

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Раздел 2. Операционные системы
1. ОС - ее место в архитектуре компьютера. Функции ОС.
2. Архитектура ОС - монолитные и многоуровневые системы. Микроядерная архитектура. Модель клиент-сервер.
3. Процессы - модель, иерархия, состояния. Планировщик, переключения процессов.
4. Межпроцессное взаимодействие - состояние состязания, критические области. Взаимное исключение с активным ожиданием - алгоритм Петерсона, команда TSL.
5. Семафоры как инструмент реализации взаимоисключений и организации взаимодействия процессов.
6. Принципы организации мониторов.
7. Управление памятью - вычисление физического адреса в реальном и виртуальном режимах. Регистры преобразования адреса, назначение и использование теневых регистров. Дескрипторы сегментов.
2.1. ОС – ее место в архитектуре компьютера. Функции ОС.
Операцио́нная систе́ма, - комплекс управляющих и обрабатывающих программ, которые, с одной стороны, выступают как интерфейс между аппаратными устройствами и прикладными программами, а с другой — предназначены для управления аппаратными устройствами, управления вычислительными процессами, эффективного распределения вычислительных ресурсов между вычислительными процессами и организации надёжных вычислений. Это определение применимо к большинству современных ОС общего назначения.
Cуществует много точек зрения на то, что такое операционная система. Невозможно дать ей адекватное строгое определение. Проще сказать не что есть операционная система, а для чего она нужна и что она делает.
В логической структуре типичной вычислительной системы ОС занимает положение между аппаратными устройствами с их микроархитектурой, машинным языком и, возможно, собственными (встроенными) микропрограммами — с одной стороны — и прикладными программами с другой.
Разработчикам программного обеспечения ОС позволяет абстрагироваться от деталей реализации и функционирования аппаратных устройств, предоставляя минимально необходимый набор функций.
В большинстве вычислительных систем ОС являются основной, наиболее важной (а иногда единственной) частью системного ПО.
Основные функции:
· Выполнение по запросу программ тех достаточно элементарных (низкоуровневых) действий, которые являются общими для большинства программ и часто встречаются почти во всех программах (ввод и вывод данных, запуск и остановка других программ, выделение и освобождение дополнительной памяти и др.).
· Загрузка программ в оперативную память и их выполнение.
· Стандартизованный доступ к периферийным устройствам (устройства ввода-вывода).
· Управление оперативной памятью (распределение между процессами, организация виртуальной памяти).
· Управление доступом к данным на энергонезависимых носителях (таких как жёсткий диск, оптические диски и др.), организованным в той или иной файловой системе.
· Обеспечение пользовательского интерфейса.

· Сетевые операции, поддержка стека сетевых протоколов.
Дополнительные функции:
· Параллельное или псевдопараллельное выполнение задач (многозадачность).
· Эффективное распределение ресурсов вычислительной системы между процессами.
· Разграничение доступа различных процессов к ресурсам.
· Организация надёжных вычислений (невозможности одного вычислительного процесса намеренно или по ошибке повлиять на вычисления в другом процессе), основана на разграничении доступа к ресурсам.
· Взаимодействие между процессами: обмен данными, взаимная синхронизация.
· Защита самой системы, а также пользовательских данных и программ от действий пользователей (злонамеренных или по незнанию) или приложений.
· Многопользовательский режим работы и разграничение прав доступа (см. аутентификация, авторизация).
2.2. Архитектура ОС – монолитные и многоуровневые системы. Микроядерная архитектура. Модель клиент-сервер.
Источник Википедия и книга http://www. citforum. ru/operating_systems/sos/glava_19.shtml
Большинство программ, как системных (входящих в ОС), так и прикладных, исполняются в непривилегированном («пользовательском») режиме работы процессора и получают доступ к оборудованию (и, при необходимости, к другим ядерным ресурсам, а также ресурсам иных программ) только посредством системных вызовов. Ядро исполняется в привилегированном режиме: именно в этом смысле говорят, что ОС (точнее, её ядро) управляет оборудованием.
В определении состава ОС значение имеет критерий операциональной целостности (замкнутости): система должна позволять полноценно использовать (включая модификацию) свои компоненты. Поэтому в полный состав ОС включают и набор инструментальных средств (от текстовых редакторов до компиляторов, отладчиков и компоновщиков).
Большинство современных операционных систем представляет собой хорошо структурированные модульные системы, способные к развитию, расширению и переносу на новые платформы.
Монолитная ОС (UNIX или Novell NetWare) использует монолитное ядро, которое компонуется как одна программа, работающая в привилегированном режиме. Монолитное ядро представляет собой набор процедур, каждая из которых может вызвать каждую. Все процедуры работают в привилегированном режиме. Таким образом, монолитное ядро – это такая схема операционной системы, при которой все ее компоненты являются составными частями одной программы, используют общие структуры данных и взаимодействуют друг с другом путем непосредственного вызова процедур. Для монолитной операционной системы ядро совпадает со всей системой.
Во многих операционных системах с монолитным ядром сборка ядра, то есть его компиляция, осуществляется отдельно для каждого компьютера, на который устанавливается операционная система. При этом можно выбрать список оборудования и программных протоколов, поддержка которых будет включена в ядро. Так как ядро является единой программой, перекомпиляция – это единственный способ добавить в него новые компоненты или исключить неиспользуемые.
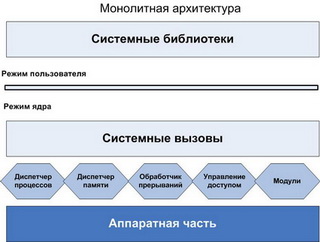
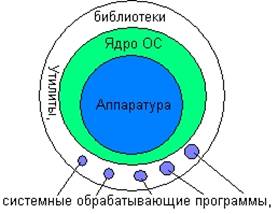
Многоуровневая ОС. Можно разбить всю вычислительную систему на ряд более мелких уровней с хорошо определенными связями между ними, так чтобы объекты уровня N могли вызывать только объекты уровня N-1. Нижним уровнем в таких системах обычно является hardware, верхним уровнем – интерфейс пользователя. Слоистую структуру вычислительной системы принято изображать в виде системы концентрических окружностей, иллюстрируя тот факт, что каждый слой может взаимодействовать только со смежными слоями.
Поскольку ядро представляет собой сложный многофункциональный комплекс, то многослойный подход обычно распространяется и на структуру ядра. Ядро может состоять из следующих слоев: Средства аппаратной поддержки ОС, Машинно-зависимые компоненты ОС, Базовые механизмы ядра, Менеджеры ресурсов, Интерфейс системных вызовов.
