

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ЛАБОРАТОРНАЯ РАБОТА №3
ПОСТРОЕНИЕ ЛОГИТ-РЕГРЕССИИ В SAS ENTERPRISE MINER
1. Зайти в программу «SAS ENTERPRISE MINER» через удаленный рабочий стол (указать имя компьютера «SAS», а потом через меню «Все программы» выбрать «SAS ENTERPRISE MINER»). Создать новый проект с именем Regression.
New Project > Next
Ввести имя проекта Regression
Указать папку для сохранения проекта.
Next > Next > Finish
2. Подключить библиотеку AAEM53.
File > New > Library
Name = AAEM53
Path = c:\workshop\aaem53
Finish
3. Создать диаграмму с именем Regression.
File > New diagram
Name = Regression
4. Задать источник данных PVA97NK. sas7bdat
File > New > Data Source
Next > Browse > AAEM53.PVA97NK > Next
Выборка данных состоит из 9686 записей и 28 параметров
На закладке №4 Metadata Advisory нажмите
Advanced > Customize
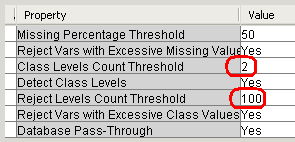
Class Levels Count Threshold = 2, то только бинарные численные переменные будут восприниматься как категориальные. А все остальные численные переменные у которых более чем два уровня будут восприняты как интервальные (непрерывные).
Благодаря тому, что Reject Levels Count Threshold =100 переменная DemCluster не была отклонена из анализа из-за большого количества уровней.
Next
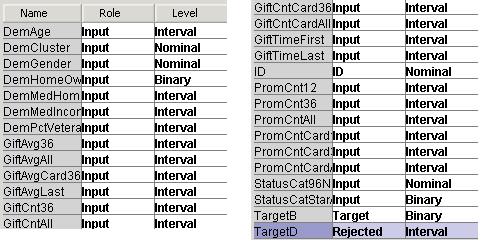
В наборе данных присутствует две целевые переменные:
TargetB – отвечает за отклик
1 – да (клиент даст деньги на нашу благотворительность)
0 – нет
TargetD – интервальная переменная и измеряет сумму отклика
Переменной TargetD нужно задать роль Rejected.
Next > Next > Next > Finish
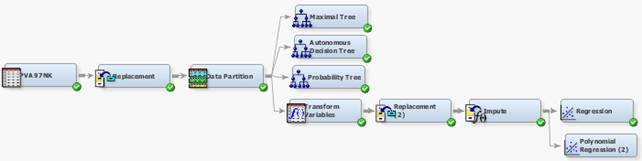
5. Перетащите компонент источник данных PVA97NK на диаграмму и соедините с компонентом Replacement

В загруженном наборе данных PVA переменная DemMedIncome, которая описывает медианный доход по региону, присутствуют нулевые значения. От них нужно избавиться, чтобы они не искажали действительную картину, так как часто на практике не имея информации о доходе, пользователь-аналитик, при сборе информации, просто вбивают ноль при заполнении анкеты клиента. В то время как между нулевым значением и unknow существует большая разница.
Перетащите источник данных PVA на диаграмму и соедините с компонентом Replacement.
Replacement Editor
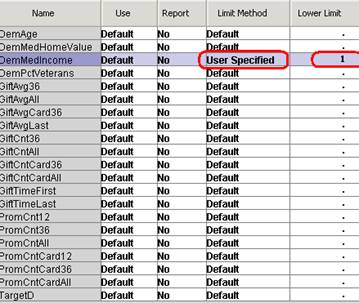
DemMedIncome – демографический показатель – Медианный доход по региону
Создается новый столбец Replacemebt : DemMedIncome который содержит значения missing если значение DemMedIncome < 1.
6. Присоедините компонент Data Partition с настройками 50 / 50 / 0

Приписывание синтетического значения вместо пропущенного
1. Выберите вкладку Modify
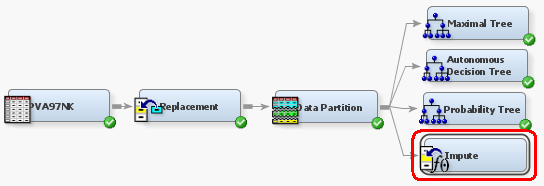
2. Поместите компонент Impute в рабочую область диаграммы
3. Соедините Data Partition и Impute, как показано на рисунке ниже.
Использование индикаторов пропущенных значений
Для создания индикаторов пропущенных значений задайте настройки в свойств в группе свойств Score компонента Impute, как показано на рисунке ниже.
