
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ОБЩАЯ ХАРАКТЕРИСТИКА РАБОТЫ
Актуальность темы диссертационного исследования. В настоящее время вопросы качества программного обеспечения приобретают особую важность. Неотъемлемой частью процесса обеспечения качества является тестирование. По существующим оценкам, затраты на тестирование программ составляют до 50% всего бюджета программного продукта. Таким образом, тестирование — очень трудоемкий и дорогостоящий процесс, автоматизация которого весьма актуальна. В то время как такие составляющие процесса тестирования, как автоматизированное контролируемое выполнение программы, оценка и запись отчетов о результатах поддерживаются существующими программными системами, задача автоматизации получения входных тестовых данных зачастую остается нерешенной.
Актуальна не только генерация тестовых данных при промышленной разработке коммерческих программных продуктов, которая в значительной степени акцентируется на функциональном тестировании, но и генерация тестовых данных на основе структурного подхода при проверке учебных программ, создаваемых на том или ином этапе обучения программированию, которая и рассматривается в данной работе. Автоматизация такой проверки особенно важна, если обучение проводится дистанционно (например, на основе сети Интернет). В этом случае число тестируемых программ превышает объем, доступный для ручной проверки за приемлемое время.
Для учебных программ сложность решения вышеупомянутой задачи может быть уменьшена за счет следующего:
· в качестве формальной спецификации может выступать эталонная правильная программа, созданная в соответствии с учебным заданием экспертом в области программирования (например, преподавателем). Данная программа обеспечивает правильный результат для любых входных данных;
· сложность учебных программ и формата их входных/выходных данных искусственно ограничена требованиями задания, что позволяет успешно применить методы автоматизированной генерации тестовых данных. Например, рассматриваются только процедурные, а не объектно-ориентированные программы.
Состояние изученности проблемы. На настоящий момент существует более десятка методов, ориентированных на решение задачи генерации входных данных для структурного тестирования. В начале периода развития данных методов преобладал статический подход, основанный на символьном исполнении (авторы - Дж. Кинг, Л. Кларк, С. Рамамурти). К текущему времени исследования сосредоточены на динамических методах, использующих локальные (Б. Корел) или глобальные методы поиска (Н. Трейси, Дж. Вегенер и др.). При этом в исследованиях практически неосвещенными остаются следующие проблемы:
· проблема набора количественных и качественных характеристик методов, позволяющего осуществить их оценку;
· проблема нахождения входных данных определенных типов, в частности, строкового и процедурного типа, являющихся весьма распространенными в практике программирования. Следует отметить, что большинство методов ориентировано на обработку числовых данных.
Цель и задачи исследования. Основной целью данной работы является усовершенствование методов нахождения входных данных для тестирования программ, а именно улучшение их количественных и качественных характеристик. Для достижения этой цели были решены следующие задачи:
· проведен сравнительный анализ существующих методов нахождения входных данных;
· выбраны методы, подлежащие усовершенствованию, и улучшен выбранный критерий покрытия;
· разработаны вспомогательные алгоритмы, обеспечивающие исходные данные для работы любых динамических методов;
· расширен набор типов данных, поддерживаемых существующими методами;
· метод релаксации адаптирован для работы с дуговыми функциями сложного вида.
Объектом исследования данной работы являются путь-ориентированные методы нахождения входных данных для структурного тестирования.
Методы проведенного исследования. Для достижения поставленных в работе целей использовались методы теоретического и эмпирического исследования.
Научная новизна исследования. В диссертации получены следующие результаты, характеризующиеся научной новизной:
· разработан метод обработки строк при генерации входных тестовых данных;
· разработан метод обработки переменных процедурного типа при генерации входных тестовых данных;
· предложена адаптация метода релаксации для обработки дуговых функций сложного (кусочно-линейного) вида.
Достоверность полученных результатов подтверждается данными, полученными в ходе применения программной реализации усовершенствованных методов, а также обсуждением научных результатов на конференциях и их положительной оценкой.
Практическая значимость полученных результатов.
Внедрение системы автоматизированного нахождения тестовых данных для учебных программ позволяет повысить качество дистанционного обучения программированию за счет увеличения числа заданий, которые могут быть проверены, и сократить объем работы преподавателя.
Включение строкового и процедурного типов данных в состав поддерживаемых методами генерации приводит к расширению множества программ, для которых задача нахождения тестовых данных может быть эффективно решена. В результате степень автоматизации решения вышеупомянутой задачи существенно повышается.
