
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Задачі XIX Міжнародної Олімпіади з інформатики
Задачі XIX Міжнародної Олімпіади з інформатики
частина 1
Гуржій А. М., науковий керівник команди
, керівник команди
Як і минулого року, на двох турах олімпіади учасникам було запропоновано по 3 задачі. Наводимо задачі першого тура олімпіади з описами їх розв’язання.
Прибульці
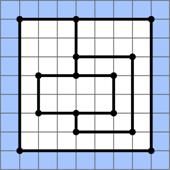
Мирко — великий фанат викошених на полях та лугах кругів і інших геометричних об’єктів за припущенням інопланетного походження. Якось в літню ніч він вирішив викосити свій власний геометричний об’єкт на лугу своєї бабусі. Як великий патріот, Мирко вирішив викосити об’єкт, який буде мати форму щитової частини хорватського герба, котра являє собою шахову дошку розміром 5×5 із 13 червоних квадратів і 12 білих квадратів.
|
Частина герба Хорватії в вигляді шахової дошки. |

Бабусин луг являє собою квадрат, розділений на N×N квадратних клітин однакового розміру. Клітина в лівому нижньому куті мають координати (1, 1), а клітина в правому верхньому куті — координати (N, N).
Мирко вирішив скосити траву тільки на тих клітинах, котрі утворюють на гербі квадрати червоного кольору, і залишити решту трави нескошеною. Він обрав непарне ціле число M ³ 3 і cкосив траву таким чином, що кожен квадрат шахової дошки відповідає M×M клітинам лугу, і шахову дошку цілком розташовано всередині лугу.
|
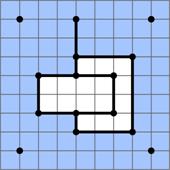
Приклад луга і викошеного Мирко об’єкта. Тут N = 19 і M = 3. Клітини, де траву скошено, показані сірим кольором. Центр об’єкта знаходиться у клітині з координатами (12, 9), відміченій чорною точкою. |

Після того, як Мирко пішов спати, його дивне творіння притягнуло увагу справжніх прибульців! Літаючи над лугом у своєму космічному кораблі, вони досліджують за допомогою простого інопланетного пристрою об’єкт, викошений Мирко. Цей пристрій може тільки визначати, чи скошено траву в деякій клітині чи ні.
Прибульці виявили одну клітину зі скошеною травою і тепер хочуть знайти центральну клітину творіння Мирко, щоб захопитись його красотою. Але вони не знають розмір квадрата M в об’єкті, що викосив Мирко.
ЗАВДАННЯ
Напишіть програму, яка по заданому розміру лугу N (15 ≤ N ≤ 2 000 000 000) і координатам (X0, Y0) однієї з клітин зі скошеною травою знаходить координати центральної клітини викошеного Мирко об’єкта за допомогою спілкування з інопланетним пристроєм.
На кожному тесті пристроєм можна користуватися не більше 300 разів.
Взаємодія
Це інтерактивна задача. Ваша програма посилає команди інопланетному пристрою з використанням стандартного потоку виведення, і отримує відповіді із стандартного потоку введення.
· На початку роботи вашої програми ви повинні прочитати три цілих числа N, X0 і Y0, розділених одиничними пропусками, із стандартного потоку вводу. Число N — це розмір лугу, а (X0, Y0) — це координати однієї клітини зі скошеною травою.
· Щоб перевірити з використанням інопланетного пристрою, чи скошено траву у клітині (X, Y), необхідно вивести в стандартний потік виведення рядок у форматі "examine X Y". Якщо координати (X, Y) не знаходяться всередині лугу (не виконані умови 1 £ X £ N і 1 £ Y £ N), або ви використовуєте пристрій більше 300 разів, ваша програма отримає 0 балів на цьому тесті.
· Інопланетний пристрій буде відповідати одним рядком "true", якщо траву в клітині (X, Y) скошено, в противному випадку він буде відповідати рядком "false".
· Коли ваша програма знайшла центральну клітину, вона повинна вивести рядок вигляду "solution XC YC" в стандартний потік виведення, де (XC, YC) — координати центральної клітини. Виконання вашої програми буде автоматично завершено, як тільки вона виведе розв’язок.
Для того, щоб правильно спілкуватись з пристроєм, ваша програма повинна робити операцію flush зі стандартним потоком виведення після кожної операції запису; вам надано приклад коду, який показує, як це можна зробити.
Приклади коду
Приклади коду на всіх трьох мовах програмування доступні для скачування в розділі “Tasks” на сторінці системи проведення олімпіади. Задача прикладів — показати, як спілкуватись з інопланетним пристроєм; вони не є правильними розв’язками і не набирають повний бал.
Система оцІнЮВАННЯ
В тестах, які будуть в сумі оцінені в 40 балів, розмір M кожного з квадратів Мирко буде не більше 100.
Кожен тест буде мати унікальну правильну відповідь, котрий не залежить від питань, що задані вашою програмою.
Приклад
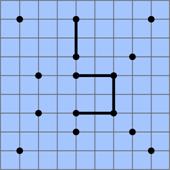
У прикладі команди дані послідовно в лівій колонці. Відповідь інопланетного пристрою надано у правій колонці відповідного рядка.
виведення (команда) | введення (відповідь) |
19 7 4 | |
examine 11 2 | True |
examine 2 5 | false |
examine 9 14 | false |
examine 18 3 | True |
solution 12 9 |
Тестуванння
Під час тура у вас є три способи протестувати ваш розв’язок.
Перший спосіб — моделювати інопланетний пристрій вручну, спілкуючись зі своєю програмою.
Другий спосіб — написати програму, яка буде моделювати інопланетний пристрій. Щоб зв’язати вашу програму-розв’язок з програмою-симулятором пристрою, ви можете використовувати службову програму, котра називається "connect", її можна скачати з системи проведення олімпіади. Щоб запустити програму, використовуйте команду "./connect./solution./device" у консолі (замість "solution" і "device" треба підставити імена відповідних ваших програм). Всі додаткові параметри командного рядка будуть передані вашій програмі-симулятору.
Третій спосіб — використовувати розділ TEST системи проведення олімпіади, щоб автоматично запустити вашу програму на вашому тесті. При використанні цього способу максимальне значення розміру лугу N дорівнює 100.
