
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Вычислительные системы с распределенной памятью
Это вычислительные узлы, объединенные коммуникационной средой.
Каждый вычислительный узел имеет один или несколько процессоров и свою собственную локальную память, разделяемую этими процессорами. Каждый процессор имеет непосредственный доступ только к локальной памяти своего узла. Доступ к данным, расположенным в памяти других узлов, выполняется дольше и другими, более сложными способами. В последнее время в качестве узлов все чаще и чаще используют полнофункциональные компьютеры, содержащие, например, и собственные внешние устройства. Коммуникационная среда может специально проектироваться для данной вычислительной системы либо быть стандартной сетью, доступной на рынке.
Преимущества:
· покупатель может достаточно точно подобрать конфигурацию в зависимости от имеющегося бюджета и своих потребностей в вычислительной мощности;
· cоотношение цена/производительность у систем с распределенной памятью ниже, чем у компьютеров других классов;
· такая схема дает возможность практически неограниченно наращивать число процессоров в системе и увеличивать ее производительность.
Большое число подключаемых процессоров даже определило специальное, название для систем данного класса: компьютеры с массовым параллелизмом или массивно-параллельные компьютеры. Уже сейчас в мире существуют десятки компьютеров, в составе которых работает более тысячи процессоров.
Широкое распространение компьютеры с такой архитектурой получили с начала 90-х годов прошлого столетия.
· Intel Paragon - Intel i860, расположенных в узлах прямоугольной двумерной решетки;
· IBM SP1/SP2 - использовалось несколько процессоров, в частности, PowerPC, P2SC и POWER3. Их взаимодействие идет через иерархическую систему высокопроизводительных коммутаторов, что дает потенциальную возможность общения каждого узла с каждым;
· Cray T3D/T3E - процессоры DEC Alpha и топология трехмерного тора.
Итак, компьютеры Cray T3D/T3E — это массивно-параллельные компьютеры с распределенной памятью, объединяющие в максимальной конфигурации более 2000 процессоров. Как и любые компьютеры данного класса, они содержат два основных компонента: узлы и коммуникационную среду.
Узлы делятся на три типа:
· управляющие - Эти узлы работают в многопользовательском режиме, на этих же узлах выполняются однопроцессорные программы и работают командные файлы.
· узлы операционной системы - Эти узлы поддерживают выполнение многих системных сервисных функций ОС, в частности, работу с файловой системой. Недоступны пользователям напрямую.
· вычислительные узлы - предназначены для выполнения программ пользователя в монопольном режиме. При запуске программе выделяется требуемое число узлов, которые за ней закрепляются вплоть до момента ее завершения. Гарантируется, что никакая программа не сможет занять вычислительные узлы, на которых уже работает другая программа.
Число узлов каждого типа зависит от конфигурации системы. В частности, данные, взятые из двух реальных конфигураций Cray T3E, выглядят так: 24/16/576 или 7/5/260 (управляющие узлы/ узлы ОС/ вычислительные узлы).
Каждый узел последних моделей состоит из процессорного элемента (ПЭ) и сетевого интерфейса. Процессорный элемент содержит один процессор Alpha, локальную память и вспомогательные подсистемы.
Локальная память каждого процессорного элемента является частью физически распределенной, но логически разделяемой памяти всего компьютера. Память физически распределена, т. к. каждый ПЭ содержит свою локальную память. В то же время память разделяется всеми ПЭ, поскольку любой ПЭ через свой сетевой интерфейс может обращаться к памяти любого другого ПЭ, не прерывая его работы.
Сетевой интерфейс узла связан с соответствующим сетевым маршрутизатором, который является частью коммуникационной сети. Все маршрутизаторы расположены в узлах трехмерной целочисленной прямоугольной решетки и соединены между собой в соответствии с топологией трехмерного тора (рис. 3.14). Это означает, что каждый узел имеет шесть непосредственных соседей вне зависимости от того, где он расположен: внутри параллелепипеда, на ребре, на грани или в его вершине.
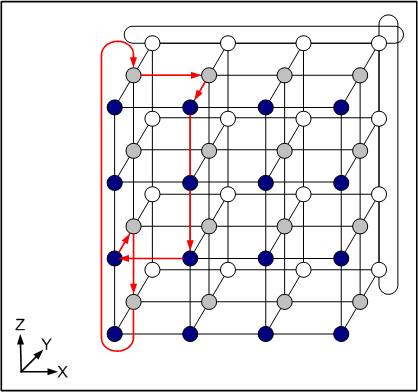
Достоинства организации коммуникационной среды:
· возможность выбора альтернативного маршрута для обхода поврежденных связей.
· быстрая связь граничных узлов и небольшое среднее число перемещений по тору при взаимодействии разных ПЭ.
Каждая элементарная связь между двумя узлами — это два однонаправленных канала передачи данных, что допускает одновременный обмен данными в противоположных направлениях.
