

Rewrite (<имя_ф_переменной>);
Процедура Rewrite (f) (где f – имя файловой переменной) устанавливает файл с именем f в начальное состояние режима записи, в результате чего указатель устанавливается на первую позицию файла. Если ранее в этот файл были записаны какие-либо элементы, то они становятся недоступными. Результат выполнения процедуры rewrite(f) выглядит следующим образом:
Запись в файл
Write (<имя_ф_переменной>, <список записи>);
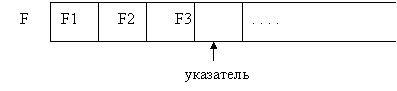
При выполнении процедуры write (f, x) в ту позицию, на которую показывает указатель, записывается очередная компонента, после чего указатель смещается на следующую позицию. Естественно, тип выражения х должен совпадать с типом компонент файла. Результат действия процедуры write(f, x) можно изобразить так:
Состояние файла f до выполнения процедуры
Состояние файла f после выполнения процедуры
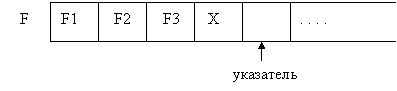
Для типизированных файлов выполняется следующее утверждение: если в списке записи перечислено несколько выражений, то они записываются в файл, начиная с первой доступной позиции, а указатель смещается на число позиций, равное числу записываемых выражений.
4. Подготовка файла к чтению
Reset(<имя_ф_переменной>);
Эта процедура ищет на диске уже существующий файл и переводит его в режим чтения, устанавливая указатель на первую позицию файла. Результат выполнения этой процедуры можно изобразить следующим образом:
Если происходит попытка открыть для чтения не существующий еще на диске файл, то возникает ошибка ввода/вывода, и выполнение программы будет прервано.
5. Чтение из файла
Read(<имя_ф_переменной>,<список переменных>);
Рассмотрим результат действия процедуры read (f, v):
Состояние файла f и переменной v до выполнения процедуры
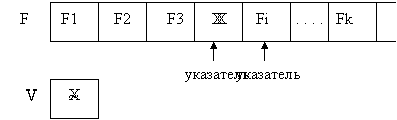
Состояние файла f и переменной v после выполнения процедуры
Для типизированных файлов при выполнении процедуры read() последовательно считывается, начиная с текущей позиции указателя, число компонент файла, соответствующее числу переменных в списке, а указатель смещается на это число позиций.
В большинстве задач, в которых используются файлы, необходимо последовательно перебрать компоненты и произвести их обработку. В таком случае необходимо иметь возможность определять, указывает ли указатель на какую-то компоненту файла, или он уже вышел за пределы файла и указывает на маркер конца файла.
6. Функция определения достижения конца файла
Eof (<имя_ф_переменной>);
Название этой функции является сложносокращенным словом от end of file. Значение этой функции имеет значение true, если конец файла уже достигнут, т. е. указатель стоит на позиции, следующей за последней компонентой файла. В противном случае значение функции – false.
7. Изменение имени файла
Rename(<имя_ф_переменной>, <новое_имя_файла>);
Здесь новое_ имя_ файла – строковое выражение, содержащее новое имя файла, возможно с указанием пути доступа к нему.
Перед выполнением этой процедуры необходимо закрыть файл, если он ранее был открыт.
8. Уничтожение файла
Erase(<имя_ф_переменной>);
Перед выполнением этой процедуры необходимо закрыть файл, если он ранее был открыт.
9. Уничтожение части файла от текущей позиции указателя до конца
Truncate(<имя_ф_переменной>);
11.Файл может быть открыт для добавления записей в конец файла
Append (<имя_ф_переменной>);
Построение динамических структур данных.
Понятие указателя, связанного списка, дерева, графа
От выбора структуры данных зависит эффективность того или иного алгоритма, поэтому принципиальным вопросом становится вопрос о представлении структур данных в памяти ЭВМ. (В дальнейшем все описания структур данных и реализации алгоритмов приводятся на языке Pascal).
Все динамические структуры данных можно представлять в памяти ЭВМ двумя способами: без использования динамического распределения памяти и с его использованием. Нам представляется, что человек знакомый с языком программирования Pascal без труда сможет описать все структуры без использования динамической памяти. Поэтому остановимся на варианте с использованием указателей.
В языке Pascal есть возможность по ходу выполнения программы выделять и освобождать необходимую память для размещения в ней различных данных. Оперативная память при этом используется наиболее эффективно. Такая возможность связана с наличием в языке особых типов данных – указателей.