Тест має містити три рядка:
· Перший рядок має містити розмір лугу N і розмір квадрата шахової дошки M;
· Другий рядок має містити координати X0 і Y0 однієї з клітин лугу, на котрій скошено траву, вони будуть передані вашій програмі;
· Третій рядок має містити координати XC і YC центра шахової дошки.
Тестуюча система видасть вам детальний звіт про виконання. При цьому ви отримаєте відповідне повідомлення про помилку якщо:
· N не задовольняє обмеженням;
· M не є непарним цілим числом, більшим або рівним 3;
· Об’єкт не лежить на лугу цілком;
· Траву в клітині (X0, Y0) не скошено.
Нижче наведено приклад коректного тестового файлу для тестуючої системи. Приклад відповідає малюнку на першій сторінці.
19 3 7 4 12 9 |
Коректний вхідной файл для тестуючої системи. |
розв’язок
Будемо використовувати терміни червона клітина та червоний квадрат для клітин та квадратів зі скошеною травою. Інші клітини та квадрати - білі. Використання інопланетного пристрою для деяких координат тепер є еквівалентним перевірці кольору клітини.
Процес пошуку розв’язку складається з двох етапів. На першому етапі визначається довжина M сторони квадрату шахової дошки та центр (XC, YC) та центр червоного квадрату F, що містить задану червону клітину (X0, Y0). На другому етапі виконується переміщення з (XC, YC) до центру всього утворення (використовуючи здвиги довжини M чи 2M по кожній з координат).
Найважливішою частиною цієї задачі є ефективність першого етапу. Щоб знайти M, ми повинні знайти:
· XR – саму праву x-координату клітини з F,
· XL – саму ліву x-координату клітини з F, та
· YB – саму нижню y-координату клітини з F.
Опишемо декілька підходів до знаходження XR; їх можна тривіально адаптувати для знаходження XL та YB.
Самим простим алгоритмом є перевірка кольору клітин (X0+1, Y0), (X0+2, Y0), (X0+3, Y0) і так далі, доки не знайдено першу білу клітину (XR+1, Y0), з використанням M запитів у найгіршому випадку. Цей підхід набере 40 балів.
Щоб зменшити кількість запитів, будемо натомість перевіряти колір клітин (X0+1, Y0), (X0+2, Y0), (X0+4, Y0),..., (X0+2k, Y0), ..., зупинившись на клітині, яку назвемо Clast. Це перша біла клітина в послідовності або перша клітина послідовності за межами лугу (треба бути обережним, щоб не зробити запит до пристрою у цьому випадку). Можна довести, що червоні клітини зліва від Clast мають належати до квадрата F а не до якогось іншого квадрата. Нехай Cprevious буде самою правою знайденою червоною клітиною зліва від Clast. До цього було використано не більше log2 M запитів.
Тепер можна встановити X0 = Cprevious та повторити описану вище процедуру, доки [Cprevious, Clast] не буде містити тільки 2 клітини, після чого Cprevious = (XR, Y0). Але ми використали (log2 M) 2 запитів у найгіршому випадку, що достатньо для отримання тільки 70 балів.
Щоб набрати повний бал, використаємо бінарний пошук в сегменті [Cprevious, Clast] щоб знайти XR: (XR, Y0) є єдиною червоною клітиною в сегменті, що має сусідню білу клітину праворуч. Використовуючи цей алгоритм ми можемо знайти XR, XL та YB з використанням щонайбільше 6 log2 M запитів. Тепер, M=XR−XL+1, XC=XL+(M−1)/2, YC=YB+(M−1)/2.
Так виглядає перший етап розв’язання задачі.
Другий етап використовує інопланетний пристрій тільки декілька разів, щоб визначити, які з 13 можливих клітин мають центром (XC, YC). Достатньо перевірити колір декількох клітин що мають x-координати XC, XC±M, XC±2M та y-координати YC, YC±M, YC±2M.
повінь
У 1964 році катастрофічна повінь потрясло Загреб. Багато будівель було зруйновано водою, що вдарила по їх стінам. В цій задачі вам буде надано спрощену модель міста перед повінню, і ви маєте визначити, які з стін залишаться цілими після повені.
Модель складається з N точок на координатній площині і W стін. Кожна стіна з’єднує пару точок і не проходить через інші точки. Модель також задовольняє наступним властивостям:
· Ніякі дві стіни не перетинаються і не накладаються одна на іншу, за виключенням того, що вони можуть мати спільні кінці;
· Кожна стіна є паралельною чи до горизонтальної, чи до вертикальної координатної вісі.
На початку вся координатна площина є сухою. В момент часу нуль вода миттєво затоплює зовнішній простір (простір, не обмежений стінами). Рівно через годину кожна стіна, у якої з одного боку — вода, а з іншого боку — повітря, руйнується під тиском води. Після цього вода миттєво затоплює простір, який перестав бути обмеженим цілими стінами. В результаті цього можуть з’явитися нові стіни, у яких з одного боку вода, а з другого боку — повітря. Ще через годину ці стіни також руйнуються, і вода потрапляє у новий простір. Так продовжується до тих пір, поки вода не затопить всю територію.
Приклад процесу руйнування показано на наступному рисунку.
|
|
|
Стан в момент часу нуль. Затінені клітини зображають затоплену територію, а білі клітини — суху територию (повітря). | Стан через одну годину. | Стан через дві години. Вода затопила всю територію, цілими залишилися чотири стіни, які у подальшому не можуть бути зруйновані. |
ЗаВДАННЯ
Напишіть програму, яка по заданим координатам N точок і опису W стін, що з’єднують ці точки, визначає, які стіни залишаться цілими після повені.
Вхідні дані
Перший рядок вхідних даних містить ціле число N (2 ≤ N ≤ 100 000), кількість точок на площині. Кожен з наступних N рядків містить по два цілих числа X і Y (кожне від 0 до 1 000 000 включно) — координати точки. Точки нумеруються від 1 до N в тому порядку, в якому вони задані. Ніякі дві точки не співпадають.
Наступний рядок містить ціле число W (1 ≤ W ≤ 2N), кількість стін.