Слоеные системы хорошо реализуются. При использовании операций нижнего слоя не нужно знать, как они реализованы, нужно лишь понимать, что они делают. Слоеные системы хорошо тестируются. При возникновении ошибки мы можем быть уверены, что она находится в тестируемом слое. Слоеные системы хорошо модифицируются. При необходимости можно заменить лишь один слой, не трогая остальные. Но слоеные системы сложны для разработки: тяжело правильно определить порядок слоев и что к какому слою относится. Слоеные системы менее эффективны, чем монолитные. Для выполнения операций ввода-вывода программе пользователя придется проходить все слои от верхнего до нижнего. Примеры: THE (Дейкстра, в 1968 г.), MULTICS, некоторые Unix.
 Микроядерная ОС. Современная тенденция в разработке операционных систем состоит в перенесении значительной части системного кода на уровень пользователя и одновременной минимизации ядра. В этом случае более высокоуровневые функции операционной системы выполняются специализированными компонентами — серверами, работающими в пользовательском режиме. Управление и обмен данными при этом осуществляется через передачу сообщений, доставка которых является одной из основных функций микроядра. Основное достоинство – высокая степень модульности ядра операционной системы. Это существенно упрощает добавление в него новых компонентов. В микроядерной ОС можно, не прерывая ее работы, загружать и выгружать новые драйверы, файловые системы и т. д. В то же время вносятся дополнительные накладные расходы, связанные с передачей сообщений, что существенно влияет на производительность.
Микроядерная ОС. Современная тенденция в разработке операционных систем состоит в перенесении значительной части системного кода на уровень пользователя и одновременной минимизации ядра. В этом случае более высокоуровневые функции операционной системы выполняются специализированными компонентами — серверами, работающими в пользовательском режиме. Управление и обмен данными при этом осуществляется через передачу сообщений, доставка которых является одной из основных функций микроядра. Основное достоинство – высокая степень модульности ядра операционной системы. Это существенно упрощает добавление в него новых компонентов. В микроядерной ОС можно, не прерывая ее работы, загружать и выгружать новые драйверы, файловые системы и т. д. В то же время вносятся дополнительные накладные расходы, связанные с передачей сообщений, что существенно влияет на производительность.
Модель клиент-сервер. Модель клиент-сервер предполагает наличие программного компонента - потребителя какого-либо сервиса - клиента, и программного компонента - поставщика этого сервиса - сервера. Взаимодействие между клиентом и сервером стандартизуется, так что сервер может обслуживать клиентов, реализованных различными способами и, может быть, разными производителями. При этом главным требованием является то, чтобы они запрашивали услуги сервера понятным ему способом. Модель клиент-сервер является скорее удобным концептуальным средством ясного представления функций того или иного программного элемента в той или иной ситуации, нежели технологией.
Применительно к структурированию ОС идея состоит в разбиении ее на несколько процессов - серверов, каждый из которых выполняет отдельный набор сервисных функций - например, управление памятью, создание или планирование процессов. Каждый сервер выполняется в пользовательском режиме. Клиент, которым может быть либо другой компонент ОС, либо прикладная программа, запрашивает сервис, посылая сообщение на сервер. Ядро ОС (называемое здесь микроядром), работая в привилегированном режиме, доставляет сообщение нужному серверу, сервер выполняет операцию, после чего ядро возвращает результаты клиенту с помощью другого сообщения
Две последние модели сливаются и их представителями являются Windows NT, Workplace OS.
2.3. Процессы – модель, иерархия, состояния. Планировщик, переключения процессов.
Чтобы поддерживать мультипрограммирование, ОС должна определить и оформить для себя те внутренние единицы работы, между которыми будет разделяться процессор и другие ресурсы компьютера. Более крупная единица работы, носящая название процесса, или задачи, требует для своего выполнения нескольких более мелких работ, для обозначения которых используют термины «поток», или «нить».
Проце́сс — выполнение пассивных инструкций компьютерной программы на процессоре ЭВМ. Стандарт ISO 9000:2000 Definitions определяет процесс как совокупность взаимосвязанных и взаимодействующих действий, преобразующих входящие данные в исходящие.
Компьютерная программа сама по себе это только пассивная совокупность инструкций, в то время как процесс — это непосредственное выполнение этих инструкций.
В операционных системах, где существуют и процессы, и потоки, процесс рассматривается операционной системой как заявка на потребление всех видов ресурсов, кроме одного — процессорного времени. Этот последний важнейший ресурс распределяется операционной системой между другими единицами работы — потоками.
В однопроцессорных системах псевдопараллельная обработка нескольких процессов достигается с помощью переключения процессора с одного процесса на другой. Каждый процесс может находиться в двух состояниях: процесс исполняется и процесс не исполняется.
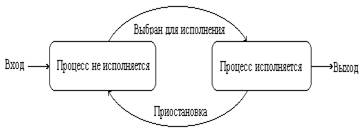 Процесс, в состоянии процесс исполняется, может завершиться или быть приостановлен ОС и снова переведен в состояние процесс не исполняется. Причины приостановки процессов: для его дальнейшей работы потребовалось возникновение какого-либо события (например, завершения операции ввода-вывода) или истек временной интервал, отведенный операционной системой для работы этого процесса. После этого операционная система по определенному алгоритму выбирает для исполнения один из процессов, находящихся в состоянии процесс не исполняется, и переводит его в состояние процесс исполняется. Новый процесс, появляющийся в системе, первоначально помещается в состояние процесс не исполняется.
Процесс, в состоянии процесс исполняется, может завершиться или быть приостановлен ОС и снова переведен в состояние процесс не исполняется. Причины приостановки процессов: для его дальнейшей работы потребовалось возникновение какого-либо события (например, завершения операции ввода-вывода) или истек временной интервал, отведенный операционной системой для работы этого процесса. После этого операционная система по определенному алгоритму выбирает для исполнения один из процессов, находящихся в состоянии процесс не исполняется, и переводит его в состояние процесс исполняется. Новый процесс, появляющийся в системе, первоначально помещается в состояние процесс не исполняется.
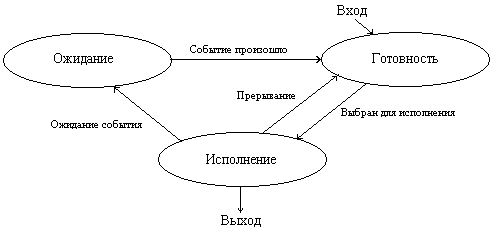 Такая модель является очень грубой. Она не учитывает, в частности то, что процесс, выбранный для исполнения, может все еще ждать события, из-за которого он был приостановлен, и реально к выполнению не готов. Для того чтобы избежать такой ситуации, разобьем состояние процесс не исполняется на два новых состояния: готовность и ожидание.