Внедрение результатов. Результаты работы внедрены в СПбГУИТМО в учебном процессе, а также в проекте “Интернет-школа программирования”.
Основные положения диссертации, выносимые на защиту:
1) разработанные методы обработки тестовых данных строкового и процедурного типа;
2) предложенное усовершенствование метода релаксации;
3) результаты применения методов нахождения тестовых данных.
Апробация результатов диссертации. Основные положения диссертационной работы и результаты исследований, включенные в диссертацию, докладывались на различных конференциях СПбГУИТМО, всероссийской научно-методической конференции «Телематика 2005», а также на четырех различных всероссийских конференциях. Доклад на конференции «Микроэлектроника и информатика-2005» (МИЭТ, Зеленоград) был отмечен дипломом за третье место в конкурсе работ аспирантов.
Структура диссертационной работы. Диссертационная работа состоит из четырех глав, введения, заключения, списка литературы, включающего 72 наименования, и приложения. Общий объем работы 265 страниц. Диссертация содержит 24 рисунка и 21 таблицу.
ОСНОВНОЕ СОДЕРЖАНИЕ РАБОТЫ
Первая глава диссертационной работы содержит обзор исследуемой предметной области. В ней рассмотрен процесс тестирования, его цели и разновидности, классификация и содержание критериев полноты структурного тестирования, связь между степенью покрытия и надежностью программы. Сформулирована постановка задачи нахождения входных данных для структурного тестирования и рассмотрена хронология развития идей решения этой задачи.
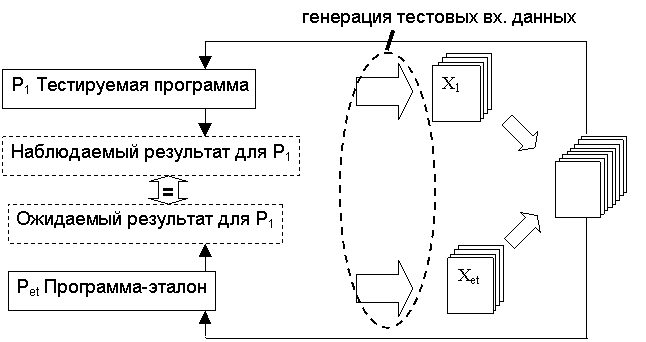

Рисунок 1
Использованная схема тестирования и место в ней процесса генерации тестовых данных показаны на рисунке 1. Ошибка обнаруживается как несоответствие между наблюдаемым результатом и ожидаемым.
Рассмотрены основные принципы, достоинства и недостатки основных методов получения входных данных.
Вторая глава посвящена построению набора характеристик методов генерации тестовых данных и их улучшению. Сначала рассматриваются количественные характеристики динамических путь-ориентированных методов. В частности, эффективность E работы метода при покрытии всего набора N путей {p1, …, pk, …, pN} в заданной программе определяется следующим образом:
|
Здесь n eval k – количество выполнений программы для нахождения данных для k-го пути, Wk – сложность k-го пути Wk=1-pk,
pk – вероятность прохождения k-го пути в случае, когда значения входных переменных – равномерно распределенные случайные величины.
Wk интерпретируется как вероятность того, что k-й путь не будет пройден.
Чем меньше вероятность прохождения пути, тем выше сложность нахождения тестовых данных для его покрытия.
Качественные характеристики методов описывают их возможности: обрабатываемые типы данных, управляющие структуры, а также поддерживаемые группы критериев тестирования. Улучшение качественных характеристик в данной работе заключается в разработке методов для поддержки строкового и процедурного типов данных.
Поддержка генерации входных данных строкового типа
В данной работе предлагается установить соответствие между множеством всех строк и множеством всех неотрицательных чисел. Пусть имеется строка S длины L, составленная из символов s[1], s[2], …, s[L]. Рассмотрим два способа сопоставления ей числа.
Способ 1. Пусть имеется N возможных символов. C = {c1, c2, …, cN}. Сопоставим им числа si = 0, 1, …, N-1. Если N=255, а символы представляют собой полную таблицу ASCII, то эти числа будут числовыми кодами символов. Будем сопоставлять этой строке число x(S):
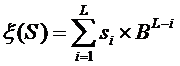
Здесь основание B – это число различных символов, B=N. При использовании однобайтовой кодировки B=28=256.
Недостатки способа. Данное соответствие не является взаимно-однозначным, то есть если s – символ, которому соответствует код 0, то строкам вида x, sx, ssx, …, ss..sssx будут соответствовать одни и те же числа.