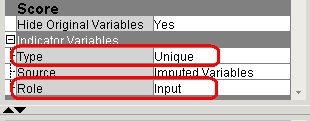
1. Выберите Indicator Variable => Type => Unique
2. Выберите Indicator Variable => Role => Input
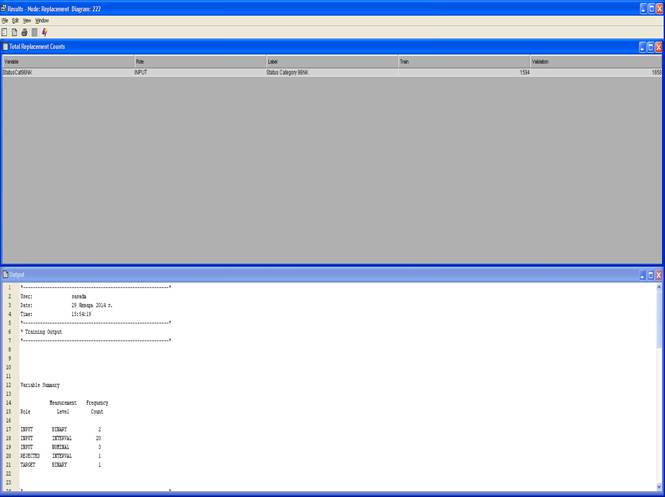
3. Запустить Impute (контекстное меню по элементу и выбрать Run).
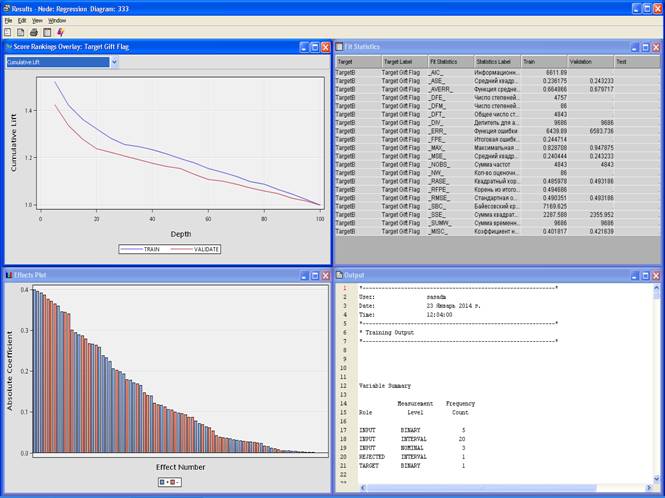
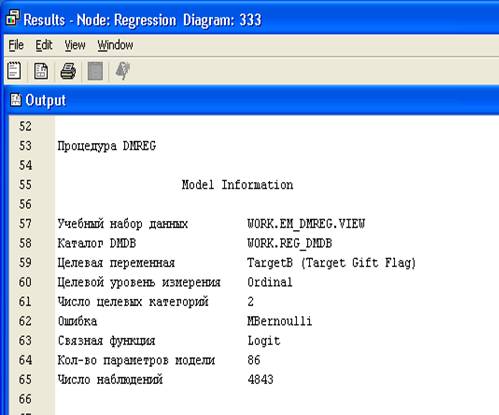
4. Вывести результаты Results.
Окно с результатами.
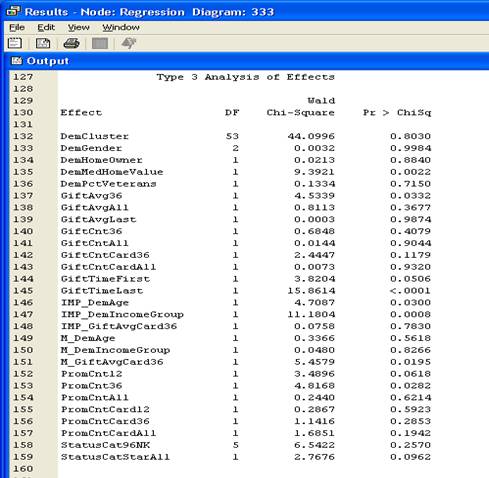
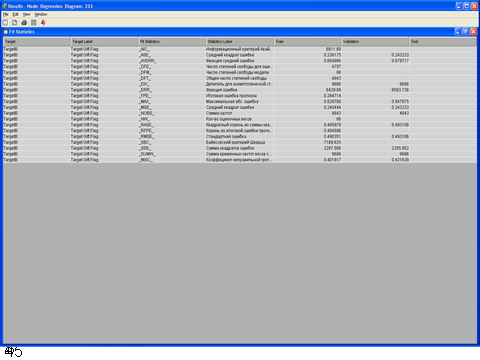
Компонент Regression
1. Выберите вкладку Model.
2. Разместите компонент Regression в рабочей области диаграммы.
