


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Министерство образования и науки Российской Федерации
Федеральное агентство по образованию
Государственное образовательное учреждение
высшего профессионального образования
“Ростовский Государственный Университет”
Методические указания
по теме «Компилятор/интерпретатор простого языка»
для студентов
факультета математики, механики и компьютерных наук
Ростов-на-Дону
2006
Методические указания разработаны кандидатом физико-математических наук, доцентом кафедры информатики и вычислительного эксперимента факультета математики, механики и компьютерных наук РГУ .
Содержание
1. Введение.
2. Синтаксис языка
3. Лексический анализ
4. Синтаксический анализ
5. Построение промежуточного представления
6. Интерпретация промежуточного представления
7. Обработка ошибок
8. Заключение
9. Литература.
Введение
Предлагаемое методическое пособие предназначено для студентов специальности “Прикладная математика” при изучении общего курса “Языки программирования и методы трансляции”. На примере программной реализации транслятора простого языка рассматриваются аспекты и этапы процесса трансляции, вопросы и проблемы, обычно возникающие при реализации транслятора конкретного языка. Программа реализации компилятора простого языка, рассмотренная в данном методическом пособии, предназначена для практической реализации в рамках лабораторных занятий по курсу “Языки программирования и методы трансляции”. Методические указания могут быть использованы при выполнении лабораторной работы по рассматриваемой теме.
Программы, написанные на языках высокого уровня, перед исполнением на ЭВМ должны преобразовываться в последовательность команд, пригодных для исполнения. Процесс преобразования программы, написанной на конкретном языке высокого уровня, в эквивалентную программу на другом языке (обычно это машинный код) называется компиляцией. Программа, осуществляющая эту операцию, называется компилятором. В общем случае процесс трансляции включает следующие этапы или фазы:
1. Лексический анализ – группирование строк литер соответствующих идентификаторам, константам или терминальным символам языка в единые символы.
2. Синтаксический анализ – проверка правильности исходной программы с точки зрения синтаксиса языка. Другими словами, на данном этапе производится проверка: является ли программа правильным предложением языка.
3. Семантический анализ – проверка правильности программы на основе правил, которые не могут быть выражены при помощи синтаксиса языка.
4. Генерация кода – создание эквивалентной программы на не зависящем от машины промежуточном коде.
5. Генерация машинного кода – преобразование промежуточного кода в машинный код для конкретной машины.
Совместно с некоторыми этапами трансляции может выполняться другие действия: обработка ошибок и оптимизация – преобразование программы с целью её улучшения, уменьшения размера машинного кода и уменьшения времени исполнения программы.
В действительности, особенно в однопроходных компиляторах, отдельные фазы компиляции идут параллельно. Однако независимо от этого при построении компилятора удобно представлять отдельные этапы как самостоятельные фазы. В предлагаемом методическом пособии на примере программной реализации компилятора простого языка мы рассмотрим этапы лексического анализа, синтаксического анализа и этап построения промежуточного представления.
2. Синтаксис языка
Прежде чем приступить к созданию компилятора необходимо иметь чёткое и однозначное определение исходного языка. В качестве примера языка для записи исходных программ мы будем использовать простой язык для алгебраических вычислений. Программа на этом языке может содержать объявление переменных, операции присваивания и вывода результата. Операндом операций присваивания и вывода может быть алгебраическое выражение, состоящее из переменных, целых положительных чисел, знаков арифметических операций и скобок. Пример программы на этом языке:
PROGRAM
VAR x, y;
x = 1+2*3;
y = 1;
OUTPUT (x+y)*(x-y);
ENDP
Для формального определения синтаксиса рассматриваемого языка используем нотацию Бэкуса-Наура. Множество правил языка в БНФ нотации имеет вид:
<программа>::= PROGRAM <декларации> <инструкции> ENDP
<декларации>::= | <декларация переменных> <декларации>
<декларация переменных>::= VAR <имя> {, <имя>};
<инструкции>::= | <исполняемая инструкция> <инструкции>
<исполняемая инструкция>::= <пустая инструкция>
| <инструкция присваивания>
| <инструкция вывода>
<пустая инструкция>::= ;
<инструкция присваивания>::= <имя> = <выражение>;
<инструкция вывода>::= OUTPUT <выражение>;
<выражение>::= <слагаемое> {+ <слагаемое> | - <слагаемое>}
<слагаемое>::= <множитель> {* <множитель> | / <множитель>}
<множитель>::= <число> | <имя> | ( <выражение> )
<число>::= <цифра> {<цифра>}
<цифра>::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
<имя>::= <буква> {<буква> | <цифра>}
<буква>::= a | b | ... | z
Грамматика приведённого языка является контекстно-свободной, для синтаксического анализа предложений данного языка можно использовать метод рекурсивного спуска – хорошо известный и легко реализуемый метод грамматического разбора.
