
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Тема 4. Нелинейные регрессии
4.1. Классификация нелинейных регрессий
Между социально-экономическими явлениями и процессами не всегда существуют линейные соотношения, и часто их нельзя упрощенно выразить линейными функциями из-за неоправданно больших ошибок, возникающих при этом. В таких случаях для описания зависимостей используют нелинейные регрессии.
Для выбора и обоснования типа кривой регрессии нет универсального метода.
Односторонняя стохастическая зависимость между явлениями может быть описана, например, с помощью полиномиальной регрессии ![]() или с помощью гиперболической регрессии
или с помощью гиперболической регрессии 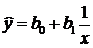 . Применяются также степенная, показательная, логарифмическая и тригонометрические функции.
. Применяются также степенная, показательная, логарифмическая и тригонометрические функции.
Выбор функции регрессии должен проводиться с применением теории той конкретной науки, на базе которой возникает задача измерения связи между явлениями. О характере зависимости между экономическими явлениями часто судят по внешнему виду эмпирического облака рассеяния.
Классы нелинейных регрессий:
![]() существенно линейные (квазилинейные) – регрессии, нелинейные по отношению к включенным в анализ объясняющим переменным
существенно линейные (квазилинейные) – регрессии, нелинейные по отношению к включенным в анализ объясняющим переменным ![]() , но линейные относительно неизвестных параметров
, но линейные относительно неизвестных параметров ![]() . Для них возможно непосредственное применение МНК.
. Для них возможно непосредственное применение МНК.
![]() существенно нелинейные – регрессии, нелинейные как по объясняющим переменным, так и по неизвестным параметрам. Непосредственное применение МНК для них невозможно.
существенно нелинейные – регрессии, нелинейные как по объясняющим переменным, так и по неизвестным параметрам. Непосредственное применение МНК для них невозможно.
Общий вид квазилинейной регрессии:
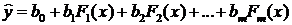 ,
,
где 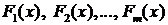 – функции от объясняющих переменных
– функции от объясняющих переменных ![]() . Например, это могут быть функции вида
. Например, это могут быть функции вида ![]() или
или ![]() и т. д.
и т. д.
Для применения МНК достаточно сделать замену:
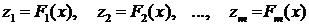
и рассматривать линейную регрессию
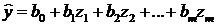 , параметры которой совпадают с параметрами исследуемой квазилинейной регрессии.
, параметры которой совпадают с параметрами исследуемой квазилинейной регрессии.
При нахождении параметров существенно нелинейных регрессий применяют итерационные методы либо прибегают к аппроксимации параметров искомой зависимости. Строгой теории нелинейной регрессии пока нет.
Наиболее распространенный метод оценки параметров нелинейных регрессий состоит в линейном преобразовании нелинейного уравнения регрессии, что дает возможность применять к ним МНК.
4.2. Спецификация формы связи между переменными
При подборе функции регрессии желательно, чтобы она обладала свойствами, присущими исследуемой зависимости.
Остановимся на моделировании монотонных процессов, для которых при 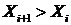 разность
разность 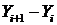 сохраняет постоянный знак. При
сохраняет постоянный знак. При ![]() функцию регрессии называют кривой роста (положительная регрессия), при
функцию регрессии называют кривой роста (положительная регрессия), при ![]() – кривой спада (отрицательная регрессия). Такие кривые позволяют описывать монотонные процессы трех основных типов:
– кривой спада (отрицательная регрессия). Такие кривые позволяют описывать монотонные процессы трех основных типов:
![]() без предела роста (спада);
без предела роста (спада);
![]() с пределом роста (спада) без точки перегиба;
с пределом роста (спада) без точки перегиба;
![]() с пределом роста (спада) и точкой перегиба.
с пределом роста (спада) и точкой перегиба.
Процессы без предела роста можно описывать, например, с помощью функций:
![]() линейная
линейная ![]() ;
;
![]() степенная
степенная ![]() ;
;
![]() показательная
показательная ![]() ;
;
![]() логарифмическая
логарифмическая ![]()
и др.
Процессы с пределом роста характерны для многих относительных показателей (потребление продуктов питания на душу населения, внесение удобрений на единицу площади, затраты на одну гривну произведенной продукции и др.). В таких случаях принимается гипотеза о существовании асимптотического уровня и могут быть использованы, например, такие функции:
![]() первая и вторая функции Торнквиста,
первая и вторая функции Торнквиста,
![]() гиперболическая функция
гиперболическая функция ![]() .
.
![]() кривая Филипса и др.
кривая Филипса и др.
Кривые, описывающие процессы с пределом роста и точкой перегиба широко используются при статистическом анализе спроса на некоторые новые товары. Наиболее простой и удобной для практики является кривая Джонсона
![]() ,
, ![]() .
.
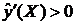 при Х >0, то есть кривая Джонсона возрастает при положительных значениях Х. По второй производной существует точка перегиба при
при Х >0, то есть кривая Джонсона возрастает при положительных значениях Х. По второй производной существует точка перегиба при 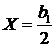 .
.
Слева от этой точки наблюдается возрастание функции с положительным ускорением (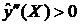 ), а справа от точки
), а справа от точки ![]() функция растет с замедлением (
функция растет с замедлением (![]() ).