3. Соедините узел Impute с узлом Regression.
Регрессия Stepwise
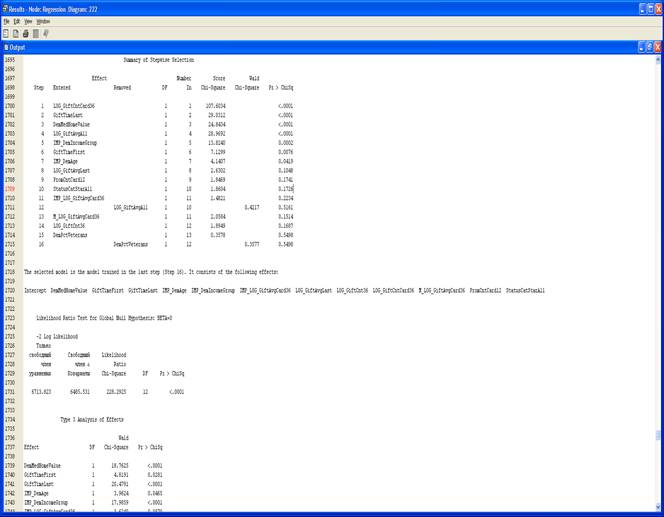
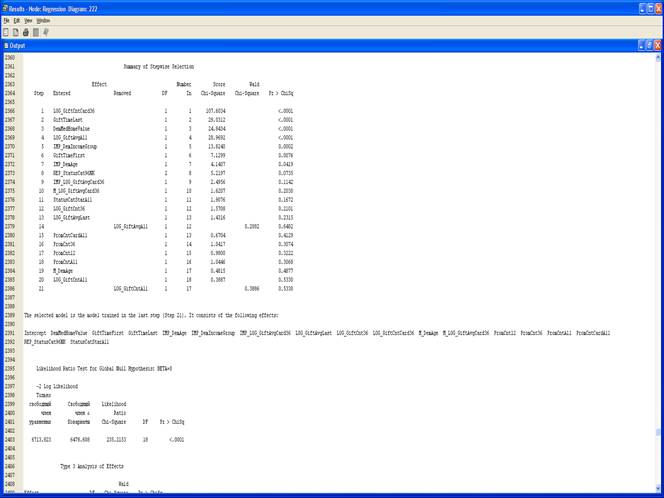
1. Выберите Selection Model => Stepwise в списке свойств узла Regression.
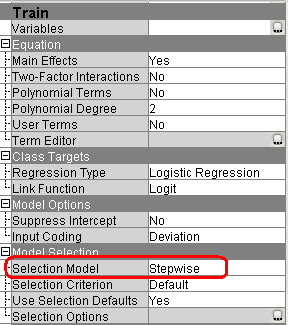
Узел Regression теперь настроен на использование пошагового выбора входных переменных для модели.
2. Выполните узел Regression.
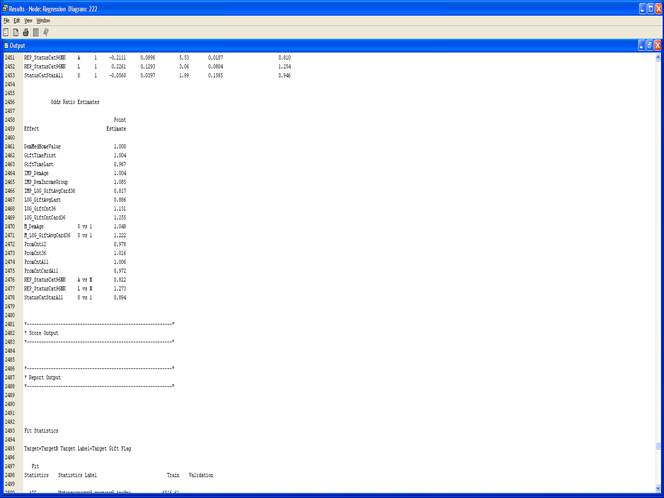
3. Результаты.