Такая модель является очень грубой. Она не учитывает, в частности то, что процесс, выбранный для исполнения, может все еще ждать события, из-за которого он был приостановлен, и реально к выполнению не готов. Для того чтобы избежать такой ситуации, разобьем состояние процесс не исполняется на два новых состояния: готовность и ожидание.
Всякий новый процесс, появляющийся в системе, попадает в состояние готовность. ОС, пользуясь каким-либо алгоритмом планирования, выбирает один из готовых процессов и переводит его в состояние исполнение. В состоянии исполнение происходит непосредственное выполнение программного кода процесса. Покинуть это состояние процесс может по трем причинам:
- либо он заканчивает свою деятельность; либо он не может продолжать свою работу, пока не произойдет некоторое событие, и операционная система переводит его в состояние ожидание; либо в результате возникновения прерывания в вычислительной системе (например, прерывания от таймера по истечении дозволенного времени выполнения) его возвращают в состояние готовность.
Для полноты необходимо ввести еще два состояния процессов: рождение и закончил исполнение.
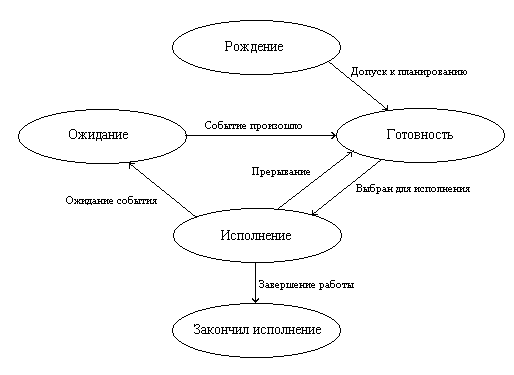 Для появления в ВС процесс должен пройти через состояние рождение. При рождении процесс получает в свое распоряжение адресное пространство, в которое загружается программный код процесса; ему выделяются стек и системные ресурсы и т. д. Родившийся процесс переводится в состояние готовность. При завершении своей деятельности процесс из состояния исполнение попадает в состояние закончил исполнение.
Для появления в ВС процесс должен пройти через состояние рождение. При рождении процесс получает в свое распоряжение адресное пространство, в которое загружается программный код процесса; ему выделяются стек и системные ресурсы и т. д. Родившийся процесс переводится в состояние готовность. При завершении своей деятельности процесс из состояния исполнение попадает в состояние закончил исполнение.
В конкретных ОС состояния процесса могут быть еще более детализированы, могут появиться некоторые новые варианты переходов из состояния в состояние. Например, модель состояний процессов для операционной системы Windows NT содержит 7 различных состояний, а для операционной системы UNIX — 9. Но все операционные системы подчиняются изложенной выше модели.
Иерархия. В UNIX все процессы, кроме одного, создающегося при старте операционной системы, могут быть порождены только какими-либо другими процессами. В качестве прародителя всех остальных процессов в системах могут выступать процессы с номерами 1 или 0 (в Linux – kernel с номером 0).
Т. о., все процессы в UNIX связаны отношениями процесс-родитель – процесс-ребенок и образуют дерево процессов. Для сохранения целостности дерева в ситуациях, когда процесс-родитель завершает свою работу до завершения выполнения процесса-ребенка, идентификатор родительского процесса в данных ядра процесса-ребенка (PPID – parent process identificator) изменяет свое значение на значение 1, соответствующее идентификатору процесса init, время жизни которого определяет время функционирования операционной системы. Тем самым процесс init как бы усыновляет осиротевшие процессы.
getppid() - идентификатора родительского процесса, getpid() - идентификатора текущего процесса.
Планирование - процесс принятия решения к какой задаче передать управление. Планировщик - отвечающая за это часть ОС.
Алгоритм планирования - используемый алгоритм для планирования.
Ситуации, когда необходимо планирование:
1. Когда создается процесс
2. Когда процесс завершает работу
3. Когда процесс блокируется на операции ввода/вывода, семафоре, и т. д.
4. При прерывании ввода/вывода.
Алгоритм планирования без переключений (неприоритетный) - не требует прерывание по аппаратному таймеру, процесс останавливается только когда блокируется или завершает работу.
Алгоритм планирования с переключениями (приоритетный) - требует прерывание по аппаратному таймеру, процесс работает только отведенный период времени, после этого он приостанавливается по таймеру, чтобы передать управление планировщику.
Переключение процесса — процесс прекращения выполнения процессором одного процесса с сохранением всей необходимой информации и состояния, необходимых для последующего продолжения с прерванного места (контекст), и восстановления и загрузки состояния задачи, к выполнению которой переходит процессор. В процедуру переключения входит планирование задачи.
ЭТО МОЖНО УБРАТЬ:
Переключение процесса тесно связано с контекстом процесса содержит часть информации о процессе, необходимую для возобновления выполнения процесса с прерванного места: содержимое регистров процессора, коды ошибок выполняемых процессором системных вызовов, информация обо всех открытых данным процессом файлах и незавершенных операциях ввода-вывода и другие данные, характеризующие состояние вычислительной среды в момент прерывания.
2.4 Межпроцессное взаимодействие - состояние состязания, критические области. Взаимное исключение с активным ожиданием - алгоритм Петерсона, команда TSL.
Межпроцессное взаимодействие (англ. Inter-Process Communication, IPC) — набор способов обмена данными между множеством потоков в одном или более процессах. Процессы могут быть запущены на одном или более компьютерах, связанных между собой сетью. IPC-способы делятся на методы обмена сообщениями, синхронизации, разделяемой памяти и удаленных вызовов (RPC). Методы IPC зависят от пропускной способности и задержки взаимодействия между потоками и типа передаваемых данных.
IPC также может упоминаться как межпотоковое взаимодействие (англ. inter-thread communication), межпоточное взаимодействие и межпрограммное взаимодействие (англ. inter-application communication).
IPC наряду с концепцией адресного пространства является основой для разграничения адресного пространства.[1]
Состояние состязания
В некоторых операционных системах процессы, работающие совместно, сообща используют некое общее хранилище данных. Каждый из процессов может считывать что-либо из общего хранилища данных и записывать туда информацию. Это хранилище представляет собой участок в основной памяти (возможно, в структуре данных ядра) или файл общего доступа. Местоположение разделяемой памяти не влияет на суть взаимодействия и возникающие проблемы. Рассмотрим межпроцессное взаимодействие на простом, но очень распространенном примере: систему буферизации - "спулер" - печати. Если процессу требуется вывести на печать файл, он помещает имя файла в специальный каталог спулера. Другой процесс, демон печати, периодически проверяет наличие поданных на печать файлов, печатает их и удаляет их имена из каталога.
