
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Селективная выборка (или метод фиксированной последовательности)
При стратификации опыты строятся таким образом, чтобы значение стратифицирующей переменной определенное число раз попадало в каждый слой. В рассмотренном методе тип событий фиксируется внутри имитационного опыта. Поэтому все опыты имеют один вид.
Пусть в модели имеется только одна случайная входная переменная w, причем она является дискретной, и известны вероятности
![]() P(w = wi)=Pi, (i=1,M).
P(w = wi)=Pi, (i=1,M).
где M – кол-во возможных значений случайной величины.
Пусть требуется m значений случайных величин в одном имитационном опыте. Обозначим через Vi количество раз, когда случайная величина w принимает значение wi. Vi будет случайной величиной, причем математическое ожидание: E(Vi)=Pim.
Имитационные опыты построим так, чтобы при их проведении величина Vi была не случайной, равнялась всегда одному и тому же числу Vi=Pim, где ![]()
В общем случае величина Pi * m не будет целым числом. Поэтому все Vi выбираются такими, чтобы минимизировать величину:
![]()
при условии, что 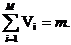
![]() Найденное значение обозначим Vi* (i=1,M).
Найденное значение обозначим Vi* (i=1,M).
Т. о., число появлений возможного значения wi в имитационном опыте определено и равно Vi* . Однако порядок их появлений не задан.
![]() Выборка производится так, чтобы появление каждого порядка имело одну и ту же вероятность. Технически это реализуется с помощью выборки без возвращения. При этом предполагается, что при получении t-го случайного числа вероятность выбора значения wi равна:
Выборка производится так, чтобы появление каждого порядка имело одну и ту же вероятность. Технически это реализуется с помощью выборки без возвращения. При этом предполагается, что при получении t-го случайного числа вероятность выбора значения wi равна:
![]() ,
,
здесь gti – количество раз, сколько значений wi уже было выбрано в имитационном опыте до t-го шага.
Эксперименты показали, что дисперсия при таком проведении имитационного опыта снижается более чем на 50 %. Однако процедура дает смещенные результаты.
Описанную процедуру можно обобщить на большее число типов входных переменных и на случай, когда они являются непрерывными. Для каждой входной переменной определяем количество значений, появляющихся в каждом имитационном опыте, и выбираем их по тому же алгоритму. Область возможных значений случайных непрерывных величин мы разбиваем на М классов так, чтобы в каждом из них оказалось по 1/M долей наблюдений. И в качестве возможных значений wi используем медианы соответствующих классов.
Метод регрессионной выборки
В данном методе выборочный процесс сам по себе не управляется, здесь значение отклика подправляется в конце имитационного опыта. Исправление производится с помощью контрольной величины, определяемой следующим образом: пусть при имитации имеется одна входная случайная величина y. В ходе опыта она принимает значения: y1,y2,…,ym.
Ее функция ![]() выступает в качестве контрольной величины. При моделировании мы знаем закон распределения случайной величины y. Значит, мы можем определить ее математическое ожидание:
выступает в качестве контрольной величины. При моделировании мы знаем закон распределения случайной величины y. Значит, мы можем определить ее математическое ожидание:
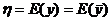 .
.
После проведения имитационного опыта мы можем подправить оценку отклика x по формуле: ![]() , здесь а - некоторая константа, неизменяющаяся в течение одного имитационного опыта.
, здесь а - некоторая константа, неизменяющаяся в течение одного имитационного опыта.
Подправленная оценка хc будет несмещенной:
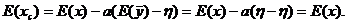
Дисперсия этой функции определяется по формуле:
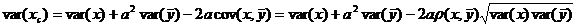 .
.
Определим, когда дисперсия подправленной оценки Xc меньше дисперсии оценки отклика х. Возможны два случая:
1. а>0, тогда ![]() (*).
(*).
(s - СКО, ![]() – коэффициент корреляции)
– коэффициент корреляции)
 2. a<0, тогда
2. a<0, тогда![]() (**).
(**).
Т. о., если x и ![]() положительно коррелируют, то дисперсия понижается, если константа а>0, и удовлетворяет неравенству(*).
положительно коррелируют, то дисперсия понижается, если константа а>0, и удовлетворяет неравенству(*).
Для отрицательной корреляции справедливо соотношение(**).
Для нахождения оптимального значения константы а требуется продифференцировать по а выражение дисперсии Xc, и приравнять к нулю. При этом мы получим, что
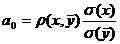 .
.
При этом минимальное значение дисперсии будет:
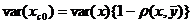 .
.
Это соотношение показывает, что чем больше коррелируют величины x(отклик) и ![]() (среднее значение входа), тем сильнее понизится дисперсия подправленной оценки откликов.
(среднее значение входа), тем сильнее понизится дисперсия подправленной оценки откликов.
Недостатком этого метода является то, что теоретическое значение корреляции ![]() (х,
(х, ![]() ) получить крайне затруднительно. Поэтому обычно берут оценку коэффициентов корреляции, построенную по n предыдущим имитационным опытам. При этом оценка оптимальных коэффициентов будет:
) получить крайне затруднительно. Поэтому обычно берут оценку коэффициентов корреляции, построенную по n предыдущим имитационным опытам. При этом оценка оптимальных коэффициентов будет:
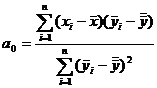 .
.![]()
В случае, когда имеется несколько разных входных переменных, оценка с множественной контрольной величиной будет следующей:
![]() .
.
Здесь ![]() ,
,
![]() .
.
Здесь yit– t-ое наблюдение входной переменной i-го типа в имитационном опыте. Эта оценка не будет смещенной, величина ее дисперсии зависит от выбора коэффициентов аi. Для их определения, удобнее взять контрольные величины с нулевым математическим ожиданием:zi=![]() -hi, т. е.
-hi, т. е. ![]()
![]() .
.
Реалистично предположить, что контрольные величины zi не зависимы в совокупности. Это справедливо для большинства имитационных моделей.
Для независимых контрольных величин мы получим:
![]()
Оптимальное значение коэффициентов ai можно определить, взяв частные производные по аi, и приравняв их к нулю.
![]() .
.
Поскольку математическое ожидание E(zi)=0, то
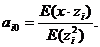
Простая оценка этих коэффициентов будет:
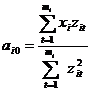 .
.
Эксперименты показывают понижение дисперсии от 15 до 90 %.
