
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Це обмеження будемо називати «дітетрад-стримуванням» (ditetrad-constraint).
Тепер розглянемо аналогічну структуру з трьома індикаторними змінними. Така модель містить три м-ланцюга, кожен з яких задовольняє умовам твердження про ЛМФЗ. Отже, можна отримати систему шести рівнянь. Члени зі змінною ![]() входять до системи парами, як відношення. Тривіальні алгебраїчні перетворення дозволяють позбавитися цих членів. Тоді система редукується до єдиного рівняння – «тріад-стримуванням» (triad-constraint):
входять до системи парами, як відношення. Тривіальні алгебраїчні перетворення дозволяють позбавитися цих членів. Тоді система редукується до єдиного рівняння – «тріад-стримуванням» (triad-constraint):
![]()
![]()
![]() =
= ![]()
![]()
![]() .
.
Рівняння констатує інваріантність добутку трьох парних залежностей до рівночасного реверсування цих залежностей. У лінійних моделях аналогічні викладки призводять до тотожності (бо коефіцієнт кореляції є симетричний показник залежності).
Взагалі, принципом виявлення прихованих змінних може бути пошук таких паттернів в даних, які є обов'язковими для моделі з прихованою змінною і є необов'язковими та малоймовірними для альтернативних моделей без прихованої змінної. Перевагу моделі з прихованою змінною можна аргументувати через критерії адекватності та простоти (або складності) моделі. Складність моделі визначається кількістю незалежних параметрів.
Легко переконатися, що розглянуті моделі вигляду «зірка» з бінарною центральною змінною мають значно менше параметрів, ніж альтернативні моделі без прихованої змінної. Такими альтернативними моделями є структури (фрагменти структури), де всі індикаторні змінні попарно поєднані («кліки» змінних). Наприклад, для випадку чотирьох тризначних індикаторних змінних ![]() ,
, ![]()
![]() ,
, ![]() модель «4-зірка» має 17 параметрів, а альтернативна (насичена) модель – 80 параметрів.
модель «4-зірка» має 17 параметрів, а альтернативна (насичена) модель – 80 параметрів.
Втім, існують спеціальні альтернативні моделі, які теж задовольняють дітетрад-стримування або тріад-стримування відповідно, але які не є насиченими. Одна з альтернатив – це модель, де виконується умовна незалежність декотрих двох змінних при кондиціонуванні третьої (бінарної) змінної. Прикладом такого випадку є модель з ланцюговою структурою ![]() —
—![]() —
—![]() , де змінна
, де змінна ![]() – бінарна. Але ця структура легко ідентифікується. Існують й інші альтернативні моделі.
– бінарна. Але ця структура легко ідентифікується. Існують й інші альтернативні моделі.
Для тестування дітетрад-стримування пропонується застосовувати дітет-статистику, яка для відповідного рівняння виглядає як:
![]() =
=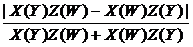 .
.
(Для тестування моделі береться середнє значення такої статистики для всіх рівнянь.) В разі, якщо залежності між змінними ![]() описуються вказаною вище моделлю «зірка» з бінарною прихованою змінною (гіпотеза «0»), величина
описуються вказаною вище моделлю «зірка» з бінарною прихованою змінною (гіпотеза «0»), величина ![]() має наближатися до нуля.
має наближатися до нуля.
Для випробування спроможності дітет-статистики розрізняти моделі і виявляти вказану модель з прихованою змінною треба дослідити поведінку дітет-статистики за альтернативної гіпотези, а саме, для загального випадку моделі. Нехай альтернативна модель – це насичена модель з чотирма тризначними попарно суміжними змінними ![]() . Для чисельного експерименту всі параметри цієї моделі були генеровані випадково. Для генерованих даних (6 тисяч випадків) побудована гістограма
. Для чисельного експерименту всі параметри цієї моделі були генеровані випадково. Для генерованих даних (6 тисяч випадків) побудована гістограма  . Виявилося, що значення
. Виявилося, що значення ![]() доволі широко розподілено і помітно зміщено відносно нуля. Навіть мода («пік») цього розподілення є значно віддалена від нуля і дорівнює приблизно 0,24. Середнє значення дітет-статистики опинилося близько 0,272. Отже, пропонований критерій може ефективно розрізняти моделі, коли є достатньо даних.
доволі широко розподілено і помітно зміщено відносно нуля. Навіть мода («пік») цього розподілення є значно віддалена від нуля і дорівнює приблизно 0,24. Середнє значення дітет-статистики опинилося близько 0,272. Отже, пропонований критерій може ефективно розрізняти моделі, коли є достатньо даних.