).
При 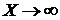 ,
, 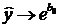
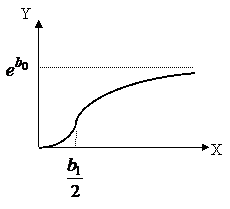

Таким образом, предварительный качественный экономический анализ исследуемого процесса или явления может выявить особенности данной зависимости, что наложит определенные требования на уравнение регрессии, а это сузит круг функций, подходящих для ее описания.
4.3. Моделирование монотонных процессов
При моделировании монотонных процессов, когда количество наблюдений невелико и неясно, есть ли асимптотический уровень и перегиб, может быть использована одна из парных функций:
1. 2. 3. 4. 5. | 6. 7. 8. 9. |
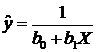 ;
;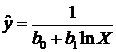 ;
;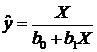 .
.Первые производные этих функций при ![]() имеют постоянные знаки, то есть сами функции или всегда возрастают, или всегда убывают при положительных значениях Х (в зависимости от значений параметров).
имеют постоянные знаки, то есть сами функции или всегда возрастают, или всегда убывают при положительных значениях Х (в зависимости от значений параметров).
Приведенные девять зависимостей имеют такое свойство: если все опытные точки (![]() ) удовлетворяют одному из этих уравнений, то и средние значения
) удовлетворяют одному из этих уравнений, то и средние значения ![]() и
и ![]() также ему удовлетворяют. При этом, в качестве средних могут быть:
также ему удовлетворяют. При этом, в качестве средних могут быть:
![]() среднее арифметическое –
среднее арифметическое – ![]() ,
,
![]() среднее геометрическое –
среднее геометрическое – ![]() ,
,
![]() среднее гармоническое –
среднее гармоническое – 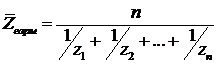 .
.
Специфика регрессионного анализа состоит в том, что с помощью уравнения регрессии описывают стохастические зависимости. В этом случае опытные точки не лежат на некоторой кривой, а рассеяны около нее. Однако, несмотря на это, точка с координатами, равными определенным средним значениям, обязательно должна лежать на кривой. Каждая из предложенных функций имеет свою характерную точку:
Вид эмпирической функции |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Для проверки пригодности выбранной эмпирической функции, используя исходные опытные данные, находят соответствующие средние значения ![]() и
и ![]() . Таким образом, наряду с диаграммой рассеивания, построенной на основании эмпирических данных, мы получим девять характерных точек, через которые обязаны пройти девять предложенных кривых. Тогда кривые можно сравнивать между собой на основании того, насколько их характерные точки согласовываются с эмпирическим облаком рассеивания.
. Таким образом, наряду с диаграммой рассеивания, построенной на основании эмпирических данных, мы получим девять характерных точек, через которые обязаны пройти девять предложенных кривых. Тогда кривые можно сравнивать между собой на основании того, насколько их характерные точки согласовываются с эмпирическим облаком рассеивания.
Критерий выбора наилучшей функции регрессии: 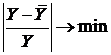 .
.
В данном случае мы располагаем прогнозными значениями (средние значениями зависимой переменной) для случая, когда независимая переменная принимает свое среднее значение: ![]() .
.
Далее нужно определить значение зависимой переменной ![]() , которое ожидается в реальной экономической действительности. При этом возможны два случая:
, которое ожидается в реальной экономической действительности. При этом возможны два случая:
![]() данная ситуация уже проверена опытным путем, то есть соответствующее среднее значение
данная ситуация уже проверена опытным путем, то есть соответствующее среднее значение ![]() есть среди исходных статистических данных;
есть среди исходных статистических данных;
![]() среднего значения объясняющей переменной нет среди исходных данных.
среднего значения объясняющей переменной нет среди исходных данных.
В первом случае мы сразу имеем реальное значение зависимой переменной.
Во втором случае соответствующее значение ![]() можно определить с помощью линейной интерполяции, соединив отрезком две соседние точки с координатами (
можно определить с помощью линейной интерполяции, соединив отрезком две соседние точки с координатами (![]() ), (
), (![]() ). Здесь
). Здесь ![]() и
и ![]() – промежуточные значения, между которыми находится
– промежуточные значения, между которыми находится ![]() (
(![]() ). При этом нет ни одной опытной точки с координатами (х, y), для которой
). При этом нет ни одной опытной точки с координатами (х, y), для которой ![]() или
или ![]() .
.
Из уравнения прямой получим: 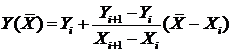 .
.
Процедура выбора наилучшей функции для описания некоторого монотонного процесса проходит следующим образом: для предложенных девяти функций регрессии находят координаты характерных точек. Далее определяют значения зависимой переменной ![]() и сравнивают его со значением
и сравнивают его со значением ![]() с помощью указанного критерия. Результаты всех проведенных расчетов удобно представлять в табличной форме:
с помощью указанного критерия. Результаты всех проведенных расчетов удобно представлять в табличной форме:
Вид функции |
|
|
|
|
Функция, которая получит наименьшую оценку, будет считаться наилучшей для описания данного монотонного процесса.