Достоинства способа. Алгоритм получения строки по ее числовому эквиваленту несложен и состоит в пошаговом получении остатков от деления на B и последнего частного, то есть является стандартным алгоритмом перевода чисел между системами счисления.
Способ 2.
Второй способ отличается тем, что символам сопоставляются числа si = 1, 2, …, N. Таким образом, si ≠ 0, и соответствие становится взаимно-однозначным.
Недостатки способа. Алгоритм получения строки по ее числовому эквиваленту более сложен, чем в первом способе.
Следует отметить, что оба способа позволяют исключить из рассмотрения символы с кодами, которые не могут появиться в строке, за счет вариации множества возможных символов C. Оба способа соответствия были реализованы в рамках данной работы.
Можно утверждать, что если возможно выразить операции, производимые над строками в программе, в терминах их числовых эквивалентов, то это означает принципиальную возможность применения методов, рассчитанных на работу с числами, и для строковых данных. В таком случае для программы, содержащей строковые операции, теоретически можно построить эквивалент, содержащий только числовые операции, и свести задачу к уже решенной.
Обобщенная схема адаптации динамического метода для работы со строками приведена на рис. 2.
Пусть программа имеет входные данные как числового (x1, …, xn), так и строкового (s1, …, sm) типа. Для каждого из L предикатов ветвления BPi (i=1..L) на заданном пути для строковых значений, входящих в предикаты, находятся их числовые эквиваленты. На основании числовых значений переменных xi и значений числовых эквивалентов ci строковых переменных si вычисляется целевая функция Fi. В соответствии с алгоритмом генерации тестовых данных, числовые значения модифицируются.
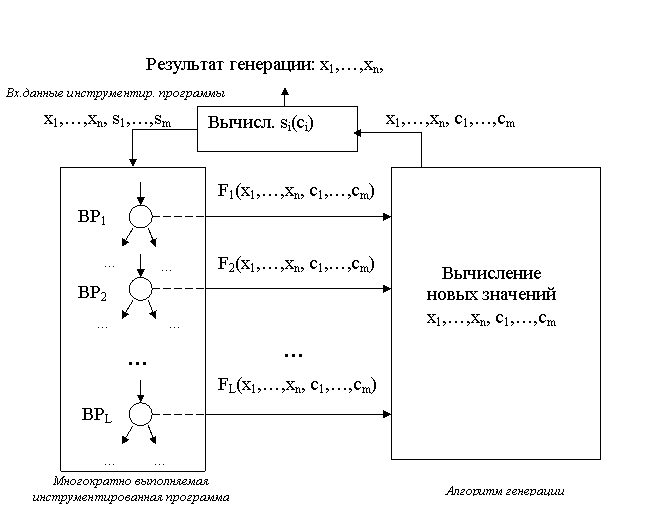

Рисунок 2
Новые вычисленные значения ci преобразуются в строковые значения для использования на следующей итерации, то есть при последующем выполнении инструментированной программы.
В данной работе реализована адаптация метода релаксации, предложенного Н. Гупта в 1998 году, для работы с тестовыми данными строкового типа, и успешно применена для тестирования учебных программ по теме «Работа со строками и записями».
Поддержка генерации тестовых данных процедурного типа
В данной работе предлагается адаптация алгоритма сокращения областей значений, предложенного Дж. Оффаттом в 1996 году, для обработки переменных процедурного типа. Исходный алгоритм является статическим, путь-ориентированным, основанным на символьном исполнении.
Пусть дана подпрограмма F(x1, x2, …, xm, f1, f2, …, fk), где xi - входные параметры непроцедурных типов, а fi - параметры-процедуры. Следует найти такие значения x1, x2, …, xm, f1, f2, …, fk, которые обеспечат прохождение заданного пути p в управляющем графе подпрограммы.
Как известно, в начале работы метода сокращения областей каждой из входных переменных назначается начальный диапазон. Затем при статическом обходе заданного пути эти диапазоны сокращаются так, чтобы любые значения из результирующих диапазонов обеспечивали прохождение пути. При прохождении операторов, отличных от условных, осуществляется их символьное выполнение, то есть выражение переменных программы через входные переменные. Будем рассматривать только случаи, когда вызов каждой функции-параметра осуществляется только один раз.