Кожна з наступних W рядків містить по два різних цілих числа A і B (1 ≤ A ≤ N, 1 ≤ B ≤ N), які означають, що перед повінню існувала стіна, що з’єднувала точки A і B. Стіни нумеруються від 1 до W в тому порядку, в якому вони задані.
Выходные данные
Перший рядок вихідних даних має містити ціле число K — кількість стін, які залишаться цілими після повені.
Наступні K рядків мають містити номери стін, які залишаться цілими, по одному номеру в кожному рядку. Номери стін можна виводити у довільному порядку.
Система оцінювання
В тестах, які будуть в сумі оцінені в 40 балів, всі координати не будуть перевищувати 500. У всих цих тестах, а також в тестах, що будуть оцінені ще в 15 балів, кількість точок не буде перевищувати 500.
Детальний відгук системы що тестує
на відісланий роз’язок
Під час туру ви можете обрати до 10 відсилань по цій задачі, які будуть перевірені (по можливості так швидко, як це можливо) на частині офіціальних тестів. Після того, як перевірку буде виконано, зведення результатів тестування буде доступне вам через систему проведення олімпіади.
ПРИКЛАД
Вхідні дані 15 1 1 8 1 4 2 7 2 2 3 4 3 6 3 2 5 4 5 6 5 4 6 7 6 1 8 4 8 8 8 17 1 2 2 15 15 14 14 13 13 1 14 11 11 12 12 4 4 3 3 6 6 5 5 8 8 9 9 11 9 10 10 7 7 6 | Вихідні дані 4 6 15 16 17 Цей приклад відповідяє малюнку з умови. |
розв’язок
· Моделювання
Простим розв’язком є " намалювати " стіни у двовимірному масиві і використати алгоритм 0-1 пошуку в ширину (починаючи з довільної зовнішньої клітини) щоб обчислити час заповнення кожної клітини. Стіна залишиться стояти після повені якщо час заповнення клітин з обох її боків є однаковимl.
Алгоритм 0-1 пошуку в ширину використовується для знаходження найкоротшого шляху в графах, в яких вага ребер є тільки 0 або 1 (використовуючи чергу та вставляючи елементи в її початок при проходженні через 0-ребро). В нашій моделі, кожна пара двох сусідніх клітин з’єднується ребром, вага ребра є 1 якщо є стіна між клітинами, 0 інакше.
Оскільки розмір графа залежить від координат точок, кількість клітин що мають бути розглянуті є в загальному випадку дуже великою. Цей розв’язок набере приблизно 40 балів.
· Моделювання з утисканням координат
Щоб покращити наведений алгоритм, можна помітити, що фактичні координати точок є не суттєвими – тільки відносний порядок точок має значення для визначення стін, що залишаться після повені. Тому, якщо координата x приймає A різних значень та координата y приймає B різних значень, ми можемо відобразити їх на множини {1, 2, ..., A} та {1, 2, ..., B} відповідно. Кількість клітин, що потрібно переглянути тепер буде O(A. B).
Оскільки A і B обмежені N (кількість точок), цей підхід має загальну складність O(N2). Цей розв’язок отримає приблизно 55 балів.
· Гарний розв’язок (дуальний граф)
Представимо кожну область (максимальний набір нерозділених стінами клітин) вершинною графа, та додамо ребра між парами вершин якщо відповідні області мають спільну стіну. Також добавимо вершину, що буде відповідати зовнішній області та з’єднаємо її ребрами з областями, що одразу затоплюються водою.
Зауважимо, що нам не потрібно знаходити точний час затоплення для кожної області – нам тільки потрібно знати чи є дві області, що мають спільну стіну, рівновіддаленими від зовнішньої області, чи ні.
Виконання простого алгоритму пошуку в ширину починаючи з зовнішньої області на описаному графі дає достатньо інформації для розв’язання задачі. Найскладнішою частиною є побудова графа.
Однією з можливих стратегій є уявити кожну стіну як дві односторонні дороги (з протилежними напрямками руху), взяти довільну дорогу і рухатись по ній, повертаючи направо на кожному перехресті – якщо можемо повернути праворуч, то повернути, інакше якщо можна рухатись прямо, то рухатись прямо, інакше рухатись наліво якщо можливо, інакше рухатись назад. Для кожної початкової дороги ми зробимо один круг навкруги однієї області за прийдемо туди, звідки почали. Послідовно обираючи нові дороги та проходячи їх, ми знайдемо всі області. Один прохід дасть зовнішню область. Якщо для певної стіни дві дороги генерують різні області, з’єднаємо ці області ребром.
Наведений алгоритм може бути реалізований зі складністю O(N+W).
· Інший гарний розв’язок (Прохід по зовнішнім стінам)
Інший, трохи відмінний підхід до задачі є постійно проходити навколо компонентів та з’ясовувати, які з зовнішніх стін будуте зруйновано. Почнемо з самої лівої зовнішньої стіни. Тепер уявно покладемо праву руку на стіну і будемо іти навколо стін тримаючи на них руку доки не прийдемо в початкову точку. Зрозуміло, що із усіх точок, що ми торкнулися, залишаться лише ті, що ми торкнулися з двох боків. Потім, видалимо всі стіни, що ми торкнулися та повторимо процес доки всі стіни не будуть видалені. Цей алгоритм можна реалізувати з часом O(N log N + W) та він також отримає повний бал.
Вітрила
Будується новий піратський вітрильник. У вітрильника є N щогл, які розділені на одиничні відрізки, при цьому висота щогли дорівнює кількості відрізків. На кожній щоглі розміщено деяку кількість вітрил, кожне з яких займає один відрізок. Вітрила на щоглі можуть бути розташовані довільним чином по відрізках, але у кожному відрізку може бути розташовано тільки одне вітрило.
Різні розташування вітрил забезпечують різну тягу, коли на них дує вітер. Вітрило, коли знаходиться перед іншими вітрилами на тій самій висоті, отримує менше вітру і дає менше тяги. Для кожного вітрила визначимо показник його неефективності як сумарну кількість вітрил, що розташовано за цим вітрилом на тій же висоті. Зверніть увагу, що «перед» і «за» визначаються відносно розташування корабля: на малюнку «перед» означає зліва, «за» — справа.
Загальний показник неефективності розміщення вітрил — це сума показників неефективності кожного з парусів.
