

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
5 Технология физического хранения и доступа к данным.. 1
5.1 Основные этапы доступа к базе данных. 1
5.2 Управление страницами. 2
5.3 Процедура индексирования и хеширования. 4
5.4 Сжатие данных. 10
6 Технология физического хранения и доступа к данным
6.1 Основные этапы доступа к базе данных
Говоря о процессе работы с БД, нельзя не остановиться на вопросах хранения и методов доступа к данным. Вообще говоря, основные проблемы, связанные с физическим хранением данных, вызваны медленностью доступа и поиска, а также низкой скоростью передачи, поэтому основной целью повышения производительности системы с этой точки зрения является минимизация числа дисковых операций ввода-вывода данных.
Для хранения данных могут быть использованы различные структуры, обладающие разной производительностью, однако идеального способа хранения данных не существует. По этой причине СУБД должна содержать несколько структур хранения данных для разных задач и частей системы, а также предусматривать возможность изменения способов хранения в зависимости от изменяющихся требований к производительности системы.
Начнем с описания основных этапов процесса доступа к БД. Сначала СУБД определяет искомую запись в БД, для чего в оперативную память помещается набор записей, в котором ищется запрашиваемая, а для извлечения записи запрашивается так называемый диспетчер файлов. Диспетчер файлов определяет страницу, на которой находится искомая запись, а затем для извлечения этой страницы запрашивается диспетчер дисков. Диспетчер дисков определяет физическое расположение страницы на устройстве хранения информации и посылает запрос на ввод-вывод данных.
Таким образом, СУБД рассматривает БД как множество записей, просматриваемых при помощи диспетчера файлов. Последний рассматривает БД как набор страниц, просматриваемых с помощью диспетчера дисков, который уже непосредственно работает с устройствами хранения информации.
Заметим, что диспетчер дисков является частью операционной системы, с помощью которого выполняются все дисковые операции ввода-вывода. Для того, чтобы выполнять эти операции, диспетчеру необходимо обладать информацией о значениях физических адресов на диске, где располагаются те или иные данные. Однако диспетчеру файлов такая информация совсем не нужна - вместо этого ему достаточно рассматривать диск как набор страниц строго фиксированного размера с уникальным идентификационным номером набора страниц. В свою очередь, каждая страница, обладает уникальным внутри данного набора идентификационным номером страницы, причем наборы не имеют общих страниц. При этом соответствие физических адресов на диске и номеров страниц достигается с помощью диспетчера дисков. Важнейшим преимуществом такой организации - хранения данных является изоляция программного кода внутри диспетчера дисков, зависящего от конкретного устройства диска, за счет чего многие компоненты системы могут быть аппаратно независимыми.
Все страницы диска делятся на несвязанные наборы, а один из таких наборов, содержащий пустые страницы, соответственно содержит все имеющиеся свободные страницы, не используемые для размещения данных. Этот набор иногда называют свободным пространством на диске. При этом использование или освобождение страниц из наборов страниц осуществляется диспетчером дисков по запросу диспетчера файлов.
Основные операции, выполняемые диспетчером дисков с набором страниц по запросу со стороны диспетчера файлов, следующие:
- извлечь страницу s из набора страниц n;
- заменить страницу s из набора страниц n;
- добавить новую страницу в набор страниц n;
- удалить страницу s из набора страниц n.
При работе с диском, как с набором хранимых файлов, диспетчер файлов использует все имеющиеся средства диспетчера дисков, при этом каждый набор страниц может содержать один или несколько хранимых файлов.
Каждый хранимый файл имеет уникальные в рассматриваемом наборе страниц имя или идентификационный номер, а каждая хранимая запись обладает идентификационным номером записи, уникальным в пределах данного хранимого файла.
С помощью операций с файлами в СУБД можно создавать структуры хранения и управлять, но следует иметь в виду, что в одних системах диспетчер файлов является компонентом операционной системы, а в других является частью СУБД, однако принципы его работы существенно от этого не различаются. Основные операции с файлами, выполняемые диспетчером файлов по запросу со стороны СУБД, следующие:
- извлечь хранимую запись z из хранимого файла f;
- заменить хранимую запись z в хранимом файле f;
- добавить новую хранимую запись z в хранимый файл f;
- удалить хранимую запись z из хранимого файла f;
- создать новый хранимый файл f;
- удалить хранимый файл f.