Представьте, что каталог спулера состоит из большого числа сегментов, пронумерованных последовательно (0, 1, 2, ...), в каждом их которых может храниться имя файла. Также есть две совместно используемые переменные: out, указывающая на следующий файл для печати, и in, указывающая на следующий свободный сегмент. Эти две переменные можно хранить в одном файле (состоящем из двух слов), доступном всем процессам. Пусть в данный момент сегменты с 0 по 3 пусты (эти файлы уже напечатаны), а сегменты с 4 по 6 заняты (эти файлы ждут своей очереди на печать). Более или менее одновременно процессы А и В решают поставить файл в очередь на печать. Описанная ситуация схематически изображена на рис. 2.5.
В соответствии с законом Мерфи (он звучит примерно так: "Если что-то плохое может случиться, оно непременно случится"), возможна следующая ситуация. Процесс А считывает значение (7) переменной in и сохраняет его в локальной переменной next_free_slot. После этого происходит прерывание по таймеру, и процессор переключается на процесс В. Процесс В, в свою очередь, считывает значение переменной in и сохраняет его (опять 7) в своей локальной переменной next_free_slot. В данный момент оба процесса считают, что следующий свободный сегмент - седьмой.
Процесс В сохраняет в каталоге спулера имя файла и заменяет значение in на 8, затем продолжает заниматься своими задачами, не связанными с печатью.
Наконец, управление переходит к процессу А, и он продолжает с того места, на котором остановился. Он обращается к переменной next_free_sbt, считывает ее значение и записывает в седьмой сегмент имя файла (разумеется, удаляя при этом имя файла, помещенное туда процессом В). Затем он заменяет значение in на 8 (next_free_sLot +1 = 8). Структура каталога спулера не нарушена, поэтому демон печати не заподозрит ничего плохого, но файл процесса В не будет напечатан. Пользователь, связанный с процессом В, может в этой ситуации полдня описывать круги вокруг принтера, ожидая результата. Ситуации, в которых два (и более) процесса считывают или записывают данные одновременно и конечный результат зависит от того, какой из них был первым, называются состояниями состязания. Отладка программы, в которой вероятно возникновение состояния состязания, вряд ли может доставить удовольствие. Результаты большинства тестов будут хорошими, но изредка будет происходить нечто странное и необъяснимое.
Критические области
Как избежать состязания? Основным способом предотвращения проблем в этой и любой другой ситуации, связанной с конкурентным использованием памяти, файлов и чего-либо еще, является запрет одновременной записи и чтения данных более чем одним процессом. Говоря иными словами, необходимо взаимное исключение. То есть в тот момент, когда один процесс использует общие данные, другому процессу это делать будет запрещено. Проблема, описанная в предыдущем разделе, возникла из-за того, что процесс В начал работу с одной из совместно используемых переменных до того, как процесс А ее закончил. Выбор подходящей простейшей операции, реализующей взаимное исключение, является серьезным моментом разработки операционной системы, и мы рассмотрим его подробно в дальнейшем.
Проблему исключения состояний состязания можно сформулировать на абстрактном уровне. Некоторый промежуток времени процесс занят внутренними расчетами и другими задачами, не приводящими к состояниям состязания. В другие моменты времени процесс обращается к совместно используемым данным или выполняет какое-то иное действие, чреватое состязанием. Часть программы, в которой происходит обращение к совместно используемым данным, называется критической областью или критической секцией. Если нам удастся избежать одновременного нахождения двух процессов в критических областях, мы сможем избежать состязаний.
Несмотря на то что поставленное требование исключает состязание, его недостаточно для правильной совместной работы параллельных процессов и эффективного использования общих данных. Для этого необходимо выполнение четырех условий.
1. Два процесса не должны одновременно находиться в критических областях.
2. В программе не должно быть предположений о скорости или количестве процессоров.
3. Процесс, в состоянии вне критической области, не может блокировать другие процессы.
4. Недопустима ситуация, в которой процесс вечно ждет попадания в критическую секцию.
Алгоритм Петерсона
Датский математик Деккер (Т. Dekker) был первым, кто разработал программное решение проблемы взаимного исключения, не требующее строгого чередования. Подробное изложение алгоритма можно найти в [7].
В 1981 году Петерсон (G. L. Peterson) придумал существенно более простой алгоритм взаимного исключения. С этого момента вариант Деккера стал считаться устаревшим. Алгоритм Петерсона, представленный в листинге 2.1, состоит из двух процедур, написанных на ANSI С, что предполагает необходимость прототипов для всех определяемых и используемых функций. В целях экономии места мы не будем приводить прототипы для этого и последующих примеров.
Листинг 2.1. Решение Петерсона для взаимного исключения
#define FALSE О #define TRUE 1
Idefine N 2 /* Количество процессов */
int turn: /* Чья сейчас очередь? */
int interested[N]: /* Все переменные изначально
/* равны О (FALSE) */
void enterj"egion(int process): /* Процесс 0 или 1 */
{
int other: /* Номер второго процесса */
other = 1 - process: /* "противоположный" процесс */
interested[process] = TRUE: /* Индикатор интереса */
turn = process: /* Установка флага */
while (turn == process && interested[other] == TRUE) /* Пустой цикл */:
}
void leave_region(int process) /* Процесс, покидающий
/* критическую область */
{
interested[process] = FALSE: /* Индикатор выхода из
/* критической области */
}
Прежде чем обратиться к совместно используемым переменным (то есть перед тем, как войти в критическую область), процесс вызывает процедуру enter_region со своим номером (0 или 1) в качестве аргумента. Поэтому процессу при необходимости придется подождать, прежде чем входить в критическую область. После выхода из критической области процесс вызывает процедуру leave_region, чтобы обозначить свой выход и тем самым разрешить другому процессу вход в критическую область.
Рассмотрим работу алгоритма более подробно. Исходно оба процесса находятся вне критических областей. Процесс 0 вызывает enter_region, задает элементы массива и устанавливает переменную turn равной 0. Поскольку процесс 1 не заинтересован в попадании в критическую область, происходит возврат из процедуры. Теперь, если процесс 1 вызовет enterjregion, ему придется подождать, пока interested [0] примет значение FALSE, а это произойдет только в тот момент, когда процесс 0 вызовет процедуру leave_region при покидании критической области.
Представьте, что оба процесса вызвали enter_region практически одновременно. Оба запомнят свои номера в turn. Но сохранится номер того процесса, который был вторым, а предыдущий номер будет утерян. Предположим, что вторым был процесс 1, отсюда значение turn равно 1. Когда оба процесса дойдут до конструкции while, процесс 0 войдет в критическую область, а процесс 1 останется в цикле и будет ждать, пока процесс 0 выйдет из нее.