3. Лексический анализ
Первой фазой процесса компиляции является лексический анализ - группирование строк литер соответствующих идентификаторам, константам или терминальным символам языка в единые символы называемые токенами. Обычно этот процесс идёт параллельно с другими фазами компиляции. Однако нам удобно представить его в виде самостоятельной фазы.
Для лексического анализа исходной программы введём функцию
void Lexical (int hFile, int hDummy);
Эта функция читает из входного файла с дескриптором hFile поток ASCII символов составляющих программу языка и в результате лексического анализа формирует поток токенов, который записывает в файл hDummy. Помимо этого функция Lexical () создаёт таблицу идентификаторов, которая устанавливает соответствие между идентификаторами, константами, зарезервированными словами языка и кодами, представляющими токены в файле hDummy. Эта таблица используется также для хранения дополнительной информации и может быть использована на последующей стадии компиляции. Каждый элемент таблицы идентификаторов имеет структуру, соответствующую типу данных TELEM:
typedef struct _TELEM {
char type;
char* name;
union {
long val;
NODE* expr;
};
} TELEM;
Значение поля type соответствует типу элемента таблицы: ‘v’-идентификатор, ’n’-числовая константа, ’t’-терминальный символ. Поле name содержит имя идентификатора или терминального символа, например x, test, PROGRAM, VAR, … Если элемент таблицы представляет число, то поле val хранит значение этого числа. Значение поля expr указывает на структуру, представляющую значение переменной. Сама таблица представлена массивом
TELEM table[100];
и переменной
int countTable;
- количество элементов в таблице.
В качестве кодового значения токенов, появляющихся в результате работы лексического анализатора, мы будем использовать индекс соответствующего элемента массива table[].
Функция Lexical () также использует глобальную переменную
int IsDecl;
значение 1 этой переменной соответствует лексическому анализу объявления переменных в программе, значение 0 – анализу операторов программы. Использование IsDecl позволяет обнаружить использование необъявленных переменных в исходной программе.
Теперь рассмотрим определение функции Lexical:
void Lexical (int hFile, int hDummy)
{
Локальные переменные:
char in;
- переменная для хранения очередной символ из входного потока,
char str[128];
- строка для формирования имени идентификаторов,
long numb;
- переменная для формирования значений числовых констант,
int i;
- счётчик циклов.
В начале работы функции заносим в таблицу зарезервированные идентификаторы языка:
table[countTable].type = 't';
strcpy (table[countTable++].name = malloc (8), "PROGRAM");
table[countTable].type = 't';
strcpy (table[countTable++].name = malloc (4), "VAR");
table[countTable].type = 't';
strcpy ( table[countTable++].name = malloc (7), "OUTPUT");
table[countTable].type = 't';
strcpy (table[countTable++].name = malloc (5), "ENDP");
Далее последовательно считываем символы из входного файла, пока не достигнем его конца:
do {
read (hFile, &in, 1);
printf("%c", in);
< шаг цикла >
} while (!eof (hFile));
При достижении конца файла завершается работа лексического анализатора.