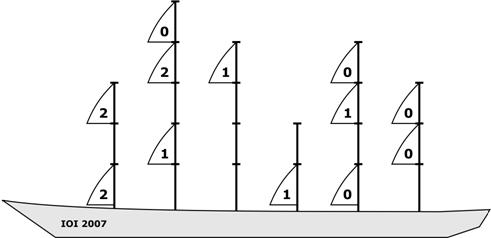
ніс |
| корма |
У цього вітрильника 6 щогл, висотою 3, 5, 4, 2, 4 і 3 від носа (лівий бік рисунка) до кормы. |
ЗаВДАННЯ
Напишіть програму, яка по заданій висоті і кількості вітрил на кожній з N щогл визначає найменший можливий загальний показник неефективності.
Вхідні дані
Перший рядок вхідних даних містить ціле число N (2 ≤ N ≤ , кількість щогл у корабля.
Кожен з наступних N рядків містить по два цілих числа H і K (1 ≤ H ≤ , 1 ≤ K ≤ H), висоту відповідної щогли і кількість парусів на ній. Щогли задані у порядку від носа до корми корабля.
Вихідні дані
Вивід має складатись з одного цілого числа — мінімально можливого загального показника неефективності.
Зауваження: використовуйте 64-бітный цілий тип для обчислення і виводу результату (long long в C/C++ і int64 в Pascal).
Система ОцІнки
В тестах, які будуть в сумі оцінені в 25 балів, загальна кількість способів розташування парусів по відрізках буде не більше 1 000 000.
ПРИклад
Вхідні дані 6 Вихідні дані 10 Цей приклад відповідає рисунку з умови. |
РОЗВ’язок
Кожен відрізок розташовано на певному рівні – щогла висоти H має відрізки на рівнях від 1 до H. Зауважимо, що порядок щогл не є важливим при підрахунку загальної неефективності, фінальний результат залежить тільки від кількості вітрил на кожному рівні.
Припустимо що щогли відсортовані у зростаючому порядку за висотою. Розглянемо наступний жадний алгоритм:
· Обробляти щогли зліва направо, зберігаючи загальну кількість вітрил на кожному з рівнів.
· Для кожної нової щогли висоти H з K вітрилами робити наступне: з H поточних рівнів обрати K рівнів з найменшим числом вітрил та помістити туди нові вітрила.
· Просумувати значення SX ・ (SX−1) / 2 для кожного рівня X, де SX є кількістю вітрил розташованих на рівні X. Видати суму як результат.
Ми уникнемо повного доведення коректності алгоритму. Інтуїтивно, нашою метою є утримувати кількість вітрил на різних рівнях якомога більш близькими між собою, тому має сенс розташовувати нові вітрила на рівнях з найменшою поточною кількістю вітрил.
Щоб отримати формальне доведення, покажемо що інші розташування не є не кращими ніж створене цім алгоритмом. Припустимо що A та B є різними рівнями, такими що кількість вітрил на рівні A до сих пір менша ніж кількість вітрил на рівні B, та доведемо що довільна конфігурація C, яка розташує вітрило на B а не на A може бути трансформована в конфігурацію C’ яка робить супротивне та має меншу або рівну неефективність.
Неефективний розв’язок
Хоча алгоритм концептуально простий, не так просто знайти ефективну його реалізацію для даних вхідних обмежень.
Наведений алгоритм можна прямо промоделювати. Ми можемо явно підтримувати загальну кількість вітрил для кожного рівня та обновлювати її на кожному кроці. Якщо використовувати масив, отримаємо алгоритм складності O(загальна_кількість_вітрил ・ максимальна_висота). Такий розв’язок отримає приблизно 30 балів.
Помітимо, що оскільки щогли відсортовані по висоті, ми можемо тільки підтримувати кількості вітрил та ігнорувати рівні, на яких їх було отримано (тобто ми можемо підтримувати гістограму сортованою). Отже, можна використовувати чергу з пріоритетами для підтримки гістограми та ефективно знаходити K найменших кількостей вітрил на кожному кроці. Цей підхід можна реалізувати з часом O(загальна_кількість_вітрил・ log(максимальна_висота)). Такий розв’язок отримає 40 балів.
Підтримка гістограми в сортованому масиві дає інший розв’язок. На кожному кроці ми можемо знайти K найменших кількостей вітрил та модифікувати гістограму за один раз. Ми тільки маємо бути певні що серед рівнів з однаковою кількістю вітрил ми модифікуємо спочатку ті рівні, які знаходяться ближче до рівнів з більшою кількістю вітрил. Цей підхід може бути реалізований з часом O(N ・ максимальна_висота). Такі розв’язки отримували 50 балів.
· Оптимальний розв’язок
Оптимальний розв’язок також використовує ідею що гістограма може зберігатися сортованою, але, замість зберігання кількостей вітрил, підтримується тільки різниці в кількості між сусідніми кількостями вітрил. Наприклад, якщо в поточному стані висота - 6 та кількості вітрил - 5, 3, 3, 3, 2 та 2, масивом різностей (delta) буде 5, -2, 0, 0, -1, 0 та -2.
Основою розв’язку є функція, яка перетворює масив різностей коли ми оброблюємо нові щогли. Коли обробляється нова щогла висоти H з K вітрилами, ми спочатку додаємо нові елементи у кінець масиву різниць(що відповідають верхнім рівням яки на початку пусті), а потім додаємо одне вітрило на кожен з нижніх K рівнів.
Щоб додати одне вітрило на кожен рівень з інтервалу [A, B], у більшості випадків достатньо збільшити delta[A] та зменшити delta[B]. Коли delta[A] дорівнює нулю (тобто коли ліва частина інтервалу знаходиться в середині групи однакових кількостей вітрил), тоді процедура призводить до масиву, я кий не є відсортованим. Однак, коли delta[A] не є нулем, описана процедура призводить до масиву різностей що відповідає відсортованому масиву.
Нехай групою рівнів буде група рівнів з однаковою кількістю вітрил. Помітимо, що група рівнів може бути ідентифікованою в масиві різностей як послідовність нулів обмежена ненульовими значеннями. Іншими словами, щоб ідентифікувати групу рівнів що містить рівень H потрібно знайти перше ненульове значення в послідовності різниць перед та після H.