При хранения данных используют принцип кластеризации данных, в основе которого лежит подход как можно более близкого физического размещения на диске логически связанных между собой и часто используемых данных. Физическая кластеризация данных - достаточно важное условие высокой производительности, при этом различают внутрифайловую и межфайловую кластеризацию
Говорят о внутрифайловой кластеризации, когда она осуществляется в рамках одного хранимого файла. Например, если в системе часто требуется осуществлять доступ к данным согласно порядковому номеру, то все записи следует физически размещать таким образом, чтобы первая запись была возле второй записи, вторая запись - возле третьей и т. д.
При межфайловой кластеризации ею охватываются одновременно несколько файлов. Это используют, если в системе часто требуется осуществлять доступ к записям и данным, связанным друг с другом, при этом первые стараются разместить радом со вторыми.
Разумеется, в каждый момент времени кластеризацию файла или набора файлов можно осуществлять только одним из этих способов. Внутрифайловую и межфайловую кластеризацию СУБД может осуществлять, размещая логически связанные записи на одной странице, если это возможно, или на соседних страницах. По этой причине СУБД важно иметь сведения не только о сохраненных файлах, но и о страницах: при создании в СУБД новой записи необходимо, чтобы она с помощью диспетчера файлов была размещена возле некоторой текущей страницы, т. е. на той же или, по крайней мере, на логически близкой странице. В свою очередь, диспетчер дисков должен обеспечить, чтобы логически близкие страницы были физически близко расположены на диске.
Конечно, кластеризация внутри СУБД возможна только в том случае, если администратор БД организует ее, при этом часто предусматривается использование нескольких различных типов кластеризации данных из разных файлов.
6.2 Управление страницами
Основной функцией диспетчера дисков является скрытие от диспетчера файлов всех деталей физических дисковых операций ввода-вывода и замена их логическими страничными операциями ввода-вывода. Эта функция диспетчера дисков называется управлением страницами, которая реализуется в следующей последовательности, например, если в каждой используемой таблице требуется логически упорядочить записи согласно ключевому полю.
На начальном этапе БД совсем не содержит данных, но в ней имеется набор пустых страниц, последовательно пронумерованных начиная с номера один, в котором содержатся все страницы диска, за исключением страницы с нулевым номером, которой отводится особая роль. Для размещения записей с данными Х диспетчер файлов создаст набор страниц и разместит на них данные X. С этой целью диспетчер дисков переместит соответствующее количество страниц из набора пустых страниц и пометит их как набор страниц данных Х. Аналогичные действия будут выполнены для размещения данных Y, Z и т. д., но для простоты ограничимся тремя наборами. В результате создано четыре набора страниц: данные X, данные Y, данные Z и набор пустых страниц.
Предположим, что необходимо добавить новую запись с данными Х. Для этого диспетчер файлов вставляет новую хранимую запись, а диспетчер дисков осуществляет поиск первой пустой страницы, а затем добавляет ее к набору страниц данных X.
Если необходимо удалить хранимую запись с данными X, диспетчер файлов удаляет ее, а диспетчер дисков возвращает освободившуюся страницу данных Х в набор пустых страниц.
Аналогичным способом вставляются или удаляются записи из набора страниц с данными Y или Z, из чего можно сделать вывод о том, что после выполнения нескольких самых обычных действий нельзя гарантировать, что логически близкие страницы будут физически располагаться одна возле другой. Поэтому логическую последовательность страниц в данном наборе следует задавать с помощью указателей, а не на основе их физически близкого размещения на диске. Для этого каждая страница содержит заголовок страницы с информацией о физическом дисковом адресе страницы, которая логически следует за данной страницей.