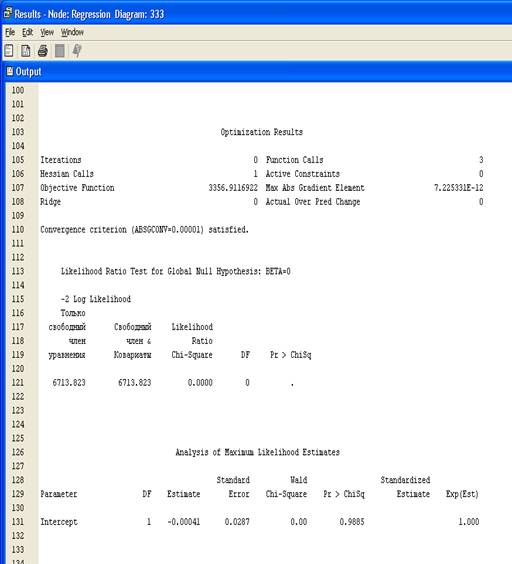
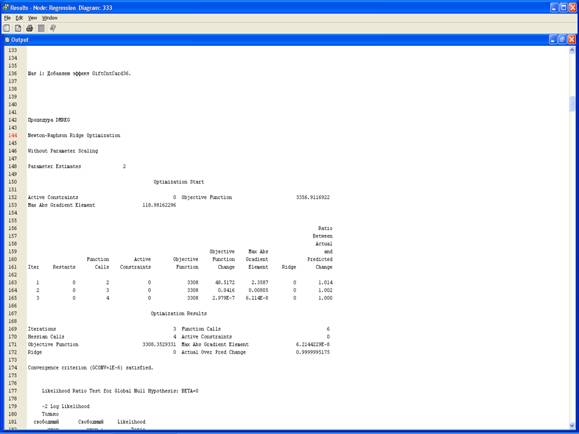
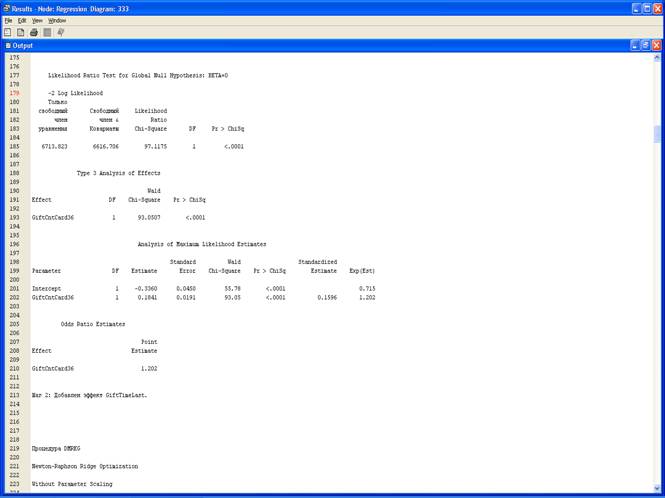
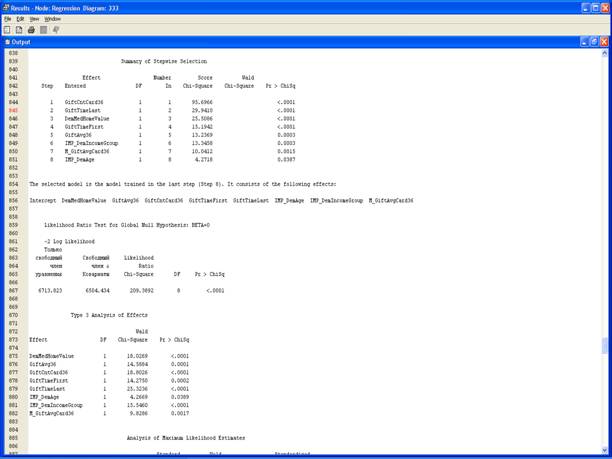
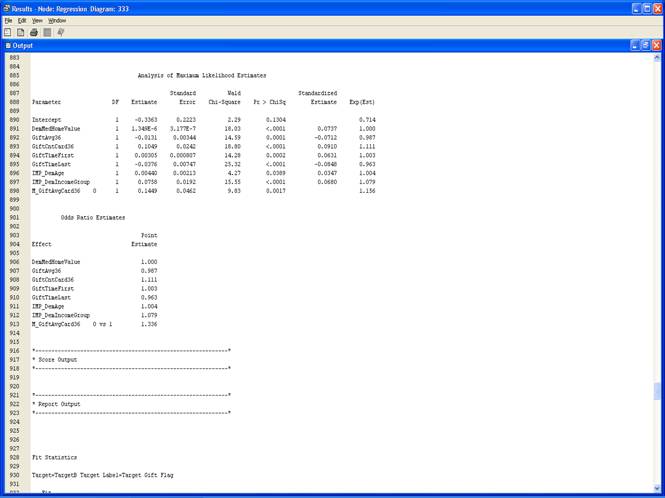
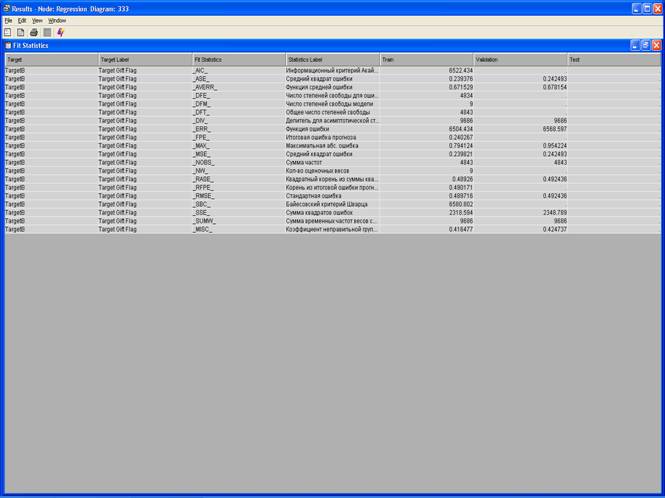