Коли модифікується нижні K рівнів (інтервал [H−K+1, H]), розв’язок працює так:
Якщо ліва границя інтервалу (H−K+1) знаходиться всередині групи рівнів [A, B], тоді модифікувати інтервали [A, A+B−H+K−1] та [B+1, H]. Іншими словами ми підтримаємо масив сортованим зсуваючи нові вітрила з правого боку групи інтервалів до лівого боку.
Інакше, модифікуємо інтервал [H−K+1, H].
Для того, щоб отримати ефективний розв’язок потрібно мати можливість швидко знаходити групу рівнів, що відповідає певному рівню. Існують декілька методів, що базуються на цій або схожих ідеях, які набирають від 70 до 100 балів, в залежності від ефективності структурі даних, що використовується для пошуку групи рівнів.
Оптимальний розв’язок використовує структуру дерева інтервалів для виконання запитів. Обробка однієї щогли потребує часу O(log(H)), де H – висота щогли. Таким чином, загальна складність розв’язку є O(N ・ log(максимальна_висота)).
Задачі XIX Міжнародної Олімпіади з інформатики
частина 2
Гуржій А. М., науковий керівник команди
, керівник команди
Другий тур олімпіади виявився складнішим за перший, менш всього учасників впоралося з третьою задачею. Задачі були такі.
ШахтАРІ
Є два рудника, в кожному з яких працює по групі шахтарів. Видобування вугілля — важка робота, тому для її виконання шахтарям потрібна їжа. Кожен раз, коли контейнер з їжею привозять до рудника, шахтарі видобувають деяку кількість вугілля. Існує три типа контейнерів: контейнер з м’ясом, контейнер з рибою і контейнер з хлібом.
Шахтарі люблять різноманітність у раціоні, і їх робота буде більш продуктивною, якщо їжа різноманітна. В момент надходження чергового контейнера з їжею у один з рудників, в залежності від типів контейнера, що надійшов, і попередніх двох (або меншої кількості, якщо всього в цей рудник надійшло менше трьох контейнерів) шахтарі цього рудника приймають одне з наступних рішень:
· Якщо всі розглянуті контейнери були одного типа, то шахтарі видобувають одну одиницю вугілля.
· Якщо розглянуті контейнери були двох різних типів, то шахтарі видобувають дві одиниці вугілля.
· Якщо розглянуті контейнери були всіх трьох різних типів, то шахтарі видобувають три одиниці вугілля.
Відомо, контейнери яких типів будуть відправлені і в якому порядку. Можна впливати на кількість вугілля, що видобувається, відповідним чином визначаючи, в який з рудників буде відправлено черговий контейнер. Контейнери неможна розділяти на частини, кожен контейнер має бути цілком відправлений до одного з рудників.
Зовсім не обов’язково, щоб в обидва рудники надійшла однакова кількість контейнерів (наприклад, дозволяється відправляти всі контейнери в один рудник).
ЗаВДАННЯ
Вашій програмі будуть надані типи контейнерів в тому порядку, у якому вони будуть відправлені. Напишіть програму, яка визначає максимальну сумарну кількість вугілля, яку можна видобути (на обох рудниках), розподіляючи, які контейнери необхідно відправити в перший, а які — у другий.
ВХіДНі ДАНі
Перший рядок вхідних даних містить ціле число N (1 ≤ N ≤ 100 000), кількість контейнерів.
Другий рядок містить рядок з N символів — типи контейнерів в том порядку, в якому вони будуть відправлені. Кожен з цих символів може бути однією з заглавних букв ‘M’ (м’ясо), ‘F’ (риба) або ‘B’ (хліб).
Вихідні дані
Виведіть ціле число — максимальну сумарну кількість вугілля, котру можна видобути.
сИСТЕМА ОЦіНКИ
В тестах, які будуть в сумі оцінені в 45 балів, кількість контейнерів N не буде перевищувати 20.
Детальний відгук системы що тестує
на відісланий роз’язок
Під час туру ви можете обрати до 10 відсилань по цій задачі, які будуть перевірені (по можливості так швидко, як це можливо) на частині офіціальних тестів. Після того, як перевірку буде виконано, зведення результатів тестування буде доступне вам через систему проведення олімпіади.
ПриКЛАДИ
вхідні дані 6 MBMFFB вихідні дані 12 | вхідні дані 16 MMBMBBBBMMMMMBMB вихідні дані 29 |
В прикладі зліва можна, наприклад, розподілити контейнери таким чином: рудник 1, рудник 1, рудник 2, рудник 2, рудник 1, рудник 2, в цьому випадку шахтарі видобудуть 1, 2, 1, 2, 3 і 3 одиниці вугілля (в цьому порядку), всього 12 одиниць вугілля. Існують і інші способи добитися максимальної кількості вугілля.
розв’язок
Задача розв’язується з використанням динамічного програмування. Нехай M(n, стан1, стан2) буде найбільшою кількістю вугілля що може бути вироблено після n-1 відправок їжі, стан1 описує які контейнери вже було відправлено до шахти 1, та стан2 описує які контейнери вже було відправлено до шахти 2. Далі, нехай value(a, b) позначає кількість видобутого вугілля якщо контейнер типу b прибуває в шахту в стані a. Виконується наступна формула:
M(n, state1, state2) = max {
M(n+1, newstate1, state2) + value(state1, тип контейнеру n),
M(n+1, state1, newstate2) + value(state2, тип контейнеру n)
}
Можна реалізувати просту рекурсію, що базується на наведеній формулі (обчислити M(0, пусто, пусто)). Такий алгоритм має складність O(2N) та набере 45 балів.
Зауважимо, що для обчислення значення M, достатньо описати стан шахти тільки останніми двома відправленнями. Це викликано тим, що довільне відправлення, крім останніх двох, не впливає на кількість видобутого вугілля. Загальна кількість різних станів зменшується до всього 3*3+1=10 на шахту (3 три типи контейнерів в останніх двох відсилках, та спеціальний стан, що описує пусту шахту).
Цей факт дозволяє суттєво зменшити кількість конфігурацій: N контейнерів × 10 станів (для першої шахти) × 10 станів (для другої шахти). Для кожної конфігурації ми можемо підрахувати об’єм для неї та зберегти цю кількість для повторного використання.
