

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Интерфейсы функций (Integral1DMK_par(…), Integral1DMK_par1(…), Integral1DMK_par2(…)), реализующих все три алгоритма приведены в приложении 3, а их реализации – в приложении 4.
Рассмотрим все три алгоритма.
1. Алгоритм, в основе которого лежит скалярный параллелизм, т. е. распараллеливание цикла, реализован в функции Integral1DMK_par(…). В этом алгоритме генерация чисел осуществляется с некоторым шагом равным отношению интервала интегрирования к количеству генерируемых точек. Это позволяет, по мере уменьшения шага, добиваться равномерного распределения чисел по оси координат. Как следствие – увеличение сходимости метода, а также повышение точности вычислений.
В этом алгоритме каждый процесс выполняет следующие основные шаги:
ü Получение количества запущенных процессов, получение процессом своего номера.
ü Начало внешнего цикла.
ü Инициализация переменных, содержащих значение интеграла на двух соседних итерациях (для проверки условия выхода).
ü Инициализация генератора псевдослучайных чисел номером процесса и текущим временем.
ü Вычисление шага, с которым ведется генерация чисел.
ü Параллельный внутренний цикл, в котором вычисляется случайная точка, значение функции в этой точке и накапливается частичная сумма. В цикле каждый процесс совершает, в среднем, totpt / totproc итераций (totproc – количество запущенных процессов, totpt – количество генерируемых точек). В таблице 3.2.1 показан пример распределения итераций цикла по процессам для 6-ти процессорной группы (totproc = 6) и totpt = 20:
Таблица 3.2.1.
Процессы | ||||||
0 | 1 | 2 | 3 | 4 | 5 | |
Итерации | 1 | 2 | 3 | 4 | 5 | 6 |
7 | 8 | 9 | 10 | 11 | 12 | |
13 | 14 | 15 | 16 | 17 | 18 | |
19 | 20 | - | - | - | - |
ü Синхронизация всех процессов.
ü Объединение частичных сумм всех процессов.
ü Вычисление корневым процессом значения интеграла.
ü Синхронизация процессов.
ü Широковещание всем процессам из корневого процесса значения интеграла.
ü Увеличение числа генерируемых точек для следующего прохода внешнего цикла.
ü Проверка условия выхода. Если ложь – прервать внешний цикл, если истина – продолжить внешний цикл с увеличенных количеством генерируемых точек.
ü Возвращение функцией полученного значения интеграла.
2. Алгоритм, в основе которого лежит идея сужения интервала интегрирования для каждого процесса (процессорный интервал), реализован в функции Integral1DMK_par1(…). В этом алгоритме, как и в предыдущем, генерация чисел осуществляется с некоторым шагом равным отношению интервала интегрирования L к количеству генерируемых точек. Здесь каждый процесс вычисляет интеграл на своем участке (частичный интеграл), а затем эти значения объединяются операцией редукции. Это позволяет, как и в предыдущем алгоритме, по мере уменьшения шага, добиваться равномерного распределения чисел по оси координат, а также точнее изучить поведение функции на узком интервале. Как следствие – увеличение сходимости метода, а также повышение точности вычислений.
В этом алгоритме каждый процесс выполняет следующие основные шаги:
ü Получение количества запущенных процессов, получение процессом своего номера.
ü Вычисление переменных, определяющих рабочие интервалы каждого процесса.
ü Начало внешнего цикла.
ü Инициализация переменных, содержащих значение интеграла на двух соседних итерациях (для проверки условия выхода).
ü Инициализация генератора псевдослучайных чисел номером процесса и текущим временем.
ü Вычисление шага, с которым ведется генерация чисел.
ü Внутренний цикл, в котором вычисляется случайная точка, значение функции в этой точке и накапливается частичная сумма.
ü Вычисление процессом частичного интеграла на узком промежутке.
ü Увеличение числа генерируемых точек для следующего прохода внешнего цикла.
ü Синхронизация всех процессов.
ü Объединение частичных интегралов всех процессов.
ü Синхронизация процессов.
ü Широковещание из корневого процесса интеграла на L всем процессам.
ü Проверка условия выхода. Если ложь – прервать внешний цикл, если истина – продолжить внешний цикл с увеличенных количеством генерируемых точек.
ü Возвращение функцией полученного значения интеграла.