На каждом шаге цикла мы проверяем очередной прочитанный символ, если этот символ является буквой
if (isalpha (in)) {
то это значит, что мы начинаем обрабатывать идентификатор. Считываем последующие символы, пока не встретим символ не являющийся буквой или цифрой:
for (i=0; i<127 && (isalpha (in) || isdigit (in)); i++) {
str[i] = in;
read (hFile, &in, 1);
printf("%c", in);
}
Если количество таких символов превышает 127, то передаём управление функции обработки ошибок с кодом ошибки соответствующим слишком длинному имени:
if (i==127) OnError (11);
В противном случае помещаем символ конца строки
str[i] = '\x0';
и если считанное имя VAR, то устанавливаем признак декларации переменных в программе:
if (!strcmp (str, "VAR"))
IsDecl = 1;
Затем ищем полученное имя в таблице идентификаторов
for (i=0; i<countTable; i++) {
if (!strcmp (table[i].name, str))
break;
}
и если его там нет
if (i==countTable) {
то мы заносим это имя в таблицу или выдаем сообщение о необъявленном идентификаторе
if (IsDecl) {
table[countTable].type = 'v';
strcpy (table[countTable++].name = malloc (strlen(str)+1), str);
}
else
OnError (12);
}
в зависимости от того находимся ли мы в области объявления переменных программы или нет.
Если искомое имя содержится в таблице идентификаторов и данное имя не является зарезервированным, а мы находимся в области программы соответствующей объявлению переменных, то управление передаём обработчику ошибок с кодом ошибки – повторное объявление переменной:
else {
if (IsDecl && table[i].type != 't')
OnError (13);
}
После анализа идентификатора заносим код токена (индекс элемента массива) в выходной файл:
write (hDummy, &i, 4);
}
Если очередной входной символ не является началом идентификатора, проверяем, может это начало числа:
else if (isdigit (in)) {
если это так, то считываем последующие цифры и формируем число:
numb = 0;
for (i=0; i<10 && isdigit (in); i++) {
numb = numb*10 + (in-48);
read (hFile, &in, 1);
printf("%c", in);
}
для очень большого числа передаём управление обработчику ошибок с соответствующим кодом:
if (i==10) OnError (15);
Если всё нормально, то формируем соответствующий элемент таблицы
table[countTable].type = 'n';
table[countTable].val = numb;
и заносим код токена в выходной файл:
write (hDummy, &countTable, 4);
countTable++;
}
После завершения обработки числовой константы пропускаем символы пробела, табуляции и перехода на новую строку:
if (!(in==' ' || in=='\t' || in=='\n')) {
Для символа ‘;’ сбрасываем признак объявления переменных
if (in == ';')
IsDecl = 0;
формируем и записываем в выходной файл код символа не вошедшего в таблицу идентификаторов:
numb = in + 0x80000000;
write (hDummy, &numb, 4);
}
это символ не вошедший в состав числовой константы или идентификатора и не являющийся символом пробела, табуляции и перехода на новую строку; это может быть символ знака арифметической операции, символs ‘;’ ‘,’ и т. п..
На этом завершается шаг цикла обработки последовательности символов составляющих исходную программу языка. При чтении каждого символа из входного файла производится его вывод на экран монитора, это позволяет обнаружить место нахождения ошибки в исходной программе.
Полный текст файла Lexical. c, содержащего определение функции лексического анализа приведён ниже:
#include "Compiler. h"
#include <io. h>
#include <ctype. h>
#include <string. h>
TELEM table[100]; // Таблица символов
int countTable=0; // Количество элементов в таблице
int IsDecl; // Индикатор области объявления переменных
void Lexical (int hFile, int hDummy)
{
char in;
char str[128];
long numb;
int i;
table[countTable].type = 't';
strcpy (table[countTable++].name = malloc (8), "PROGRAM");
table[countTable].type = 't';
strcpy (table[countTable++].name = malloc (4), "VAR");
table[countTable].type = 't';
strcpy ( table[countTable++].name = malloc (7), "OUTPUT");
table[countTable].type = 't';
strcpy (table[countTable++].name = malloc (5), "ENDP");
do {
read (hFile, &in, 1);
printf("%c", in);
if (isalpha (in)) {
for (i=0; i<127 && (isalpha (in) || isdigit (in)); i++) {
str[i] = in;
read (hFile, &in, 1);
printf("%c", in);
}
if (i==127) OnError (11);
str[i] = '\x0';
if (!strcmp (str, "VAR"))
IsDecl = 1;
for (i=0; i<countTable; i++) {
if (!strcmp (table[i].name, str))
break;
}
if (i==countTable) {
if (IsDecl) {
table[countTable].type = 'v';
strcpy (table[countTable++].name = malloc (strlen(str)+1), str);
}
else
OnError (12);
}
else {
if (IsDecl && table[i].type!= 't')
OnError (13);
}
write (hDummy, &i, 4);
}
else if (isdigit (in)) {
numb = 0;
for (i=0; i<10 && isdigit (in); i++) {
numb = numb*10 + (in-48);
read (hFile, &in, 1);
printf("%c", in);
}
if (i==10) OnError (15);
table[countTable].type = 'n';
table[countTable].val = numb;
write (hDummy, &countTable, 4);
countTable++;
}
if (!(in==' ' || in=='\t' || in=='\n')) {
if (in == ';')
IsDecl = 0;
numb = in + 0x80000000;
write (hDummy, &numb, 4);
}
} while (!eof (hFile));
}
4. Синтаксический анализ
Задача транслятора, решаемая на этапе синтаксического анализа, заключается в распознавании предложений языка. Метод рекурсивного спуска является наиболее известным и широко используемым методом грамматического разбора для решения задач подобного типа.
