

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ПОДХОДЫ К РАЗРАБОТКЕ ОТКАЗОУСТОЙЧИВОЙ РАСПРЕДЕЛЕННОЙ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ ПРОТИВОАВАРИЙНОГО УПРАВЛЕНИЯ
, , Субботин-
автоматизации энергетических систем»
2. ВВЕДЕНИЕ
Для широкого спектра задач управления электроэнергетическими объектами характерны необходимость обеспечения бесперебойного функционирования системы управления и высокого быстродействия [1, 2]. В соотношение между этими понятиями вкладывается различный смысл, в зависимости от задачи, решаемой конкретной системой, с учетом иерархии управления.
Рассмотрим предметную область противоаварийного управления (ПАУ) энергосистемой. На верхнем уровне иерархии ПАУ решается задача выбора управляющих воздействий (УВ), которые должны быть реализованы конкретными устройствами на нижнем уровне иерархии, при фиксации на данном уровне аварийных возмущений в энергосистеме, с целью минимизации ущерба от этих возмущений. На сегодняшний день, с учетом развития алгоритмической базы в части применения способа I-ДО [3], выбор управления становится ресурсоемкой математической задачей, максимальная длительность цикла которой определена стандартом [4] на уровне 30 секунд, при этом на верхнем уровне, как правило, нет необходимости в непосредственной выдаче управляющих сигналов.
В свою очередь, быстродействие реализации управления устройствами нижнего уровня находится в пределах нескольких десятков миллисекунд, с учетом времени срабатывания промежуточных реле. В случае, если устройства нижнего уровня осуществляют собственный цикл выбора управления по способу II-ДО в целях резервирования [5], длительность данного цикла определяется частотой обновления локальной доаварийной информации и составляет, как правило, не менее 1 секунды (вообще говоря, время доставки доаварийной информации нормируется стандартом [4] на уровне 1-2 секунд).
Таким образом, в рамках одной системы управления решаются два класса задач, которые могут быть условно разделены по соотношению параметров быстродействия и надежности на расчетные задачи и задачи реального времени.
Одним из перспективных методов обеспечения надежности и быстродействия при создании систем управления является использование распределенных вычислительных систем (ВС). Это позволяет обеспечить требуемое быстродействие для расчетных задач, за счет распараллеливания вычислений, и требуемую надежность функционирования для задач реального времени, за счет резервирования.
Рассмотрим подходы к разработке распределенной вычислительной системы управления.
3. ПОДХОДЫ К РАЗРАБОТКЕ РАСПРЕДЕЛЕННОЙ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ УПРАВЛЕНИЯ
3.1. Общие сведения
Как известно, распределенная ВС представляет собой совокупность вычислительных машин (ВМ), или узлов, объединенных сетью передачи данных. Соответственно, конкретные функции, выполняемые системой управления, могут быть распределены по узлам ВС. Так, например, при разработке системы управления, решающей расчетные задачи на верхнем уровне иерархии управления, целесообразно разделить функции следующим образом:
1. Ввод и подготовка исходных данных для расчета.
2. Расчет.
3. Сведение результатов расчета в общую таблицу.
4. Взаимодействие с системами управления нижнего уровня.
5. Взаимодействие с автоматизированным рабочим местом (АРМ) пользователя.
6. Взаимодействие с внешними системами управления и мониторинга (АСУТП и пр.)
Функция расчета, в свою очередь, может быть разделена между несколькими узлами по определенным критериям, с целью одновременного выполнения расчетных задач для однотипных элементов управляемого объекта для обеспечения требуемого быстродействия (оставим пока за скобками параллелизм математических операций). Функции, касающиеся обмена информацией с внешними системами в ряде случаев целесообразно объединять на одном узле, т. н. предвключенной ВМ. В составе ВС необходимо также предусмотреть некоторое количество резервных узлов, готовых принять на себя функции узлов, вышедших из строя либо остановленных на профилактику. Укрупненная структура расчетной распределенной ВС приведена на рис. 1.