Команда TSL
Рассмотрим решение, требующее участия аппаратного обеспечения. Многие компьютеры, особенно разработанные с расчетом на несколько процессоров, имеют команду Test and Set Lock (TSL) - "проверить и заблокировать", которая действует следующим образом. В регистр считывается содержимое слова памяти, а затем в этой ячейке памяти сохраняется ненулевое значение. Гарантируется, что операция считывания слова и сохранения неделима - другой процесс не может обратиться к слову в памяти, пока команда не выполнена. Процессор, выполняющий команду tsl, блокирует шину памяти, препятствуя обращениям к памяти со стороны остальных процессоров.
Воспользуемся командой tsl. Пусть разделяемая переменная lock управляет доступом к общей памяти. Если значение lock равно 0, любой процесс может изменить его на 1 и обратиться к общей памяти, а затем вернуть его обратно в 0, пользуясь обычной командой типа move.
Как использовать команду tsl для реализации взаимного исключения? Решение приведено в листинге 2.2. Здесь представлена подпрограмма из четырех команд, написанная на некотором обобщенном (но типичном) ассемблере. Первая команда копирует старое значение lock в регистр и затем устанавливает значение переменной в 1. Потом старое значение сравнивается с нулем. Если оно ненулевое, значит, блокировка уже была произведена, и проверка начинается сначала. Рано или поздно значение окажется нулевым (это означает, что процесс, находившийся в критической области, покинул ее), и подпрограмма вернет управление в вызвавшую программу, установив блокировку. Сброс блокировки не представляет собой ничего сложного - просто помещается 0 в переменную lock. Специальной команды процессора не требуется.
Листинг 2.2. Вход и выход из критической области с помощью команды tsl
enter_region:
tsT register. lock /* значение lock копируется в регистр */
/* значение переменной устанавливается равным 1 */ cmp register,#0 /* Старое значение lock сравнивается с нулей */ jne enter^region /* Если оно ненулевое, значит, блокировка уже была */
/* установлена, поэтому цикл */ ret /* Возврат в вызывающую программу */
/* процесс вошел в критическую область */ leave_region;
move lock.#0 /* Сохранение 0 в переменной lock */ ret
Одно решение проблемы критических областей теперь очевидно. Прежде чем попасть в критическую область, процесс вызывает процедуру enter_region, которая выполняет активное ожидание вплоть до снятия блокировки, затем она устанавливает блокировку и возвращает управление. По выходу из критической области процесс вызывает процедуру leave_region, помещающую 0 в переменную Lock. Как и во всех остальных решениях проблемы критической области, для корректной работы процесс должен вызывать эти процедуры своевременно, в противном случае исключить взаимное исключение не удастся.
2.5. Семафоры - средство управления процессами
Семафоры традиционно использовались для синхронизации процессов, обращающихся к разделяемым данным. Каждый процесс должен исключать для всех других процессов возможность одновременно с ним обращаться к этим данным (взаимоисключение). Когда процесс обращается к разделяемым данным, говорят, что он находится в своем критическом участке.
Для решения задачи синхронизации необходимо, в случае если один процесс находится в критическом участке, исключить возможность вхождения для других процессов в их критические участки. Хотя бы для тех, которые обращаются к тем же самым разделяемым данным. Когда процесс выходит из своего критического участка, то одному из остальных процессов, ожидающих входа в свои критические участки, должно быть разрешено продолжить работу.
Процессы должны как можно быстрее проходить свои критические участки и не должны в этот период блокироваться. Если процесс, находящийся в своем критическом участке, завершается (возможно, аварийно), то необходимо, чтобы некоторый другой процесс мог отменить режим взаимоисключения, предоставляя другим процессам возможность продолжить выполнение и войти в свои критические участки.
Семафор - это защищенная переменная, значение которой можно опрашивать и менять только при помощи специальных операций wait и signal и операции инициализации init. Двоичные семафоры могут принимать только значения 0 и 1. Семафоры со счетчиками могут принимать неотрицательные целые значения.
Операция wait(s) над семафором s состоит в следующем:
если s > 0 то s:=s-1 иначе (ожидать на s)
а операция signal(s) заключается в том, что:
если (имеются процессы, которые ожидают на s)
то (разрешить одному из них продолжить работу)
иначе s:=s+1
Операции являются неделимыми. Критические участки процессов обрамляются операциями wait(s) и signal(s). Если одновременно несколько процессов попытаются выполнить операцию wait(s), то это будет разрешено только одному из них, а остальным придется ждать.
Семафоры со счетчиками используются, если некоторые ресурс выделяется из множества идентичных ресурсов. При инициализации такого семафора в его счетчике указывается число элементов множества. Каждая операция wait(s) уменьшает значения счетчика семафора s на 1, показывая, что некоторому процессу выделен один ресурс из множества. Каждая операция signal(s) увеличивает значение счетчика на 1, показывая, что процесс возвратил ресурс во множество. Если операция wait(s) выполняется, когда в счетчике содержится нуль (больше нет ресурсов), то соответствующий процесс ожидает, пока во множество не будет возвращен освободившийся ресурс, то есть пока не будет выполнена операция signal.
2.6 Принципы организации мониторов.
Межпроцессное взаимодействие с применением семафоров выглядит довольно просто, не правда ли? Эта простота кажущаяся. Взгляните внимательнее на порядок выполнения процедур down перед помещением или удалением элементов из буфера в листинге 2.4. Представьте себе, что две процедуры down в программе производителя поменялись местами, так что значение mutex было уменьшено раньше, чем empty. Если буфер был заполнен, производитель блокируется, сбросив mutex в 0. Соответственно, в следующий раз, когда потребитель обратится к буферу, он выполнит down с переменной mutex, равной 0, и тоже заблокируется. Оба процесса заблокированы навсегда. Эта неприятная ситуация называется взаимоблокировкой, и мы вернемся к ней в главе 3.
Вышеизложенная ситуация показывает, с какой аккуратностью нужно обращаться с семафорами. Одна маленькая ошибка, и все останавливается. Это напоминает программирование на ассемблере, но на самом деле еще сложнее, поскольку такие ошибки приводят к абсолютно невоспроизводимым и непредсказуемым состояниям состязания, взаимоблокировкам и т. п.