Входной поток токенов мы будем получать из файла hDummy созданного на этапе лексического анализа. Глобальная переменная
long Token;
будет хранить код очередного анализируемого токена. Для чтения токенов из входного потока введём функцию
void GetNextToken (void);
Эта функция помимо чтения очередного токена
void GetNextToken ()
{
read (hDummy, &Token, 4);
выводит соответствующее значение на экран монитора. Если полученный токен не содержится в таблице идентификаторов, то мы сбрасываем бит признака и выводим на экран соответствующий ASCII символ:
if (Token & 0x80000000) {
Token &= 0x7fffffff;
if (Token == ';')
printf (";\n");
else
printf ("%c", Token);
}
Для токена присутствующего в таблице идентификаторов выводим соответствующее значение для идентификатора, числовой константы или зарезервированного идентификатора:
else {
switch (table[Token].type) {
case 'v':
printf ("%s", table[Token].name);
break;
case 'n':
printf ("%li", table[Token].val);
break;
case 't':
printf ("%s ", table[Token].name);
if (!strcmp (table[Token].name, "PROGRAM"))
printf ("\n");
break;
}
}
}
В случае обнаружения ошибки выводимая информация позволит локализовать место ошибки в исходной программе.
В соответствии с принципами программной реализации метода рекурсивного спуска напишем функции распознавания каждого нетерминального символа в списке порождающих правил нашего языка рассмотренных в разделе “Синтаксис языка”.
Начав с символа <программа>, получаем:
void Program ()
{
Если исходная программа не начинается с терминального символа PROGRAM, то передаём управление обработчику ошибок:
if (strcmp (table[Token].name, "PROGRAM"))
OnError (21);
Получаем из входного потока следующий токен
GetNextToken ();
и вызываем функцию распознавания нетерминального символа <декларации>, соответствующего области объявления переменных в программе:
Declist ();
далее вызываем функцию распознавания нетерминального символа <инструкции>, соответствующего последовательности операторов:
Oplist ();
и проверяем наличие символа ENDP в конце программы:
if (strcmp (table[Token].name, "ENDP"))
OnError (22);
}
Аналогичным образом мы определяем функции для разбора других нетерминальных символов языка:
Declist () – для анализа символа <декларации> (объявление переменных)
Oplist () - для символа <инструкции> (последовательность операторов)
Operator () - для символа <исполняемая инструкция>
Expr () - для символа <выражение>
Term () - для символа <слагаемое>
Factor () - для символа <множитель>
Identifier () - для символа <имя>
Полный текст этих функций приведён в конце раздела. Сейчас отметим, что перед завершением работы каждой функции читается очередной токен из входного потока. Таким образом, переменная Token всегда содержит код токена, который будет проанализирован при вызове функции разбора соответствующего нетерминального символа.
Сама программа синтаксического разбора имеет вид:
void Syntactic (int Handle)
{
hDummy = Handle;
- устанавливаем дескриптор файла содержащего входную последовательность токенов,
GetNextToken ();
- читаем первый токен,
Program ();
- вызываем функцию разбора начального символа языка.
