

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Концепция хранилища данных: основные архитектуры и принципы построения
Уильям Инмон, считающийся основателем этого направления дал классическое определение информационного хранилища в 1990г. Хранилище данных – предметно-ориентированный, интегрированный, привязанный ко времени и неизменяемый набор данных (в виде специально администрируемой БД), предназначенный для поддержки принятия решения.
Указанные в определении характеристики можно рассматривать следующим образом:
Предметная ориентированность. Хранилище данных организуется вокруг основных объектов (предметов) или субъектов организации (клиенты, товары), а не вокруг прикладных областей деятельности (выставление счета, контроль запасов и продажа товаров).
Интегрированность. Смысл этой характеристики состоит в том, что оперативно-прикладные данные обычно поступают из разных источников, которые часто имеют несогласованные представление одних и тех же данных, например, используют разный формат. Для предоставления пользователю единого обобщенного представления данных необходимо создать интегрированный источник, обеспечивающий согласованность хранимой информации.
Привязка ко времени. Данные в хранилище точны и действительны только в том случае, если они привязаны к некоторому моменту или промежутку времени.
Неизменяемость. Это означает, что данные не обновляются в оперативном режиме, а лишь регулярно пополняются за счет информации из оперативных систем обработки. При этом новые данные никогда не заменяют, а лишь дополняют прежние. Таким образом, база данных хранилища постоянно пополняется новыми данными, последовательно интегрируемыми с уже накопленной информацией.
Миминизация избыточности информации. Избыточность данных в DW системах минимальна (около 1%) и это объясняется следующими причинами: при загрузке данных в хранилище они фильтруются, сортируются, очищаются от ненужной информации и приводятся к единому формату, а некоторые из них вообще не попадают в DW из OLTP поскольку лишены смысла с точки зрения использования в системах поддержки решений; в DW хранится некая итоговая информация, которая в базах OLTP вообще отсутствует.
Основные компоненты информационного хранилища
Концептуально модель хранилища данных можно представить в виде схемы.
Данные из различных источников помещаются в хранилище, а их описания - в репозиторий метаданных. Конечный пользователь, используя различные инструменты (средства визуализации, построения отчетов, статистической обработки и т. д.) и содержимое репозитория, анализирует данные из хранилища. Результатом является информация в виде готовых отчетов, найденных скрытых закономерностей, каких-либо прогнозов. Так как средства работы конечного пользователя с хранилищем данных могут быть самыми разнообразными, то теоретически их выбор не должен влиять на структуру хранилища и функции его поддержания в актуальном состоянии. Физическая реализация данной концептуальной схемы может быть самой разнообразной.
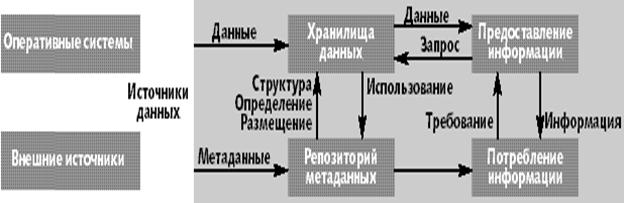
Исходные данные, помещаемые в хранилище, поступают из следующих источников.
· Оперативные данные, содержащиеся в иерархических и сетевых БД первого поколения.
· Оперативные данные, содержащиеся в реляционных БД.
· Данные, сохраняемые в специализированных файловых системах.
· Внешние системы, например, Intanet, электронные архивы.

Хранилище оперативных данных. Хранилище оперативных данных представляет собой репозиторий для текущих и интегрированных оперативных данных. Чаще всего оно структурируется и заполняется данными по такому же принципу, как и обычное хранилище, но фактически применяется просто как область накопления данных перед их передачей в обычное хранилище. Такие системы создаются для поддержки устаревших прикладных систем, которые обнаруживают свою неприспособленность к современным требованиям по формированию отчетов.
Диспетчер загрузки. Еще его называют внешним компонентом, выполняет все операции, связанные с извлечением и загрузкой данных в хранилище. Данные могут извлекаться непосредственно из источников данных, а в последнее время для этого все чаще применяются хранилища оперативных данных. Операции, выполняемые диспетчером загрузки, включают простые преобразования данных, необходимые для их подготовки к вводу в хранилище. Размеры и сложность данного компонента зависят от типа хранилища данных, а в его состав обычно входят не только программы собственной разработки, но и инструменты загрузки, созданные независимыми поставщиками.