3. Алгоритм, в основе которого лежит идея сужения интервала интегрирования для каждого процесса и вычисление полного интеграла на этом участке, реализован в функции Integral1DMK_par2(…). В этом алгоритме, как и в предыдущих, генерация чисел осуществляется с некоторым шагом равным отношению интервала интегрирования L к количеству генерируемых точек. Здесь каждый процесс вычисляет интеграл на своем участке до тех пор, пока не получит значения с заданной точностью, а затем эти значения объединяются операцией редукции после завершения внешнего цикла. Это позволяет, как и в предыдущих алгоритмах по мере уменьшения шага, добиваться равномерного распределения чисел по оси координат, а также точнее изучить поведение функции на узком интервале. Кроме того, обмен сообщениями осуществляется только один раз. Как следствие – увеличение сходимости метода, повышение точности вычислений и уменьшение времени вычислений на некоторых классах функций.
В этом алгоритме каждый процесс выполняет следующие основные шаги:
ü Получение количества запущенных процессов, получение процессом своего номера.
ü Вычисление переменных, определяющих рабочие интервалы каждого процесса.
ü Начало внешнего цикла.
ü Инициализация переменных, содержащих значение интеграла на двух соседних итерациях (для проверки условия выхода).
ü Инициализация генератора псевдослучайных чисел номером процесса и текущим временем.
ü Вычисление шага, с которым ведется генерация чисел.
ü Внутренний цикл, в котором вычисляется случайная точка, значение функции в этой точке и накапливается частичная сумма.
ü Вычисление процессом частичного интеграла на узком промежутке.
ü Увеличение числа генерируемых точек для следующего прохода внешнего цикла.
ü Проверка условия выхода. Если ложь – прервать внешний цикл, если истина – продолжить внешний цикл с увеличенных количеством генерируемых точек.
ü Синхронизация процессов.
ü Редукция полных интегралов на всех процессорных интервалах.
ü Возвращение функцией полученного значения интеграла.
Временные диаграммы синхронных вычислительных процессов с независимыми ветвями приведены на рис. 3.2.3.
Еще раз подчеркнем, что для увеличения сходимости метода существенную роль играет, состав последовательности псевдослучайных чисел или, иными словами, ее качество.
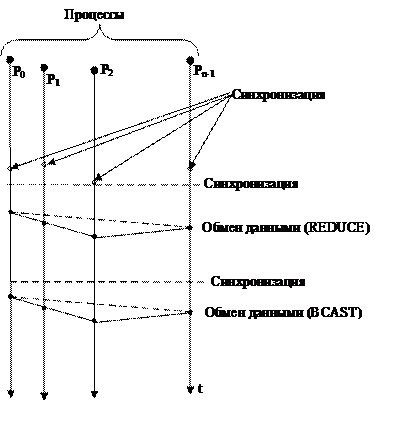
Рис. 3.2.3 |
3.3. Эксперимент. Анализ эффективности
некоторых из реализованных алгоритмов
Были проведены исследования эффективности разработанных алгоритмов на кластере MPI, с компонентами: процессор – Pentium 1 Ггц, ОЗУ – 128 Мб, сеть – Fast Ethernet.
![]() В экспериментах тестировалась подынтегральная функция. Пределы интегрирования составляли a = 0, b = 1e6. По результатам тестирования были получены кривые 3.3.1 и 3.3.2.
В экспериментах тестировалась подынтегральная функция. Пределы интегрирования составляли a = 0, b = 1e6. По результатам тестирования были получены кривые 3.3.1 и 3.3.2.
