиков пересмотреть подход к измерению температуры процессора. Процессоры с микроархитектурой Core снабжаются несколькими температурными датчиками, расположенными на ядре в тех местах, которые предрасположены к сильному нагреву.
Для обработки показаний этих многочисленных датчиков процессор содержит специальную схему, определяющую максимальную температуру. Именно эта температура и рапортуется процессором пользователю и системам аппаратного мониторинга.
Каждая из этих технологий по отдельности способна значительным образом повысить эффективность процессора, а все вместе они значительная сила для установления новых стандартов производительности в сочетании с экономным энергопотреблением.
Таким образом, новая микроархитектура Intel Core задействовала все плюсы, уже реализованные в первых поколениях мобильных процессоров Intel Pentium M, взяла всё самое лучшее из наработок архитектуры Intel NetBurst, и, в дополнение, обогатилась самыми свежими инновационными идеями разработчиков.
Penryn построены на базе усовершенствованной микроархитектуры Intel Core. Основным их отличием стал переход на 45-нм техпроцесс и некоторые архитектурные новшества, вследствие чего повысилась энергоэффективность, расширился частотный потенциал, увеличилось количество выполняемых команд за такт и прочее.
Усовершенствования, которые принес переход на новый техпроцесс, интересно рассмотреть с позиций количественного сравнения. Например, четырехъядерные процессоры Penryn включают около 820 млн. транзисторов, которые разместились на двух кристаллах площадью 107 мм2. Для сравнения, современные четырехъядерные процессоры Intel Kentsfield имеют 582 млн. транзисторов, при этом площади кристаллов четырехъядерных процессоров, выпускающихся по 65-нм нормам, составляют 143 мм2.
Новшества, которые принесло следующее поколение процессоров, можно рассматривать по отношению к пяти современным технологиям Intel: Wide Dynamic Execution, Advanced Smart Cache, Smart Memory Access, Advanced Digital Media Boost, Intelligent Power Capability.
Механизм Wide Dynamic Execution обеспечивает выполнение большего числа команд за один тактовый цикл, что увеличивает производительность и помогает добиться повышения энергоэффективности. В рамках этой технологии компания Intel представил усовершенствованный более быстрый блок деления, основанный на базе методики radix-16, а также улучшенную технологию виртуализации Enhanced Intel Virtualization Technology. Инновационная архитектура на базе radix-16 позволяет существенно уменьшить задержки при выполнении целочисленных операций деления, а также операций деления с плавающей запятой.
Технология Advanced Smart Cache нацелена на обеспечение более высокой производительности и эффективности кэш-памяти. В процессорах семейства Penryn компания Intel решила увеличить объем кэша. Так, двухъядерные процессоры оснащаются кэшем L2 емкостью до 6 Мб, а отдельные четырехъядерные модели обзавелись 12-Мб кэш-памятью. Частотные характеристики преодолели планку 3 ГГц.
В рамках технологии Smart Memory Access говорится об увеличении пропускной способности шины. Подтверждилась информация об освоении шины FSB 1600 МГц. Шина FSB 1600 МГц появилась в некоторых моделях процессоров для серверов и рабочих станций.
Технология Advanced Digital Media Boost применяется для ускорения обработки видео, изображения и речевых потоков. Для повышения производительности при обработке медиаданных Intel решила добавить к архитектуре ISA набор расширений SSE4 (Streaming SIMD Extensions 4), который стал доступным для большинства массовых секторов рынка ПК с появлением 45-нм процессоров. Этот новый набор команд включает множество инновационных инструкций (их насчитывается около 50), которые условно можно разделить на две группы:
Примитивы векторизации для компиляторов и ускорители мультимедийных приложений;
Ускорители обработки строк и текстовой информации.
Пожалуй, на SSE4 остановимся детальнее, поскольку технология является одним из ключевых нововведений. Для начала опишем приложения, которые затронуло это усовершенствование. Улучшения коснулись графики, кодирования и обработки видео, создания трёхмерных изображений, игр, Web-серверов, серверов приложений. Как утверждает Intel, увеличилась производительность приложений с высокой интенсивностью вычислений – анализа хранилищ данных, СУБД, сложных алгоритмов поиска и сопоставления, алгоритмов сжатия звука, видео, изображений и данных, алгоритмов синтаксического анализа и анализа логических состояний, а также многих других.