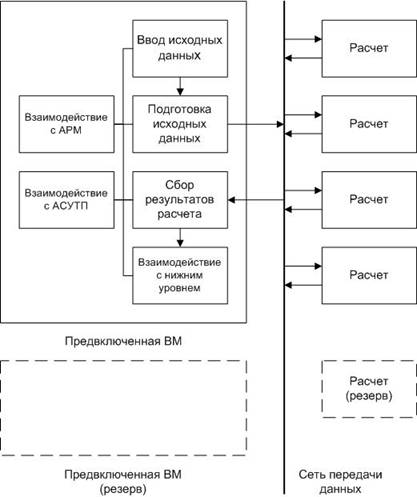
Рис. 1: Структура расчетной распределенной системы управления
В свою очередь, в системе управления, решающей задачи реального времени на нижнем уровне иерархии управления, обеспечивается выполнение следующих функций:
1. Ввод и подготовка исходных данных для локального расчета (при необходимости).
2. Локальный расчет (при необходимости).
3. Взаимодействие с системами управления верхнего уровня.
4. Получение аварийных сигналов и выдача управляющих сигналов.
5. Взаимодействие с АРМ пользователя.
6. Взаимодействие с внешними системами управления и мониторинга (АСУТП и пр.)
В данном случае, с точки зрения обеспечения надежности, целесообразно выделить функции реального времени на совокупность резервированных узлов (не менее двух). Остальные функции могут быть вынесены на предвключенную ВМ, которая также должна быть резервирована (рис 2). При сравнительно небольшой вычислительной нагрузке, функции предвключенной ВМ могут быть совмещены с функциями реального времени.
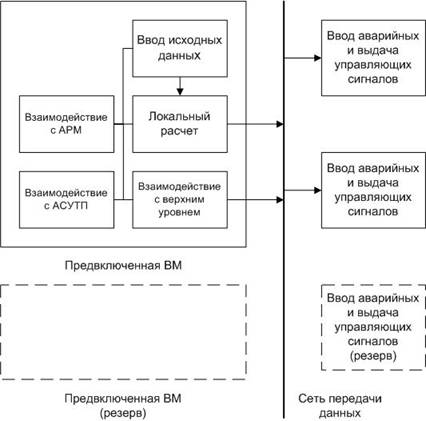
Рис. 2: Структура распределенной системы управления реального времени
В системах управления реального времени, как правило, возникает необходимость непосредственного взаимодействия с объектом управления при помощи дискретных сигналов. В связи с этим, в распределенной системе управления функции реального времени должны выполняться, как минимум, на двух физических узлах системы, оснащенных соответствующим аппаратным обеспечением. При этом место установки системы управления, как правило, вносит определенные физические ограничения по максимальному количеству микропроцессорных устройств в одном шкафу управления, а также по общему количеству шкафов. Данный вопрос может быть решен только за счет архитектуры системы, т. е. совмещения функций.
В расчетных распределенных системах управления, не требующих непосредственного взаимодействия с управляемым объектом, могут быть применены современные технологии виртуализации. При этом технологические функции распределяются по виртуальным машинам, запускаемым на нескольких (по условиям обеспечения резервирования, минимум на двух) высокопроизводительных серверах. Это позволяет, с одной стороны, обеспечить необходимое быстродействие системы, как за счет распределения типовых задач по различным узлам, так и за счет распараллеливания математических операций, поскольку под одну виртуальную машину может быть выделено несколько процессорных ядер. С другой стороны, виртуализация дает возможность абстрагироваться от аппаратного обеспечения, и, при исчерпании физических возможностей по увеличению быстродействия, при устаревании, либо при выходе из строя без возможности восстановления, заменить технические средства на новые. С точки зрения разработчика, виртуализация позволяет также проводить отладку и тестирование технологических функций практически на любом аппаратном обеспечении, однако тестирование распределенной системы в части быстродействия рекомендуется проводить на тех технических средствах, которые будут установлены на объекте, либо на полностью аналогичных.