Але, для такого великого N як , треба використовувати багато пам’яті (100N цілих) для зберігання кількостей для конфігурацій, що перевищує обмеження на пам’ять. Такий розв’язок набере від 70 до 85 балів.
Щоб набрати повний бал треба використати той факт, що коли обчислюється M(n, *, *), то використовується тільки M(n+1, *, *). Якщо ми обчислюємо M за зменшенням n, нам потрібно зберігати тільки 2・100 цілих чисел.
Пари
Мирко и Славко грають з іграшковими звірятами. Спочатку вони обирають одну з трьох можливих дошок для гри, які показано на малюнку нижче. Кожна дошка складається з клітин (показаних нижче кружками), організованих в одно-, дво - або тривимірну решітку.
|
|
|
Дошка типу 1 | Дошка типу 2 | Дошка типу 3 |
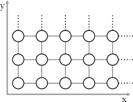
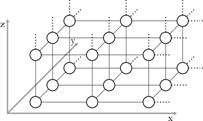
Потім Мирко розташовує N звірят по клітинам.
Відстань між двома клітинами — це мінімальна кількість кроків, яку треба зробити звірятку, щоб переміститися с однієї клітини в іншу. За один крок звірятко може переміститься в довільну з сусідніх клітин (на малюнку сусідні клітини з’єднані відрізками).
Двоє звірят можуть чути один одного, якщо відстань між їх клітинами не перевищує число D. Задача Славка — підрахувати кількість пар звірят, які можуть чути один одного.
ЗАВДАННЯ
Напишіть програму, яка по заданому типу дошки, розташуванню всіх звірят на ній і числу D знаходить потрібну кількість пар звірят.
ВхІдні дані
Перший рядок вхідних даних містить чотири цілих числа у наступному порядку:
· Тип дошки B (1 ≤ B ≤ 3);
· Кількість звірят N (1 ≤ N ≤ 100 000);
· Максимальну відстань D, на якій двоє звірят можуть чути один одного(1 ≤ D ≤ 100 000 000);
· Розмір дошки M (максимальна координата, яка може зустрітися у вхідних даних):
§ Якщо B=1, то M не буде перевищувати 75 000 000.
§ Якщо B=2, то M не буде перевищувати 75 000.
§ Якщо B=3, то M не буде перевищувати 75.
Кожен з наступних N рядків містить по B цілих чисел, розділених одиничними пропусками — координати відповідного звірятка. Кожна координата знаходиться у діапазоні від 1 до M, включно.
В одній клітині може розташовуватись більше одного звірятка.
Виходні дані
Вихідні дані мають складатись з єдиного цілого числа — кількості пар звірят, які можуть чути один одного.
Зауваження: використовуйте 64-бітний цілий тип для обчислення і виведення результату (long long в C/C++ і int64 в Pascal).
Система оцінки
В тестах, яків будуть в сумі оцінюватись в 30 балів, кількість звірят N не буде перевищувати 1 000.
Більш того, для кожного з трьох типів дошки, розв’язок, який видає правильну відповідь на тестах з цим типом дошки, буде оцінено не менш ніж у 30 балів.
Приклади
вхідні дані
25 50 50 10 20 23 вихідні дані 4 | вхідні дані
5 2 7 2 8 4 6 5 4 4 вихідні дані 8 | вхідні дані
10 10 10 10 10 20 10 20 10 10 20 20 20 10 10 20 10 20 20 20 10 20 20 20 вихідні дані 12 |
Пояснення до прикладу зліва: нехай звірят пронумеровано від 1 до 6 в том порядку, в якому вони задані. Тоді наступні чотири пари звірят можуть чути один іншого:
· 1-5 (відстань 5)
· 1-6 (відстань 2)
· 2-3 (відстань 0)
· 5-6 (відстань 3)
Пояснення до прикладу посередині: наступні вісім пар звірят можуть чути один одного:
· 1-2 (відстань 2)
· 1-4 (відстань 4)
· 1-5 (відстань 3)
· 2-3 (відстань 3)
· 2-4 (відстань 4)
· 3-4 (відстань 3)
· 3-5 (відстань 4)
· 4-5 (відстань 3)
розв’язок
Нехай N буде кількістю звірят, M – розмір дошки та D – найбільша відстань.
· Розв’язок для 1D дошки
Щоб розв’язати задачу на одновимірній дошці, спочатку відсортуємо координати, потім виконаємо алгоритм замітання. Будемо підтримувати два покажчика: голову та хвіст. Коли голова вказує на елемент з координатою x, хвіст вказує на перший елемент з координатою більше або рівною x−D.
Для кожної позиції голови треба додавати (голова−хвіст) до загального результату. Коли голова просувається на наступний елемент, ми можемо легко підсунути хвіст, щоб він вказував на потрібний елемент.
Складність алгоритму - O(N log N) для сортування та O(N) для замітання.
· Розв’язок для 2D дошки
Щоб розв’язати задачу для двовимірної дошки, спочатку розглянемо формулу відстані:
dist(P, Q) = | P. x − Q. x | + | P. y − Q. y |
Вказана формула перетвориться в одну з наступних формул, в залежності від взаємного розташування клітин:
dist(P, Q) = P. x − Q. x + P. y − Q. y = (P. x + P. y) − (Q. x + Q. y)
dist(P, Q) = P. x − Q. x − P. y + Q. y = (P. x − P. y) − (Q. x − Q. y)
dist(P, Q) = −P. x + Q. x + P. y − Q. y = (Q. x − Q. y) − (P. x − P. y)
dist(P, Q) = −P. x + Q. x − P. y + Q. y = (Q. x + Q. y) − (P. x + P. y)
Легко бачити, що відстань завжди дорівнює найбільшому з цих чотирьох значень. Оскільки P. x + P. y та P. x − P. y представляють "діагональні координати" точки P, зробимо підстановку:
P. d1 := P. x + P. y та P. d2 := P. x − P. y.
Тепер, можемо переписати формулу відстані в термінах d1 та d2:
dist(P, Q) = max{ P. d1 − Q. d1, P. d2 − Q. d2, Q. d2 − P. d2, Q. d1 − P. d1 },
або коротше:
dist(P, Q) = max{ |P. d1 − Q. d1|, |P. d2 − Q. d2| }
Після підстановки, відсортуємо всі точки по першій координаті (d1) за зростанням та виконаємо алгоритм замітання, схожий на одномірний випадок. Оскільки кожна точка P між головою та хвостом задовольняє нерівність голова. d1 − P. d1 ≤ D, нам тільки залишається перевірити для якої кількості також виконується нерівність |head. d2 − P. d2| ≤ D. Щоб обчислити це значення, будемо зберігати d2-координати всіх точок між головою та хвостом в дереві інтервалів або двійковому індексованому дереві.