Особенности использования указателей следующие:
- заголовки страниц, в частности указатели следующей страницы, обрабатываются диспетчером дисков и должны быть скрыты для диспетчера файлов;
- желательно сохранять логически связанные страницы в физически близких фрагментах диска, поэтому диспетчер дисков обычно размещает или удаляет страницы в наборах не по одной, а целыми блоками физически связанных страниц;
- для получения информации о размещении различных наборов страниц диспетчером дисков, на диске организуется отдельная страница, в которой сохраняется вся необходимая для этого информация. Эта страница часто называется таблицей размещения или просто страницей 0, где перечислены все имеющиеся на данном диске наборы страниц вместе с указателями на первые страницы каждого из наборов.
Диспетчер дисков скрывает особенности физической организации ввода-вывода от диспетчера файлов и предоставляет ему возможность вести работу только на логическом уровне. Аналогично диспетчер файлов скрывает все подробности операций ввода-вывода на основе страниц от СУБД и предоставляет ей возможность вести работу только с хранимыми записями и файлами. Такая работа, выполняемая диспетчером файлов, называется управлением хранимыми записями.
Предположим, что на одной странице могут быть размещены не одна, а несколько хранимых записей. При вставке небольшого количества хранимых записей, например, данных X, на соответствующей странице теперь может оставаться достаточно свободного пространства. Поэтому, если возникнет необходимость вставить новую запись данных X, то диспетчер файлов сохранит эту запись на той же странице вслед за последней сохраненной записью.
Теперь, при возникновении необходимости удалить существующую запись данных X, это выполнит диспетчер файлов и, если образовался пустой промежуток между записями на странице, он передвинет записи к началу страницы. Это говорит о том, что логическая последовательность хранимых записей для данной страницы может соответствовать физической последовательности, заданной внутри этой страницы. Для этого диспетчер файлов может передвигать отдельные записи вверх или вниз, размещая все записи в верхней части страницы и оставляя свободное пространство в нижней части страницы. Более того, если СУБД необходимо вставить новую запись на рассматриваемую страницу, то диспетчер файлов разместит запись в соответствии с ее идентификационным номером.
Итак, хранимые записи идентифицируются с помощью идентификационного номера записи z, который состоит из двух частей: номера страницы s. на которой данная запись находится, и информации о смещении записи от конца страницы s. Последняя, в свою очередь, содержит информацию о смещения записи z от начала страницы s. Эта схема в некоторой степени сочетает быстроту непосредственной адресации и гибкость косвенной адресации, т. к. записи внутри страницы могут сдвигаться без изменения идентификационных номеров записей, а корректируются только значения локальных смещений в конце страницы. К тому же, если известен идентификационный номер записей, доступ к требуемой записи осуществляется достаточно быстро, поскольку используется только доступ к данной странице.
Иногда для работы с некоторой записью может потребоваться доступ к двум страницам. Такая ситуация может возникнуть, например, если длина записи превышает размер страницы. Тогда такая запись будет размещена на специальной странице переполнения, а исходный указатель на идентификационный номер прежней записи будет заменен новым. При следующем переполнении страницы запись опять перемещается на новую страницу переполнения с соответствующим изменением указателя.
Следует обратить внимание на то, что для некоторого хранимого файла всегда можно осуществить последовательный доступ ко всем хранимым записям, т. е. доступ согласно последовательности записей внутри страницы и последовательности страниц внутри набора страниц, чаще всего, в порядке возрастания идентификационных номеров записей. Такая последовательность называется физической, хотя надо понимать, что она не обязательно соответствует физическому расположению данных на диске. Доступ к хранимому файлу можно осуществить согласно физической последовательности, даже если несколько файлов находятся на одной и той же странице, при этом записи, которые не относятся к искомому файлу, будут пропущены при последовательном просмотре содержания данной страницы. Кроме того, поля хранимой записи используются в СУБД для составления индексов и т. д., однако диспетчер файлов эту информацию не использует.
Таким образом, важным отличием между диспетчером файлов и СУБД является представление хранимой записи:
- с точки зрения СУБД хранимая запись обладает внутренней структурой,
- с точки зрения диспетчера файлов запись – это строка байтов.
Однако, существуют более совершенные способы упорядочения записей и способы доступа по сравнению с физической последовательностью: использование индексирования, хеширования, цепочек указателей, а также технологии сжатая. При этом часто эти способы используются совместно один на основе другого.