В таблице 3.3.1 приведены результаты тестирования алгоритмов на различных функциях. Сравнивались результаты вычисления на 1 и 5 процессорных системах
Таблица 3.3.1
Функция | a | b | t, с (1 проц.) | t, с (5 проц.) |
| 2 | 4 | 0,001784 | 0,007947 |
sinx/x | 0,0000001 | 1 | 0,000555 | 0,002694 |
x3 | -100 | 100 | 75,140435 | 7,556625 |
| 0 | 3 | 39,392135 | 15,766564 |
| 0 | 100000 | 6,454987 | 2,638202 |
100 | -0,0010000 | 1000 | 0,004833 | 0,00334 |
| 0 | 1000000 | 131,795787 | 20,773000 |
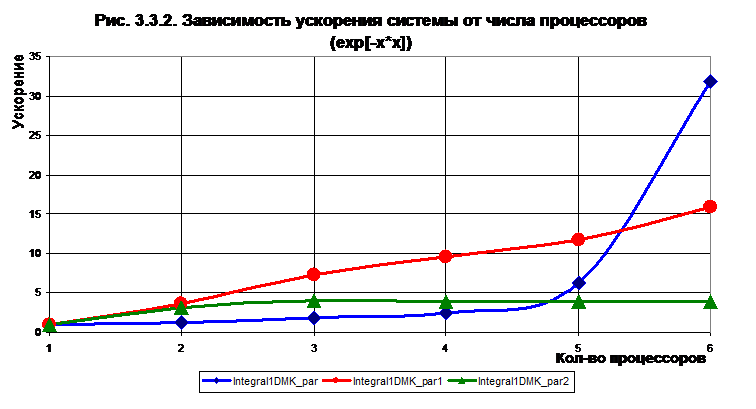
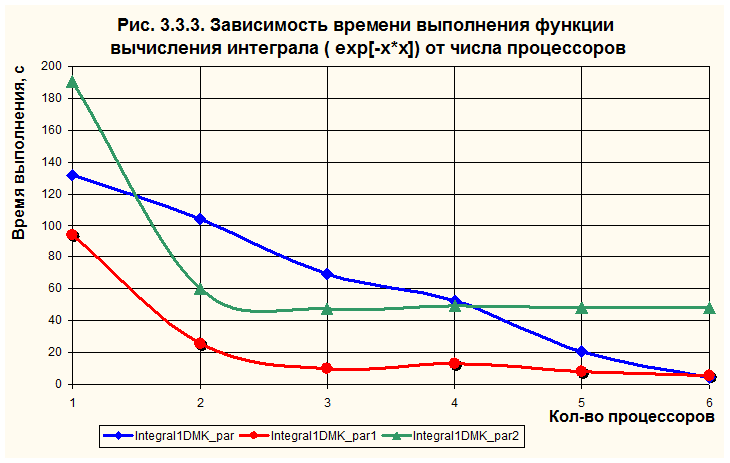
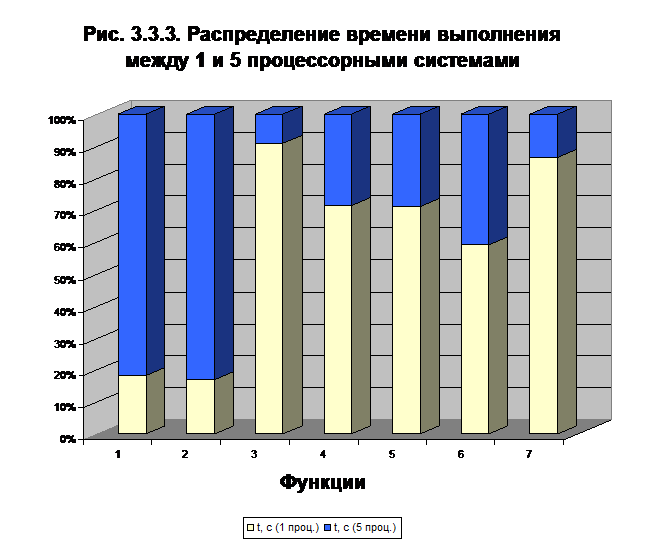
По результатам экспериментов были сделаны следующие выводы:
1. Алгоритм 1 работает наиболее эффективно со сложными функциями в широком диапазоне L. В то время как остальные заметно уступают ему в работе с такими функциями.
2. Для небольших функций в небольших пределах L 3-ий алгоритм работают быстрее других, т. к. содержит только одну операцию обмена данными. Для того же класса функций 1-ый алгоритм проигрывает, т. к. время, затраченное на обмен данными оказывается больше времени вычислений.
Таким образом, для вычислений интегралов могут быть использованы все три алгоритма – в зависимости от класса функции и пределов интегрирования.
ЗАКЛЮЧЕНИЕ
В заключении хотим отметить следующее.
1. Полученные алгоритмы легко обобщаются на случай многомерных пространств. Это осуществляется путем генерации в функции чисел, отвечающих за нужную координату. Так, в приложениях 3, 4 приведены тексты функций, реализующих вычисление двойных интегралов на последовательной и параллельной ЭВМ.
2. Для вычисления n-кратного интеграла необходимо знать величину n-1-кратного интеграла. Поэтому при расчете интегралов высокой кратности необходимо рассчитывать распределение вычислений по процессам особенно тщательно. Для решения этой проблемы в MPI предусмотрены виртуальная топология, группы, коммуникаторы.