Якщо автентична модель з прихованою змінною має вигляд «недовершеної зірки», тобто відрізняється від вищеописаного випадку 4-зірки тим, що між змінними ![]() та
та ![]() є додатковий безпосередній зв'язок, то буде виконуватись неповне дітетрад-стримування, яке складається тільки з двох рівнянь:
є додатковий безпосередній зв'язок, то буде виконуватись неповне дітетрад-стримування, яке складається тільки з двох рівнянь:
![]()
![]() =
=![]()
![]() ,
, ![]()
![]() =
=![]()
![]() .
.
Відкриття прихованої змінної допомагає з'ясувати або уточнити каузальні відносини. Наприклад, результатом виведення алгоритмом типу РС або «Razor» може бути така «кліка» (індикаторних) змінних, що не виключена можливість автентичної структури, де дві, три чи більше індикаторних змінних можуть одночасно бути причинами для іншої індикаторної змінної. Але після виявлення прихованої змінної, яка пояснює утворення цієї кліки змінних, зазначена можлива інтерпретації відпадає. Дійсно, конфігурація типу «зірка» означає, що безпосередні зв'язки між індикаторними змінними відсутні, і залишається тільки дві можливості: або всі індикаторні змінні є наслідками прихованої змінної, або одна з індикаторних змінних є причиною для прихованої змінної, яка у свою чергу є причиною для решти індикаторних змінних. Виявлене обмеження на каузальні відношення у поєднанні з іншою інформацією (орієнтація деяких ребер) дозволяє суто логічно отримати більш конкретну і точну каузальну інформацію.
Отже, відкриття прихованої змінної в позиції «вузла» моделі надає додаткову каузальну інформацію, що у сукупності з відношеннями незалежності може усунути невизначеність каузальних відношень.
Висновки
У дисертації досліджено широкий клас моделей – каузальних мереж та ймовірнісних моделей залежностей, – які визначаються на основі орієнтованих графів та характеризуються багатомірними марковськими властивостями. Репрезентація моделі у вигляді мережевої структури з орієнтованими (спрямованими) зв'язками надає змогу адекватно відображати систему впливів та каузальних відношень в об'єкті (середовищі) за неповної спостережуваності. Досліджено методи аналізу, синтезу та індуктивного виведення вказаних моделей.
Для моделювання об'єктів та процесів (з різних предметних галузей) ставиться задача виведення каузальної мережі чи структури системи залежностей на основі даних пасивних спостережень. Така задача може ставитися за відсутності апріорних знань. В даній роботі показано шляхи подолання проблем високої обчислювальної трудомісткості та низької надійності виведення структури моделі з даних. Існує певна межа (яка залежить від якості та обсягу вхідних даних), за якою ніякий метод аналізу даних пасивних спостережень не може точно ідентифікувати структуру моделі. Неточність результату виведення каузальної мережі проявляється як власне структурні помилки, а також як неповнота ідентифікації спрямування зв'язків.
1. Головним науковим результатом роботи є теоретичний апарат та методологічні принципи створення ефективних методів та алгоритмів індуктивного виведення структур ймовірнісних залежностей та каузальних мереж, які забезпечують переваги над відомими аналогами за обчислювальною складністю, адекватністю результату та вимогами до формату даних.
2. Введено концепцію локально-мінімального сепаратора в каузальних мережах, яка виокремлює таку підмножину марковських властивостей цих мереж, що можна сформулювати необхідні вимоги до членів сепараторів виключно в термінах марковських властивостей. Необхідні вимоги до членів локально-мінімальних сепараторів дають змогу вивести нетривіальні обмеження для фактів незалежності складних форматів за наявності фактів незалежності простого формату.
3. Обмеження на множині локально-мінімальних сепараторів формалізовано у вигляді імплікативних правил мінімальної сепарації, які дозволяють на основі набору фактів незалежності робити висновки про фрагменти структури або характеристики моделі. Правила мінімальної сепарації іноді дозволяють робити висновок про існування чи відсутність відповідного зв'язку в моделі без його прямого тестування і вичерпного пошуку спростування. Включення таких правил в алгоритм іноді дозволяє уникнути перебору (факторіальної складності) під час виведення моделі.