Диспетчер хранилища. Диспетчер хранилища выполняет все операции, связанные с управлением информацией, помещенной в хранилище данных. Этот компонент может также включать программы собственной разработки и инструменты, представленные независимыми компаниями. Диспетчер хранилища выполняет следующие операции:
· Анализ непротиворечивости данных;
· Преобразование и перемещение исходных данных из временной области хранения и основные таблицы хранилища данных;
· Создание индексов и представлений для базовых таблиц;
· Денормализация данных (в случае необходимости);
· Агрегирование данных (в случае необходимости);
· Резервное копирование и архивирование данных.
В некоторых случаях диспетчер хранилища также анализирует профили запросов для определения необходимых индексов и требований к агрегированию данных.
Диспетчер запросов (называют внутренним компонентом) выполняет все операции, связанные с управлением пользовательскими запросами. Этот компонент обычно создается на основе предоставляемых разработчиком СУБД инструментов доступа к данным, инструментов мониторинга хранилища и программ собственной разработки, использующих весь набор функциональных возможностей СУБД. Сложность диспетчера запросов определяется функциональными средствами, которые предоставляются инструментами доступа к данным и самой СУБД.
Фактические данные. В этой части хранилища данных хранятся все фактические данные, описанные в схеме БД. В большинстве случаев фактические данные хранятся не на оперативном уровне, а в виде информации, агрегированной до следующего уровня детализации. Но фактические данные регулярно вводятся в хранилище и пополняют агрегированные данные.
Агрегированные данные. В этой области хранилища размещаются все данные, предварительно обработанные диспетчером хранилища с целью их агрегирования за короткие и продолжительные периоды времени. Назначение агрегированных данных состоит в повышении производительности запросов. Хотя предварительное агрегирование информации связано с некоторым повышением расходов на обслуживание хранилища, однако эти дополнительные затраты компенсируются за счет исключения необходимости многократно выполнять агрегирующие операции при обработке каждого из запросов пользователей. Хранимые агрегированные значения обновляются по мере загрузки новых данных в хранилище.
Архивные и резервные копии. Этот компонент хранилища отвечает за подготовку фактической и агрегированной информации, предназначенной для создания архивов и резервных копий. Хотя агрегированные данные вырабатываются на основе фактических данных, на их получение затрачены ресурсы, поэтому такие данные также должны быть включены в резервную копию или переданы в архив вместе с фактическими данными по истечении срока их хранения. Как правило, резервные и архивные копии размещаются на таких носителях, как магнитная лента или оптических диск.
Метаданные. Метаданные – это описание информационного содержания хранилища данных: что в нем содержится, откуда что поступает, какие операции выполнялись во время очистки, как осуществлялась интеграция и обобщение данных.
Например, для каждого исходного поля должны храниться такие сведения, как уникальный идентификатор, исходное имя поля, тип источника данных, исходное расположение, включая системное и объектное имя, тип преобразованных данных и имя таблицы назначения. Если поле подвергалось каким-то изменениям, начиная с простого изменения его типа и вплоть до выполнения над ним сложного набора процедур и функций, то все эти изменения также должны быть зафиксированы.
Для пользователей DW-систем требуются метаданные следующих типов:
1. Описание структур данных, их взаимосвязей;
2. Информация о хранимых на хранилище данных и поддерживаемых их агрегатах данных;
3. Информация об источниках данных и о степени их достоверности. Одна и та же информация могла попасть в хранилище данных из разных источников. Пользователь должен иметь возможность узнать, какой источник был выбран основным, и каким образом производились согласование и очистка данных;
4. Информация о периодичности обновлений данных. Желательно знать не только то, какому моменту времени соответствует интересующие его данные, но и когда они в следующий раз будут обновлены;
5. Информация о владельцах данных. Пользователю DW системы может оказаться полезной информация о наличии в системе данных, к которым он не имеет доступа, о владельцах этих данных и о действиях, которые он должен предпринять, чтобы получить доступ к данным;
6. Статистические оценки времени выполнения запросов. До выполнения запроса полезно иметь хотя бы приблизительную оценку времени, которое потребуется для получения ответа, и объема этого ответа.
Средства доступа к данным. Основным назначением хранилища данных является представление конечным пользователям информации, необходимой им для принятия стратегических решений. Пользователи взаимодействуют хранилищем с помощью специальных инструментов доступа к данным. Хотя определение пользовательских инструментов доступа к данным могут различаться, обычно их разбивают на пять групп:
· Инструменты создания запросов и отчетов;
· Инструменты разработки приложений;
· Инструменты управленческой информационной системы;
· Инструменты оперативной аналитической обработки (OLAP);
· Инструменты разработки данных.