Безусловно, интересной особенностью архитектуры компьютера является аппаратная поддержка барьерной синхронизации. Барьер — это точка в программе, при достижении которой каждый процесс должен ждать до тех пор, пока остальные процессы также не дойдут до барьера. Лишь после этого события все процессы могут продолжать работу дальше. Данный вид синхронизации часто используется в программах, но его реализация средствами системы программирования сопровождается большими накладными расходами. Поддержка барьеров в аппаратуре позволяет свести эти расходы к минимуму.
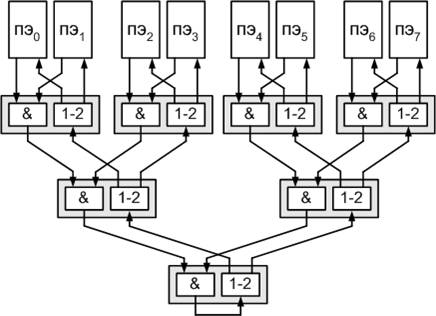
Эти же цепи в компьютерах данного семейства используются и по-другому. Если все устройства логического умножения в схеме заменить устройствами логического сложения, то получится цепь для реализации механизма "Эврика". На выходе любого устройства логического сложения единица появится в том случае, если единица есть хотя бы на одном его входе. Это значит, что как только один ПЭ записал единицу во входной регистр, эта единица распространяется всем ПЭ, сигнализируя о некотором событии на исходном ПЭ. Самая очевидная область применения данного механизма — это задачи поиска.
Помимо традиционных суперкомпьютеров типа Cray T3E или IBM SP, класс компьютеров с распределенной памятью в последнее время активно расширяется за счет вычислительных кластеров.
Вычислительный кластер есть совокупность компьютеров, объединенных в рамках некоторой сети для решения одной задачи (рис. 3.16). В качестве вычислительных узлов обычно используются доступные на рынке однопроцессорные компьютеры, двух - или четырех-процессорные SMP-серверы. Каждый узел работает под управлением своей копии операционной системы, в качестве которой чаще всего используются стандартные ОС: Linux, Windows NT, Solaris и т. п. Состав и мощность узлов могут меняться даже в рамках одного кластера, что дает возможность создавать неоднородные системы. Выбор конкретной коммуникационной среды определяется многими факторами: особенностями класса решаемых задач, доступным финансированием, необходимостью последующего расширения кластера и т. п. Возможно включение в конфигурацию кластера специализированных компьютеров, например, файл-сервера. Как правило, предоставляется возможность удаленного доступа на кластер через Интернет.
Кластерные проекты
Beowulf-кластеры (1994 год) – NASA, 16-процессорный кластер, 16 Мбайт ОЗУ, 3 сетевых адаптера Ethernet. Были разработаны специальные драйверы для распределения трафика.
TheHIVE (Highly-parallel Integrated Virtual Environment) - кластер состоит из четырех подкластеров, объединяя 332 процессора и два выделенных хост-компьютера. Все узлы данного кластера работают под управлением Red Hat Linux.
Avalon (1998 год) – 68 процессоров (увеличили до 140), 256 Мбайт ОЗУ, HDD 3 Гбайт, Fast Ethernet, 47,7 Гфлопс.
Velocity+ (2000 год) – Корнельский университет биомедицинский исследований, 64 узла * 4 процессора Intel Pentium III, Windows 2000, cLAN.
LoBoS (Lots of Boxes on Shelfes, 1997 год) – Национальный Институт здоровья США. Gigabit Ethernet, 47 узлов * 2 процессора Intel Pentium Pro, 128 Мбайт ОЗУ.
LoBoS2 (1998 год) – Национальный Институт здоровья США. Gigabit Ethernet, 100 узлов * 2 процессора Intel Pentium II, 256 Мбайт ОЗУ.
Chiba City – Аргонская Национальная лаборатория. 256 вычислительных узлов * 2 процессора Pentium III, 512 Мб ОЗУ.
· Раздел виртуализации: 32 компьютера IBM Intellistation с графическими картами Matrox Millenium G400, 512 Мбайт оперативной памяти и дисками 300 Гбайт.
· Раздел хранения данных: 8 серверов IBM Netfinity 7000 с процессорами Хеоn/500 МГц и дисками по 300 Гбайт
· Управляющий раздел: 12 компьютеров IBM Netfinity 500
Объединены сетью Myrinet, которая используется для поддержки параллельных приложений. Для управляющих и служебных целей используются сети Gigabit Ethernet и Fast Ethernet. Все разделы делятся на "города" (towns) по 32 компьютера. Каждый из них имеет своего "мэра", который локально обслуживает свой "город", снижая нагрузку на служебную сеть и обеспечивая быстрый доступ к локальным ресурсам.
MBC-1000M - установлен в Межведомственном суперкомпьютерном центре в Москве. Cостоит из шести базовых блоков, содержащих по 64 двухпроцессорных модуля. Каждый модуль имеет два процессора Alpha 21264/667 МГц (кэш-память второго уровня 4 Мбайт), 2 Гбайт оперативной памяти, разделяемой процессорами модуля, жесткий диск. Общее число процессоров в системе равно 768, а пиковая производительность МВС-1000М превышает 1 Тфлопс.