6.3 Процедура индексирования и хеширования
Для того, чтобы детальнее разобраться с индексами, рассмотрим в качестве примера таблицу с данными об оценках и запрос на поиск студентов, сдававших тот или иной учебный предмет. При таких условиях в БД можно выбрать способ хранения данных, представленный на Рис. 5.1.
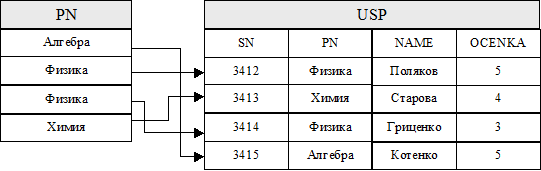 |
Рис. 5.1Индексирование файла оценок по полю PN
Данный способ основан на двух хранимых файлах: файле с данными об успеваемости студентов USP и файле с данными об учебных предметах PN. Эти файлы могут размещаться в различных наборах страниц, при этом предполагается, что в файле предметов используется упорядочение по алфавитному перечню их названий, т. е. по ключевому полю PN с указателями на соответствующие запаси в файле успеваемости.
Возможны следующие стратегии, которые можно применить для поиска всех студентов, сдававших физику:
- найти весь файл успеваемости, найти все записи, для которых названием дисциплины является строка «Физика».
- найти файл предметов со строкой «Физика», а затем согласно указателям извлечь все соответствующие записи из файла успеваемости.
Если доля всех студентов, сдавших физику, по отношению к общему количеству студентов невелика, то вторая стратегия будет гораздо эффективнее первой. Дело в том, что СУБД известна физическая последовательность записей в файле предметов, а поиск будет прекращен после извлечения следующего за физикой в алфавитном порядке названии предмета. Кроме того, даже если придется просмотреть файл предметов полностью, для такого поиска потребуется гораздо меньше операций ввода-вывода, поскольку физический размер файла предметов меньше, чем размер файла успеваемости из-за меньшего размера записей.
В рассмотренном примере файл предметов называют индексным файлом или индексом по отношению к файлу успеваемости, или наоборот - файл успеваемости индексирован по отношению к файлу предметов. Индексный файл является хранимым файлом особого типа, в котором каждая запись состоит из двух значений: данных и указателя номера записи. При этом данные необходимы для индексного поля из индексированного файла, а указатель - для связывания с соответствующей записью индексированного файла.
Если индексирование организовано на основе ключевого поля, например, на основе поля SN файла успеваемости, то индекс называется первичным. А если индекс организован на основе другого поля, например, поля PN, то он называется вторичным. Кроме того, индекс, организованный на основе ключевого поля или другого ключа, называется уникальным.
Основным преимуществом использования индексов является значительное ускорение процесса выборки или извлечения данных, а основным недостатком - замедление процесса обновления данных, т. к. при каждом добавлении новой записи в индексированный файл потребуется также добавить новый индекс в индексный файл. Индексы можно использовать двумя разными способами:
- для последовательного доступа к индексированному файлy, т. е. в последовательности, заданной значениями индексного поля. Например, индекс PN будет определять доступ к записям файла успеваемости согласно алфавитному перечню предметов;
- индексы могут использоваться и для прямого доступа к отдельным записям индексированного файла на основе заданного значения индексного поля, как это было сделано в приведенном примере.
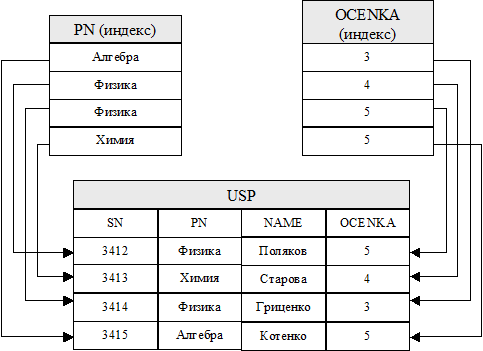
Хранимый файл может иметь несколько индексов: например, файл успеваемости может иметь индекс PN и индекс OCENKA (Рис. 5.2).