}
Полный текст файла Syntactic. c:
#include "Compiler. h"
#include <io. h>
#include <string. h>
int hDummy;
long Token;
void GetNextToken (void);
void Program (void);
void Declist (void);
void Oplist (void);
int Operator (void);
void Expr (void);
void Term (void);
void Factor (void);
void Identifier (void);
void GetNextToken ()
{
read (hDummy, &Token, 4);
if (Token & 0x80000000) {
Token &= 0x7fffffff;
if (Token == ';')
printf (";\n");
else
printf ("%c", Token);
}
else {
switch (table[Token].type) {
case 'v':
printf ("%s", table[Token].name);
break;
case 'n':
printf ("%li", table[Token].val);
break;
case 't':
printf ("%s ", table[Token].name);
if (!strcmp (table[Token].name, "PROGRAM"))
printf ("\n");
break;
}
}
}
void Syntactic (int Handle)
{
hDummy = Handle;
GetNextToken ();
Program ();
}
void Program ()
{
if (strcmp (table[Token].name, "PROGRAM"))
OnError (21);
GetNextToken ();
Declist ();
Oplist ();
if (strcmp (table[Token].name, "ENDP"))
OnError (22);
}
void Declist ()
{
if (strcmp (table[Token].name, "VAR"))
return;
do {
GetNextToken ();
Identifier ();
}
while (Token == ',');
if (Token!= ';')
OnError (23);
GetNextToken ();
if (strcmp (table[Token].name, "VAR"))
return;
Declist ();
}
void Oplist ()
{
if (!Operator ())
return;
Oplist ();
}
int Operator ()
{
if (Token == ';') {
GetNextToken ();
return 1;
}
if (!strcmp (table[Token].name, "OUTPUT")) {
GetNextToken ();
Expr ();
if (Token!= ';')
OnError (23);
table[countTable].type = 'e';
table[countTable].expr = (NODE*)Pop (&Stack1);
countTable++;
GetNextToken ();
return 1;
}
if (table[Token].type == 'v') {
long i = Token;
GetNextToken ();
if (Token!= '=')
OnError (25);
GetNextToken ();
Expr ();
if (Token!= ';')
OnError (23);
table[i].expr = (NODE*)Pop (&Stack1);
GetNextToken ();
return 1;
}
return 0;
}
void Expr ()
{
Term ();
while (Token == '+' || Token == '-') {
Action2 ();
GetNextToken ();
Term ();
Action3 ();
}
}
void Term ()
{
Factor ();
while (Token == '*' || Token == '/') {
Action2 ();
GetNextToken ();
Factor ();
Action3 ();
}
}
void Factor ()
{
if (table[Token].type == 'n') {
Action1 ();
GetNextToken ();
return;
}
if (table[Token].type == 'v') {
if (!table[Token].expr)
OnError (31);
Action1 ();
GetNextToken ();
return;
}
if (Token == '(') {
GetNextToken ();
Expr ();
if (Token!= ')')
OnError (26);
GetNextToken ();
return;
}
}
void Identifier ()
{
if (table[Token].type!= 'v')
OnError (24);
GetNextToken ();
}
5. Построение промежуточного представления
Проанализировав программу на фазах лексического и синтаксического анализа и разместив в таблицы требуемую информацию, компилятор должен переходить к построению соответствующей программы в машинном коде. Во многих случаях бывает удобно вначале создать некоторое промежуточное представление исходной программы, затем переходить к генерации машинного кода. Промежуточное представление можно проектировать на разных уровнях и использовать различные формы такого представления.
В данном разделе мы рассмотрим построение структур данных, которые в дальнейшем могут быть использованы при генерации кода. В нашем случае в качестве промежуточного представления для алгебраических выражений мы будем использовать бинарные деревья. Так, например, выражение
(x+y)*(x-y)
будет представлено в виде дерева:
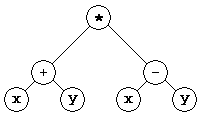
При присваивании значений переменным значение поля expr элемента в таблице идентификаторов будет указывать на соответствующую структуру; выражения, предназначенные для вывода, будем заносить в таблицу идентификаторов в виде отдельной записи.