По словам Intel, SSE4 – самое масштабное и значительное расширение архитектуры Intel ISA со времени появления SSE2. Набор команд SSE4 содержит несколько примитивов векторизации для компиляторов, обеспечивающих дальнейшее увеличение производительности и эффективности мультимедийных приложений. Имеются также и новые инновационные инструкции для обработки строк.
Еще одним усовершенствованием является механизм перестановок – Super Shuffle Engine. Новый блок умеет выполнять перестановки значений сразу во всем 128-разрядном регистре за один такт. Это существенно повышает производительность при обработке операций, связанных с перестановкой (упаковка, распаковка, сдвиг упакованных значений, вставка). В среднем наблюдается двукратное увеличение производительности.
Интересные новшества касаются уменьшения уровня потребления мощности и увеличения показателя «производительность на ватт». В связи с этим Intel представила две новые технологии: Deep Power Down Technology и Enhanced Dynamic Acceleration Technology.
Технология Deep Power Down Technology внедрена, в первую очередь, в процессоры для мобильных платформ (Mobile Penryn). Для понижения энергопотребления в режиме бездействия добавлено еще одно особое состояние процессора, именуемое как Deep Power Down Technology State, или C6. В этом режиме предусмотрено отключение ядер, при этом также полностью отключается кэш-память. Это позволяет существенно понизить напряжение ядра и потребляемой мощности, что, в свою очередь, увеличивает время работы батареи.
Интересным нововведением является технология Enhanced Dynamic Acceleration Technology (EDAT). Её идея состоит в следующем. Для простоты возьмём случай с двухъядерным процессором. Поскольку в однопоточных приложениях от многоядерности толку мало, основную роль здесь играет производительность отдельно взятого ядра. Поэтому Intel предусмотрела увеличение частоты работающего ядра (non-idle core), в то время как второе (idle core) находится в одном из состояний бездействия (C3-C6) и его тепловыделение резко сокращается. Эту разницу использует работающее ядро и повышает свою частоту до достижения процессором граничного уровня TDP.
Теперь об уровне TDP 45-нм процессоров. Двухъядерные Penryn для настольных ПК попадут в энергетический класс 65 Вт, а для их четырехъядерных родственников предусмотрены тепловые пакеты 95 и 130 Вт. В серверном сегменте для двухъядерных Intel Xeon уровни TDP составят 40, 65 и 80 Вт, а для четырехъядерных – 50, 80 и 120 Вт.
Для маркировки Penryn в качестве 4-й цифры индекса используется 8 и 9 (серии 8000 и 9000).
У МП Penryn используются новые технологии:
Deep Power Down, снижающая энергопотребление путем уменьшения токов утечки транзисторов в моменты их простоя,
усовершенствованная Dynamic Acceleration Technology, повышающая производительность однопоточных приложений путем отключения простаивающих ядер и повышения тактовой частоты работающего ядра
усовершенствованная Intel Virtualization Technology, уменьшающая время переключения виртуальных машин.
МП семейства Penryn поддерживают расширенный набор команд Intel Streaming SIMD Extension 4 (SSE4), а также кэш-память L2 большего объема:
двухъядерные до 6 Мбайт,
а четырехядерные до 12 Мбайт.
Согласно внутренним тестам Intel, в игровых приложениях наблюдается 20-ти процентный прирост производительности новых чипов, а в операциях с декодированием видео (при условии использования SSE4) – более 40% прирост. Если сравнивать серверный процессор Penryn с частотой более 3 ГГц и Xeon X5355, 2,66 ГГц, FSB 1333 МГц, прирост в приложениях, интенсивно использующих операции с плавающей запятой и чувствительных к пропускной способности, составляет около 45%.