Индексы могут как раздельно, так и совместно использоваться для более эффективного доступа к данным об успеваемости, например, при запросе на поиск студентов, сдавших физику на 5. Тогда согласно индексу PN для студентов будут найдены записи с идентификационными указателями z3412 и z3414, а согласно индексу OCENKA - записи с указателями z3412 и r3415. Понятно, что на основе сравнения этих двух наборов записей условиям запроса удовлетворяет только запись с данными о студенте z3412 и только после этого в СУБД будет организован доступ к файлу успеваемости и будет извлечена данная запись.
 |
Часто индекс создают на основе комбинации двух или более полей. Например, на Рис. 5.3 показана схема индексирования файла успеваемости на основе комбинации полей PN и OCENKA. При такой организации индексов в СУБД можно выполнить запрос на поиск студентов, сдавших физику на 5 на основе однократного просмотра с помощью одного индекса, а, как было показано выше, при использовании пары индексов требуется два отдельных просмотра, тем более, что скорость выполнения запроса может сильно зависеть от последовательности выполнения отдельных просмотров по индексам.
Рис. 5.2 Индексирование файла оценок по полю PN и OCENKA
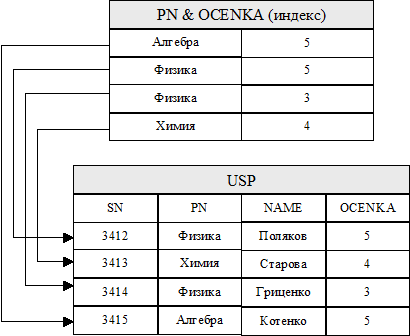
Рис. 5.3 Индексирование файла оценок по комбинации полей PN и OCENKA
Стоит обратить внимание на тот факт, что комбинированный индекс PN&OCENKA может также служить индексом по одному полю PN, т. к. все записи в комбинированном индексе расположены последовательно. Вообще говоря, индекс на основе комбинации полей может использоваться либо для отдельного индексирования по конкретному полю, либо для индексирования на основе их комбинации, следовательно, для создания достаточно сложного индексирования может потребоваться совсем немного индексных полей.
Итак, основной целью использования индекса является ускорение процесса извлечения данных за счет уменьшения числа дисковых операций ввода-вывода, для чего используются указатели Предположим, что физическая последовательность файла успеваемости соответствует логической последовательности, заданной на основе номера студенческого билета, т. е. в этом файле выполнена внутрифайловая кластеризация по данному полю. Если по этому же полю осуществляется индексирование, то нет необходимости в индексе хранить указатели для каждой записи индексируемого файла. Достаточно указать для каждой страницы максимальный номер студента на ней и соответствующий номер страницы.
Индекс с описанной структурой называется неплотным, поскольку в нем не содержатся указатели на все записи индексированного файла. Одним из преимуществ неплотных индексов является их малый размер по сравнению с плотными индексами, описанными выше, т. к-, очевидно, они содержат меньшее число записей. Это часто позволяет просматривать содержимое БД с большей скоростью, но зато нельзя выполнить проверку наличия некоторого значения.
Другим не менее интересным способом упорядочения записей и доступа является хеширование. Хешированием (хеш-индексированием) называется технология быстрого прямого доступа к хранимой записи на основе заданного значения некоторого поля, при этом совсем не обязательно, чтобы поле было ключевым.
Основные особенности этой технологии следующие:
- каждая хранимая запись БД размещается по адресу, который вычисляется с помощью специальной хеш-функции на основе значения некоторого поля данной записи, т. е. хеш-поля, а вычисленный адрес называется хеш-адресом.
- для сохранения записи в СУБД сначала вычисляется хеш-адрес новой записи, после чего диспетчер файлов помещает эту запись по вычисленному адресу;
- для извлечения нужной записи по заданному значению хеш-поля в СУБД сначала вычисляется хеш-адрес, а затем диспетчеру файлов посылается запрос на извлечение записи по вычисленному адресу.
Простейшим примером хеш-функции может служить:
Хеш-адрес = остаток от деления на простое натуральное число значения, содержащегося в хеш-поле.