Все модули МВС-1000М связаны двумя независимыми сетями. Сеть Myrinet 2000 используется программами пользователей для обмена данными в процессе вычислений. При использовании MPI пропускная способность каналов сети достигает значений 110—170 Мбайт/с. Сеть Fast Ethernet используется операционной системой для выполнения сервисных функций.
IBM RoadRunner (2008 год) – самый мощный кластер на настоящее время. Производительнсть 1,096 Петафлопс. Состоит из блоков TriBlade, который по 180 штук создают объединенный модуль. Кластер состоит из 18 таких модулей.
Всего в состав IBM RoadRunner входит 6480 двухъядерных процессоров Opteron и 12 960 процессоров Cell.
Коммуникационные технологии построения кластеров
Понятно, что различных вариантов построения кластеров очень много. Одно из существенных различий лежит в используемой сетевой технологии, выбор которой определяется, прежде всего, классом решаемых задач.
Первоначально Beowulf-кластеры строились на базе обычной 10-мегабитной сети Ethernet. Сегодня часто используется сеть Fast Ethernet, как правило, на базе коммутаторов. Основное достоинство такого решения — это низкая стоимость. Вместе с тем, большие накладные расходы на передачу сообщений в рамках Fast Ethernet приводят к серьезным ограничениям на спектр задач, эффективно решаемых на таких кластерах. Если от кластера требуется большая универсальность, то нужно переходить на другие, более производительные коммуникационные технологии. Исходя из соображений стоимости, производительности и масштабируемости, разработчики кластерных систем делают выбор между Fast Ethernet, Gigabit Ethernet, SCI, Myrinet, cLAN, ServerNet и рядом других сетевых технологий.
Необходимых пользователю характеристик коммуникационных сетей две:
· латентность - время начальной задержки при посылке сообщений.
· пропускная способность - скоростью передачи информации по каналам связи.
Если в программе много маленьких сообщений, то сильно скажется латентность. Если сообщения передаются большими порциями, то важна высокая пропускная способность каналов связи. Из-за латентности максимальная скорость передачи по сети не может быть достигнута на сообщениях с небольшой длиной.
На практике пользователям не столько важны заявляемые производителем пиковые характеристики, сколько реальные показатели, достигаемые на уровне приложений. После вызова пользователем функции посылки сообщения Send() сообщение последовательно проходит через целый набор слоев, определяемых особенностями организации программного обеспечения и аппаратуры. Этим, в частности, определяются и множество вариаций на тему латентности реальных систем.
Выделим факторы, снижающие производительность вычислительных систем с распределенной памятью на реальных программах.
Начнем с уже упоминавшегося ранее закона Амдала («В случае, когда задача разделяется на несколько частей, суммарное время ее выполнения на параллельной системе не может быть меньше времени выполнения самого длинного фрагмента»). Для компьютеров данного класса он играет очень большую роль. В самом деле, если предположить, что в программе есть лишь 2% последовательных операций, то рассчитывать на более чем 50-кратное ускорение работы программы не приходится. Теперь попробуйте критически взглянуть на свою программу. Скорее всего, в ней есть инициализация, операции ввода/вывода, какие-то сугубо последовательные участки. Оцените их долю на фоне всей программы и на мгновенье предположите, что вы получили доступ к вычислительной системе из 1000 процессоров. После вычисления верхней границы для ускорения программы на такой системе, думаем, станет ясно, что недооценивать влияние закона Амдала никак нельзя.
Если аппаратура или программное обеспечение не поддерживают возможности асинхронной посылки сообщений на фоне вычислений, то возникнут неизбежные накладные расходы, связанные с ожиданием полного завершения взаимодействия параллельных процессов.
Для достижения эффективной параллельной обработки необходимо добиться максимально равномерной загрузки всех процессоров. Если равномерности нет. То часть процессоров неизбежно будет простаивать, ожидая остальных, хотя в это время они вполне могли бы выполнять полезную работу. Данная проблема решается проще, если вычислительная система однородна. Очень большие трудности возникают при переходе на неоднородные системы, в которых есть значительное различие либо между вычислительными узлами, либо между каналами связи.
Существенный фактор — это реальная производительность одного процессора вычислительной системы. Разные модели микропроцессоров могут поддерживать несколько уровней кэш-памяти, иметь специализированные функциональные устройства и т. п. Возьмем хотя бы иерархию памяти компьютера Cray T3E: регистры процессора, кэш-память 1-го уровня, кэш-память 2-го уровня, локальная память процессора, удаленная память другого процессора. Эффективное использование такой структуры требует особого внимания при выборе подхода к решению задачи.
К сожалению, как и прежде, на работе каждой конкретной программы в той или иной мере сказываются все эти факторы. Однако в отличие от компьютеров других классов, суммарное воздействие изложенных здесь факторов может снизить реальную производительность не в десятки, а в сотни и даже тысячи раз по сравнению с пиковой. Потенциал компьютеров этого класса огромен, добиться на них можно очень многого. Однако могут потребоваться значительные усилия. Все этапы в решении каждой задачи, начиная от выбора метода до записи программы, нужно продумывать очень аккуратно.