3. Вследствие низкой сходимости метода Монте-Карло целесообразно применять его только при расчетах интегралов кратности 2 и выше.
ЛИТЕРАТУРА
1. Бахвалов методы. – М.: «Наука», 1975. – 631 с.
2. Конкретная математика. – М.: «Мир», 1998. – 703 с.
3. Демидович задач и упражнений по математическому анализу. – М.: «Наука», 1972. – 544 с.
4. , Марон вычислительной математики. – М.: «Наука», 1966. – 664 с.
5. Информатика. Энциклопедический словарь для начинающих. – М.: «Педагогика-пресс», 1994. – 349 с.
6. , Лапко игр. Исследование операций. – Мн.: «Вышэйшая школа», 1982. – 210 с.
7. Математика. Основы математического анализа. – М.: «Айрис Пресс», 1999. – 270 с.
8. Шпаковский параллельных ЭВМ и суперскалярных процессоров. – Мн.: БГУ, 1996. – 283 с.
9. , Серикова для многопроцессорных систем в стандарте MPI. – Мн.: БГУ, 2002. – 324 с.
10. Что такое Beowulf? (http://acdwp. narod. ru/la/podr/.htm).
ПРИЛОЖЕНИЕ 1
// Файл DataType. h
// Содержит определенные и используемые в работе типы данных
// 20.05.04 г.
// Целые знаковые и беззнаковые
typedef unsigned int CODE_ERR; // Тип для возврата результата-ошибки
typedef unsigned int UINT; // Тип для счетчиков
typedef unsigned long int ULONG; // Тип для счетчиков
// Вещественные знаковые и беззнаковые
typedef float PTCOUNT; // Хранит кол-во точек
typedef long double LIMIT; // Тип для границ диапазона
typedef long double FUNC_TYPE; /* Тип результата подынтегральной функции */
typedef long double ARG_TYPE; // Тип для аргументов функций
typedef unsigned long double UFUNC_TYPE; // Тип для площади
typedef unsigned long double ERR_T; // Тип для точности
// Указатели на функции
typedef FUNC_TYPE (*SURF) (ARG_TYPE, ARG_TYPE); /* Функция двух аргументов */
typedef FUNC_TYPE (*CURVLINE) (ARG_TYPE); // Функция одного аргумента.
ПРИЛОЖЕНИЕ 2
// __MyHeader__.h
// Инлайн реализации вспомогательных функций
// Последние изменения 20 мая 2004 г.
///////////////////////////////////////////////////////////////////////////////////////////////////////////
// Включения
#include <time. h>
#include <stdio. h>
#include <stdlib. h>
#include "DataType. h"
///////////////////////////////////////////////////////////////////////////////////////////////
inline CODE_ERR TotTimePrint
(clock_t start, clock_t stop, FILE *fp, char mode = 'f')
/* Инлайн функция печатает в файл (по умолчанию) или на дисплей (mode == 'd') время в минутах и секундах между отметками start и stop, полученными с помощью функции clock(). При этом, если время меньше 1 секунды функция выводит, что общее время выполнения чего-либо – < 1 sec. Возвращает код ошибки: "0" – если ошибок нет, "−1" – если значения start и/или stop – ошибочные или указан несуществующий режим */
{
if (start < 0 || stop < 0) return −1;
// Подсчитываем время выполнения
clock_t t = (stop-start) / CLK_TCK;
switch (mode) {
case 'f': // Печать в файл
if (t < 1) fprintf (fp, "Total time < 1 sec\n");
else fprintf (fp, "Total time = %d sec (%d min %d
sec)\n", t, t/60, (t - (t/60)*60));
break;
case 'd': // Печать на экран
if (t < 1) printf ("Total time < 1 sec\n");
else printf ("Total time = %d sec (%d min %d sec)\n",
t, t/60, (t - (t/60)*60));
break;
default:
return −1;
break;
}
return 0;
}
inline long double random (LIMIT left, LIMIT right)
/*Инлайн функция возвращает случайное число в интервале от left до right */
{ return ((long double)rand()) * (right-left) / RAND_MAX + left; }
ПРИЛОЖЕНИЕ 3
// Файл IntegralMK. h
/* Описания функций для подсчета интегралов методом Монте-Карло */
// 4 мая 2004 г. – 25 мая 2004 г.