Из этого ясно, что хеширование отличается от индексирования тем, что в файле может быть любое количество индексов, но только одно хеш-поле. Теоретически можно было бы для определения адреса вместо функции использовать непосредственно значение ключевого числового поля, однако практически такой способ непригоден, т. к. диапазон возможных значений ключевого поля может быть гораздо шире диапазона имеющихся адресов. Таким образом, во избежание неэффективного использования дискового пространства следует найти такую хеш-функцию, чтобы можно было сузить диапазон до оптимальной величины с учетом возможности резервирования дополнительного пространства.
Недостаток хеширования заключается в том, что физическая последовательность записей внутри хранимого файла почти всегда отличается от последовательности ключевого поля, а также любой другой логически заданной последовательности, а между последовательно размещенными записями могут быть промежутки неопределенной протяженности. Практически всегда физическая последовательность записей в хранимом хешированием файле принципиально иная по сравнению с заданной в нем логической последовательностью.
Другим недостатком хеширования является возможность возникновения ситуаций, когда две или более различных записей имеют одинаковые адреса, поэтому иногда возникает необходимость функцию исправлять. Если на одной странице располагается несколько записей, то для исправления можно воспользоваться методом прямого перебора. Суть метода заключается в следующем: предположим, что на пустой странице s размещается n записей. Тогда при размещении записей и возникновении первых n совпадений по некоторому хеш-адресу s, все такие записи будут размещены на этой странице и найдены при необходимости с помощью прямого перебора. Однако при размещении следующей n+1 записи и возникновении очередного совпадения, запись придется разместить на дополнительной странице переполнения, для чего понадобится дополнительная дисковая операция ввода-вывода.
Необходимо иметь в виду, что с увеличением размера хранимого файла количество совпадений адресов увеличивается, что приводит к значительному увеличению среднего времени доступа - ведь все больше времени придется тратить на поиск информации в наборах конфликтующих записей. Это можно устранить, если реорганизовать файл, т. е. загрузить данный файл, используя новую функцию, что решается при помощи расширяемого хеширования.
При использовании расширяемого хеширования необходимо, чтобы все значения хеш-поля были уникальны, а это может быть реализовано только в том случае, если хеш-поле является ключевым.
Основные принципы работы метода расширяемого хеширования следующие:
- если в качестве хеш-функции используется функция j, а значение ключевого поля для некоторой записи z равно p, то в качестве результата хеширования значения ключевого поля будет получено значение псевдоключа для записи z в виде j(p). Здесь псевдоключ используется не в качестве адреса записи, а лишь как косвенный указатель на место их хранения;
- хранимый файл имеет связанный с ним каталог, который также сохраняется на диске. Он состоит из заголовка, содержащего значение g, которое называется глубиной каталога, а также ![]() указателей на страницы с несколькими записями данных на каждой.
указателей на страницы с несколькими записями данных на каждой.
Таким образом, с помощью каталога глубиной g можно организовать доступ к файлу, содержащему ![]() различных страниц с данными.
различных страниц с данными.
Если рассматривать первые g бит псевдоключа как целое беззнаковое двоичное число b, то i-й указатель в каталоге будет относиться к странице, содержащей все записи, для которых величина b равна ![]() . Для того чтобы найти запись со значением клювого поля, равным p, следует с помощью хеш-функции вычислить значение псевдоключа, а затем по первым g бит псевдоключа определить численное значение
. Для того чтобы найти запись со значением клювого поля, равным p, следует с помощью хеш-функции вычислить значение псевдоключа, а затем по первым g бит псевдоключа определить численное значение ![]() и найти в каталоге соответствующий ему i-й указатель на страницу, содержащую искомую запись, что реализуется за два доступа к диску.
и найти в каталоге соответствующий ему i-й указатель на страницу, содержащую искомую запись, что реализуется за два доступа к диску.
Здесь был описан лишь один из вариантов хеширования, однако существует множество других способов реализации этой основной идеи.
Для выполнения запросов можно применять другой, не менее эффективный, способ хранения данных с использованием цепочек указателей. При этом, в отличие от индексирования, оба файла могут находиться в одном наборе файлов, причем файл, аналогичный индексному, в данном случае принято называть родительским, а файл с основными данными соответственно дочерним.