В общем случае, прохождение предиката e1 OP e2 (e1, e2 - выражения, зависящие от входных переменных) сопровождается сокращением областей по схеме
{Ri} ®Re1 ® Re1‘® {Ri‘}
{Rj} ®Re2 ® Re2‘®{Rj‘},
где Ri и Ri’ – исходные и результирующие диапазоны переменных, входящих в выражение e1, Re1 и Re1’ – исходные и результирующие диапазоны выражения e1. Обозначения для e2 аналогичны. Если выражение включает вызов переменной-процедуры, будем задавать диапазоны выходных переменных параметрически. Например, в процессе работы может быть пройден предикат f_param1(in_value1) + x < f_param2(in_value2) + y, где исходные диапазоны входных переменных xÎ[0;100], yÎ[0..100], in_value1Î[0;100], in_value2Î[0..100], f_param1, f_param2 – процедурные параметры. Задаем диапазон значений функций-параметров: f_param1(in_value1)Î[d1; d2], f_param2(in_value2) Î[d3; d4]. Получаем [d1;100+d2] < [d3;100+d4], выбираем d2>0=10 произвольно, 0<d1<100+d2, d1=10, d3>100+d2, d3=111, d4:100+d4>d3, d4 = 20.
Теперь требуется найти некоторые функции, которые, принимая аргумент из заданного диапазона [zi1вх, zi2вх], сформируют значение из заданного диапазона [zi1вых, zi2вых]. Предлагается использовать линейную функцию.
Для этого можно положить, что [zi1вых, zi2вых] – это диапазон на оси ординат, а [zi1вх, zi2вх] – диапазон на оси абсцисс, и построить уравнение прямой, проходящей через точки A(zi1вх; zi1вых) и B(zi2вх; zi2вых). Обозначив x=ziвх, y=ziвых, имеем (x-xA)/(xB-xA) = (y-yA)/(yB-yA) и y = (yB-yA)/(xB-xA) x + yA - xA(yB-yA)/(xB-xA).
Таким образом, подпрограммы, выполняющие подобные преобразования для всех необходимых значений из диапазона, и будут искомыми. Заданный путь p будет пройден.
Поддержка дуговых функций кусочно-линейного типа в методе релаксации
В данной работе также предлагается метод преодоления сложностей, с которыми сталкивается метод релаксации, когда частные производные дуговой функции в некоторых точках равны 0, однако функция – не константа (Рис. 3‑а). Дуговые функции такого вида могут встречаться в программах, обрабатывающих как числовые данные, так и строковые данные, например для предикатов следующего вида:
1. if x div y=k then …, if int(x)=k then …, if x mod c < k then …
2. if length(s)<k then …, if pos(':', s) <> 0 then …, if copy(s, 1,2) = ‘XY’ …
Если производная вычисляется равной нулю, то соответствующий коэффициент ci равен нулю в линейном представлении приращения дуговой функции ![]() , где xi – N входных переменных, входящих в j-й предикат ветвления. Если это условие будет выполняться для всех xi, то результирующая система линейных ограничений, формируемая методом релаксации, не будет иметь решений, и алгоритм потерпит неудачу, а если для некоторых xi – может потребовать дополнительных итераций.
, где xi – N входных переменных, входящих в j-й предикат ветвления. Если это условие будет выполняться для всех xi, то результирующая система линейных ограничений, формируемая методом релаксации, не будет иметь решений, и алгоритм потерпит неудачу, а если для некоторых xi – может потребовать дополнительных итераций.
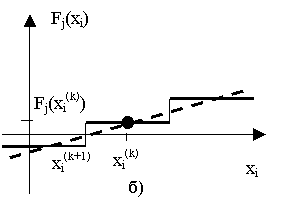
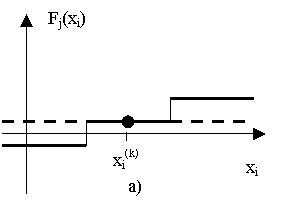 |
Рисунок 3
Интерпретация предложенного усовершенствования в том, чтобы вычислять ci как F(xi(k))/(xi(k+1)-xi(k)) - угловой коэффициент секущей как показано на рисунке 3-б. При этом для нахождения точки xi, такой, что Fj(xi)=0, используется один из алгоритмов глобального поиска – алгоритм моделирования отжига.
Третья глава посвящена разработке вспомогательных алгоритмов для генерации тестовых данных.