///////////////////////////////////////////////////////////////////////////////////////////////
// Включения
#include <mpi. h>
#include "DataType. h"
#include "__MyHeader__.h"
///////////////////////////////////////////////////////////////////////////////////////////////
// Константы
#define EPS_ERR 1 // Неккоректная величина абсолютной ошибки
#define TOTPT_MAX 1e30 // Максимально допустимое число точек
///////////////////////////////////////////////////////////////////////////////////////////////
// Поверхность
FUNC_TYPE Surf (ARG_TYPE x, ARG_TYPE y);
// Границы у-правильной области, т. е. bot(x) и top(x)
FUNC_TYPE bot (ARG_TYPE arg); // Нижняя граница
FUNC_TYPE top (ARG_TYPE arg); // Верхняя граница
// Подынтегральная функция для 1-кратного интеграла
FUNC_TYPE f (ARG_TYPE arg);
///////////////////////////////////////////////////////////////////////////////////////////////
// Интерфейсы функций
FUNC_TYPE Integral1DSF
(CURVLINE f, LIMIT left, LIMIT right, ERR_T eps = 1e-4);
// Рассчет 1-кратного интеграла по формуле парабол (Симпсона)
/* Использовалась для сравнения со значениями, полученными методом Монте-Карло */
// П Р О Т Е С Т И Р О В А Н А! ! ! – 22.05.04 г.
FUNC_TYPE Integral1DMK
(CURVLINE f, LIMIT left, LIMIT right, ERR_T eps = 1e-3,
PTCOUNT totpt = 100, ULONG mult = 2);
// Вычисление 1-кратного интеграла методом Монте-Карло
// Вариант со средним значением функции
// П Р О Т Е С Т И Р О В А Н А! ! ! – 25.05.04 г.
FUNC_TYPE Integral1DMK_par
(CURVLINE f, LIMIT left, LIMIT right, ERR_T eps = 1e-3,
PTCOUNT totpt = 100, ULONG mult = 2);
// Вычисление 1-кратного интеграла методом Монте-Карло на кластере MPI
// Вариант со средним значением функции
// П Р О Т Е С Т И Р О В А Н А
// НА КЛАСТЕРЕ! ! ! – 26.05.04 г.
FUNC_TYPE Integral1DMK_par1
(CURVLINE f, LIMIT left, LIMIT right, ERR_T eps = 1e-3,
PTCOUNT totpt = 100, ULONG mult = 2);
/* Вычисление 1-кратного интеграла методом Монте-Карло на кластере MPI. Вариант со средним значением функции. Каждый процесс работает в более узком диапазоне, чем первоначальный */
// П Р О Т Е С Т И Р О В А Н А
// НА КЛАСТЕРЕ! ! ! – 26.05.04 г.
FUNC_TYPE Integral1DMK_par2
(CURVLINE f, LIMIT left, LIMIT right, ERR_T eps = 1e-3,
PTCOUNT totpt = 100, ULONG mult = 2);
/* Вычисление 1-кратного интеграла методом Монте-Карло на кластере MPI. Вариант со средним значением функции. Каждый процесс работает в более узком диапазоне, чем начальный. Операция редукции проводится однажды, когда каждый процесс подсчитал интеграл на своем узком участке */
// П Р О Т Е С Т И Р О В А Н А
// НА КЛАСТЕРЕ! ! ! – 26.05.04 г.
UFUNC_TYPE Square
(CURVLINE f, LIMIT left, LIMIT right, ERR_T eps = 1e-4);
/* Вычисление площади под кривой f(x). Используется формула Симпсона */
// П Р О Т Е С Т И Р О В А Н А! ! ! – 24.05.04 г.
inline UFUNC_TYPE RegionY
(CURVLINE bottom, CURVLINE top, LIMIT left,
LIMIT right, unsigned char var, ERR_T eps = 1e-4)
/* Вычисление площади между кривыми bottom(x) и top(x). Кривые сшиваются в точках left и right */
// П Р О Т Е С Т И Р О В А Н А! ! ! – 25.05.04 г.
{
// var определяет случай вычисления площади области
switch (var) {
// Кривые top и bottom лежат в положительной полуоси
case 1: return Square(top, left, right, eps) –
Square(bottom, left, right, eps);
break;
// Кривые top и bottom лежат в отрицательной полуоси
case 2: return Square(bottom, left, right, eps) –
Square(top, left, right, eps);
break;
// Кривая top лежит в положительной полуоси
// кривая bottom лежит в отрицательной полуоси
case 3: return Square(top, left, right, eps) +

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