4. Сформульовано аксіоми для підкласів моделей залежностей, визначених відповідними обмеженнями на типи припустимих шляхів та циклів. Досліджено та формалізовано графові та статистичні властивості цих моделей. Розроблено апарат генотипів вершин (змінних) для компактної репрезентації множини безумовних залежностей в моделях, а також апарат провокованих залежностей. Розроблено нові спеціалізовані алгоритми синтезу моделей (суб-кубічної складності) в підкласі полі-лісів залежностей та в підкласі монопотокових моделей залежностей, які використовують тільки двомісні та тримісні відношення (тести).
5. Розроблено новий метод й алгоритм «Proliferator-D» суб-кубічної складності, який на основі даних відтворює структуру моделей залежностей в підкласі монопотокових моделей. Алгоритм «Proliferator-D» застосовує техніку провокованих залежностей та величини безумовних залежностей й дозволяє обійтися без пошуку сепараторів. Перевага цього алгоритму визначається тим, що він використовує тільки двомісні та тримісні статистики й зберігає здатність виводити наближену модель поза межами класу монопотокових моделей.
6. Розроблено нові ефективні й коректні методи й алгоритми синтезу баєсових мереж та каузальних мереж без орієнтованих циклів, побудовані на ідеології звуження простору пошуку сепараторів з використанням правил мінімальної сепарації. Ці алгоритми, зберігаючи коректність для всього класу моделей, в разі моделі з підкласу полі-лісів дозволяють виконати синтез на основі тестів першого рангу.
7. Розроблено нові ефективні алгоритми (серії «Razor») виведення баєсових мереж та каузальних мереж без орієнтованих циклів виключно на основі даних, без апріорних знань. Коректність алгоритмів серії «Razor» ґрунтується на доволі простих припущеннях не-оманливості розподілення ймовірностей змінних відносно структури генеративної моделі. Завдяки застосуванню правил прискорення індуктивного виведення пропоновані алгоритми суттєво переважають відомі методи за швидкістю, залишаючись асимптотично-коректними.
Згідно результатів випробувань на складних моделях з дискретними змінними, новий алгоритм Razor-1.2 є більш ефективним при виведення моделі з даних, ніж базовий аналог (алгоритм РС). Алгоритм Razor-1.2 робить менше реберних помилок і виконує значно менше тестів (від 50% до кількох разів), що забезпечує перевагу у швидкодії. Алгоритм Razor-1.2 переважає аналог й за каузальною продуктивністю, вірно відтворюючи більше каузальних зв'язків.
8. Розвинуто нові методи виявлення прихованих бінарних змінних у контексті номінальних змінних з використанням нового оригінального показника залежності – індексу детермінації. Принципом виявлення прихованої змінної, через яку поєднані спостережувані змінні, є перевірка виконання відповідних обмежень типу рівність для набору парних залежностей. Відкриття прихованої змінної у відповідному контексті дає інформацію для уточнення каузальних відношень в моделі.
Список опублікованих праць за темою дисертації
1. Балабанов сепараторы в структурах зависимостей. Свойства и идентификация / // Кибернетика и системный анализ. – 2008. – № 6. – С. 17–32.
2. Логика минимальной сепарации в каузальных сетях / // Кибернетика и системный анализ. – 2013. – № 2. – С. 36–47.
3. С. Формирование минимальных d-сепараторов в системе зависимостей / // Кибернетика и системный анализ. – 2009. – № 5. – С. 38–50.
4. І. До відкриття латентного бінарного фактора в статистичних даних категорного типа / П. І. Андон, // Доповіді НАН України. – 2008. – № 9. – С. 37–43.
5. Від коваріацій до каузальності. Відкриття структур залежностей в даних / О.С. Балабанов // Системні дослідження та інформаційні технології. – 2011. – № 4 . – С. 104–118.
6. Правила підбору сепараторів в баєсівських мережах / О.С. Балабанов // Проблеми програмування. – 2007. – № 4. – С. 33–43.
7. Балабанов і-лінеарність у дискретних моделях залежностей та відкриття латентного фактору трьох ефектів / О.С. Балабанов // Проблемы программирования. – 2006. – № 4. – С. 28–36.
8. Балабанов A. C. К выводу структур моделей вероятностных зависимостей из статистических данных / // Кибернетика и системный анализ. – 2005. – № 5. – С. 19–31.
9. Быстрый алгоритм вывода структур байесовых сетей из данных / , , // Проблемы управления и информатики. – 2011. – № 5. – С. 73–80.