Алгоритм построения управляющего графа программы из его исходного текста включает в себя два этапа: получение представления исходного текста в виде абстрактного синтаксического дерева (АСД) и преобразование АСД в структуру, представляющую управляющий граф (УГ). Первый этап реализуется при помощи готового программного инструмента ANTLR. Для реализации второго этапа построен рекурсивный алгоритм, в котором текущий фрагмент синтаксического дерева, соответствующий блоку программы, преобразуется в фрагмент УГ и затем включается в общую структуру УГ.
Построенный УГ используется для формирования набора требуемых путей, инструментации программы и для работы основных алгоритмов.
Алгоритм формирования базисного набора путей. В данной работе строится набор базисных путей, обладающих свойством линейной независимости. Такой набор удовлетворяет критерию покрытия ветвей и, кроме того, обеспечивает независимую проверку каждого из ветвлений. В отличие от существующих алгоритмов, учитывается реализуемость путей на основе учета числа итераций циклов.
Следует отметить, что критерий покрытия базисных путей модифицирован в данной работе. Для каждого пути должен быть найден не один, а несколько входных наборов, если выполнение каких-либо K предикатов на пути соответствует отношению «³», «£» или «¹». Каждому из таких отношений ставится в соответствие два отношения {R1, R2} : {>, =}, {<, =} и {>, <}, соответственно. Первый из полученных K+1 наборов для пути должен обеспечивать выполнение R1 для всех предикатов, а каждый из последующих K наборов - выполнение R2 ровно для одного из K предикатов и выполнение R1 для остальных. Например, для пути с K=2 предикатами {«x1³x2», «x3³x4»} будут получены K+1=3 набора, в которых выполняются: {«x1>x2», «x3>x4»}, {«x1=x2», «x3>x4}, {«x1>x2», «x3=x4»}.
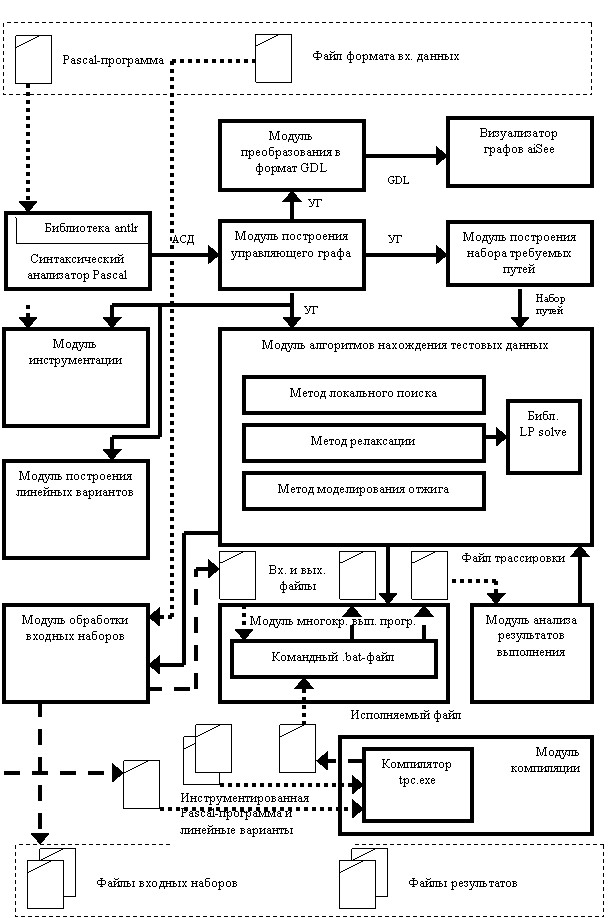
Четвертая глава данной работы описывает созданную программную систему генерации тестовых данных и результаты ее применения. Программная реализация представляет собой многомодульную систему, написанную на объектно-ориентированном языке С# на платформе Microsoft. NET Framework v1.1.
Структура программной системы представлена на рисунке 4.
|
№ | Наиме-нование | Описание | Особен-ности | V(G) этал. |
1 | Л. р. 2-1 | Для заданного x вычислить f(x), кусочно заданную на интервалах | Ветвления | 7 |
2 | Л. р. 2-1 | Для заданных (x;y) вычислить, лежит ли точка внутри указанной фигуры | Ветвления | 3 |
3 | Л. р. 3-1 | Для x, изменяющегося от xнач до xкон, вычислить f(x) из л. р. 2-1 | Цикл, ветвления | 8 |
4 | Л. р. 6 | В массиве из N записей вывести записи, в которых строковое поле равно заданному значению | Цикл, ветвления, данные строкового типа | 2 |
|
|
|





 |
Для каждой из программ были рассмотрены неверные реализации, содержавшие дефекты следующих видов.