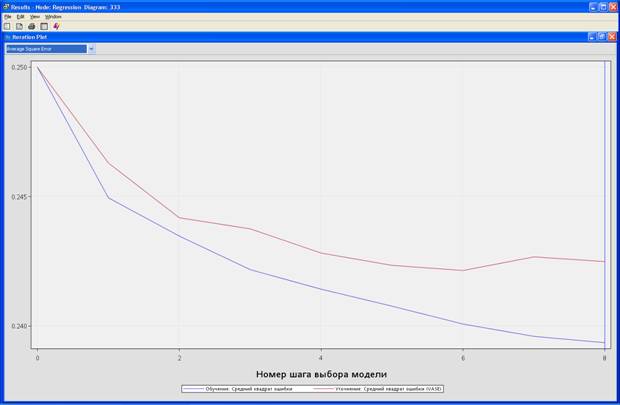
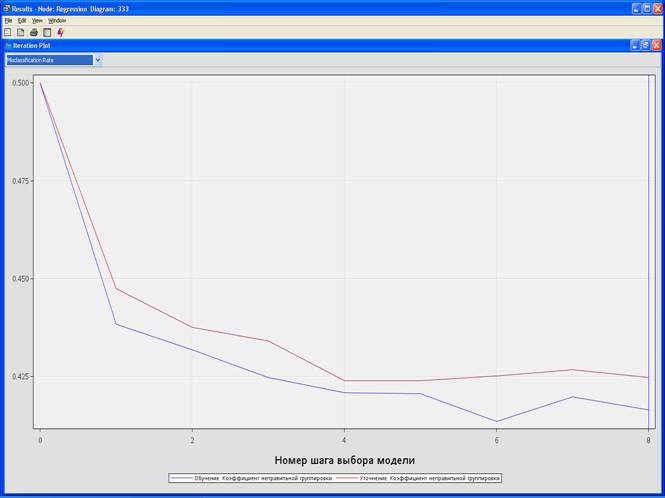
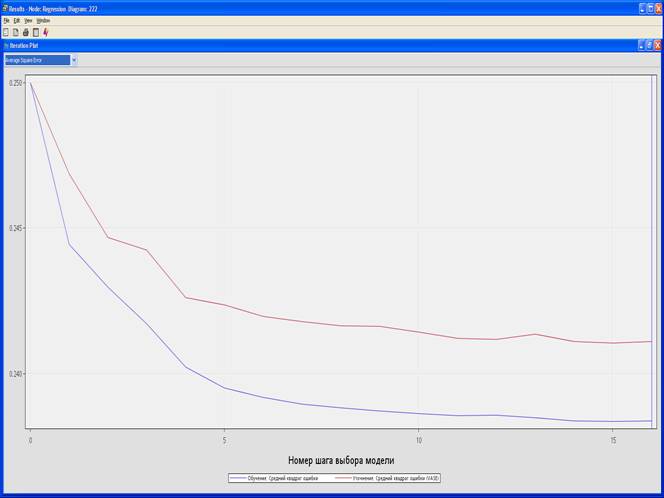
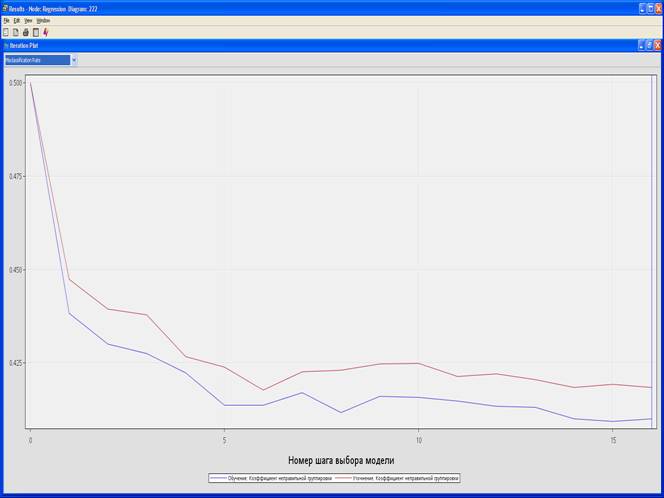
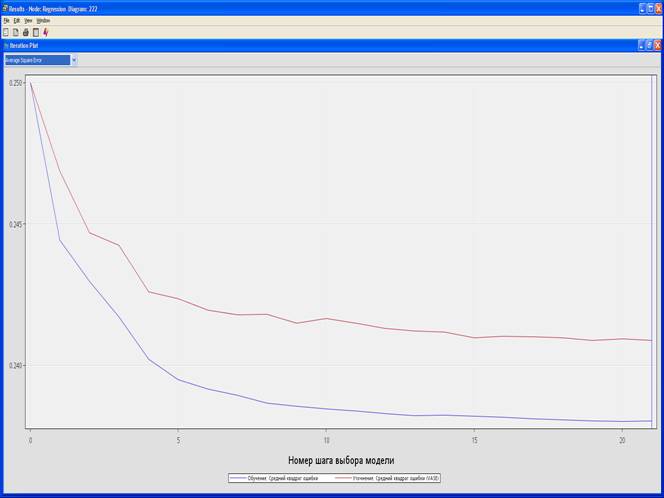
4. Выберите View – Model – Iteration Plot.