Рассмотрим такую структуру (ее часто называют родительско-дочерней) на примере уже рассмотренного выше файла, содержащего данные об успеваемости студентов. Тогда структура будет состоять из файлов успеваемости и учебных предметов, при этом родительский файл будет содержать одну хранимую запись для каждого предмета, предоставляя при необходимости название предмета в качестве заголовка цепочки или кольца указателей, связывающих вместе все дочерние записи об успеваемости студентов по этому предмету (см. Рис. 5.4).
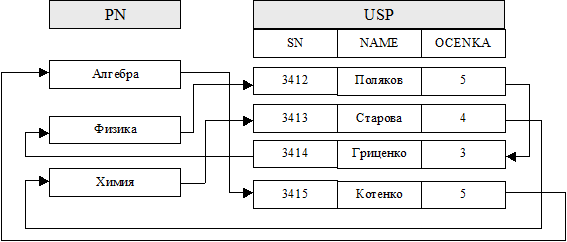 |
Стоит обратить внимание на то, что поле с названиями предметов РN отсутствует в файле успеваемости, т. к. СУБД для поиска студентов в зависимости от сданного предмета будет искать строку с названием предмета в родительском файле, а затем извлекается вся связанная с данной строкой цепочка указателей.
Рис. 5.4 Родительско-дочерняя структура для файла с данными об успеваемости
Основным преимуществом родительско-дочерней структуры является значительно более простое выполнение операций вставки или удаления записей по сравнению с индексной структурой. Кроме того, родительско-дочерняя структура занимает меньше места на диске, чем соответствующая индексная структура, поскольку в ней не повторяется информация в родительском файле. Однако такая структура имеет и некоторые недостатки. Например, для данного предмета единственным путем доступа к n-му студенту является цепочка с последовательным перебором всех предыдущих записей студентов, а если для этих записей не выполнена кластеризация, то для каждого доступа к данным может потребоваться отдельная операция поиска и время доступа к записи может оказаться очень большим.
С другой стороны, такая структура может быть оптимальной для выполнения запроса на поиск студентов, сдавших тот или предмет, однако она неэффективна для обратного запроса на поиск предмета, сданного студентом, поэтому для обратного запроса больше подошла бы индексная или хешированная структура. И, наконец, если родительский файл имеет очень большой размер, то для него также потребуется применить индексирование или хеширование, а значит, цепочки указателей не являются способом создания качественной структуры хранения данных и с ними требуется совместно использовать другие методы.
Усовершенствование родительско-дочерней структуры можно произвести за счет добавления в дочерних записях еще одного указателя на соответствующую родительскую запись - при такой организации цепочек можно было бы избежать просмотра всей цепочки при выполнении запросов.
6.4 Сжатие данных
С целью сокращения пространства, необходимого для хранения некоторого набора данных, часто используют технологии сжатия. При этом в результате экономится не только пространство на диске, но и количество дисковых операций ввода-вывода, т. к. доступ к данным меньшего размера требует меньше дисковых операций ввода-вывода. С другой стороны, для распаковки и извлечения сжатых данных требуются некоторые дополнительные манипуляции, но в целом преимущества сокращения операций ввода-вывода могут компенсировать недостатки, связанные с дополнительной обработкой данных.
Технологии сжатия основаны на малой вероятности того, что данные имеют совершенно беспорядочную структуру. Наиболее распространенной является технология сжатия на основе различий, при которой некоторое значение заменяется сведениями о его отличиях от предыдущего значения. Следует отметить, что для реализации такой технологии требуется размещать данные последовательно, поскольку для их распаковки необходимо иметь значение предыдущей величины. Такое сжатие весьма эффективно для данных, к которым необходим последовательный доступ, например для записей в одноуровневом списке. Более того, в таких случаях наряду с данными допускается также сжать и указатели. Дело в том, что если логическая последовательность в файле соответствует физической последовательности размещения данных на диске, то соседние указатели будут незначительно отличаться друг от друга, а значит, сжатие указателей может оказаться весьма полезным и эффективным.