Таблица 2
1 | Неверное присваиваемое выражение |
2.1 | Неверное выражение в условии |
2.2 | Неверный знак в условии |
3 | Пропущенные вычисления |
4 | Лишние вычисления |
Результаты, полученные для Л. Р. 2-1, приведены в табл. 3.
Таблица 3
Тип дефек-та. | Количество тестовых наборов | ||||||||
Из эталона | Из тестируемой программы | Итого | |||||||
общее Net | обнаруж. ошибку Net err | общее Nt | обнаруж. ошиб. Nt err | избыточных Nt изб | оставшихся после сокращ. | общее Nå | обн. ошиб. Nå err | ||
общ. Nt’ | обн. ошиб. Nt err’ | ||||||||
Программа: Л. Р. 2-1 | |||||||||
1 | 13 | 2 | 13 | 2 | 13 | 0 | 0 | 13 | 2 |
2 | 13 | 2 | 11 | 2 | 0 | 15 | 2 | ||
0 | 13 | 2 | 11 | 2 | 2 | 15 | 2 | ||
2.2 | 10 | 13 | 10 | 3 | 10 | 10 | 23 | 20 | |
3 | 1 | 11 | 0 | 11 | 0 | 0 | 13 | 1 | |
4 | 0 | 15 | 1 | 14 | 1 | 1 | 14 | 1 |
В табл. 3 Nå = Net + Nt’ , Nå err = Net err + Nt err’
Табл. 3 иллюстрирует тот факт, что наборы, найденные в соответствии с модифицированным в работе критерием покрытия базисных путей, способны обнаруживать несоответствие между эталоном и тестируемой программой при наличии в ней некоторых типичных дефектов.
ЗАКЛЮЧЕНИЕ
В диссертационной работе рассмотрены различные подходы и методы, нацеленные на решение задачи нахождения входных данных для структурного тестирования программ.
Введены характеристики методов и предложены способы улучшения этих характеристик, а именно:
· разработаны методы нахождения тестовых данных строкового типа и процедурного типа;
· предложено усовершенствование метода релаксации.
Разработаны вспомогательные алгоритмы, необходимые для генерации тестовых данных.
Программно реализован усовершенствованный метод последовательной релаксации, включающий поддержку строковых данных. При помощи программной системы были автоматически получены входные данные, позволившие выявить наличие ошибок в реализациях учебных программ, содержащих типичные дефекты.
СПИСОК ПУБЛИКАЦИЙ ПО ТЕМЕ РАБОТЫ
1. Яковлев полноты тестирования программ// Вестник конференции молодых ученых СПбГУИТМО. Сборник научных трудов. – СПб: СПбГИТМО (ТУ), 2004. – том 1. – с.150-154
2. Яковлев исследования методов генерации входных данных для структурного тестирования программного обеспечения // Вестник II межвузовской конференции молодых ученых. Сборник научных трудов /Под ред. . – СПб: СПбГУИТМО(ТУ), 2005. – том 1. – с. 60-64
3. Реализация генетического алгоритма для поиска входных данных при структурном тестировании программ. //Материалы международной научно-технической конференции "Наука и образование-2005"– Мурманск, 2005. – с. 12-15
4. Яковлев входных тестовых данных символьного типа. //Микроэлектроника и информатика-20я всероссийская межвузовская научно-техническая конференция студентов и аспирантов. Тезисы докладов. – Москва, 2005. – с.299
5. , Павловская интерпретация динамических методов генерации входных данных для тестирования программ. //Информационные технологии в науке, проектировании и производстве. Материалы 14-й всероссийской научно-технической конференции. – Нижний Новгород, 2005. – с. 25-28
6. , Павловская метода генерации входных данных для тестирования программ с параметрами процедурного типа //Информационные технологии в профессиональной деятельности и научной работе. Сборник материалов региональной научно-практической конференции. – Йошкар-Ола, 2005. – с. 144-146.
7. , Павловская алгоритмов генерации входных данных для структурного тестирования объектно-ориентированных программ //Техника и технология, № 2, 2005. – с. 86‑88
8. , Павловская методы генерации входных данных для тестирования учебных программ // Сборник XII Всероссийской научно-методической конференции Телематика 2005 / Под ред. — СПб: СПбГУ ИТМО (ТУ), 2005 г. – т.2. – с. 514-515