10. С. Реконструкция модели вероятностных зависимостей по статистическим данным. Инструментарий и алгоритм / // Проблемы управления и информатики. – 2009. – № 6. – С. 90–103.
11. С. Мера для обнаружения зависимостей между переменными в данных в условиях случайных возмущений / // Проблемы программирования. – 1999. – № 2. – С. 63–69.
12. С. Індуктивне відтворення деревовидних структур систем залежностей / О.С. Балабанов // Проблемы программирования. – 2001. – № 1–2. – С. 95–108.
13. Балабанов ймовірнісних залежностей: графові та статистичні властивості / О.С. Балабанов // Математичні машини та системи. – 2009. – № 3. – С. 80–97.
14. Балабанов алгоритмів відтворення баєсових мереж. Адаптація до структур без циклів / О.С. Балабанов // Проблеми програмування. – 2011. – № 1. – С. 63–69.
15. Структурные статистические модели: инструмент познания и моделирования / , // Системні дослідження та інформаційні технології. – 2007. – № 1. – С. 79–98.
16. Балабанов A. C. Восстановление структур систем вероятностных зависимостей из данных. Аппарат генотипов переменных / // Проблемы управления и информатики. – 2003. – № 2. – C. 91–99.
17. С. Индуктивный метод восстановления монопотоковых вероятностных графовых моделей зависимостей / // Проблемы управления и информатики. – 2003. – № 5. – С.75–84.
18. С. О логике независимости каузальных диаграмм / // Сб.: Компьютерная математика. – 2009. – № 2. – Ин-т кибернетики им. НАН Украины. – С. 109–115.
19. Выделение знаний из баз данных – передовые компьютерные технологии интеллектуального анализа данных / А.С. Балабанов // Математичні машини і системи. – 2001. – № 1–2. – С. 40–54.
20. Балабанов метод виявлення структур залежностей в статистичних даних / О.С. Балабанов // Проблемы программирования. – 2004. – № 2–3. – С. 312–319.
21. К проблеме вывода знаний о структуре зависимостей между переменными из данных большого объема в условиях помех / // Проблемы программирования. – 2000. – № 3. – С. 527–535.
22. С. Відкриття структур залежностей в даних: від непрямих асоціацій до каузальності / О.С. Балабанов // Проблемы программирования. – 2002. – № 1-2. – С. 309–316.
23. Выявление знаний и изыскания в базах данных: подходы, модели, методы и системы (обзор) / , // Проблемы программирования. – 2000. – № 1–2. – С. 513–526.
24. С. Критерії ідентифікації ймовірнісних залежностей в базах даних / О.С. Балабанов // Праці 1-ї міжнар. наук.-практ. конфер. з програмування (УкрПрог'98), Київ, 2-4 вересня 1998. – С. 380–382.
25. О методе идентификации направленности зависимостей по результатам наблюдений в условиях шумов / , // Сб.: Транспорт. Математичне моделювання в інженерних та економічних задачах транспорту. – Дніпропетровськ: Січ, 1999. – С. 127–133.
26. С. Новий метод відтворення ймовірнісних графових моделей залежностей / / О.С. Балабанов // Праці 1-ї міжнар. конф. з індуктивного моделювання “МКІМ-2002”, Львів, 20-25 травня 2002 р., т. 1. – С. 118–124.
27. Balabanov O. S. On perspectives of causal networks reconstruction by independence-based methods // Proceedings of the 4th Intern. Conf. on Inductive Modelling (ICIM’2013). – Kyiv, September 16–20, 2013. – Kyiv, Ukraine – P.139–142.
28. Balabanov O. S. Acceleration of Inductive Inference of Causal Diagrams // Proc. of the 4th Intern. Workshop on Inductive Modelling (IWIM'2011). – Kyiv, July 4-11, 2011. – P. 16–21. – ISBN 6078-8.
29. Балабанов методологія виведення систем структуральних рівнянь з даних. Вдосконалення методів виведення / О.С. Балабанов. – «Інформатика та системні науки». – Матеріали ІІІ Всеукраїн. науково-практ. конф., 1–3 березня 2012 р. – Полтава, ПУЕТ, 2012. – С. 15–17. – ISBN -154-2.
аНОТАЦІя
Каузальні мережі: аналіз, синтез та виведення з статистичних даних. – Рукопис.
Дисертація на здобуття наукового ступеня доктора фізико-математичних наук за спеціальністю 01.05.01 – теоретичні основи інформатики та кібернетики. – Інститут кібернетики імені НАН України, Київ, 2014.