В качестве примера рассмотрим несколько записей со следующими данными:
Студент; Студентка; Студенческий
Предположим, что длина поля составляет 15 символов и справа от данных в несжатом виде содержится соответствующее количество пробелов. Один из способов применения сжатия на основе различий - это удаление повторяющихся символов в начале каждой записи с указанием их количества, т. е. переднее сжатие. В результате будет получено (числа соответствуют количеству повторяющихся символов в начале имени, пробелы справа до полной длины поля -15 символов - не показаны):
0 – Студент
7 – ка
6 – ческий
При необходимости можно осуществить дополнительное сжатие, удаляя пробелы с указанием их количества, т. е. выполнить так называемое заднее сжатие. Иногда еще допускается удаление с правого конца каждого значения всех повторяющихся символов в двух ближайших соседних значениях.
Другим способом уменьшения объема занимаемого данными места является иерархическое сжатие. Предположим, что в хранимом файле задана некоторая физическая последовательность согласно выбранному полю, различные значения которого располагаются в нескольких последовательных записях этого файла.
Например, в хранимом файле успеваемости благодаря кластеризации, выполненной согласно полю PN с названиями предметов, отдельно содержатся все записи о студентах, сдавших тот или иной предмет. В таком случае набор всех записей с данными о студентах, сдавших тот или иной предмет, может быть успешно ежат в одну хранимую иерархическую запись, при этом название предмета будет упомянуто только один раз, а вслед за ним будут расположены данные о студентах ( Рис. 5.5).
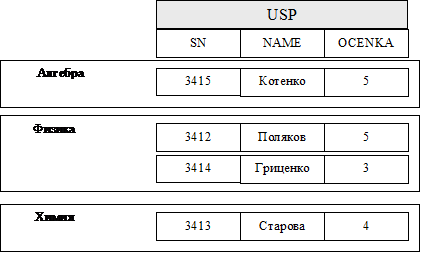 |
Рис. 5.5 Внутрифайловое иерархическое сжатие файла с данными об успеваемости
Хранимая иерархическая запись состоит из двух частей: постоянной, в нашем примере это поля с названиями предметов, и переменной - записи с информацией о студентах. Такой набор значений переменного количества внутри одной записи обычно называется группой повторения. Таким образом, можно сказать, что иерархическая запись, представленная на Рис. 5.5, состоит из значения поля предметов и группы повторения с информацией о студентах, состоящей из полей с номерами студенческих билетов фамилий студентов и оценок по предмету.
Иерархическое сжатие такого типа применяют и для индекса, в котором несколько последовательно расположенных значений содержат одни и те же повторяющиеся значения данных, но различные значения указателей.
Аналогичным образом можно применять иерархическое сжатие на основе межфайловой кластеризации. Например, записи с данными о студентах как бы объединяются с данными обо всех оценках по всем предметам для данного студента.
В заключение отметим, что структуру на основе цепочки указателей можно рассматривать как межфайловое сжатие, которое не требует межфайловой кластеризации, т. к. указатели позволяют логически достичь эффекта кластеризации.
Кодирование Хафмана - это еще одна технология кодирования символов, которая может быть весьма эффективной для сжатия различных символов, встречающихся с разной частотой, Основная идея этого метода заключается в кодировании отдельных символов битовыми строками различной длины, наиболее часто встречающиеся символы кодируются строками наименьшей длины. Кроме того, код любого символа длиной n не должен совпадать с первыми n символами кода какого-либо другого символа Предположим, что некоторые данные записаны с помощью символов А, Б, В, Г, Д, тогда с учетом относительной частоты, с которой они встречаются, их коды приведены в таблице.
Таблица. Коды символов
Символ | Частота, % | Код |
А | 35 | 1 |
В | 30 | 01 |
Г | 20 | 001 |
Д | 10 | 0001 |
Б | 5 | 0000 |
Символ А встречается чаще остальных, потому имеет самый короткий код, состоящий из одного бита. Все остальные коды должны быть длиннее, однако нельзя использовать код на основе одного нуля, так как он будет совпадать с начальной частью других, более длинных кодов. Оценочно можно сказать, что в среднем общая длина закодированного текста на 40% меньше, чем при отсутствии кодирования.