Указатели. Работа с указателями
Указатель представляет собой переменную целого типа, которая интерпретируется как адрес байта памяти, содержащий некоторый элемент данных. Этим элементом может быть переменная, константа, адрес другой переменной. Обычно, работая с программой, мы не интересуемся расположением в памяти переменных и констант. Мы просто можем обращаться к ним по именам, при этом Турбо Паскаль точно знает, где нужно искать эти переменные и константы.
Часто в процессе программирования возникают ситуации, когда без применения указателей нельзя обойтись. Например: программа должна использовать данные, объем памяти, для хранения которых заранее неизвестен; программа использует динамические структуры данных.
В Турбо Паскале указатели могут связываться с некоторым типом данных (типизированные указатели) или не связываться (нетипизированные указатели). Для описания динамических структур данных будем использовать типизированные указатели.
Для объявления типизированного указателя обычно используется символ ^, который размещается непосредственно перед соответствующим типом данных, например:
Type
Point = ^Integer;
Var
P1:^Integer;
Как известно, в Турбо Паскале существует правило, согласно которому любой идентификатор должен быть описан в программе до того, как впервые используется. Для указателей в данном случае сделано исключение, они могут ссылаться на еще не объявленный тип данных. (Это дает возможность организовать хранение данных в виде списка.)
Для указателей допустимы только операции присваивания и сравнения. Указателю можно присваивать содержимое другого указателя того же типа, константу NIL (пустой указатель) или адрес объекта, определенный с помощью функции Addr (или оператора @), а также адрес, возвращаемый функцией Ptr.
Выделение и освобождение динамической памяти
В Турбо Паскале существует два основных метода работы с динамически распределяемой областью памяти:
· с помощью процедур New и Dispose;
· с помощью процедур GetMem и FreeMem.
В данной работе не рассматриваются процедуры второй группы, поэтому останавливаться на них мы не будем.
Процедура New.
Процедура New (P), где P – переменная типа Pointer (указатель), создает новую динамическую переменную того типа, на который ссылается указатель, и устанавливает значение переменной P таким образом, чтобы оно указывало на эту новую динамическую переменную.
Var P1: ^Integer;
Begin
New (P1);
...
End.
Процедура Dispose.
Процедура Dispose (P), где P – переменная типа Pointer (указатель) уничтожает динамическую переменную на которую указывает указатель P. Следует отметить, что процедура Dispose (P) не изменяет значения указателя P, а только возвращает память в кучу. Однако следует помнить, повторное применение процедуры к свободному указателю приводит к сообщению об ошибке во время исполнения программы. Во избежание такой ошибки освободившийся указатель можно пометить зарезервированным словом Nil.
...
Dispose (P);
New (P);
...
Кроме рассмотренных. Существует еще целый ряд функций, работающих с указателями (подробнее работа с указателями описана, например, в книге [1]), но для рассмотрения темы данной работы достаточно перечисленных функций.
Представление структур данных в памяти ЭВМ можно разбить на два больших класса:
1. Линейные структуры, такие как связанные списки, стеки, очереди, деки.
2. Нелинейные структуры: графы и деревья.
Все рассматриваемые структуры связные, т. е. для каждого элемента можно определить последующий и предыдущий.
В связных структурах обычно используются однотипные элементы. Каждый элемент имеет две (а может и больше) различные части:
· информационную часть – та часть, которая содержит всю информацию о том или ином объекте;
· ссылку на соседний элемент (элементы) в конкретной иерархии элементов.
Наиболее удобно для фиксации такой информации использовать тип-запись. Однако при задании такого типа элемента возникает определенная трудность, связанная с тем, что этот тип должен содержать тип-указатель на элемент структуры, который, в свою очередь, нельзя определить пока не определен тип элемента. При этом в какой бы последовательности ни определялись эти типы, будет нарушено правило, гласящее, что использовать можно только те элементы, которые определены ранее. Для устранения этого препятствия в языке Pascal сделано исключение из данного правила по отношению к двум типам данных, один из которых является типом - указатель на объект второго типа.
При работе с динамическими структурами данных выполняются следующие основные операции:
· добавление элемента структуры;
· исключение элемента структуры;
· поиск элементов структуры по какому-то признаку;
причем в разных структурах эти операции выполняются по-разному.
Реализация структур данных на ЭВМ
В данной главе рассматриваются вопросы, связанные с выбором базового типа для представления конкретных динамических структур данных, а также приводятся описания этих структур на языке Pascal. Отдельно рассматриваются вопросы добавления и исключения элементов структур.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