Далее мы будем рассматривать подходы к разработке системы управления, которая может быть применена как для решения расчетных задач, так и для решения задач реального времени.
3.2. Постановка задачи
К разрабатываемой распределенной вычислительной системе управления предъявляются следующие требования:
1. Возможность выполнения узлами системы функций различных видов, как то: подготовка исходных данных, расчетные задачи, задачи реального времени, взаимодействие с внешними системами.
2. Гибкость структуры системы, отсутствие централизованных элементов и т. н. «узких мест» на уровне архитектуры.
3. Возможность резервирования функций, как-то: передача всех функций или их части другим узлам системы при выходе из строя узла, выполнявшего ранее эти функции (миграция технологических задач).
4. Возможность автоматизированного восстановления функций узла, выходившего ранее из строя и затем восстановленного (обратная миграция технологических задач).
5. Возможность использования средств виртуализации при развертывании системы.
3.3. Выбор операционной системы и стандартов разработки
Выбор операционной системы (ОС) производится, как правило, по следующим критериям:
1. Возможность обеспечения реального времени.
2. Поддержка стандартного стека сетевых протоколов, с возможностью работы на уровне IP и ниже.
3. Поддержка используемого аппаратного обеспечения и/или системы виртуализации.
4. Удобство разработки программного обеспечения, поддержка стандартов в данной области.
5. Удобство настройки и эксплуатации.
6. Наличие технической поддержки, перспективы развития, лицензирование.
7. Цена.
При всем многообразии выбора, эти критерии изначально ограничивают список до следующих наиболее распространенных вариантов:
· Семейство Windows (Windows Embedded).
· Семейство Linux.
· QNX.
· RTOS32.
К операционным системам жесткого реального времени из рассматриваемых относятся две последних – QNX и RTOS32. Кроме того, на ОС семейства Linux могут быть установлены дополнительные пакеты, обеспечивающие функциональность реального времени [6]. С одной стороны, работа в реальном времени необходима для решения задач взаимодействия с управляемым объектом, например, для ввода-вывода аварийных и управляющих дискретных сигналов. С другой стороны, для решения расчетных задач, с учетом менее строгих требований к длительности цикла расчета, обеспечение жесткого реального времени не обязательно.
В любом случае, во всех рассматриваемых ОС реализован т. н. системный таймер, срабатывающий на каждом кванте процессорного времени, на базе которого реализуются таймеры произвольной (задаваемой разработчиком) периодичности. Таким образом, выполнение действий, критичных по времени, может быть возложено на обработчик прерывания системного таймера, либо на обработчик сигналов от таймера, периодичность срабатывания которого равна кванту процессорного времени. Организация работы в реальном времени подобным образом возможна даже на ОС семейства Windows, которые, строго говоря, не являются системами реального времени.
Несмотря на стабильность и удобство работы, из рассмотрения целесообразно исключить ОС QNX 4.25, как не удовлетворяющую в полном объеме требованиям в части поддержки сетевого стека (нет доступа на уровень IP и ниже) и аппаратного обеспечения. Кроме того, на сегодняшний день компания-производитель практически отказалась от поддержки данной ОС, в пользу QNX 6 и построенной на ее базе Blackberry OS. Из рассмотрения также целесообразно исключить RTOS32, которая, несмотря на поддержку Win32 API и совместимость с Windows в части интерфейса прикладных программ, вызывает вопросы в части поддержки всего многообразия систем виртуализации. Уточненный список операционных систем выглядит следующим образом:
· Семейство Windows (Windows Embedded).
· Семейство Linux.
· QNX 6.