Дисертація присвячена дослідженню теорії каузальних мереж та інших моделей систем ймовірнісних залежностей, а також розробці методології виведення таких моделей з статистичних даних (зокрема, за відсутності апріорних знань). Для подолання проблем відомих методів відтворення каузальних мереж та структур залежностей (спричинених складним перебором) запропоновано нові методологічні засоби аналізу, синтезу та виведення з даних. Ідея розроблених у дисертації засобів та методів полягає у систематичному використанні поняття локально-мінімального сепаратора та імплікацій марковських властивостей цих моделей, а також у систематичному врахуванні топологічних обмежень відповідних підкласів моделей залежностей. Це дозволяє суттєво звузити (обмежити) простір пошуку адекватної моделі або навіть звести виведення моделі до верифікації відносно невеликого набору певних статистичних паттернів та свідчень.
Створено методологічні засади побудови ефективних методів та алгоритмів виведення каузальних мереж та структур залежностей з даних. Встановлено і доведено низку імплікативних правил для марковських властивостей (правил мінімальної сепарації), які дозволяють на основі набору свідчень логічно виводити елементи структури моделі або звужувати множину припустимих структур. Розроблено принципи та правила застосування апарату генотипів змінних, техніки провокованих залежностей та топологічних обмежень відповідних підкласів моделей залежностей для підвищення ефективності методів та алгоритмів індуктивного виведення моделей. Розроблено новий спеціалізований алгоритм («Proliferator-D») відтворення моделей залежностей в підкласі монопотокових структур, який використовує тільки двомісні та тримісні статистики (тести нульового та першого рангу), що гарантує кубічну обчислювальну складність.
Розроблено кілька нових ефективних алгоритмів (серії «Razor») виведення каузальних мереж з даних, асимптотично-коректних для ситуації без латентних змінних. Розроблено алгоритм Razor-1.2, який робить менше помилок, ніж відомий базовий аналог, і разом з тим у середньому виконує у півтори рази менше тестів (що забезпечує перевагу у швидкодії). Алгоритм Razor-1.2 переважає аналог й за адекватністю відтворення каузальних зв'язків.
Запропоновано нові засоби та методи виявлення прихованих змінних у контексті моделі. Виведено обмеження типу рівність («дітетрад-стримування» та «тріад-стримування») для набору парних залежностей, які дозволяють виявляти бінарну приховану змінну.
Загалом, дисертація робить внесок у методологію виведення структур каузальних зв'язків та впливів між змінними об'єкту дослідження на основі даних пасивних спостережень.
Ключові слова: каузальні мережі, умовна незалежність, марковські властивості, розподілення ймовірностей, d-сепарація, ациклічний орієнтований граф, орієнтація ребер, обчислювальна ефективність, виведення з даних.
АННОТАЦИЯ
Балабанов сети: анализ, синтез и вывод из статистических данных. – Рукопись.
Диссертация на соискание ученой степени доктора физико-математических наук по специальности 01.05.01 – теоретические основы информатики и кибернетики. – Институт кибернетики им. В. М. Глушкова НАН Украины, Киев, 2014.
Диссертация посвящена исследованию теории каузальных сетей и других моделей систем вероятностных зависимостей, а также разработке методологии выведения таких моделей из статистических данных (в частности, при отсутствии априорных знаний). Для преодоления проблем известных методов восстановления каузальных сетей и структур зависимостей из данных (обусловленных сложным перебором) предложены новые методологические средства анализа, синтеза и вывода из данных. Идея разработанных в диссертации средств и методов заключается в систематическом использовании понятия локально-минимального сепаратора и импликаций марковских свойств этих моделей, а также в систематическом учете топологических ограничений соответствующих подклассов моделей зависимостей. Это позволяет существенно сузить (ограничить) простор поиска адекватной модели или даже свести вывод модели к верификации относительно небольшого набора определенных статистических паттернов и свидетельств.
Созданы методологические основы построения эффективных методов и алгоритмов вывода каузальных сетей и структур зависимостей из данных. Установлены и доказаны ряд импликативных правил для марковских свойств (правил минимальной сепарации), которые позволяют на основе набора свидетельств логически выводить элементы структуры модели или сужать множество допустимых структур. Разработаны принципы и правила применения аппарата генотипов переменных, техники провоцированных зависимостей и топологических ограничений соответствующих подклассов моделей зависимостей для повышения эффективности методов и алгоритмов индуктивного вывода моделей. Разработан новый специализированный алгоритм («Proliferator-D») восстановления моделей зависимостей в подклассе монопотоковых структур, который использует только двуместные и трехместные статистики (тесты нулевого и первого ранга), что гарантирует кубическую вычислительную сложность.