Average Square Error
Misclasification Rate
Модели полного перебора
Используйте ниже приведенные шаги для построения и оценки большей последовательности регрессионных моделей.
1. Выберите Use Selection Default => No в панели свойств узла Regression.
2. Выберите Selection Options => ![]()
Откроется окно настроек параметров выбора модели.
3. Введите 1.0 в поле Entry Significance Level.
4. Введите 0.5 в поле Stay Significance Level.
5. Вывести результаты.
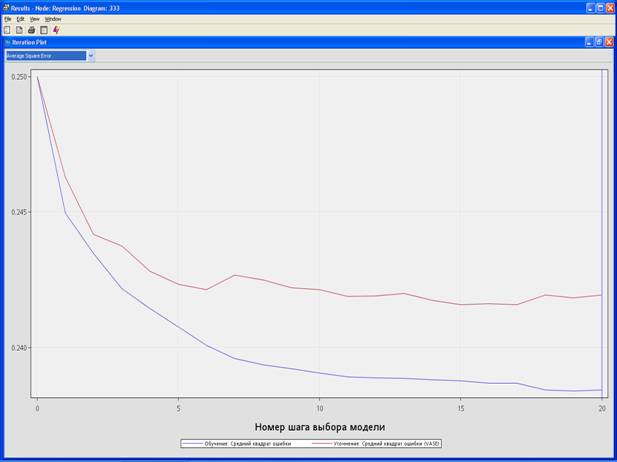
Модель с оптимальной последовательностью
Узел Regression можно настроить на выбор модели с наименьшей статистикой подгонки (а не конечной итерации пошагового выбора). Именно так SAS Enterprise Miner оптимизирует сложность регрессионных моделей.
1. Закройте окно с результатами.
2. Если интересуют прогнозы-оценки или рейтинги, то используют настройку:
Selection Criterion => Validation Error
| В рассматриваемом далее практическом примере использует критерий Validation Error |
3. Выполните узел Regression и просмотрите результаты.
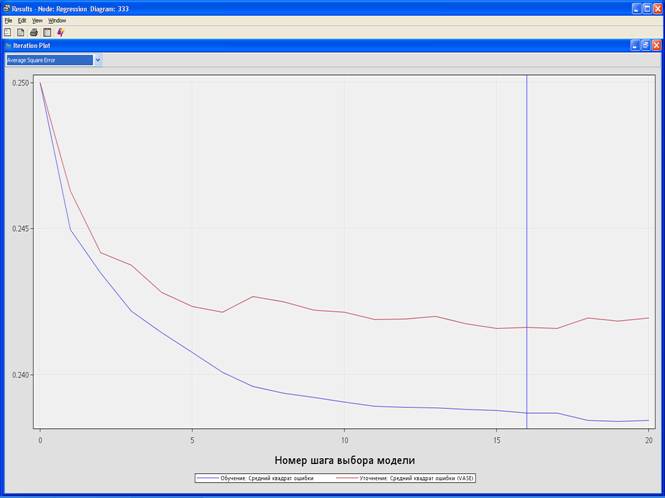
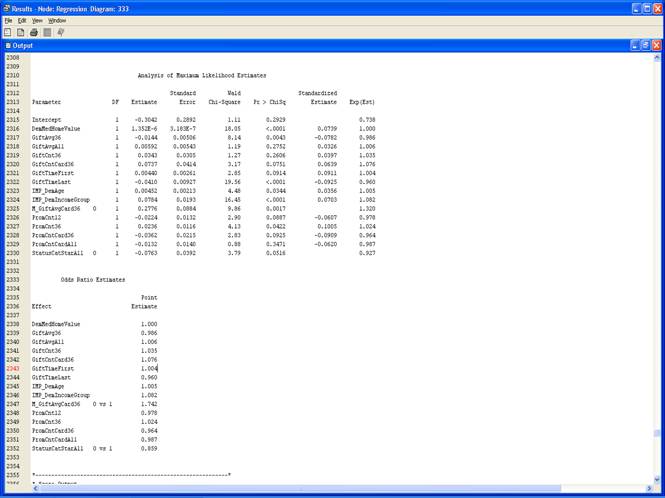
4. Если у вас прогнозы-решения, то используется настройка:
Selection Criterion => Validation Misclassification.