Построение дерева алгебраических выражений удобно объединить с процессом грамматического разбора. Для этого модифицируем синтаксические правила языка. А именно: в правила относящиеся к анализу алгебраических выражений включим дополнительные элементы – действия, которые необходимо выполнять в данной точке грамматического разбора:
<выражение>::= <слагаемое> {+:A2: <слагаемое>:A3: | -:A2: <слагаемое>:A3:}
<слагаемое>::= <множитель> {*:A2: <множитель>:A3: | /:A2: <множитель>:A3:}
<множитель>::= <число>:A1: | <имя>:A1: | ( <выражение> )
Эти действия мы обозначили как :A1:, :A2:, :A3:. Функции, выполняющие необходимые действия, имеют имена Action1( ), Action2( ), Action3( ) и их вызовы мы уже включили в соответствующие места функций Expr( ), Term( ) и Factor( ), используемых в предыдущем разделе для анализа нетерминальных символов <выражение>, <слагаемое> и <множитель>.
Для дерева, представляющего алгебраическое выражение, определим структуру данных для элемента дерева:
typedef struct _NODE {
long token;
struct _NODE* left;
struct _NODE* right;
} NODE;
В соответствии с определением каждый элемент дерева содержит поля, предназначенные для хранения токена и указателей на левое и правое поддеревья. Функция создания нового элемента дерева с соответствующими значениями T, L и R имеет вид:
NODE* NewNode (long T, NODE* L, NODE* R)
{
NODE* p;
p = (NODE*)malloc (sizeof (NODE));
p->token = T;
p->left = L;
p->right = R;
return p;
}
При построении дерева и выполнении операций :A1:, :A2:, :A3: нам понадобятся два стека: стек выражений и стек операций. Для реализации этих стеков введём переменные Stack1 и Stack2:
struct STACK {
long S[100];
int top;
} Stack1, Stack2;
В дальнейшем Stack1 будет использоваться в качестве стека выражений, а Stack2 в качестве стека операций. Определим функции записи элемента на стек:
void Push (struct STACK* pStack, long N)
{ pStack->S[++pStack->top] = N; }
и извлечения элемента из стека:
long Pop (struct STACK* pStack)
{ return pStack->S[pStack->top--]; }
Теперь опишем дополнительные действия, включённые в синтаксические правила для алгебраических выражений:
1. Операция :A1: - после чтения идентификатора или числовой константы создадим узел дерева, занесём в него значение соответствующего токена и поместим указатель на этот узел в стек выражений.
2. Операция :A2: - после чтения арифметического оператора поместить символ операции в стек операций.
3. Операция :A3: - после чтения правого операнда извлечь из стека операций знак операции и из стека выражений два его операнда, создать узел дерева соответствующий новому выражению и поместить его в стек выражений.
После завершения грамматического разбора алгебраического выражения стек операций должен быть пустым, а стек выражений содержать единственный элемент – указатель на дерево соответствующее исходному выражению.
Определения функций соответствующих операциям :A1:, :A2:, :A3: приведены ниже:
void Action1 ()
{ if (table[Token].type == 'n')
Push (&Stack1, (long)NewNode (table[Token].val, NULL, NULL));
else
Push (&Stack1, (long)table[Token].expr);
}
void Action2 ()
{ Push (&Stack2, Token); }
void Action3 ()
{ Push (&Stack1, (long)NewNode (Pop (&Stack2), (NODE*)Pop (&Stack1), (NODE*)Pop (&Stack1)));
}
В рассматриваемом языке для записи исходных программ выражения могут присутствовать в двух местах: в правой части оператора присваивания и в качестве операнда оператора OUTPUT. Если алгебраическое выражение относится к оператору присваивания, то указатель на соответствующее дерево мы будем заносить в поле expr элемента таблицы идентификаторов относящегося к переменной в левой части оператора присваивания. Если выражение является операндом оператора OUTPUT, то мы создадим новый элемент в таблице идентификаторов, в поле типа этого элемента занесём значение ‘e’ и поле expr поместим указатель на соответствующее дерево. В определение функции Operator( ), введённой в предыдущем разделе для анализа символа <исполняемая инструкция>, указанные действия выполняются следующим образом:
int Operator ()
{
...
if (table[Token].type == 'v') {
...
table[i].expr = (NODE*)Pop (&Stack1);
...
}
if (!strcmp (table[Token].name, "OUTPUT")) {
...
table[countTable].type = 'e';
table[countTable].expr = (NODE*)Pop (&Stack1);
countTable++;
...
}
...