Чтобы упростить написание программ, в 1974 году Хоар (Ноаге) [43] и Бринч Хансен (Brinch Hansen) предложили примитив синхронизации более высокого уровня, называемый монитором. Их предложения несколько отличались друг от друга, как мы увидим дальше. Монитор - набор процедур, переменных и других структур данных, объединенных в особый модуль или пакет. Процессы могут вызывать процедуры монитора, но у процедур, объявленных вне монитора, нет прямого доступа к внутренним структурам данных монитора. В листинге 2.5 представлен монитор, написанный на воображаемом языке, некоем "местечковом диалекте" - "пиджин" Pascal.
Листинг 2.5. Монитор
monitor example integer i: condition с:
procedure producer():
end:
procedure consumer*):
end; end monitor:
Реализации взаимных исключений способствует важное свойство монитора: при обращении к монитору в любой момент времени активным может быть только один процесс. Мониторы являются структурным компонентом языка программирования, поэтому компилятор знает, что обрабатывать вызовы процедур монитора следует иначе, чем вызовы остальных процедур. Обычно при вызове процедуры монитора первые несколько команд процедуры проверяют, нет ли в мониторе активного процесса. Если таковой есть, вызывающему процессу придется подождать, в противном случае запрос удовлетворяется.
Реализация взаимного исключения зависит от компилятора, но обычно используется двоичный семафор. Поскольку взаимное исключение обеспечивает компилятор, а не программист, вероятность ошибки гораздо меньше. В любом случае программист, пишущий код монитора, не должен задумываться о том, как компилятор организует взаимное исключение. Достаточно знать, что обеспечив попадание в критические области через процедуры монитора, можно не бояться нахождения в критических областях двух процессов одновременно.
Хотя мониторы предоставляют простой способ реализации взаимного исключения, этого недостаточно. Необходим также способ блокировки процессов, которые не могут продолжать свою деятельность. В случае проблемы производителя и потребителя достаточно просто поместить все проверки буфера на не-пустоту и пустоту в процедуры монитора, но как процесс заблокируется, обнаружив полный буфер?
Решение заключается в переменных состояния и двух операциях, wait и signal Когда процедура монитора обнаруживает, что она не в состоянии продолжать работу (например, производитель выясняет, что буфер заполнен), она выполняет операцию wait на какой-либо переменной состояния, скажем, full. Это приводит к блокировке вызывающего процесса и позволяет другому процессу войти в монитор.
Другой процесс, в нашем примере потребитель, может активизировать ожидающего напарника, например, выполнив операцию signal на той переменной состояния, на которой он был заблокирован. Чтобы в мониторе не оказалось двух активных процессов одновременно, нам необходимо правило, определяющее последствия операции signal. Xoap предложил запуск "разбуженного" процесса и остановку второго. Бринч Хансен придумал другое решение: процесс, выполнивший signal, должен немедленно покинуть монитор. Иными словами, операция signal выполняется только в самом конце процедуры монитора. Мы будем использовать это решение, поскольку оно в принципе проще и к тому же легче в реализации. Если операция signal выполнена на переменной, с которой связаны несколько заблокированных процессов, планировщик выбирает и "оживляет" только один из них.
Кроме этого, существует третье решение, не основывающееся на предположениях Хоара и Хансена: позволить процессу, выполнившему signal, продолжать работу и запустить ждущий процесс только после того, как первый процесс покинет монитор.
Переменные состояния не являются счетчиками. В отличие от семафоров они не аккумулируют сигналы, чтобы впоследствии воспользоваться ими. Это означает, что в случае выполнения операции signal на переменной состояния, с которой не связано ни одного блокированного процесса, сигнал будет утерян. Проще говоря, операция wait должна выполняться прежде, чем signal. Последнее правило существенно упрощает реализацию. На практике оно не создает проблем, поскольку отслеживать состояния процессов при необходимости не очень трудно. Процесс, который собирается выполнить signal, может оценить необходимость этого действия по значениям переменных.
В листинге 2.6 представлена схема решения проблемы производителя и потребителя с применением мониторов, написанная на "пиджин" Pascal. В данной ситуации этот суррогат языка удобен своей простотой, а также тем, что он позволяет в точности следовать моделям Хоара и Хансена. В каждый момент времени активна только одна процедура монитора. Буфер состоит из N сегментов.
Листинг 2.6. Схема решения проблемы производителя и потребителя с применением мониторов
monitor ProducerConsumer
condition full. empty: integer count:
procedure insertUtem: integer): begin
if count = N then wait(full):
insert_item(item);
count := count+1;
if count = 1 then signal(empty) end:
2.2. Межпроцессное взаимодействие 93
function remove: integer: begin
if count - 0 then wait(empty);
remove - remove_item:
count := count-1:
if count = N-l then signal(full) end:
count := 0; end monitor;
procedure producer: begin
while true do begin
item = produce_item; ProducerConsumer. i nsert(i tern) end end:
procedure consumer: begin
while true do begin
item = ProducerConsumer. remove: consume_item(item) end end:
Можно подумать, что операции wait и signal похожи на sleep и wakeup, которые приводили к неустранимым состояниям конкуренции. Они действительно похожи, но с одним существенным отличием: неудачи применения операций sleep и wakeup были связаны с тем, что один процесс пытался уйти в состояние ожидания, в то время как другой процесс предпринимал попытки активизировать его. С мониторами такого произойти не может. Автоматическое взаимное исключение, реализуемое процедурами монитора, гарантирует: если производитель, находящийся в мониторе, обнаружит полный буфер и решит выполнить операцию wait, можно не опасаться, что планировщик передаст управление потребителю раньше, чем операция wait будет завершена. Потребитель даже не сумеет попасть в монитор, пока операция wait не будет выполнена и производитель не прекратит работу.
Благодаря автоматизации взаимного исключения применение мониторов сделало параллельное программирование значительно менее подверженным ошибкам, в отличие от применения семафоров. Но и у мониторов тоже есть свои недостатки. Недаром два примера мониторов, которые мы рассмотрели, были написаны на "пиджин" Pascal, а не на С, как все остальные примеры этой книги. Как мы уже говорили, мониторы являются структурным компонентом языка программирования, и компилятор должен их распознавать и организовывать взаимное исключение. В Pascal, С и многих других языках нет мониторов, поэтому странно было бы ожидать от их компиляторов выполнения правил взаимного исключения. И в самом деле, как отличить компилятор процедуры монитора от остальных?
Другая проблема, связанная с мониторами и семафорами, состоит в том, что они были разработаны для решения задачи взаимного исключения в системе с одним или несколькими процессорами, имеющими доступ к общей памяти. Помещение семафоров в разделенную память с защитой в виде команд TSL может исключить состояния состязания. Эти примитивы будут неприменимы в распределенной системе, состоящей из нескольких процессоров с собственной памятью у каждого, связанных локальной сетью. Вывод из всего вышесказанного следующий: семафоры являются примитивами слишком низкого уровня, а мониторы применимы только в некоторых языках программирования. Примитивы не подходят и для реализации обмена информацией между компьютерами - нужно что-то другое.