Как упоминалось выше, расчетные задачи, задачи взаимодействия с внешними устройствами и задачи реального времени в распределенной системе управления могут быть разделены по различным узлам. Следовательно, для каждого класса задач может быть выбрана наиболее подходящая ОС, например, Windows Embedded для расчетных задач, Debian Linux для задач взаимодействия с внешними устройствами и QNX 6 для задач реального времени. В связи с этим встает вопрос совместимости рассматриваемых ОС по интерфейсу прикладных программ. Так, QNX 6 предусматривает весьма удобные механизмы межпроцессного и сетевого взаимодействия для построения распределенных систем, прозрачные для разработчика технологического программного обеспечения [7]. Однако в Linux и Windows подобные механизмы реализуются только библиотеками сторонних производителей (например, различными реализациями интерфейса MPI [8, 9]), не совместимыми с QNX 6. Разработчик системы становится перед выбором – использовать в каждой ОС ее «родные» механизмы межпроцессного и сетевого взаимодействия, создавая универсальную обертку для технологических задач, или же использовать некие стандартные для всех ОС механизмы, с некоторой потерей удобства в пользу универсальности. Таким стандартом является POSIX [10], с некоторыми оговорками: QNX 6 и Linux являются на сегодняшний день POSIX-совместимыми «из коробки», в то время как Windows требует установки дополнительных библиотек, реализующих POSIX-слой (например, UWIN, Cygwin, SUA).
Таким образом, целесообразно принять следующий подход к программированию распределенной системы управления: максимальное использование стандарта POSIX, с переходом к системно-зависимым функциям только в том случае, если это неизбежно (например, при обработке прерываний). При этом, для технологических задач разрабатывается обертка, инкапсулирующая функции нижнего уровня, для упрощения их переноса из одной операционной системы в другую.
3.4. Принципы определения состояния системы. Механизмы взаимодействия между узлами.
От принципов программирования перейдем к архитектуре распределенной системы управления.
Казалось бы, существует стандарт МЭК 61850 [11], описывающий, в том числе, принципы взаимодействия между узлами распределенной системы [12], и сравнительно широко, на сегодняшний день, поддерживаемый производителями средств промышленной автоматизации. Однако, данный стандарт не удовлетворяет всем требованиям, изложенным в постановочной части. Прежде всего, МЭК 61850, при правильном проектировании, жестко и однозначно задает структуру вычислительной системы, не предусматривая возможности передачи каких-то функций другим узлам. Данный подход оправдан для узлов, непосредственно взаимодействующих с объектом управления, передающих управляющие сигналы и т. п., т. е. решающих задачи реального времени, но при этом неудобен для решения других задач. Кроме того, состояние системы в целом в данном стандарте может быть определено лишь на верхнем уровне иерархии управления.
В связи с этим, было принято решение разработать собственные принципы определения состояния системы и, на основе этих принципов, механизмы взаимодействия между узлами, с возможным использованием наработок МЭК 61850 и других стандартов.
Итак, для определения состояния системы в целом в каждый момент времени, необходимо обеспечить ее наблюдаемость, т. е. определение состояния каждого узла системы и своевременную доставку этой информации на все узлы. Логически, узлы должны быть связаны «каждый с каждым», что естественным образом приводит систему к топологии «шина».
Следовательно, необходимо организовать некую шину данных, в которую каждый узел системы периодически отправляет сообщение, однозначно определяющее текущее состояние узла (назовем его «слово состояния»), и откуда, в свою очередь, каждый узел получает слова состояния остальных узлов. Каждый узел из полученных им сообщений формирует у себя общее слово состояния системы. Таким образом, каждый узел независимо наблюдает и оценивает текущее состояние децентрализованной системы.
К слову состояния узла предъявляются следующие требования:
1. Сообщение должно включать информацию, однозначно определяющую состояния узла, как минимум: идентификатор узла, пульс активности, состав запущенных процессов.
2. Сообщение должно быть коротким по размеру, в идеале – в пределах стандартного Ethernet-пакета (около 1400 байт).
3. Сообщение должно быть доставлено быстро и по возможности одномоментно всем узлам.