СУБД для хранилища данных. Специфические требования к реляционной СУБД, предназначенной для хранилища данных:
· Высокая производительность данных. В хранилищах требуется периодически выполнять загрузку новых данных, причем в ограниченных временных рамках. Производительность процесса загрузки в подобных случаях должна измеряться в сотнях миллионов строк или гигабайтах данных в час, и требования, по максимальному повышению производительности загрузки, связаны с необходимостью, обеспечить бесперебойное выполнение основных производственных задач.
· Возможность обработки данных во время загрузки. При загрузке в хранилище новых или обновленных данных обычно требуется выполнение нескольких последовательных этапов, включающих преобразование данных, фильтрацию, переформатирование, проверку целостности, физическое сохранение, индексацию и обновление метаданных. На практике каждый такой этап может выполняться отдельно, но, в общем, процесс загрузки должен выглядеть как единая и неразрывная процедура.
· Высокая производительность запросов. Большие сложные запросы, связанные с выполнением важных деловых операций, должны завершаться за приемлемое время.
· Масштабируемость по объему. Объемы хранилищ данных возрастают с огромной скоростью и достигают величие от сотен гигабайт до терабайтов. Используемые реляционные СУБД должны поддерживать модульное и параллельное управление и не иметь никаких архитектурных ограничений на размер БД. В случае сбоя реляционная СУБД должна сохранять готовность к работе и представлять механизм восстановления до исходного состояния. Производительность выполнения запросов должна зависеть не от размеров БД, а от сложности самого запроса.
· Масштабируемость по количеству пользователей. В настоящее время считается, что доступ к хранилищу данных будет ограничен только относительно небольшим кругом управленческого персонала. Однако, маловероятно, что такая тенденция сохранится и при возрастании значения хранилища данных.
· Наличие средств администрирования хранилища..
· Поддержка многомерного интегрированного анализа. Поддержка многомерных представлений должна быть предусмотрена в реляционной СУБД, используемой для организации хранилища данных.
Способы реализации хранилищ данных
Варианты реализации хранилищ данных:
· виртуальное хранилище данных;
· витрины данных (двухуровневая архитектура);
· глобальное хранилище данных (многоуровневая архитектура).
Виртуальное хранилище данных. В его основе – репозиторий метаданных, которые описывают источники информации, SQL-запросы для их считывания и процедуры обработки и представления информации. Непосредственный доступ к последним обеспечивает ПО промежуточного слоя. В этом случае избыточность данных нулевая. Конечные пользователи работают с транзакционными системами со всеми вытекающими отсюда плюсами (доступ к данным в режиме реального времени) и минусами (интенсивный сетевой трафик, снижение производительности OLTP систем, угроза их работоспособности вследствие неудачных действий аналитиков).
Витрины данных (Data Mart). По своему определению – это набор тематически связанных баз данных, которые содержат информацию, относящуюся к отдельным аспектам деятельности организации (предприятия). По сути дела, витрина данных – это облегченны вариант хранилища, содержащий только тематически объединенные данные. Целевая база данных максимально приближена к конечному пользователю и может содержать тематически ориентированные агрегатные данные. Плюсы: простота и малая стоимость реализации; высокая производительность за счет физического разделения регистрирующих и аналитических систем, выделения загрузки и трансформации данных в отдельный процесс, оптимизированной под анализ структурой хранения данных; поддержка истории; возможность добавления метаданных.
Глобальное хранилище данных. В его основе лежит идея совмещения концепции хранилища и витрины данных в одной реализации и использование хранилища данных в качестве единственного источника интегрированных данных для всех витрин. Тогда становится естественной трехуровневая архитектура системы. На первом уровне расположены разнообразные источники данных – реляционная СУБД, внутренние регистрирующие системы, справочные системы, внешние источники (данные информационных агентств, макроэкономические показатели). Второй уровень содержит центральное хранилище, куда стекается информация от всех источников с первого уровня, и, возможно, оперативный склад данных, который не содержит исторических данных и выполняет две основные функции. Во-первых, он является источником аналитической информации для оперативного управления и, во-вторых, здесь подготавливаются данные для последующей загрузки в центральное хранилище. Под подготовкой данных понимают их преобразование и проведение определенных проверок. Наличие оперативного склада данных просто необходимо при различном регламенте поступления информации из источников. На втором уровне поддерживаются витрины данных на основе многомерной системы управления базами данных. Но эти СУБД пока не могут хранить сверхбольшие объемы данных (предельный размер многомерной базы составляет не более 40Гб). Третий уровень представляет собой набор предметно-ориентированных витрин данных, источником информации для которых является центральное хранилище данных. Именно с витринами данных и работает большинство конечных пользователей.