5. Выполните узел Regression и просмотрите результаты.
Компонент Transform Variables
Выполните описанные ниже действия.
1. Удалите связь между узлом Data Partition и Impute.
2. Выберите вкладку Modify.
3. Переместите компонент Transform Variables в рабочую область диаграммы.
4. Соедините узел Data Partition с узлом Transform Variables.
5. Соедините узел Transform Variables с узлом Impute.
6. Отрегулируйте иконки для красоты.
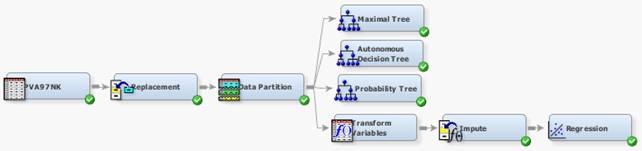
Узел Transform Variables размещается перед Impute для того, чтобы в качестве замещающие значений использовать математическое ожидание (или центр масс) входных переменных.
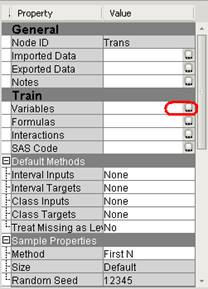
7. Выберите свойство Variables => ![]() узла Transform Variables.
узла Transform Variables.
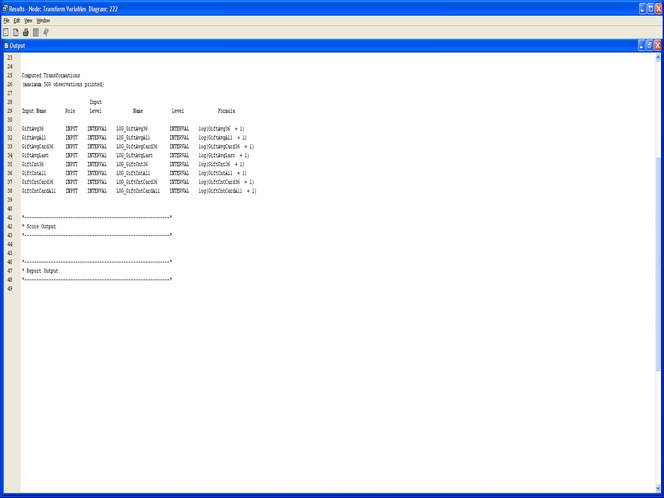
8. Выберите все входные переменные с Gift в названии кроме GiftTime.
9. Выберите Method => Log для выделенных переменных. Для этого достаточно задать соответствующий метод одной из выделенных переменных, а для остальных переменных с GiftAvg и GiftCnt в названии изменится автоматически.
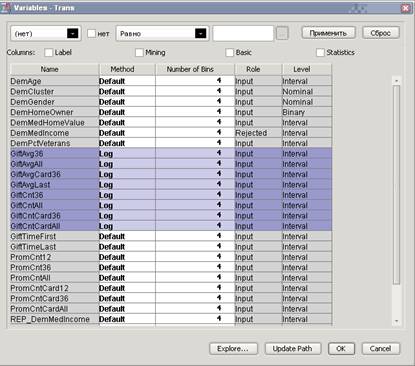
10. Выберите OK чтобы закрыть окно Variables – Trans.
11. Выполните узел Transform Variables и просмотрите результаты.
Перекодирование категориальных входных переменных
Рассмотрим практический пример использования инструмента Replacement для облегчения процесса объединения уровней входных переменных.
1. Удалите связь между узлом Transform Variables и узлом Impute.
2. Выберите вкладку Modify.
3. Разместите узел Replacement в рабочей области диаграммы.
4. Соедините узел Transform Variables с узлом Replacement.
5. Соедините узел Replacement с узлом Impute.