С учетом этих требований, обмен состояниями узлов (и другими сообщениями, к которым могут быть предъявлены схожие требования) организован на базе групповой (multicast) рассылки UDP-сообщений, с использованием принципов, определенных стандартом МЭК 61850 (в части GOOSE-сообщений). Для независимого контроля активности узлов, в слово состояния узла добавлена т. н. маска активности узлов, которая формируется локально на каждом узле по факту получения слова состояния от других узлов системы. Таким образом, кроме пульса активности, формируемого и отправляемого самим узлом, контролируется физическая доступность данного узла и, соответственно, физическая целостность канала связи.
Кроме обмена состояниями, узлам распределенной системы управления необходимо обмениваться данными произвольного, в зависимости от конкретной настройки, объема. Так, на расчетные узлы должны периодически поступать подготовленные исходные данные, а результаты расчета должны передаваться на предвключенную машину для их сведения и дальнейшей обработки. При этом:
1. Данные должны быть актуальными.
2. Данные должны поступать одновременно на расчетные машины.
3. Успешное получение данных должно подтверждаться.
Кроме того, при запуске узла он должен получать актуальные данные настройки.
Как видно, требования к обмену данными функционально подобны требованиям к обмену словами состояния. В связи с этим, обмен данными также организован на базе групповой рассылки UDP-пакетов, с использованием специально разработанного механизма подписок на данные.
Идея механизма подписок заключается в следующем. На этапе конфигурирования системы описываются определенные наборы таблиц (файлов) данных, каждый из которых имеет определенный узел-источник. При помощи специальной области в слове состояния, узел сообщает, какие именно наборы данных он желает получать. Узел-источник набора данных, зафиксировав факт подписки, начинает широковещательно рассылать данные из этого набора, с возможным (определяется настройкой) контролем получения данных. В свою очередь, узел-приемник, получив набор данных, согласно настройке может подтверждать получение.
Данный механизм позволяет сконфигурировать первоначальную загрузку всех необходимых данных на узел (по старту узла), периодическое обновление необходимых исходных данных на узле, сбор всех таблиц данных системы на определенном узле с целью архивирования, обмен сообщениями произвольного размера и т. п.
3.5. Управление функциями узлов системы. Передача функций, миграция задач.
Частью конфигурации распределенной системы управления является также состав задач (программных модулей), запускаемых на определенных узлах системы. При этом часть задач, которые являются системообразующими, т. е. формируют среду исполнения для технологических задач (например, механизмы обмена данными и подписок на данные), должна запускаться на всех узлах. В то же время расчетные задачи, задачи предвключенной машины, задачи реального времени должны запускаться только на предназначенных для этого узлах. Кроме того, для каждой задачи должна быть определена дисциплина поведения при фиксации сбоя в функционировании либо при невозможности запуска: количество попыток перезапуска задачи, необходимость перезапуска узла, возможность продолжения работы узла при остановленной задаче и т. п.
Функции запуска, останова, контроля состояния задач, запускаемых на конкретном узле распределенной системы управления, возлагаются на данный узел. Однако, для успешного выполнения этих функций, следует учитывать состояние системы в целом, что в децентрализованной системе приводит к необходимости выделения функции арбитра системы. Арбитр, на основании текущей информации о состоянии системы, дает команды узлам на запуск и останов процессов, при помощи специальной области в своем слове состояния. Функция арбитра является переходящей. Текущий узел-арбитр определяется в результате выборов следующим образом.
В конфигурации системы описывается, какие узлы могут принимать на себя роль арбитра, и в какой последовательности (приоритет узлов). В зависимости от идентификатора узла, определяется интервал выборов арбитра, уникальный для каждого узла. Затем, с указанной периодичностью, каждый узел, имеющий право быть арбитром, проверяет:
1. Активен ли текущий арбитр.
2. Если текущий арбитр неактивен, не принял ли один из более приоритетных узлов на себя роль арбитра.
3. Если никто не принял на себя роль арбитра, активны ли более приоритетные кандидаты на роль арбитра.