}
Файл Expr2Tree. c содержит определения функций используемых при построении дерева выражений:
#include "Compiler. h"
NODE* NewNode (long T, NODE* L, NODE* R)
{
NODE* p;
p = (NODE*)malloc (sizeof (NODE));
p->token = T;
p->left = L;
p->right = R;
return p;
}
struct STACK {
long S[100];
int top;
} Stack1, Stack2;
void Push (struct STACK* pStack, long N)
{ pStack->S[++pStack->top] = N; }
long Pop (struct STACK* pStack)
{ return pStack->S[pStack->top--]; }
void Action1 ()
{ if (table[Token].type == 'n')
Push (&Stack1, (long)NewNode (table[Token].val, NULL, NULL));
else
Push (&Stack1, (long)table[Token].expr);
}
void Action2 ()
{ Push (&Stack2, Token);
}
void Action3 ()
{ Push (&Stack1, (long)NewNode (Pop (&Stack2), (NODE*)Pop (&Stack1), (NODE*)Pop (&Stack1)));
}
6. Интерпретация промежуточного представления
После этапа синтаксического анализа дальнейшие действия компилятора должны заключаться в генерации эквивалентной программы в машинном коде. Однако возможен и другой способ действий. Он заключается в том, чтобы вместо трансляции программы в машинный код с последующим её исполнением исходная программа транслируется в промежуточное представление и промежуточное представление используется для управления работой другой программы, выполняющей операции в соответствии с алгоритмом исходной программы. Программа, преобразующая исходную программу в промежуточное представление и интерпретирующая его, называется интерпретатором.
В нашем случае интерпретация промежуточного представления реализована в виде функции Calculate( ). Эта функция
void Calculate ()
{
int i;
просматривает все элементы таблицы идентификаторов
for (i=0; i<countTable; i++)
и если найдёт элемент соответствующий операнду оператора вывода (его признаком является значение ‘e’ в поле типа)
if (table[i].type == 'e') {
то на экран монитора выводится значение соответствующего выражения:
printf ("\nAnswer: %li\n\n", CalcTree (table[i].expr));
}
}
Вычисление значения алгебраического выражения представленного в виде дерева производится при помощи функции CalcTree( ). В качестве аргумента эта функция получает указатель на корневой узел дерева
long CalcTree (NODE* T)
{
и если этот узел не имеет поддеревьев, то он соответствует листу дерева и содержит числовую константу
if (!T->left && !T->right)
тогда в качестве результата функция возвращает соответствующее числовое значение:
return T->token;
В противном случае узел дерева содержит знак арифметической операции, левое и правое поддеревья этого представляют выражения – операнды этой операции:
else {
switch (T->token) {
case '+':
return CalcTree (T->left) + CalcTree (T->right);
case '-':
return CalcTree (T->left) - CalcTree (T->right);
case '*':
return CalcTree (T->left) * CalcTree (T->right);
case '/':
return CalcTree (T->left) / CalcTree (T->right);
}
в этом случае функция CalcTree( ) в качестве своего значения возвращает результат исполнения соответствующей операции над значениями выражений-поддеревьев.
}
}
Полный текст файла Calculation. c приведён ниже:
#include "Compiler. h"
long CalcTree (NODE* T);
void Calculate ()
{
int i;
for (i=0; i<countTable; i++)
if (table[i].type == 'e') {
printf ("\nAnswer: %li\n\n", CalcTree (table[i].expr));
}
}
long CalcTree (NODE* T)
{
if (!T->left && !T->right)
return T->token;
else {
switch (T->token) {
case '+':
return CalcTree (T->left) + CalcTree (T->right);
case '-':
return CalcTree (T->left) - CalcTree (T->right);
case '*':
return CalcTree (T->left) * CalcTree (T->right);
case '/':
return CalcTree (T->left) / CalcTree (T->right);
}
}
return 0;
}
7. Обработка ошибок
При проектировании компилятора необходимо с самого начала предусмотреть возможность обнаружения и диагностики ошибок в исходной программе. Система обработки ошибок должна указывать место ошибки в программе и сообщать тип ошибки. Кроме этого желательно иметь возможность попытки исправления ошибки и продолжения компиляции программы после обнаружения первой ошибки с целью обнаружения остальных.