Складність алгоритму для бінарного індексованого дерева буде O(N log N) для сортування та O(N log M) для замітання, де M – верхня межа для координат.
· Розв’язок для 3D дошки
Надихнувшись розв’язком для двомірного випадку, почнемо знову з формули відстані та отримаємо:
dist(P, Q) = max{ |P. f1 − Q. f1|, |P. f2 − Q. f2|, |P. f3 − Q. f3|, |P. f4 − Q. f4| }, де
P. f1 := P. x + P. y + P. z
P. f2 := P. x + P. y − P. z
P. f3 := P. x − P. y + P. z
P. f4 := P. x − P. y − P. z
Знову, виконаємо алгоритм замітання по координаті f1 для точок між головою і хвостом в тривимірному індексованому бінарному дереві щоб знайти кількість точок P, що задовольняють нерівності
|head. f2 − P. f2| ≤ D, |head. f3 − P. f3| ≤ D та |head. f4 − P. f4| ≤ D.
Складність алгоритму буде O(N log N) для сортування, та O(N log3 M) для замітання.
Варто зауважити, що ми можемо використати цей розв’язок для розв’язання задачі на всіх типах дошок. Присвоймо довільне константне значення (наприклад, 1) кожній відсутній координаті та реалізуємо тривимірне бінарне індексоване дерево, використовуючи динамічне виділення пам’яті або одновимірний масив з ручним відображенням тривимірного простору на масив.
ТРЕНування
Мирко і Славко усердно тренуються перед щорічним веломарафоном для тандемів, який пройде в Хорватії. Їм потрібно обрати маршрут для тренувань.
В країні N міст і M доріг. Кожна дорога з’єднує два міста, і по ній можна їхати в обох напрямках. Рівно N−1 з цих доріг є мощеними, а решта доріг — немощені стежки. На щастя, мережу доріг влаштовано таким чином, що довільну пару міст з’єднує шлях, що складається тільки з мощених доріг. Другими словами, N міст і N−1 мощених доріг утворюють структуру дерева.
Додатково відомо, що в кожному городі закінчується не більше 10 доріг.
Тренувальний маршрут починається в деякому місті, проходить по деяким дорогам та закінчується в тому же місті, де почався. Мирко і Славко люблять відвідувати нові міста, так що вони ввели правило: ніколи не проїжджати через одне й те саме місце, а також по одній і тій самій дорозі двічі. Тренувальний маршрут може починатись в довільному місті і не зобов’язаний проходити через всі міста.
В тандемі їхати на задньому сидінні легше, тому що велосипедист позаду захищений від вітру партнером, що сидить попереду. Із-за цього Мирко і Славко міняються місцями в кожному місті. Щоб отримати однакове навантаження на тренуванні, вони повинні обрати маршрут з парною кількістю доріг.
Суперники Мирка і Славка вирішили заблокувати деякі стежки, щоб було не можливо побудувати тренувальний маршрут, що задовольняє перераховані вимоги. Для кожної стежки відомо цену її блокування (додатне ціле число). Мощені дороги блокувати неможна.
Завдання
Напишіть програму, яка за описом мережі міст та доріг знаходить найменшу загальну вартість, що потрібна для блокування доріг таким чином, щоб не існувало тренувального маршруту, що задовольняє перерахованим вимогам.
Вхідні дані
Перший рядок вхідних даних містить два цілих числа N і M (2 ≤ N ≤ 1 000, N−1 ≤ M ≤ 5 000), що задають кількість міст і загальну кількість доріг.
Кожен з наступних M рядків містить три цілих числа A, B і C (1 ≤ A ≤ N, 1 ≤ B ≤ N,
0 ≤ C ≤ 10 000), що описують одну дорогу. Числа A і B є різними і визначають міста, що напряму з’єднані дорогою. Якщо C=0 — дорога є мощеною; інакше — це стежка, і число C задає ціну блокування дороги.
В кожному місті закінчується не більше 10 доріг. Два міста з’єднані напряму не більше ніж однією дорогою.
Вихідні дані
Вихідні дані мають мстити з одного цілого числа — найменшої загальної вартості, як описано вище.
Система оцінювання
В тестах, які буде в сумі оцінено в 30 балів, мощені дороги будуть утворювати ланцюг (тобто ніяке місто не буде кінцем трьох або більше мощених доріг).
Детальний відгук системы що тестує
на відісланий роз’язок
Під час туру ви можете обрати до 10 відсилань по цій задачі, які будуть перевірені (по можливості так швидко, як це можливо) на частині офіціальних тестів. Після того, як перевірку буде виконано, зведення результатів тестування буде доступне вам через систему проведення олімпіади.
ПРИКЛАДИ
вхідні дані 5 8 2 1 0 3 2 0 4 3 0 5 4 0 1 3 2 3 5 2 2 4 5 2 5 1 вихідні дані 5 | вхідні дані 9 14 1 2 0 1 3 0 2 3 14 2 6 15 3 4 0 3 5 0 3 6 12 3 7 13 4 6 10 5 6 0 5 7 0 5 8 0 6 9 11 8 9 0 вихідні дані 48 |
|
Розташування доріг і міст у першому прикладі. Мощені дороги виділено жирним. |
|
У Мирка і Славка є п’ять можливих маршрутів. Якщо дороги 1-3, 3-5 і 2-5 заблоковано, Мирко і Славко не можуть використовувати жоден з цих маршрутів. Вартість блокування цих трьох доріг - 5. Також можна заблокувати тільки 2 дороги, 2-4 і 2-5, але це дасть більшу вартість - 6. |
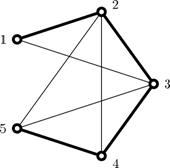

РОЗв’язок
Перевірка існування непарного циклу в графі є добре відомою проблемою задачею. В графі немає непарного циклу тоді і тільки тоді, коли граф є дводольним. З іншого боку, задача виявлення непарного циклу не є широко відомою.