2.7. Управление памятью - вычисление физического адреса в реальном и виртуальном режимах. Регистры преобразования адреса, назначение и использование теневых регистров. Дескрипторы сегментов
Управление памятью
Ключевым моментом управления памятью в процессоре 80286 является преобразование адреса, т. е. превращение адресов, используемых программами, в адреса, воспринимаемые схемами памяти. Напомним, что указатель в процессоре 80286 (и в микропроцессорах 8086, 8088 и 80186) имеет длину 32 бита.
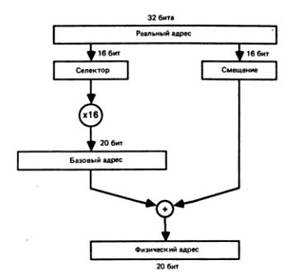 Он состоит из 16-битного селектора сегмента и 16-битного смещения в выбранном сегменте. Когда указатель находится в памяти, смещение содержится по меньшему адресу, а затем размещается селектор сегмента, адрес которого на 2 больше. Это соответствует соглашению о хранении более значимых величин по большим адресам. Но, как мы видели в гл. 2, наиболее часто два компонента указателя разделены, причем селектор находится в сегментном регистре, а смещение либо вычисляется в соответствии с режимом адресации операнда (прямая, база + смещение и др.), либо находится в регистре (IP, BP и др.) Этот принцип действует в реальном и виртуальном режимах работы процессора 80286, Однако оба режима различаются тем, каким образом из селектора и смещения образуется физический адрес памяти. Под физическим адресом мы понимаем то единственное число, которое передается в память для обращения к ней.
Он состоит из 16-битного селектора сегмента и 16-битного смещения в выбранном сегменте. Когда указатель находится в памяти, смещение содержится по меньшему адресу, а затем размещается селектор сегмента, адрес которого на 2 больше. Это соответствует соглашению о хранении более значимых величин по большим адресам. Но, как мы видели в гл. 2, наиболее часто два компонента указателя разделены, причем селектор находится в сегментном регистре, а смещение либо вычисляется в соответствии с режимом адресации операнда (прямая, база + смещение и др.), либо находится в регистре (IP, BP и др.) Этот принцип действует в реальном и виртуальном режимах работы процессора 80286, Однако оба режима различаются тем, каким образом из селектора и смещения образуется физический адрес памяти. Под физическим адресом мы понимаем то единственное число, которое передается в память для обращения к ней.
Вычисление физического адреса в реальном режиме.
Это действие уже рассматривалось, поэтому здесь мы только напомним о нем. В реальном режиме 32-битный указатель называется реальным адресом.
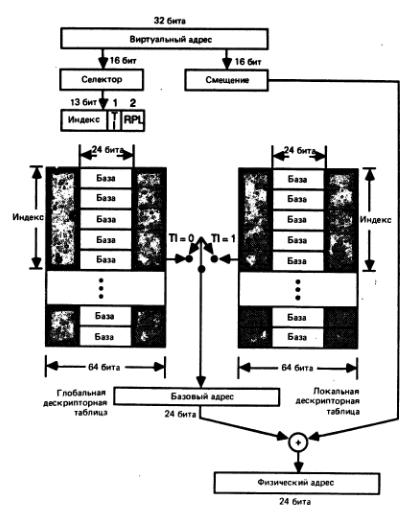 На рисунке показано преобразование реального адреса в физический. Шестнадцатибитный селектор сдвигается на 4 бита влево (т. е. умножается на 16), определяя 20-битный базовый адрес сегмента. Затем к базовому адресу прибавляется 16-битное смещение и в результате получается 20-битный физический адрес При сложении переполнение игнорируется. Несмотря на то, что 16-битные селектор и смещение допускают 216 сегментов по 216 байт, результирующее адресное пространство составляет на 216 х 216 = 232 (около 4 млрд.) байт, а всего 220 (около 1 млн.) байт. Объясняется это перекрытием сегментов. Например, два реальных адреса с парами (селектор, смещение) = (2, 5) и (1, 21) соответствуют одному и тому же физическому адресу 37. Чтобы получить большее адресное пространство, допускаемое 32-битным указателем, требуется другой способ преобразования адреса.
На рисунке показано преобразование реального адреса в физический. Шестнадцатибитный селектор сдвигается на 4 бита влево (т. е. умножается на 16), определяя 20-битный базовый адрес сегмента. Затем к базовому адресу прибавляется 16-битное смещение и в результате получается 20-битный физический адрес При сложении переполнение игнорируется. Несмотря на то, что 16-битные селектор и смещение допускают 216 сегментов по 216 байт, результирующее адресное пространство составляет на 216 х 216 = 232 (около 4 млрд.) байт, а всего 220 (около 1 млн.) байт. Объясняется это перекрытием сегментов. Например, два реальных адреса с парами (селектор, смещение) = (2, 5) и (1, 21) соответствуют одному и тому же физическому адресу 37. Чтобы получить большее адресное пространство, допускаемое 32-битным указателем, требуется другой способ преобразования адреса.
Вычисление физического адреса в виртуальном режиме.
В виртуальном режиме 32-битный указатель называется виртуальным адресом. Он, как и реальный адрес, состоит из 16-битных селектора и смещения. По-прежнему селектор определяет базовый адрес сегмента, к которому для получения физического адреса прибавляется смещение. Но вместо образования базового адреса сегмента путем сдвига селектора влево на 4 бита базовый адрес получается посредством обращения (индексирования) к таблице в памяти, что показано. Селектор виртуального адреса состоит из трех полей: запрашиваемый уровень привилегий RPL, индикатор таблицы TI и индекс. Поле RPL использ. операцион. системой для решения рассматриваемой далее проблемы "троянского коня".
Это поле на участвует в преобразовании адреса и обсуждается в разделе по кольцам защиты. Поле индикатора таблицы показывает, какая из двух таблиц привлекается для поиска базового адреса. Если TI = 0, то используется глобальная дескрипторная таблица GDT. Система с процессором 80286 имеет одну таблицу GDT, которая разделяется всеми задачами. Если TI = 1, то используется локальная дескрипторная таблица LDT, причем каждая задача имеет свою LDT. Следовательно, базовые адреса сегментов, разделяемых всеми задачами, хранятся в GDT, a базовые адреса "частных" сегментов каждой задачи находятся в LDT. Поле индекса селектора служит индексом выбранной таблицы. Каждый элемент таблицы называется дескриптором. Таблица индексируется с нуля и значение i поля индекса относится к i-му дескриптору в таблице. Дескрипторы имеют длину 8 байт и каждый из них содержит 24-битный базовый адрес соответствующего сегмента, т. е. он занимает 3 байта из 8. Назначение остальных байт дескриптора мы рассмотрим в дальнейшем. Полученный из выбранного дескриптора 24-битный базовый адрес суммируется с 16-битным смещением, в результате чего получается 24-битный физический адрес. Переполнение при сложении игнорируется.