В нашем случае мы ограничимся простейшим случаем обработки ошибок: вывод диагностического сообщения и прерывание процесса компиляции. В случае обнаружения ошибки вызывается функция OnError( ). Эта функция в соответствии с полученным кодом ошибки выводит диагностическое сообщение и прекращает работу компилятора. Коды ошибок в интервале 11-19 соответствуют фазе лексического анализа, в интервале 21-29 - фазе синтаксического анализа, 31-39 – построению промежуточного представления. Так как в процессе своей работы рассматриваемый компилятор синхронно выводит на экран очередной анализируемый элемент (символ или токен) то в случае обнаружения ошибки и прекращения компиляции это позволяет локализовать местоположение ошибки в исходной программе.
Определение функции обработки ошибок OnError( ) содержится в файле Errors. c:
#include "Compiler. h"
void OnError (int N)
{
switch (N) {
case 11:
printf ("\n*** Слишком длинное имя переменной ***\n");
break;
case 12:
printf ("\n*** Необъявленная переменная ***\n");
break;
case 13:
printf ("\n*** Повторное объявление переменной ***\n");
break;
case 15:
printf ("\n*** Слишком большое число ***\n");
break;
case 21:
printf ("\n*** Ожидается слово PROGRAM ***\n");
break;
case 22:
printf ("\n*** Ожидается слово ENDP ***\n");
break;
case 23:
printf ("\n*** Ожидается символ ';' ***\n");
break;
case 24:
printf ("\n*** Ожидается имя переменной ***\n");
break;
case 25:
printf ("\n*** Ожидается символ '=' ***\n");
break;
case 26:
printf ("\n*** Ожидается символ ')' ***\n");
break;
case 31:
printf ("\n*** Неопределённая переменная ***\n");
break;
}
exit (1);
}
8. Заключение
Исходный текст программной реализации проекта компилятора простого языка разбит на несколько файлов. Содержимое некоторых из них было приведено в соответствующих разделах методического пособия:
Lexical. c – раздел “Лексический анализ”
Syntactic. c – раздел “Синтаксический анализ”
Expr2Tree. c – раздел “Построение промежуточного представления”
Calculation. c – раздел “Интерпретация промежуточного представления”
Errors. c – раздел “Обработка ошибок ”
Для полной сборки проекта кроме указанных файлов необходимы ещё два файла. Основной файл проекта Compiler. c с определением функции main( ):
#include "Compiler. h"
#include <sys\stat. h>
#include <fcntl. h>
#include <io. h>
int main ()
{
int hFile, hDummy;
// Открытие входного файла с исходной программой
if ((hFile = open ("Program. txt", O_RDONLY|O_TEXT)) == -1) {
perror ("Error");
return 1;
}
hDummy = open ("Dummy.$$$", O_CREAT|O_RDWR|O_TRUNC, S_IREAD|S_IWRITE);
// Лексический анализатор
Lexical (hFile, hDummy);
close (hFile);
// Синтаксический анализатор
lseek (hDummy, 0, SEEK_SET);
printf ("\n");
Syntactic (hDummy);
close (hDummy);
// Интерпретация промежуточного представления
printf ("\n");
Calculate ();
return 0;
}
и заголовочный файл Compiler. h:
#include <stdlib. h>
#include <stdio. h>
typedef struct _NODE {
long token;
struct _NODE* left;
struct _NODE* right;
} NODE;
typedef struct _TELEM {
char type;
char *name;
union {
long val;
NODE* expr;
};
} TELEM;
// Compiler. c
extern void OnError (int);
// Lexical. c
extern TELEM table[100];
extern int countTable;
extern void Lexical (int hFile, int hDummy);
// Syntactic. c
extern long Token;
extern void Syntactic (int Handle);
// Expr2Tree. c
extern struct STACK Stack1;
extern long Pop (struct STACK*);
extern void Action1 (void);
extern void Action2 (void);
extern void Action3 (void);
// Calculation. c
extern void Calculate (void);
// Errors. c
extern void OnError (int N);
Литература
1. Р. Хантер “Проектирование и конструирование компиляторов”, Москва, Финансы и Статистика, 1984.
2. Н. Вирт “Алгоритмы + структуры данных = программы”, Москва, Мир, 1985.