4. Если ни один из более приоритетных кандидатов не активен, узел принимает функции арбитра на себя и сообщает об этом всем в слове состояния.
В случае выхода из строя одного из узлов распределенной системы управления, либо остановки узла для проведения регламентных работ, либо при нарушении физической связи с данным узлом необходимо передать все его функции другому узлу, с целью резервирования. Механизм миграции задач организован следующим образом:
Для каждой задачи в конфигурации системы описывается, на каких узлах задача может запускаться, в какой последовательности (приоритет узлов), а также количество одновременно запущенных в системе экземпляров данной задачи. При первоначальном запуске задачи арбитр подает соответствующую команду на первый активный узел из очереди приоритетов для данной задачи, на последующие активные узлы из очереди – для запуска остальных экземпляров задачи. В случае пропадания одного из узлов из системы, выдается команда на запуск задачи на следующем по приоритету активном узле, на котором данная задача еще не запущена (рис. 3а).
При восстановлении активности выведенного из системы узла в связи с устранением причины сбоя или окончанием регламентных работ, арбитр выдает команду на останов всех экземпляров задачи, а затем – на запуск с учетом изменений в очереди узлов, т. е. со сдвигом к ее началу (рис. 3б). Таким образом, обеспечивается обратная миграция задач на восстановленный узел.
Необходимо отметить, что команда на останов задачи в процессе ее миграции всегда выдается раньше, чем команда на запуск, с тем, чтобы не превысить заданное количество одновременно запущенных экземпляров задачи в системе.
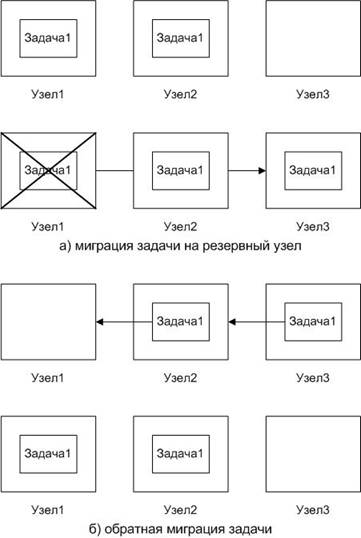
Рис. 3: Миграция задачи при выходе из строя узла системы
Из опыта разработки дублированных устройств ПАУ [5] известно, что функции основного и резервного экземпляра одной и той же системообразующей или технологической задачи могут отличаться. Поскольку дублированная система управления является частным случаем вырожденной распределенной системы, необходимо предусматривать такую возможность и при создании более сложных систем. В связи с этим, был разработан следующий механизм резервирования отдельных задач, с учетом разделения функций основного и резервного экземпляров:
Для резервированной задачи с разделением функций, при конфигурировании системы указываются параметры запуска основного и резервного экземпляров, а также очередь узлов, на которых запускается данная задача, и максимальное количество запущенных экземпляров. Однако, очередь узлов здесь имеет иной смысл, по сравнению с простой миграцией задачи. На первом активном в очереди узле всегда запускается основной экземпляр задачи, в то время как на остальных узлах очереди запускаются резервные экземпляры. При пропадании из системы узла, на котором выполнялся основной экземпляр, первому из оставшихся в очереди узлов выдается команда на изменение роли задачи с резервной на основную. Кроме того, в зависимости от количества экземпляров, выдаются команды на запуск дополнительных резервных задач на следующих в очереди узлах (рис. 4а).
При восстановлении активности выведенного из системы узла, роли экземпляров задачи сдвигаются к началу очереди узлов, аналогично простой миграции задачи (рис. 4б).