После наладки массового производства чипов Penryn, Intel представил процессоры Nehalem с новой одноименной микроархитектурой – на смену Intel Core. Примерно через два-три года после анонса 45-нм процессоров – ориентировочно, ближе к , Intel надеется представить новый, более прецизионный 32-нм техпроцесс. Пока эти планы довольно туманны: даже переход на 45 нм сопровождался большими трудностями и потребовал задействования совершенно новых материалов (high-k диэлектрики и металлические затворы). В рамках 32 нм техпроцесса будут представлены процессоры с рабочим названием Westmere, ранее известные как Nehalem-C, с той же микроархитектурой Nehalem.
Через два года после появления Nehalem на смену придёт микроархитектура Gesher. О ней пока очень мало сведений. Известно лишь, что первые процессоры Gesher будут выпускаться по 32-нм техпроцессу. На этом прогнозы относительно развития процессоров заканчиваются.
Примеры процессров с микроархитектурой Intel Core
Core 2
Это потомок микроархитектуры Intel P6, на которой, начиная с процессора Pentium Pro, построено большинство микропроцессоров Intel, исключая процессоры с архитектурой NetBurst.
Введя новый бренд, от названий Pentium и Celeron Intel не отказалась, в 2007 году переведя их также на микроархитектуру Core, и на данный момент доступны процессоры Pentium Dual-Core (не путать с Pentium D) и Core Celeron (400-я серия). Но теперь воссоединились мобильные и настольные серии продуктов (разделившиеся на Pentium M и Pentium 4 в 2003 году).
Первые процессоры Core 2 официально представлены 27 июля 2006 года. Также как и их предшедственники, процессоры Intel Core, они делятся на модели Solo (одноядерные), Duo (двухъядерные), Quad (четырёхъядерные) и Extreme (двух - или четырёхъядерные с повышенной частотой и разблокированным множителем). Процессоры получили следующие кодовые названия — «Conroe» (двухъядерные процессоры для настольного сегмента), «Merom» (для портативных ПК), «Kentsfield» (четырёхъядерный Conroe) и «Penryn» (Merom, выполненный по 45 нанометровому техпроцессу). Хотя процессоры «Woodcrest» также основаны на архитектуре Core, они выпускаются под маркой Xeon.[1]. С декабря 2006 года все процессоры Core 2 Duo производятся на 300-миллиметровых листах на заводе Fab 12 в Аризоне, США и на заводе Fab 24-2 в County Kildare, Ирландия.
В отличие от процессоров архитектуры NetBurst (Pentium 4 и Pentium D), в архитектуре Core 2 ставка делается не на повышение тактовой частоты, а на улучшение других параметров процессоров, таких как кэш, эффективность и количество ядер. Рассеиваемая мощность этих процессоров значительно ниже, чем у настольной линейки Pentium. С параметром TDP, равным 65 Вт, процессор Core 2 имеет наименьшую рассеиваемую мощность из всех доступных в продаже настольных чипов, в том числе на ядрах Prescott (в системе кодовых имён Intel) с TDP, равным 130 Вт, и на ядрах San Diego’s (в системе кодовых имён AMD) с TDP, равным 89 Вт.
Особенностями процессоров Intel Core 2 являются EM64T (поддержка архитектуры EM64T), технология поддержки виртуальных x86 машин Vanderpool (en), NX-бит и набор инструкций SSSE3. Кроме того, впервые реализованы следующие технологии: LaGrande Technology, усовершенствованная технология, SpeedStep (EIST) и Active Management Technology (iAMT2).
Процессорные ядра
Conroe
Intel Core 2 Duo E6600 «Conroe»
Первые процессорные ядра Intel Core 2 Duo с кодовыми именами Conroe и Allendale были представлены 27 июля 2006 года. Эти процессоры созданы с использованием 65 нм техпроцесса и предназначены для настольных систем, заменяя линейки Pentium 4 и Pentium D. Intel заявляет, что Conroe обеспечивает на 40 % большую производительность при меньшем на 40 % энергопотреблении по сравнению с Pentium D. Все Conroe процессоры имеют 4 Мб L2-кэша, однако, у процессоров E6300 и E6400 половина L2-кэша отключена, поэтому для использования им доступно только 2 Мб.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