Маємо граф, що складається з N вершин та M ребер. Точно N−1 ребер помічені як ребра дерева та вони формують дерево. Ребро, яке не є ребром дерева, будемо називати недерев’яними. Кожне недерев’яне ребро має асоційовану з ним вагу.
Задачею є пошук мінімального за вагою набору недерев’яних ребер, видалення яких утворює граф без циклів парної довжини. Будемо називати такі цикли парними циклами. Дивлячись з іншого боку, потрібно починаючи з графа, що містить тільки ребра дерева, ми повинні знайти набір не дерев’яних ребер максимальної ваги, які можна добавити в граф без утворення парних циклів.
Щоб описати модельний розв’язок, спершу зробимо декілька зауважень відносно структури графа з яким ми працюємо.
· Парні й непарні ребра
Розглянемо не дерев’яне ребро e={A, B}. Визначимо шлях у дереві для цього ребра як єдиний шлях з A до B, що складається тільки з ребер дерева. Якщо довжина шляху є парною, будемо казати, що це парне ребро, інакше – непарне. Будемо TP(e) позначати шлях у дереві для ребра e.
Очевидно, довільне непарне ребро задає в графі разом зі шляхом у дереві формує парний цикл. Таким чином, ми не можемо включати непарні ребра в наш граф і ми можемо повністю їх ігнорувати.
· Відношення між двома парними ребрами
Деякі парні ребра можуть входити до графу. Однак, якщо ми включимо декілька парних ребер, може утворитися парний цикл. Точніше кажучи, якщо e1 та e2 є парними ребрами, такими що TP(e1) та TP(e2) мають спільне ребро, тоді додавання в граф разом e1 та e2 обов’язково утворить парний цикл.
Щоб намітити шлях доведення цього твердження, розглянемо два непарних цикли, що утворені e1 та e2 разом з їх відповідними шляхами у дереві. Якщо ми викинемо всі спільні ребра з цих циклів, то отримаємо шляхи P1 та P2. Парність P1 дорівнює парності P2, оскільки ми видалили однакову кількість ребер з двох початково непарних циклів. Оскільки P1 та P2 також мають однакові кінцеві точки, ми можемо об’єднати їх в один великий парний цикл.
· Ребра дерева, що містяться в непарних циклах
Як прямий наслідок попереднього твердження, ми можемо заключити, що кожне ребро дерева може міститись як найбільше в одному непарному циклі.
Відповідно, якщо ми додаємо тільки парні ребра до дерева таким чином, що кожне ребро з дерева міститься в не більш як в одному непарному циклі, ми ніколи не утворимо парний цикл. Ідея доведення така. Якщо існує парний цикл, він має містити один або більше недерев’яних ребер. Неформально, якщо він містить рівно одне не дерев’яне ребро, це суперечить припущенню, що додавались тільки парні ребра; якщо він містить два або більше недерев’яних ребер, ми увійдемо у суперечність з другим припущенням.
· Модельний розв’язок
Тепер ми можемо використати наші спостереження для розробки розв’язку, з використанням ідеї динамічного програмування. Станом буде піддерево заданого дерева. Для кожного стану ми підрахуємо вагу максимального за вагою набора парних ребер, що можуть бути додані до піддерева, зберігаючи властивість що кожне ребро з дерева міститься в не більш ніж одному непарному циклі. Розв’язком задачі буде вага, отримана для стану, що задає початкове дерево.
Щоб отримати рекурсивну залежність, розглянемо всі парні ребра зі шляхами у дереві, що проходять через корінь дерева.
Ми можемо обрати одну з наступних дій:
(1) Ми не добавляємо ніякого парного ребра, чий шлях у дереві проходить через корінь дерева. У цьому випадку, ми можемо видалити корінь та продовжити обчислення оптимального розв’язку для кожного з піддерев, отриманих після видалення кореневої вершини.
(2) Ми обираємо парне ребро e, чий шлях у дереві проходить через корінь дерева. та додаємо його до дерева. Потім ми видаляємо всі ребра з дерева, що належать TP(e) (оскільки тепер вони містяться в одному непарному циклі), та, остаточно, ми обчислюємо оптимальну розв’язок для піддерев, що отримані після видалення шляху у дереві. Додамо w(e) до загальної суми.
Використаємо дерево на мал..1 як приклад. Мал. 2 ілюструє випадок (1) у рекурсивній залежності (було обрано не додавати ребро, чий шлях у дереві проходить через корінь дерева). Мал. 3 ілюструє випадок (2) рекурсивного відношення, коли ми включаємо ребро e={7, 9} до графа.
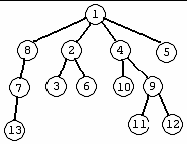
Мал 1
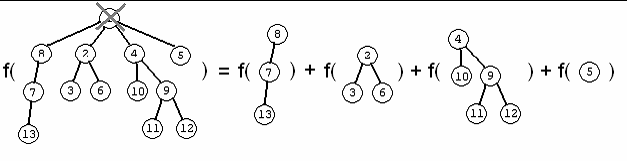
Мал 2
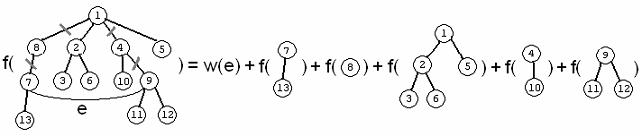
Мал 3
У залежності від того, як проводиться декомпозиція дерева, всі піддерева, які виникають як підзадачі, можуть бути подані цілим числом та бітовою маскою. Ціле задає індекс кореня піддерева, у той час як бітова маска визначає, які сини кореневого вузла видалені з піддрева.
Таким чином, загальна кількість можливих станів є обмежено. значенням N・2K, де K – це максимальна ступінь вузла.
У залежності від деталей реалізації, складність алгоритму може змінюватись. У офіціальній реалізації складність - O(M log M + MN + M・2K).