Регистры преобразования адреса, назначение и использование теневых регистров
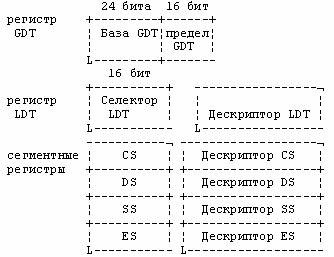 На рис.3 показаны все регистры преобразования адреса и их теневые
На рис.3 показаны все регистры преобразования адреса и их теневые
регистры
Рис.3. Регистры преобразования адреса
Когда селектор загружает в сегментный регистр, соответствующий дескриптор автоматически загружается в его теневой регистр.
Т. о. в виртуальном режиме происходит преобразование виртуального адреса в физический. Виртуальный адрес состоит из сеслектора, по которому процессор может определить адрес базы сегмента и значение смещения, которое складывается с базовым адресом. Селектор определяет соответствующий базовый адрес сегмента путем обращения к таблице. Один бит селектора показывает нужно ли использовать таблицу глобальную для всей системы, или локальную для текущей задачи. Селектор содержит также индекс, который позволяет получить дескриптор сегмента. Этот адрес содержит адрес базы выбранного сегмента. Каждый селектор обращается к соответствующему дескриптору, а дескриптор к соответствующему сегменту. Чтобы ускорить обращение к памяти, при загрузке селектора в сегментный регистр соответствующий дескриптор автоматически загружается в теневой регистр этого сегментного регистра. Дальнейшее обращение к памяти через сегментный регистр не требует обращения к таблице, т. к. базовый адрес выбранного сегмента находится в теневом регистре.
Дескриптор сегмента — служебная структура в памяти, которая определяет сегмент. Длина дескриптора равна восьми байтам.
 Структура сегментного дескриптора
Структура сегментного дескриптора
§ База (жёлтые поля, 32 бита) — начало сегмента в линейной памяти
§ Лимит (красные поля, 20 бит) — (размер сегмента в байтах)-1 (База+Лимит = линейный адрес последнего байта)
§ Права доступа (синие поля, 12 бит) — флаги, определяющие наличие сегмента в памяти, уровень защиты, тип, разрядность + один пользовательский флаг
Байт прав доступа (AR, англ. Access Rights, биты 8-15 на рисунке):
§ Бит P определяет доступность сегмента (0 — сегмента нет, 1 — есть). При обращении к сегменту со сброшенным битом P происходит исключение #NP, обработчик которого может загрузить/создать сегмент.
§ Номер привилегий DPL содержит 2-битный номер (0-3), определяющий, к какому уровню (кольцу) защиты относится этот сегмент.
§ Тип сегмента (биты 8-12 на рисунке). Старший бит (S) определяет сегмент как системный (S=0) или пользовательский (S=1). Значение прочих бит для системных и пользовательских сегментов описано в таблице:
Типы системных сегментов | ||||||
№ | Биты AR | Описание |
| |||
3 | 2 | 1 | 0 |
| ||
0 | 0 | 0 | 0 | 0 | Зарезервировано |
|
1 | 0 | 0 | 0 | 1 | Свободный 16-битный TSS |
|
2 | 0 | 0 | 1 | 0 | LDT |
|
3 | 0 | 0 | 1 | 1 | Занятый 16-битный TSS |
|
4 | 0 | 1 | 0 | 0 | 16-битный шлюз вызова |
|
5 | 0 | 1 | 0 | 1 | Шлюз задачи |
|
6 | 0 | 1 | 1 | 0 | 16-битный шлюз прерывания |
|
7 | 0 | 1 | 1 | 1 | 16-битный шлюз ловушки |
|
8 | 1 | 0 | 0 | 0 | Зарезервировано |
|
9 | 1 | 0 | 0 | 1 | Свободный 32-битный TSS |
|
A | 1 | 0 | 1 | 0 | Зарезервировано |
|
B | 1 | 0 | 1 | 1 | Занятый 32-битный TSS |
|
C | 1 | 1 | 0 | 0 | 32-битный шлюз вызова |
|
D | 1 | 1 | 0 | 1 | Зарезервировано |
|
E | 1 | 1 | 1 | 0 | 32-битный шлюз прерывания |
|
F | 1 | 1 | 1 | 1 | 32-битный шлюз ловушки |
|
Типы пользовательских сегментов | |||||
№ | Биты AR | Описание |
| ||
3 | 2 | 1 |
| ||
0 | 0 | 0 | 0 | Сегмент данных только для чтения |
|
2 | 0 | 0 | 1 | Сегмент данных для чтения/записи |
|
4 | 0 | 1 | 0 | Сегмент данных только для чтения, растёт вниз |
|
6 | 0 | 1 | 1 | Сегмент данных для чтения/записи, растёт вниз |
|
8 | 1 | 0 | 0 | Сегмент кода только для выполнения |
|
A | 1 | 0 | 1 | Сегмент кода для выполнения/чтения |
|
C | 1 | 1 | 0 | Подчинённый сегмент кода только для выполнения |
|
E | 1 | 1 | 1 | Подчинённый сегмент кода для выполнения/чтения |
|
Младший бит байта AR пользовательских сегментов (A, англ. Accessed, бит 8 на рисунке) можно использовать для сбора статистики о сегменте. При первом же обращении ксегменту (чтение, запись, выполнение) он устанавливается процессором в 1.
§ Флаг гранулярности G определяет лимит сегмента: при G=0 лимит равен значению соответствующего поля в дескрипторе, а при G=1 лимит равен полю дескриптора, умноженному на (212 = 4096). Таким образом при G=0 максимальный размер сегмента 1 МБайт, а при G=1 4 ГБайт.
§ Флаг разрядности DB (бит 22 на рисунке) актуален для пользовательских сегментов кода и стека. Определяет разрядность в 16 бит при нулевом и 32 бит при единичном значении.
§ Зарезервированный флаг (серое поле) должен всегда равняться нулю.
§ Пользовательский флаг AVL (A, бит 20 на рисунке) отдан операционной системе. Его состояние никак не влияет на работу с сегментом.