Разработаны несколько новых эффективных алгоритмов (серии «Razor») вывода каузальных сетей из данных, асимптотически-корректных для ситуации без латентных переменных. Разработан алгоритм Razor-1.2, который делает меньше ошибок, чем известный базовый аналог, и вместе с тем в среднем выполняет в полтора раза меньше тестов (что обеспечивает преимущество в быстродействии). Алгоритм Razor-1.2 превосходит аналог также и по адекватности восстановления каузальных связей.
Предложены новые средства и методы обнаружения скрытых переменных в контексте модели. Выведены ограничения типа равенство («дитетрад-констрейнт и «триад-констрейнт») для набора парных зависимостей, которые позволяют выявлять бинарную скрытую переменную.
В целом, диссертация вносит вклад в методологию вывода структур каузальных связей и влияний между переменными объекта исследования на основе данных пассивных наблюдений.
Ключевые слова: каузальные сети, условная независимость, марковские свойства, распределение вероятностей, d-сепарация, ациклический ориентированный граф, ориентация ребер, вычислительная эффективность, выведение из данных.
Abstract
Balabanov O. S. Causal nets: analysis, synthesis and inference from statistical data. – Manuscript.
Thesis submitted for a Doctor's degree in physical and mathematical sciences by speciality 01.05.01 – theoretical foundations of informatics and cybernetics. – V. M. Glushkov Institute of Cybernetics, National Academy of Sciences of Ukraine, Kyiv, 2014.
The dissertation is devoted to the theory of causal nets and graphical models of probabilistic dependencies, as well as to the methods of model inference from data. We have considered an acyclic digraph structure (ADG) dependency models, and we take a constraint-based approach to model reconstruction. In aim to overcome the problems of graphical model induction we propose new methodological means and methods of model’s analysis, synthesis and inference from data. The key idea to improve inductive inference of model’s structure comes from systematic exploitation of Markov properties and topological restrictions of causal nets and of their subclasses. Introducing and intensive utilization of the concept of locally-minimal d-separator has allowed us developing several rules of minimal separation and their empirical counterparts – separational rules of inductive inference acceleration (SIIA-rules). These rules are deduced from the criterion of d-separation and acyclic property of digraph. The rules perform such functions as: recognition of edge presence (absence), recognition of some variables as non members (obligate members) of supposed separator. Utilization of SIIA-rules in inference algorithms can radically reduce a searching space during model’s skeleton identification.
We have developed a few constraint-based algorithms (“Razor”) for learning Bayesian networks from data. Novelty of proposed algorithms comes from SIIA-rules utilization. It has been demonstrated that algorithm Razor-1.2, equipped with proposed rules, performs learning Bayesian networks (of moderate density) 1.5 times faster then well-known PC algorithm. It has been experimentally demonstrated, that Razor-1.2 algorithm improves percentage of causal recovery, increasing it up to 24%, whereas PC algorithm provides 6% only.
We have developed technique and algorithm for recovery of probabilistic dependency model in the class of ‘mono-streams’ structures (subclass of Bayesian nets) from data. The “Proliferator-D” algorithm relies on dependence provocation rather then separation (i. e. dependence destroying) and utilizes dependence’s magnitude (analogously to Chow-Liu algorithm). Due to this the algorithm needs to execute a zero - and first-order independence tests only. So the algorithm is of sub-cubic complexity. When generic model goes beyond class of ‘mono-streams’ structures, the algorithm gracefully degrades to Chow-Liu algorithm and would infer relevant spanning tree model.
We have proposed new instruments for hidden variable discovery in context of probabilistically dependent variables. For a discrete model with tree-like structure it is demonstrated, that if a separating variable (a root vertex) is binary, then constraints (like “tetrad difference”) hold. Specifically, when there are four or three manifest variables in a model, the “ditetrad-constraint” or “triad-constraint” applies respectively. So, these constraints facilitate discovery of hidden binary variable (latent class), which is responsible for associations among discrete manifest variables. It has been demonstrated, that these constraints do discriminate between the tree-like structure with hidden common factor and the structure where manifest variables are pair-wisely adjacent.
Keywords: causal nets, conditional independence, Markov properties, probability distribution, d-separation, acyclic digraph, edge orientation, computational efficiency, inference from data.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