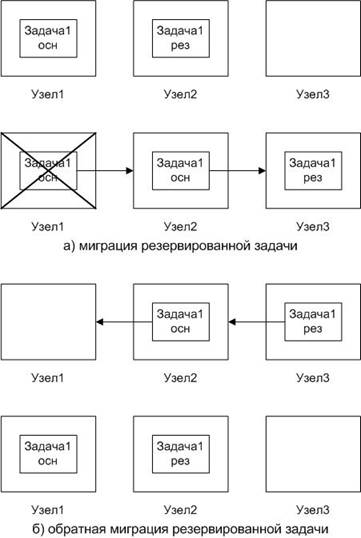
Рис. 4: Миграция резервированной задачи при выходе из строя узла системы
4. ЗАКЛЮЧЕНИЕ
В настоящее время, в разрабатывается универсальная программная платформа для обеспечения функционирования технологических задач в распределенной вычислительной системе управления. Использование перечисленных в статье подходов при разработке системы:
· Минимизирует зависимость платформы от используемой операционной системы.
В современных условиях, ситуация на рынке программного и аппаратного обеспечения меняется крайне быстро. Так, еще десять лет назад снятие с производства программного продукта было редкостью, на сегодняшний день это один из рассматриваемых рисков, даже в сегменте промышленной автоматизации. Снижение зависимости от используемой операционной системы, позволяет застраховаться от подобных рисков.
· Дает возможность широкого использования средств виртуализации.
Использование средств виртуализации дает, в свою очередь, независимость от аппаратного обеспечения для расчетных задач. Кроме того, данное направление актуально при разработке систем управления цифровыми подстанциями.
· Дает возможность масштабирования платформы на устройства различных уровней иерархии противоаварийного управления.
Объединение устройств ПА на единой платформе в пределах объекта в распределенную систему управления позволяет организовать обмен технологической информацией, архивирование, централизованное взаимодействие с внешними системами и т. п.
ЛИТЕРАТУРА
[1] , , . Программное обеспечение отказоустойчивых распределенных вычислительных систем для управления электроэнергетическими системами. // Научные проблемы транспорта Сибири и Дальнего Востока. – 2009. – Спецвыпуск. – №1. – С.155-160.
[2] , , . Использование отказоустойчивых распределенных вычислительных систем для управления электроэнергетическими системами. // Сборник докладов международной научно-технической конференции «Современные направления развития систем релейной защиты и автоматики энергосистем». – СПб, 2011.
[3] , , . Перспективы совершенствования алгоритмов централизованной противоаварийной автоматики. // Сборник докладов международной научно-технической конференции «Современные направления развития систем релейной защиты и автоматики энергосистем». – Екатеринбург, 2013.
[4] СТО 59012820.29.240.001-2011. Автоматическое противоаварийное управление режимами энергосистем. Противоаварийная автоматика энергосистем. Условия организации процесса. Условия создания объекта. Нормы и требования. М., 2011.
[5] , , . Разработка интегрированной системы ПА ОЭС Сибири. // Релейная защита и автоматика энергосистем 2010. Сборник докладов XX конференции (Москва, 1-4 июня 2010). - М., «Научно-инженерное информационное агентство», 2010. – С. 52-59.
[6] Herman Bruyninckx. Real-Time and Embedded Guide. – Leuven, Belgium, 2002.
[7] Роб Кертен. Введение в QNX/Neutrino 2. – СПб., «Петрополис», 2001.
[8] Эрик Ланц. Использование интерфейса обмена сообщениями Microsoft (MS-MPI). – Microsoft, 2008.
[9] William Gropp and Ewing Lusk. User’s guide for mpich, a portable implementation of MPI. Technical Report ANL-96/6, Argonne National Laboratory, 1996.
[10] The Open Group Base Specifications Issue 6, IEEE Std 1003.1-2004. General Information. Copyright © 2004 The IEEE and The Open Group.
[11] IEC munication networks and systems in substations. Part 1: Introduction and overview. Copyright © 2003 IEC
[12] IEC munication networks and systems in substations. Part 8-1: Specific communication Service Mapping (SCSM) – Mappings to MMS (ISO 9506-1 and ISO 9506-2) and to ISO/IEC 8802-3. Copyright © 2004 IEC