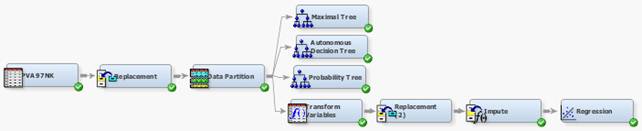
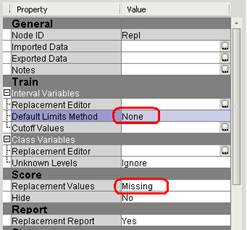
6. На панели настройки свойств узла Replacement выберите:
Default Limits Method => None
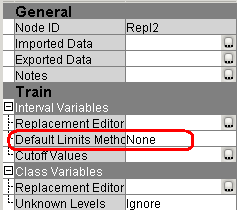
7. На панели настройки свойств узла Replacement в категории Class Variables, выберите Replacement Editor => ![]() .
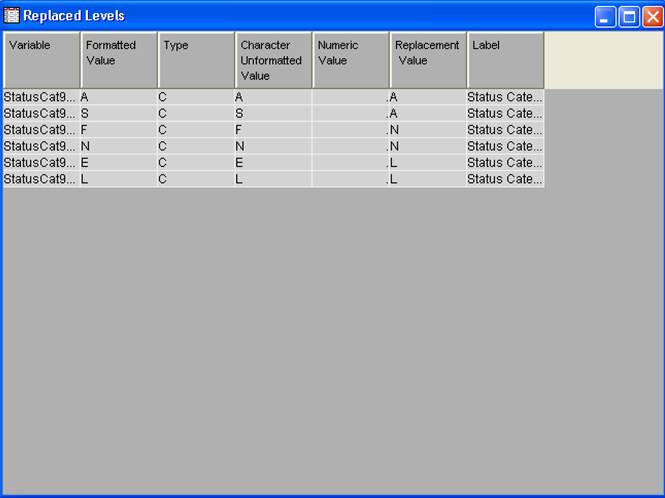
.
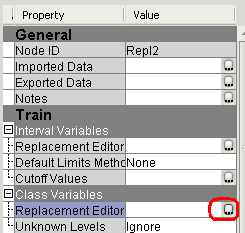
9. Введите A в поле Replacement для уровней StatusCat96NK A и S.
10. Введите N в поле Replacement для уровней StatusCat96NK F и N.
11. Введите L в поле Replacement для уровней StatusCat96NK L и E.
12. Нажмите кнопку OK, чтобы закрыть Replacement Editor.
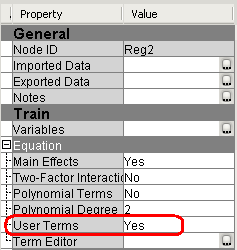
Выборочное добавление членов полиномиальной регрессии
1. Щелкните правой кнопкой по узлу Regression и выберите действие Copy.
2. Щелкните правой кнопкой по рабочей области диаграммы и выберите действие Paste. Новый узел с именем Regression (2) будет добавлен.
3. Выберите узел Regression (2). Заметьте, что его свойства идентичны существующему узлу.
4. Переименуйте новый узел Regression (2) в Polynomial Regression (2). Часть старого имени (2) оставлена специально, чтобы “сразу бросалось в глаза”, что это новая модель.
5. Соедините узел Polynomial Regression (2) с узлом Impute.
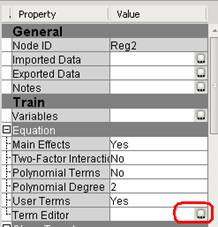
Term Editor позволяет добавлять полиномиальные члены в регрессионную модель. Для того, чтобы воспользоваться Term Editor сначала нужно его сделать активным.
6. Выберите Use Term =>Yes на панели свойств Polynomial Regression (2).
7. Выберите Term Editor … на панели свойств Polynomial Regression (2).
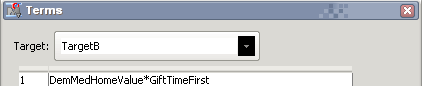
Параболическая зависимость
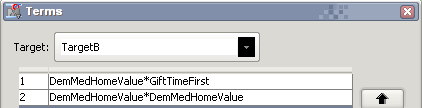
Результатом работы метода пошагового выбора является добавление комбинированного члена на шаге 13 и квадратического на шаге 9.
Автономное добавление членов полиномиальной регрессии
1. Выберите Two-Factor Interaction => Yes.
2. Выберите Polynomial Terms => Yes.
На панели свойств узла Polynomial Regression (2).
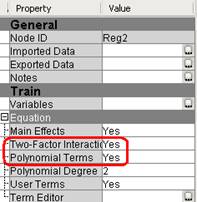
3. Запустите узел Polynomial Regression (2) и просмотрите результаты.
